البرنامج التعليمي: استخراج البيانات وتحويلها وتحميلها باستخدام Azure Databricks
في هذا البرنامج التعليمي، يمكنك إجراء عملية ETL (استخراج البيانات وتحويلها وتحميلها) باستخدام Azure Databricks. يمكنك استخراج البيانات من Azure Data Lake Storage Gen2 إلى Azure Databricks، وتشغيل التحويلات على البيانات في Azure Databricks، وتحميل البيانات المحولة إلى Azure Synapse Analytics.
تستخدم الخطوات الواردة في هذا البرنامج التعليمي موصل Azure Synapse ل Azure Databricks لنقل البيانات إلى Azure Databricks. يستخدم هذا الموصل بدوره تخزين Azure Blob كمخزن مؤقت للبيانات التي يتم نقلها بين مجموعة Azure Databricks وAzure Synapse.
يوضح الرسم التوضيحي التالي تدفق التطبيق:

يشمل البرنامج التعليمي المهام التالية:
- إنشاء خدمة Azure Databricks.
- إنشاء مجموعة Spark في Azure Databricks.
- إنشاء نظام ملفات في حساب Data Lake Storage Gen2.
- تحميل نموذج البيانات إلى حساب Azure Data Lake Storage Gen2.
- إنشاء كيان الخدمة.
- استخراج البيانات من حساب Azure Data Lake Storage Gen2.
- تحويل البيانات في Azure Databricks.
- تحميل البيانات في Azure Synapse.
في حال لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانيّاً قبل البدء.
إشعار
لا يمكن تنفيذ هذا البرنامج التعليمي باستخدام Azure Free Trial Subscription. إذا كان لديك حساب مجاني، فانتقل إلى ملف التعريف الخاص بك وغير اشتراكك إلى الدفع أولا بأول. لمزيد من المعلومات، راجع حساب Azure المجاني. ثم قم بإزالة حد الإنفاق، وطلب زيادة الحصة النسبية لوحدات المعالجة المركزية الظاهرية في منطقتك. عند إنشاء مساحة عمل Azure Databricks، يمكنك تحديد مستوى التسعير التجريبي (Premium - وحدات DBUs المجانية لمدة 14 يوما) لمنح مساحة العمل حق الوصول إلى وحدات Premium Azure Databricks DBUs المجانية لمدة 14 يوما.
المتطلبات الأساسية
أكمل هذه المهام قبل أن تبدأ هذا البرنامج التعليمي:
إنشاء Azure Synapse، وإنشاء قاعدة جدار حماية على مستوى الخادم، والاتصال بالخادم كمسؤول خادم. راجع التشغيل السريع: إنشاء تجمع Synapse SQL والاستعلام عن ذلك باستخدام مدخل Microsoft Azure.
إنشاء مفتاح رئيسي ل Azure Synapse. راجع إنشاء مفتاح رئيسي لقاعدة البيانات.
إنشاء حساب تخزين Azure Blob وحاوية داخله. أيضا، قم باسترداد مفتاح الوصول للوصول إلى حساب التخزين. راجع التشغيل السريع: تحميل الكائنات الثنائية كبيرة الحجم وتنزيلها وإدراجها باستخدام مدخل Microsoft Azure.
إنشاء حساب تخزين Azure Data Lake Storage Gen2. راجع التشغيل السريع: إنشاء حساب تخزين Azure Data Lake Storage Gen2.
إنشاء كيان الخدمة. راجع كيفية: استخدام المدخل لإنشاء تطبيق Microsoft Entra ID (المعروف سابقا ب Azure Active Directory) ومدير الخدمة الذي يمكنه الوصول إلى الموارد.
هناك بعض الأشياء المحددة التي يجب عليك فعلها أثناء تنفيذ الخطوات الواردة في هذه المقالة.
عند تنفيذ الخطوات في قسم تعيين التطبيق إلى دور في المقالة، تأكد من تعيين دور Storage Blob Data Contributor إلى كيان الخدمة في نطاق حساب Data Lake Storage Gen2. إذا قمت بتعيين الدور إلى مجموعة الموارد الأصلية أو الاشتراك، فستتلقى أخطاء متعلقة بالأذونات حتى يتم نشر تعيينات الدور هذه إلى حساب التخزين.
إذا كنت تفضل استخدام قائمة التحكم بالوصول (ACL) لربط كيان الخدمة بملف أو دليل معين، فراجع التحكم في الوصول في Azure Data Lake Storage Gen2.
عند تنفيذ الخطوات في قسم الحصول على قيم لتسجيل الدخول في المقالة، الصق معرف المستأجر ومعرف التطبيق والقيم السرية في ملف نصي.
قم بتسجيل الدخول إلى بوابة Azure.
جمع المعلومات التي تحتاجها
تأكد من إكمال المتطلبات الأساسية لهذا البرنامج التعليمي.
قبل البدء، يجب أن يكون لديك عناصر المعلومات هذه:
✔️ اسم قاعدة البيانات واسم خادم قاعدة البيانات واسم المستخدم وكلمة المرور الخاصة ب Azure Synapse.
✔️ مفتاح الوصول لحساب تخزين الكائن الثنائي كبير الحجم.
✔️ اسم حساب تخزين Data Lake Storage Gen2.
✔️ معرف المستأجر لاشتراكك.
✔️ معرف التطبيق للتطبيق الذي قمت بتسجيله باستخدام معرف Microsoft Entra (المعروف سابقا باسم Azure Active Directory).
✔️ مفتاح المصادقة للتطبيق الذي قمت بتسجيله باستخدام معرف Microsoft Entra (المعروف سابقا باسم Azure Active Directory).
إنشاء خدمة Azure Databricks
في هذا القسم، سوف تنشئ خدمة Azure Databricks باستخدام مدخل Microsoft Azure.
من قائمة مدخل Azure، حدد إنشاء مورد.
ثم حدد Analytics>Azure Databricks.
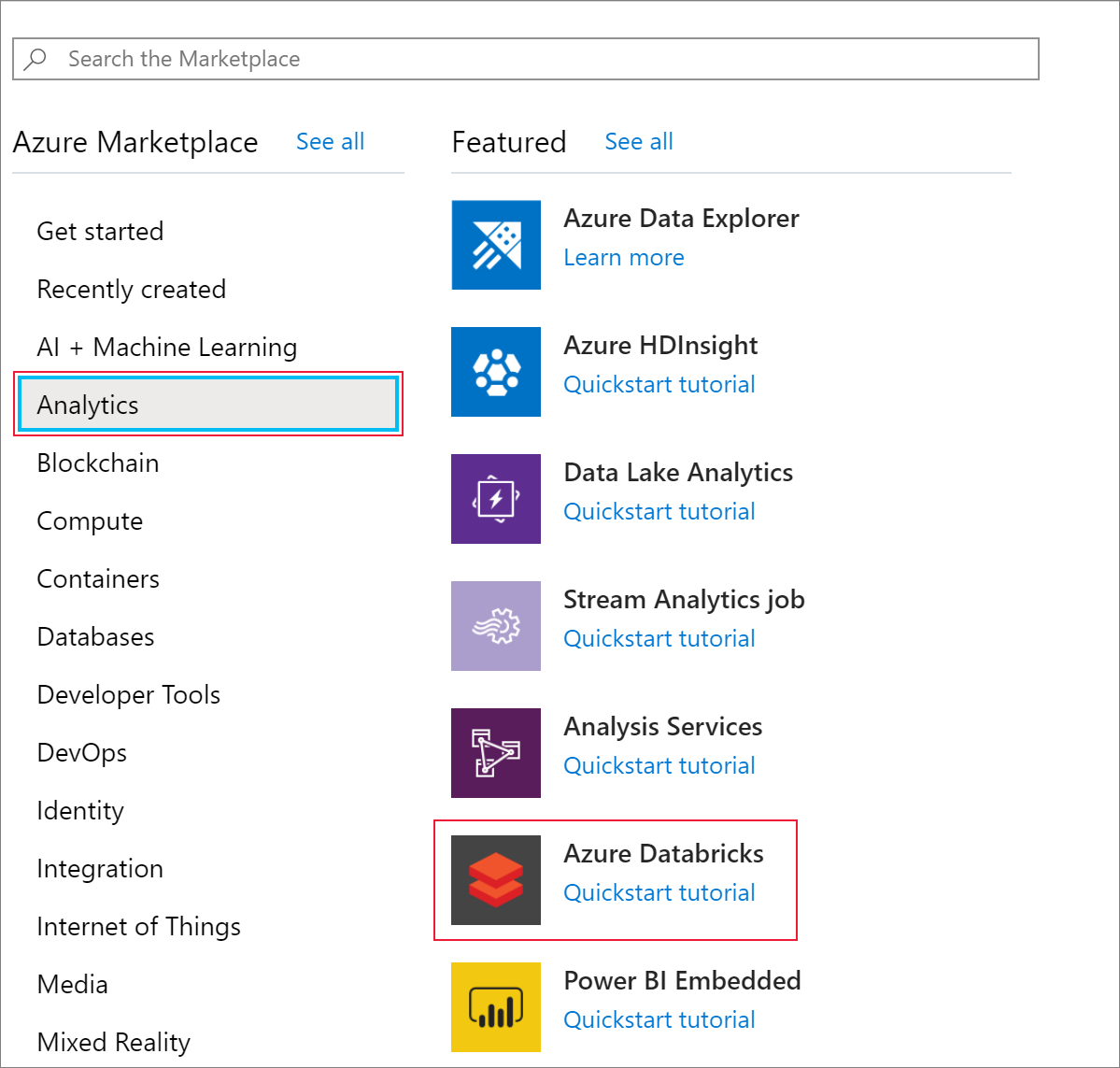
في خدمة Azure Databricks، أدخل القيم الآتية لإنشاء خدمة Databricks:
الخاصية الوصف اسم مساحة العمل أدخل اسماً لمساحة عمل Databricks. الاشتراك من القائمة المنسدلة، حدد اشتراك Azure الخاص بك. مجموعة الموارد حدد «ما إذا كنت تريد إنشاء مجموعة موارد جديدة أو استخدام مجموعة موجودة». تُعد مجموعة الموارد حاويةً تضم موارد ذات صلة بحلول Azure. لمزيد من المعلومات، راجع نظرة عامة حول مجموعة موارد Azure. Location حدد غرب الولايات المتحدة 2. بالنسبة إلى المناطق الأخرى المتوفرة، راجع خدمات Azure المتوفرة حسب المنطقة. مستوى التسعير حدد قياسي. يستغرق إنشاء الحساب بضع دقائق. لمراقبة حالة العملية، اعرض شريط التقدم في الأعلى.
حدد تثبيت في لوحة المعلومات ثم حدد إنشاء.
إنشاء نظام مجموعة Spark في Azure Databricks
في مدخل Microsoft Azure، انتقل إلى خدمة Databricks التي أنشأتها، ثم حدد تشغيل مساحة العمل.
سوف تتم إعادة توجيهك إلى مدخل Microsoft Azure Databricks. من المدخل، حدد نظام المجموعة.

في صفحة نظام المجموعة الجديد، أدخل القيم لإنشاء نظام مجموعة.

املأ قيم الحقول الآتية واقبل القيم الافتراضية للحقول الأخرى:
أدخل اسماً لنظام المجموعة.
تأكد من تحديد خانة الاختيار إنهاء بعد __ دقائق من عدم النشاط . إذا لم يتم استخدام نظام المجموعة، فوفر مدة (بالدقائق) لإنهاء نظام المجموعة.
حدد إنشاء نظام مجموعة. بعد تشغيل نظام المجموعة، يمكنك إرفاق دفاتر ملاحظات بنظام المجموعة وتشغيل مهام Spark.
إنشاء نظام ملفات في حساب Azure Data Lake Storage Gen2
في هذا القسم، يمكنك إنشاء دفتر ملاحظات في مساحة عمل Azure Databricks ثم تشغيل القصاصات البرمجية لتكوين حساب التخزين
في مدخل Microsoft Azure، انتقل إلى خدمة Azure Databricks التي أنشأتها، ثم حدد تشغيل مساحة العمل.
على اليسار، حدد مساحة العمل. من القائمة المنسدلة مساحة العمل حدد إنشاء>دفتر ملاحظات.

في مربع الحوار إنشاء دفتر ملاحظات، أدخل اسماً لدفتر الملاحظات. حدد Scala كلغة، ثم حدد مجموعة Spark التي قمت بإنشائها سابقا.

حدد إنشاء.
تعين كتلة التعليمات البرمجية التالية بيانات اعتماد كيان الخدمة الافتراضية لأي حساب ADLS Gen 2 يتم الوصول إليه في جلسة Spark. تقوم كتلة التعليمات البرمجية الثانية بإلحاق اسم الحساب بالإعداد لتحديد بيانات الاعتماد لحساب ADLS Gen 2 معين. انسخ كتلة التعليمات البرمجية والصقها في الخلية الأولى من دفتر ملاحظات Azure Databricks.
تكوين جلسة العمل
val appID = "<appID>" val secret = "<secret>" val tenantID = "<tenant-id>" spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appID>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<secret>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant-id>/oauth2/token") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true")تكوين الحساب
val storageAccountName = "<storage-account-name>" val appID = "<app-id>" val secret = "<secret>" val fileSystemName = "<file-system-name>" val tenantID = "<tenant-id>" spark.conf.set("fs.azure.account.auth.type." + storageAccountName + ".dfs.core.windows.net", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type." + storageAccountName + ".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id." + storageAccountName + ".dfs.core.windows.net", "" + appID + "") spark.conf.set("fs.azure.account.oauth2.client.secret." + storageAccountName + ".dfs.core.windows.net", "" + secret + "") spark.conf.set("fs.azure.account.oauth2.client.endpoint." + storageAccountName + ".dfs.core.windows.net", "https://login.microsoftonline.com/" + tenantID + "/oauth2/token") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true") dbutils.fs.ls("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "false")في كتلة التعليمات البرمجية هذه، استبدل قيم العنصر النائب
<app-id>و<secret>و<tenant-id>و<storage-account-name>في كتلة التعليمات البرمجية هذه بالقيم التي جمعتها في أثناء إكمال المتطلبات الأساسية لهذا البرنامج التعليمي.<file-system-name>استبدل قيمة العنصر النائب بأي اسم تريد منحه لنظام الملفات.<secret>و<app-id>من التطبيق الذي قمت بتسجيله مع Active Directory كجزء من إنشاء كيان خدمة.هو
<tenant-id>من اشتراكك.<storage-account-name>هو اسم حساب تخزين Azure Data Lake Storage Gen2.
اضغط على المفاتيح SHIFT + ENTER لتشغيل التعليمات البرمجية في هذه الكتلة.
استيعاب بيانات العينة في حساب Azure Data Lake Storage Gen2
قبل البدء بهذا القسم، يجب إكمال المتطلبات الأساسية التالية:
أدخل التعليمات البرمجية التالية في خلية دفتر ملاحظات:
%sh wget -P /tmp https://raw.githubusercontent.com/Azure/usql/master/Examples/Samples/Data/json/radiowebsite/small_radio_json.json
في الخلية، اضغط على SHIFT + ENTER لتشغيل التعليمات البرمجية.
الآن في خلية جديدة أسفل هذه الخلية، أدخل التعليمات البرمجية التالية، واستبدل القيم التي تظهر بين قوسين بنفس القيم التي استخدمتها سابقا:
dbutils.fs.cp("file:///tmp/small_radio_json.json", "abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/")
في الخلية، اضغط على SHIFT + ENTER لتشغيل التعليمات البرمجية.
استخراج البيانات من حساب Azure Data Lake Storage Gen2
يمكنك الآن تحميل نموذج ملف json كإطار بيانات في Azure Databricks. الصق التعليمات البرمجية التالية في خلية جديدة. استبدل العناصر النائبة الموضحة بين قوسين بقيمك.
val df = spark.read.json("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/small_radio_json.json")اضغط على المفاتيح SHIFT + ENTER لتشغيل التعليمات البرمجية في هذه الكتلة.
قم بتشغيل التعليمات البرمجية التالية لمشاهدة محتويات إطار البيانات:
df.show()يجب أن ترى ناتجًا مماثلًا للقصاصة البرمجية التالية:
+---------------------+---------+---------+------+-------------+----------+---------+-------+--------------------+------+--------+-------------+---------+--------------------+------+-------------+------+ | artist| auth|firstName|gender|itemInSession| lastName| length| level| location|method| page| registration|sessionId| song|status| ts|userId| +---------------------+---------+---------+------+-------------+----------+---------+-------+--------------------+------+--------+-------------+---------+--------------------+------+-------------+------+ | El Arrebato |Logged In| Annalyse| F| 2|Montgomery|234.57914| free | Killeen-Temple, TX| PUT|NextSong|1384448062332| 1879|Quiero Quererte Q...| 200|1409318650332| 309| | Creedence Clearwa...|Logged In| Dylann| M| 9| Thomas|340.87138| paid | Anchorage, AK| PUT|NextSong|1400723739332| 10| Born To Move| 200|1409318653332| 11| | Gorillaz |Logged In| Liam| M| 11| Watts|246.17751| paid |New York-Newark-J...| PUT|NextSong|1406279422332| 2047| DARE| 200|1409318685332| 201| ... ...لقد قمت الآن باستخراج البيانات من Azure Data Lake Storage Gen2 إلى Azure Databricks.
تحويل البيانات في Azure Databricks
يلتقط ملف البيانات الأولية small_radio_json.json الجمهور لمحطة راديو ويحتوي على مجموعة متنوعة من الأعمدة. في هذا القسم، يمكنك تحويل البيانات لاسترداد أعمدة معينة فقط من مجموعة البيانات.
أولا، قم باسترداد الأعمدة firstName وlastName والجنس والموقع والمستوىفقط من إطار البيانات الذي قمت بإنشائه.
val specificColumnsDf = df.select("firstname", "lastname", "gender", "location", "level") specificColumnsDf.show()تتلقى الإخراج كما هو موضح في القصاصة البرمجية التالية:
+---------+----------+------+--------------------+-----+ |firstname| lastname|gender| location|level| +---------+----------+------+--------------------+-----+ | Annalyse|Montgomery| F| Killeen-Temple, TX| free| | Dylann| Thomas| M| Anchorage, AK| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Tess| Townsend| F|Nashville-Davidso...| free| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| |Gabriella| Shelton| F|San Jose-Sunnyval...| free| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Tess| Townsend| F|Nashville-Davidso...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Alan| Morse| M|Chicago-Napervill...| paid| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| +---------+----------+------+--------------------+-----+يمكنك تحويل هذه البيانات لإعادة تسمية مستوى العمود إلى subscription_type.
val renamedColumnsDF = specificColumnsDf.withColumnRenamed("level", "subscription_type") renamedColumnsDF.show()تتلقى الإخراج كما هو موضح في القصاصة البرمجية التالية.
+---------+----------+------+--------------------+-----------------+ |firstname| lastname|gender| location|subscription_type| +---------+----------+------+--------------------+-----------------+ | Annalyse|Montgomery| F| Killeen-Temple, TX| free| | Dylann| Thomas| M| Anchorage, AK| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Tess| Townsend| F|Nashville-Davidso...| free| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| |Gabriella| Shelton| F|San Jose-Sunnyval...| free| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Tess| Townsend| F|Nashville-Davidso...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Alan| Morse| M|Chicago-Napervill...| paid| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| +---------+----------+------+--------------------+-----------------+
تحميل البيانات في Azure Synapse
في هذا القسم، يمكنك تحميل البيانات المحولة إلى Azure Synapse. يمكنك استخدام موصل Azure Synapse ل Azure Databricks لتحميل إطار بيانات مباشرة كجدول في تجمع Synapse Spark.
كما ذكرنا سابقا، يستخدم موصل Azure Synapse تخزين Azure Blob كمخزن مؤقت لتحميل البيانات بين Azure Databricks وAzure Synapse. لذلك، تبدأ بتوفير التكوين للاتصال بحساب التخزين. يجب أن تكون قد أنشأت الحساب بالفعل كجزء من المتطلبات الأساسية لهذه المقالة.
قم بتوفير التكوين للوصول إلى حساب Azure Storage من Azure Databricks.
val blobStorage = "<blob-storage-account-name>.blob.core.windows.net" val blobContainer = "<blob-container-name>" val blobAccessKey = "<access-key>"حدد مجلدا مؤقتا لاستخدامه أثناء نقل البيانات بين Azure Databricks وAzure Synapse.
val tempDir = "wasbs://" + blobContainer + "@" + blobStorage +"/tempDirs"قم بتشغيل القصاصة البرمجية التالية لتخزين مفاتيح الوصول إلى تخزين Azure Blob في التكوين. يضمن هذا الإجراء عدم الاحتفاظ بمفتاح الوصول في دفتر الملاحظات في نص عادي.
val acntInfo = "fs.azure.account.key."+ blobStorage sc.hadoopConfiguration.set(acntInfo, blobAccessKey)توفير القيم للاتصال بمثيل Azure Synapse. يجب أن تكون قد أنشأت خدمة Azure Synapse Analytics كشرط أساسي. استخدم اسم الخادم المؤهل بالكامل ل dwServer. على سبيل المثال،
<servername>.database.windows.net//Azure Synapse related settings val dwDatabase = "<database-name>" val dwServer = "<database-server-name>" val dwUser = "<user-name>" val dwPass = "<password>" val dwJdbcPort = "1433" val dwJdbcExtraOptions = "encrypt=true;trustServerCertificate=true;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" val sqlDwUrl = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass + ";$dwJdbcExtraOptions" val sqlDwUrlSmall = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPassقم بتشغيل القصاصة البرمجية التالية لتحميل إطار البيانات المحول، المعاد تسميتهColumnsDF، كجدول في Azure Synapse. ينشئ هذا المقتطف جدولا يسمى SampleTable في قاعدة بيانات SQL.
spark.conf.set( "spark.sql.parquet.writeLegacyFormat", "true") renamedColumnsDF.write.format("com.databricks.spark.sqldw").option("url", sqlDwUrlSmall).option("dbtable", "SampleTable") .option( "forward_spark_azure_storage_credentials","True").option("tempdir", tempDir).mode("overwrite").save()إشعار
يستخدم هذا النموذج العلامة
forward_spark_azure_storage_credentials، مما يؤدي إلى وصول Azure Synapse إلى البيانات من تخزين كائن ثنائي كبير الحجم باستخدام مفتاح الوصول. هذه هي الطريقة الوحيدة المعتمدة للمصادقة.إذا كان Azure Blob Storage مقيدا بتحديد الشبكات الظاهرية، فإن Azure Synapse يتطلب هوية الخدمة المدارة بدلا من مفاتيح الوصول. سيؤدي هذا إلى ظهور الخطأ "هذا الطلب غير مصرح به لتنفيذ هذه العملية."
الاتصال إلى قاعدة بيانات SQL وتحقق من رؤية قاعدة بيانات باسم SampleTable.

قم بتشغيل استعلام تحديد للتحقق من محتويات الجدول. يجب أن يحتوي الجدول على نفس البيانات مثل إطار بيانات reedColumnsDF .

تنظيف الموارد
بعد الانتهاء من البرنامج التعليمي، يمكنك إنهاء نظام المجموعة. من مساحة عمل Azure Databricks، حدد Clusters على اليسار. لإنهاء نظام المجموعة، ضمن Actions، أشر إلى علامة الحذف (...) وحدد رمز Terminate .

إذا لم تقم بإنهاء نظام المجموعة يدويا، فإنه يتوقف تلقائيا، بشرط تحديد خانة الاختيار إنهاء بعد __ دقائق من عدم النشاط عند إنشاء نظام المجموعة. في مثل هذه الحالة، يتوقف نظام المجموعة تلقائيا إذا كان غير نشط للوقت المحدد.
الخطوات التالية
في هذا البرنامج التعليمي، نتعلم طريقة القيام بما يأتي:
- إنشاء خدمة Azure Databricks
- إنشاء نظام مجموعة Spark في Azure Databricks
- إنشاء دفتر ملاحظات في Azure Databricks
- استخراج البيانات من حساب Data Lake Storage Gen2
- تحويل البيانات في Azure Databricks
- تحميل البيانات في Azure Synapse