الإصلاح بعد كارثة الإقليمي لنُظم مجموعات Azure Databricks
توضح هذه المقالة بنية التعافي من الكوارث المفيدة لمجموعات Azure Databricks، والخطوات لإنجاز هذا التصميم.
بنية Azure Databricks
عند إنشاء مساحة عمل Azure Databricks من مدخل Microsoft Azure، يتم نشر تطبيق مدار كمورد Azure في اشتراكك، في منطقة Azure المختارة (على سبيل المثال، غرب الولايات المتحدة). يتم نشر هذا الجهاز في شبكة Azure الظاهرية مع مجموعة أمان الشبكة وحساب تخزين Azure، المتوفر في اشتراكك. توفر الشبكة الظاهرية أمان مستوى المحيط لمساحة عمل Databricks، وهي محمية عبر مجموعة أمان الشبكة. داخل مساحة العمل، يمكنك إنشاء مجموعات Databricks عن طريق توفير نوع الجهاز الظاهري للعامل وبرنامج التشغيل وإصدار وقت تشغيل Databricks. تتوفر البيانات المستمرة في حساب التخزين الخاص بك. بمجرد إنشاء نظام المجموعة، يمكنك تشغيل المهام عبر دفاتر الملاحظات أو واجهات برمجة تطبيقات REST أو نقاط نهاية ODBC/JDBC، عن طريق إرفاقها بمجموعة معينة.
تدير وحدة التحكم Databricks بيئة مساحة عمل Databricks وتراقبها. سيتم بدء أي عملية إدارة، مثل إنشاء نظام مجموعة، من مستوى التحكم. يتم تخزين جميع بيانات التعريف، مثل المهام المجدولة، في قاعدة بيانات Azure، ويتم نسخ النسخ الاحتياطية لقاعدة البيانات تلقائيا جغرافيا في مناطق مقترنة حيث يتم تنفيذها.
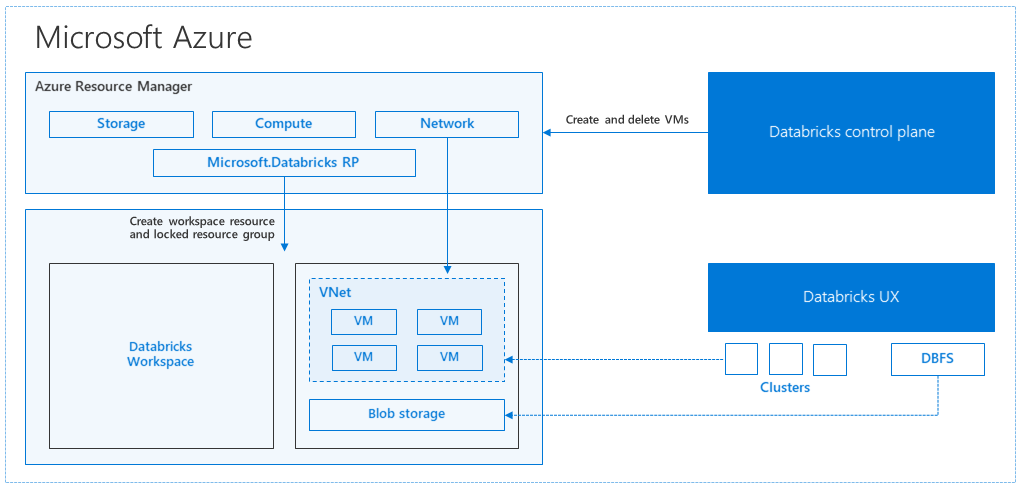
تتمثل إحدى مزايا هذه البنية في أنه يمكن للمستخدمين توصيل Azure Databricks بأي مورد تخزين في حسابهم. الفائدة الرئيسية هي أنه يمكن توسيع نطاق كل من الحوسبة (Azure Databricks) والتخزين بشكل مستقل عن بعضهما البعض.
كيفية إنشاء طوبولوجيا إقليمية للتعافي من الكوارث
في وصف البنية السابقة، هناك عدد من المكونات المستخدمة لمسار البيانات الضخمة مع Azure Databricks: تخزين Azure وقاعدة بيانات Azure ومصادر البيانات الأخرى. Azure Databricks هو الحساب لمسار البيانات الضخمة. إنه سريع الزوال بطبيعتها، ما يعني أنه على الرغم من أن بياناتك لا تزال متوفرة في Azure Storage، يمكن إنهاء الحساب (مجموعة Azure Databricks) لتجنب الدفع مقابل الحساب عندما لا تحتاج إليه. يجب أن تكون مصادر الحوسبة (Azure Databricks) والتخزين في نفس المنطقة بحيث لا تواجه الوظائف زمن انتقال عال.
لإنشاء طوبولوجيا التعافي من الكوارث الإقليمية الخاصة بك، اتبع المتطلبات التالية:
توفير مساحات عمل Azure Databricks متعددة في مناطق Azure منفصلة. على سبيل المثال، إنشاء مساحة عمل Azure Databricks الأساسية في شرق الولايات المتحدة. إنشاء مساحة عمل Azure Databricks الثانوية للتعافي من الكوارث في منطقة منفصلة، مثل غرب الولايات المتحدة. للحصول على قائمة بمناطق Azure المقترنة، راجع النسخ المتماثل عبر المناطق. للحصول على تفاصيل حول مناطق Azure Databricks، راجع المناطق المدعومة.
استخدم التخزين المتكرر جغرافيا. بشكل افتراضي، يتم تخزين البيانات المقترنة ب Azure Databricks في Azure Storage ويتم تخزين النتائج من مهام Databricks في Azure Blob Storage، بحيث تكون البيانات المعالجة دائمة وتظل متوفرة بشكل كبير بعد إنهاء نظام المجموعة. يقع تخزين نظام المجموعة وتخزين الوظائف في نفس منطقة التوفر. للحماية من عدم التوفر الإقليمي، تستخدم مساحات عمل Azure Databricks التخزين المتكرر جغرافيا بشكل افتراضي. باستخدام التخزين المتكرر جغرافيا، يتم نسخ البيانات نسخا متماثلا إلى منطقة مقترنة ب Azure. توصي Databricks بالاحتفاظ بالتخزين المتكرر جغرافيا افتراضيا، ولكن إذا كنت بحاجة إلى استخدام التخزين المكرر محليا بدلا من ذلك، يمكنك التعيين
storageAccountSkuNameإلىStandard_LRSفي قالب ARM لمساحة العمل.بمجرد إنشاء المنطقة الثانوية، يجب ترحيل المستخدمين ومجلدات المستخدمين ودفاتر الملاحظات وتكوين نظام المجموعة وتكوين المهام والمكتبات والتخزين والبرامج النصية init وإعادة تكوين التحكم في الوصول. يتم توضيح تفاصيل إضافية في القسم التالي.
كارثة إقليمية
للتحضير للكوارث الإقليمية، تحتاج إلى الاحتفاظ بشكل صريح بمجموعة أخرى من مساحات عمل Azure Databricks في منطقة ثانوية. راجع التعافي من الكوارث.
أدواتنا الموصى بها للتعافي من الكوارث هي أساسا Terraform (للنسخ المتماثل للأشعة تحت الحمراء) وData Deep Clone (للنسخ المتماثل للبيانات).
خطوات الترحيل التفصيلية
إعداد واجهة سطر الأوامر Databricks على جهاز الكمبيوتر الخاص بك
تعرض هذه المقالة عددا من أمثلة التعليمات البرمجية التي تستخدم واجهة سطر الأوامر لمعظم الخطوات التلقائية، لأنها عبارة عن برنامج تضمين سهل للمستخدم عبر Azure Databricks REST API.
قبل تنفيذ أي خطوات ترحيل، قم بتثبيت databricks-cli على كمبيوتر سطح المكتب أو جهاز ظاهري حيث تخطط للقيام بالعمل. لمزيد من المعلومات، راجع تثبيت Databricks CLI
pip install databricks-cliإشعار
من المتوقع أن تعمل أي برامج نصية python متوفرة في هذه المقالة مع Python 2.7+ < 3.x.
تكوين ملفي تعريف.
تكوين واحد لمساحة العمل الأساسية، والآخر لمساحة العمل الثانوية:
databricks configure --profile primary --token databricks configure --profile secondary --tokenتقوم كتل التعليمات البرمجية في هذه المقالة بالتبديل بين ملفات التعريف في كل خطوة لاحقة باستخدام أمر مساحة العمل المقابل. تأكد من استبدال أسماء ملفات التعريف التي تقوم بإنشائها في كل كتلة تعليمات برمجية.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"يمكنك التبديل يدويا في سطر الأوامر إذا لزم الأمر:
databricks workspace ls --profile primary databricks workspace ls --profile secondaryترحيل مستخدمي Microsoft Entra ID (المعروف سابقا ب Azure Active Directory)
أضف يدويا نفس مستخدمي Microsoft Entra ID (المعروف سابقا باسم Azure Active Directory) إلى مساحة العمل الثانوية الموجودة في مساحة العمل الأساسية.
ترحيل مجلدات المستخدمين ودفاتر الملاحظات
استخدم التعليمات البرمجية python التالية لترحيل بيئات المستخدم المعزولة، والتي تتضمن بنية المجلد المتداخل ودفاتر الملاحظات لكل مستخدم.
إشعار
لا يتم نسخ المكتبات في هذه الخطوة، حيث لا تدعم واجهة برمجة التطبيقات الأساسية تلك.
انسخ البرنامج النصي python التالي واحفظه في ملف، ثم قم بتشغيله في سطر أوامر Databricks. على سبيل المثال،
python scriptname.pyimport sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "ls", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")ترحيل تكوينات نظام المجموعة
بمجرد ترحيل دفاتر الملاحظات، يمكنك ترحيل تكوينات نظام المجموعة اختياريا إلى مساحة العمل الجديدة. إنها خطوة تلقائية بالكامل تقريبا باستخدام databricks-cli، إلا إذا كنت ترغب في القيام بترحيل تكوين نظام المجموعة الانتقائي بدلا من الترحيل للجميع.
إشعار
لسوء الحظ لا توجد نقطة نهاية تكوين نظام المجموعة، ويحاول هذا البرنامج النصي إنشاء كل مجموعة على الفور. إذا لم تكن هناك ذاكرات أساسية كافية متوفرة في اشتراكك، فقد يفشل إنشاء نظام المجموعة. يمكن تجاهل الفشل، طالما تم نقل التكوين بنجاح.
البرنامج النصي التالي المقدم يطبع تعيينا من معرفات نظام المجموعة القديمة إلى الجديدة، والتي يمكن استخدامها لترحيل الوظيفة لاحقا (للوظائف التي تم تكوينها لاستخدام المجموعات الموجودة).
انسخ البرنامج النصي python التالي واحفظه في ملف، ثم قم بتشغيله في سطر أوامر Databricks. على سبيل المثال،
python scriptname.pyimport sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")). splitlines() print("Printting Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append (cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")ترحيل تكوين المهام
إذا قمت بترحيل تكوينات نظام المجموعة في الخطوة السابقة، يمكنك اختيار ترحيل تكوينات المهمة إلى مساحة العمل الجديدة. إنها خطوة مؤتمتة بالكامل باستخدام databricks-cli، إلا إذا كنت ترغب في القيام بترحيل تكوين وظيفة انتقائية بدلا من القيام بذلك لجميع الوظائف.
إشعار
يحتوي تكوين مهمة مجدولة على معلومات "الجدول" أيضا، لذلك بشكل افتراضي سيبدأ العمل وفقا للتوقيت المكون بمجرد ترحيله. ومن ثم، تقوم كتلة التعليمات البرمجية التالية بإزالة أي معلومات جدول أثناء الترحيل (لتجنب عمليات التشغيل المكررة عبر مساحات العمل القديمة والجديدة). قم بتكوين الجداول الزمنية لمثل هذه الوظائف بمجرد أن تصبح جاهزا للقطع.
يتطلب تكوين الوظيفة إعدادات لمجموعة جديدة أو موجودة. إذا كنت تستخدم نظام مجموعة موجود، سيحاول البرنامج النصي /التعليمات البرمجية أدناه استبدال معرف نظام المجموعة القديم بمعرف نظام المجموعة الجديد.
انسخ البرنامج النصي python التالي واحفظه في ملف. استبدل القيمة ل
old_cluster_idوnew_cluster_id، مع الإخراج من ترحيل نظام المجموعة الذي تم في الخطوة السابقة. قم بتشغيله في سطر الأوامر databricks-cli الخاص بك، على سبيل المثال،python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate ") + job job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id ") + job_req_settings_json['existing_cluster_id'] continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")ترحيل المكتبات
لا توجد حاليا طريقة مباشرة لترحيل المكتبات من مساحة عمل إلى أخرى. بدلا من ذلك، أعد تثبيت هذه المكتبات في مساحة العمل الجديدة يدويا. من الممكن أتمتة استخدام مجموعة من DBFS CLI لتحميل مكتبات مخصصة إلى مساحة العمل والمكتبات CLI.
ترحيل تخزين Azure blob وAzure Data Lake Storage
أعد تحميل جميع نقاط تحميل تخزين Azure Blob وAzure Data Lake Storage (Gen 2) يدويا باستخدام حل يستند إلى دفتر الملاحظات. كان سيتم تحميل موارد التخزين في مساحة العمل الأساسية، ويجب تكرار ذلك في مساحة العمل الثانوية. لا توجد واجهة برمجة تطبيقات خارجية للتركيبات.
ترحيل البرامج النصية ل init لنظام المجموعة
يمكن ترحيل أي برامج نصية لتهيئة نظام المجموعة من مساحة عمل قديمة إلى جديدة باستخدام DBFS CLI. أولا، انسخ البرامج النصية المطلوبة من
dbfs:/dat abricks/init/..إلى سطح المكتب المحلي أو الجهاز الظاهري. بعد ذلك، انسخ هذه البرامج النصية إلى مساحة العمل الجديدة في نفس المسار.// Primary to local dbfs cp -r dbfs:/databricks/init ./old-ws-init-scripts --profile primary // Local to Secondary workspace dbfs cp -r old-ws-init-scripts dbfs:/databricks/init --profile secondaryإعادة تكوين التحكم في الوصول وإعادة تطبيقه يدويا.
إذا تم تكوين مساحة العمل الأساسية الحالية لاستخدام طبقة Premium أو Enterprise (SKU)، فمن المحتمل أنك تستخدم أيضا عنصر التحكم في الوصول.
إذا كنت تستخدم عنصر التحكم في الوصول، فقم بإعادة تطبيق عنصر التحكم بالوصول يدويا على الموارد (دفاتر الملاحظات، المجموعات، المهام، الجداول).
التعافي من الكوارث لنظام Azure البيئي الخاص بك
إذا كنت تستخدم خدمات Azure الأخرى، فتأكد من تنفيذ أفضل ممارسات التعافي من الكوارث لتلك الخدمات أيضا. على سبيل المثال، إذا اخترت استخدام مثيل Hive metastore خارجي، فيجب مراعاة التعافي من الكوارث لقاعدة بيانات Azure SQL وAzure HDInsight و/أو قاعدة بيانات Azure ل MySQL. للحصول على معلومات عامة حول التعافي من الكوارث، راجع التعافي من الكوارث لتطبيقات Azure.
الخطوات التالية
لمزيد من المعلومات، راجع وثائق Azure Databricks.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ