إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
تم دمج Delta Lake بشكل عميق مع Spark Structured Streaming من خلال readStream و writeStream. تتغلب Delta Lake على العديد من القيود المرتبطة عادة بأنظمة البث والملفات، بما في ذلك:
- دمج الملفات الصغيرة التي ينتجها استيعاب زمن الانتقال المنخفض.
- الحفاظ على معالجة "مرة واحدة بالضبط" مع أكثر من دفق واحد (أو مهام دفعية متزامنة).
- اكتشاف الملفات الجديدة بكفاءة عند استخدام الملفات كمصدر للتدفق.
إشعار
توضح هذه المقالة استخدام جداول Delta Lake كمصادر تدفق ومتلقين. لمعرفة كيفية تحميل البيانات باستخدام جداول الدفق في Databricks SQL، راجع تحميل البيانات باستخدام جداول الدفق في Databricks SQL.
للحصول على معلومات حول الصلات الثابتة مع Delta Lake، راجع الصلات الثابتة للبث.
جدول Delta كمصدر
يقرأ الدفق المنظم جداول دلتا بشكل متزايد. بينما يكون استعلام الدفق نشطا مقابل جدول Delta، تتم معالجة السجلات الجديدة بشكل متكرر مع تثبيت إصدارات الجدول الجديدة بالجدول المصدر.
تظهر أمثلة التعليمات البرمجية التالية تكوين قراءة دفق باستخدام اسم الجدول أو مسار الملف.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
هام
إذا تغير مخطط جدول Delta بعد بدء قراءة الدفق مقابل الجدول، يفشل الاستعلام. بالنسبة لمعظم تغييرات المخطط، يمكنك إعادة تشغيل الدفق لحل عدم تطابق المخطط ومتابعة المعالجة.
في Databricks Runtime 12.2 LTS والإسفل، لا يمكنك البث من جدول Delta مع تمكين تعيين العمود الذي خضع لتطور مخطط غير إضافي مثل إعادة تسمية الأعمدة أو إسقاطها. للحصول على التفاصيل، راجع البث باستخدام تعيين العمود وتغييرات المخطط.
تحديد معدل الإدخال
تتوفر الخيارات التالية للتحكم في الدفعات الصغيرة:
maxFilesPerTrigger: كم عدد الملفات الجديدة التي سيتم النظر فيها في كل دفعة صغيرة. الافتراضي هو 1000.maxBytesPerTrigger: مقدار البيانات التي تتم معالجتها في كل دفعة صغيرة. يعين هذا الخيار "الحد الأقصى الناعم"، ما يعني أن الدفعة تعالج هذا القدر من البيانات تقريبا وقد تعالج أكثر من الحد لجعل استعلام الدفق يتحرك للأمام في الحالات التي تكون فيها أصغر وحدة إدخال أكبر من هذا الحد. لم يتم تعيين هذا بشكل افتراضي.
إذا كنت تستخدم maxBytesPerTrigger بالاقتران مع maxFilesPerTrigger، فإن الدفعة الصغيرة تعالج البيانات حتى يتم الوصول إلى الحد maxFilesPerTrigger أو maxBytesPerTrigger .
إشعار
في الحالات التي يتم فيها تنظيف معاملات الجدول المصدر بسبب logRetentionDuration التكوين ويحاول استعلام الدفق معالجة هذه الإصدارات، بشكل افتراضي يفشل الاستعلام في تجنب فقدان البيانات. يمكنك تعيين الخيار failOnDataLoss لتجاهل false البيانات المفقودة ومتابعة المعالجة.
دفق موجز التقاط بيانات تغيير Delta Lake (CDC)
تقوم Delta Lake بتغيير سجلات موجز البيانات إلى جدول Delta، بما في ذلك التحديثات والحذف. عند التمكين، يمكنك الدفق من موجز بيانات التغيير ومنطق الكتابة لمعالجة عمليات الإدراج والتحديثات والحذف في جداول انتقال البيانات من الخادم. على الرغم من أن تغيير إخراج بيانات موجز البيانات يختلف قليلا عن جدول Delta الذي يصفه، فإن هذا يوفر حلا لنشر التغييرات المتزايدة على جداول انتقال البيانات من الخادم في بنية الميدالية.
هام
في Databricks Runtime 12.2 LTS والإصدارات أدناه، لا يمكنك النقل المستمر من موجز بيانات التغيير لجدول Delta مع تمكين تعيين العمود الذي خضع لتطور مخطط غير إضافي مثل إعادة تسمية الأعمدة أو إسقاطها. راجع البث مع تعيين العمود وتغييرات المخطط.
تجاهل التحديثات والحذف
لا يعالج Structured Streaming الإدخال الذي ليس إلحاقا ويطرح استثناء إذا حدثت أي تعديلات على الجدول المستخدم كمصدر. هناك إستراتيجيتان رئيسيتان للتعامل مع التغييرات التي لا يمكن نشرها تلقائيا في المراحل النهائية:
- يمكنك حذف الإخراج ونقطة التحقق وإعادة تشغيل الدفق من البداية.
- يمكنك تعيين أي من هذين الخيارين:
ignoreDeletes: تجاهل المعاملات التي تحذف البيانات عند حدود القسم.skipChangeCommits: تجاهل المعاملات التي تحذف السجلات الموجودة أو تعدلها.skipChangeCommitsمجلدات فرعيةignoreDeletes.
إشعار
في Databricks Runtime 12.2 LTS وما فوق، skipChangeCommits يؤدي إلى إهمال الإعداد ignoreChangesالسابق . في Databricks Runtime 11.3 LTS والإقل، ignoreChanges هو الخيار الوحيد المدعوم.
تختلف دلالات إلى ignoreChanges حد كبير عن skipChangeCommits. مع ignoreChanges التمكين، تتم إعادة كتابة ملفات البيانات في الجدول المصدر بعد عملية تغيير البيانات مثل UPDATEأو MERGE INTOأو DELETE (داخل الأقسام) أو OVERWRITE. غالبا ما تنبعث الصفوف التي لم تتغير إلى جانب صفوف جديدة، لذلك يجب أن يكون المستهلكون في المراحل النهائية قادرين على التعامل مع التكرارات. لا يتم نشر عمليات الحذف في المراحل النهائية. ignoreChanges مجلدات فرعية ignoreDeletes.
skipChangeCommits يتجاهل عمليات تغيير الملفات بالكامل. يتم تجاهل ملفات البيانات التي تتم إعادة كتابتها في الجدول المصدر بسبب عملية تغيير البيانات مثل UPDATEو MERGE INTODELETEو OVERWRITE و بالكامل. لكي تعكس التغييرات في جداول المصدر، يجب تنفيذ منطق منفصل لنشر هذه التغييرات.
تستمر أحمال العمل المكونة مع ignoreChanges الاستمرار في العمل باستخدام دلالات معروفة، ولكن Databricks توصي باستخدام skipChangeCommits لجميع أحمال العمل الجديدة. يتطلب ترحيل أحمال العمل باستخدام ignoreChanges لإعادة skipChangeCommits بناء التعليمات البرمجية منطقا.
مثال
على سبيل المثال، افترض أن لديك جدولا user_events يحتوي user_emaildateعلى أعمدة و و action مقسمة حسب date. تقوم بالبث user_events من الجدول وتحتاج إلى حذف البيانات منه بسبب القانون العام لحماية البيانات (GDPR).
عند الحذف عند حدود القسم (أي، WHERE يكون على عمود قسم)، يتم تقسيم الملفات بالفعل حسب القيمة بحيث يقوم الحذف فقط بإسقاط هذه الملفات من بيانات التعريف. عند حذف قسم كامل من البيانات، يمكنك استخدام ما يلي:
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
إذا قمت بحذف البيانات في أقسام متعددة (في هذا المثال، التصفية على user_email)، فاستخدم بناء الجملة التالي:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
إذا قمت بتحديث user_email باستخدام العبارة UPDATE ، تتم إعادة كتابة الملف الذي يحتوي على user_email السؤال. استخدم skipChangeCommits لتجاهل ملفات البيانات التي تم تغييرها.
تحديد الموضع الأولي
يمكنك استخدام الخيارات التالية لتحديد نقطة البداية لمصدر تدفق Delta Lake دون معالجة الجدول بأكمله.
startingVersion: إصدار Delta Lake للبدء منه. توصي Databricks بحذف هذا الخيار لمعظم أحمال العمل. عند عدم التعيين، يبدأ الدفق من أحدث إصدار متوفر بما في ذلك لقطة كاملة من الجدول في تلك اللحظة.إذا تم تحديده، يقرأ الدفق جميع التغييرات على جدول Delta بدءا من الإصدار المحدد (شامل). إذا لم يعد الإصدار المحدد متوفرا، يفشل الدفق في البدء. يمكنك الحصول على إصدارات التثبيت من
versionعمود إخراج الأمر وصف محفوظات .لإرجاع أحدث التغييرات فقط، حدد
latest.startingTimestamp: الطابع الزمني للبدء منه. تتم قراءة جميع تغييرات الجدول التي تم إجراؤها في الطابع الزمني أو بعده (شاملة) من قبل قارئ البث. إذا كان الطابع الزمني المتوفر يسبق جميع عمليات تثبيت الجدول، تبدأ قراءة الدفق بأقرب طابع زمني متوفر. واحد من:- سلسلة طابع زمني. على سبيل المثال،
"2019-01-01T00:00:00.000Z" - سلسلة تاريخ. على سبيل المثال،
"2019-01-01"
- سلسلة طابع زمني. على سبيل المثال،
لا يمكنك تعيين كلا الخيارين في نفس الوقت. وهي لا تسري إلا عند بدء تشغيل استعلام تدفق جديد. إذا بدأ استعلام دفق وتم تسجيل التقدم في نقطة التحقق الخاصة به، يتم تجاهل هذه الخيارات.
هام
على الرغم من أنه يمكنك بدء تشغيل مصدر البث من إصدار محدد أو طابع زمني محدد، فإن مخطط مصدر الدفق هو دائما أحدث مخطط لجدول Delta. يجب التأكد من عدم وجود تغيير مخطط غير متوافق في جدول Delta بعد الإصدار أو الطابع الزمني المحدد. وإلا، فقد يرجع مصدر البث نتائج غير صحيحة عند قراءة البيانات بمخطط غير صحيح.
مثال
على سبيل المثال، افترض أن لديك جدول user_events. إذا كنت تريد قراءة التغييرات منذ الإصدار 5، فاستخدم:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
إذا كنت تريد قراءة التغييرات منذ 2018-10-18، فاستخدم:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
معالجة اللقطة الأولية دون إسقاط البيانات
عند استخدام جدول Delta كمصدر دفق، يعالج الاستعلام أولا جميع البيانات الموجودة في الجدول. يسمى جدول Delta في هذا الإصدار اللقطة الأولية. بشكل افتراضي، تتم معالجة ملفات بيانات جدول Delta استنادا إلى الملف الذي تم تعديله مؤخرا. ومع ذلك، لا يمثل وقت التعديل الأخير بالضرورة ترتيب وقت حدث السجل.
في استعلام دفق ذي حالة مع علامة مائية محددة، يمكن أن تؤدي معالجة الملفات حسب وقت التعديل إلى معالجة السجلات بترتيب خاطئ. قد يؤدي هذا إلى إسقاط السجلات كأحداث متأخرة بواسطة العلامة المائية.
يمكنك تجنب مشكلة إسقاط البيانات عن طريق تمكين الخيار التالي:
- withEventTimeOrder: ما إذا كان يجب معالجة اللقطة الأولية بترتيب وقت الحدث.
مع تمكين ترتيب وقت الحدث، يتم تقسيم النطاق الزمني للحدث لبيانات اللقطة الأولية إلى مستودعات زمنية. تعالج كل دفعة صغيرة مستودعا عن طريق تصفية البيانات ضمن النطاق الزمني. لا تزال خيارات تكوين maxFilesPerTrigger وmaxBytesPerTrigger قابلة للتطبيق للتحكم في حجم الميكروبات ولكن فقط بطريقة تقريبية بسبب طبيعة المعالجة.
يوضح الرسم أدناه هذه العملية:
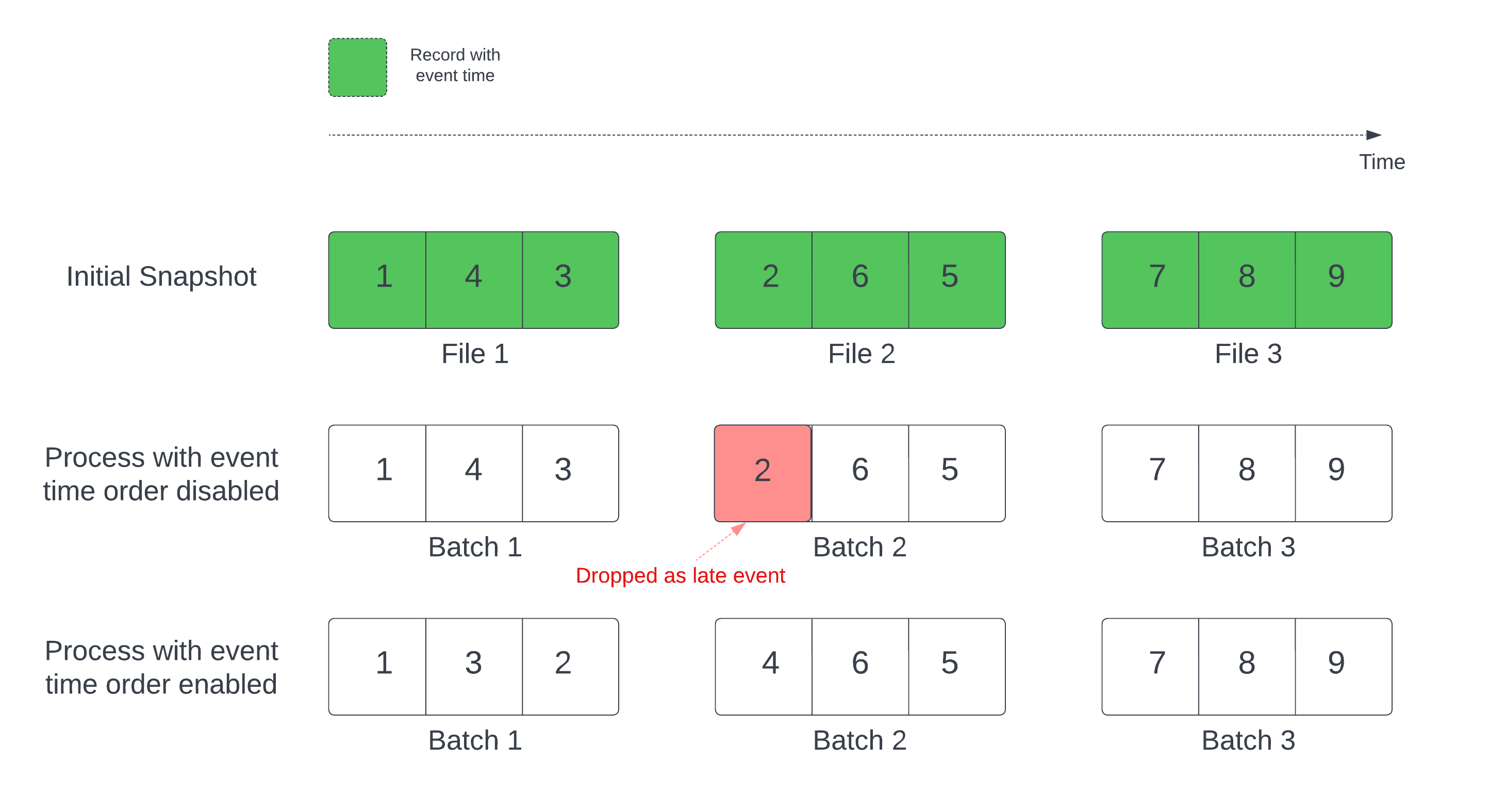
معلومات ملحوظة حول هذه الميزة:
- تحدث مشكلة إسقاط البيانات فقط عند معالجة لقطة دلتا الأولية لاستعلام دفق ذي حالة بالترتيب الافتراضي.
- لا يمكنك التغيير
withEventTimeOrderبمجرد بدء تشغيل استعلام الدفق أثناء معالجة اللقطة الأولية. لإعادة التشغيل معwithEventTimeOrderتغيير، تحتاج إلى حذف نقطة التحقق. - إذا كنت تقوم بتشغيل استعلام دفق مع تمكينEventTimeOrder، فلا يمكنك الرجوع إلى إصدار DBR الذي لا يدعم هذه الميزة حتى تكتمل معالجة اللقطة الأولية. إذا كنت بحاجة إلى الرجوع إلى إصدار أدنى، يمكنك الانتظار حتى تنتهي اللقطة الأولية، أو حذف نقطة التحقق وإعادة تشغيل الاستعلام.
- هذه الميزة غير معتمدة في السيناريوهات غير الشائعة التالية:
- عمود وقت الحدث هو عمود تم إنشاؤه وهناك تحويلات غير إسقاط بين مصدر دلتا والعلامة المائية.
- هناك علامة مائية تحتوي على أكثر من مصدر دلتا واحد في استعلام الدفق.
- مع تمكين ترتيب وقت الحدث، قد يكون أداء معالجة اللقطة الأولية دلتا أبطأ.
- تقوم كل دفعة صغيرة بفحص اللقطة الأولية لتصفية البيانات ضمن النطاق الزمني للحدث المقابل. لإجراء تصفية أسرع، ينصح باستخدام عمود مصدر Delta كوقت الحدث بحيث يمكن تطبيق تخطي البيانات (تحقق من تخطي البيانات ل Delta Lake عندما يكون قابلا للتطبيق). بالإضافة إلى ذلك، يمكن أن يؤدي تقسيم الجدول على طول عمود وقت الحدث إلى زيادة سرعة المعالجة. يمكنك التحقق من واجهة مستخدم Spark لمعرفة عدد ملفات دلتا التي يتم مسحها ضوئيا لدفعة صغيرة معينة.
مثال
لنفترض أن لديك جدولا user_events يحتوي على event_time عمود. استعلام البث الخاص بك هو استعلام تجميع. إذا كنت تريد التأكد من عدم انخفاض البيانات أثناء معالجة اللقطة الأولية، يمكنك استخدام:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
إشعار
يمكنك أيضا تمكين هذا مع تكوين Spark على نظام المجموعة الذي سيتم تطبيقه على جميع استعلامات الدفق: spark.databricks.delta.withEventTimeOrder.enabled true
جدول Delta كمتلقي
يمكنك أيضا كتابة البيانات في جدول Delta باستخدام Structured Streaming. يمكن سجل المعاملات Delta Lake من ضمان المعالجة مرة واحدة بالضبط، حتى عندما تكون هناك تدفقات أو استعلامات دفعية أخرى تعمل بشكل متزامن مقابل الجدول.
إشعار
تزيل دالة Delta Lake VACUUM جميع الملفات التي لا تديرها Delta Lake ولكنها تتخطى أي دلائل تبدأ ب _. يمكنك تخزين نقاط التحقق بأمان جنبا إلى جنب مع بيانات وبيانات التعريف الأخرى لجدول Delta باستخدام بنية دليل مثل <table-name>/_checkpoints.
المقاييس
يمكنك معرفة عدد وحدات البايت وعدد الملفات التي لم تتم معالجتها بعد في عملية استعلام دفق كمقياسين numBytesOutstanding و numFilesOutstanding . تتضمن المقاييس الإضافية ما يلي:
numNewListedFiles: عدد ملفات Delta Lake التي تم سردها لحساب تراكم هذه الدفعة.backlogEndOffset: إصدار الجدول المستخدم لحساب التراكم.
إذا كنت تقوم بتشغيل الدفق في دفتر ملاحظات، يمكنك مشاهدة هذه المقاييس ضمن علامة التبويب البيانات الأولية في لوحة معلومات تقدم الاستعلام المتدفق:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
وضع الإلحاق
يتم تشغيل عمليات الدفق بشكل افتراضي في وضع الإلحاق، الذي يضيف سجلات جديدة إلى الجدول.
toTable استخدم الأسلوب عند البث إلى الجداول، كما في المثال التالي:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
الوضع الكامل
يمكنك أيضا استخدام Structured Streaming لاستبدال الجدول بأكمله بكل دفعة. مثال واحد على حالة الاستخدام هو حساب ملخص باستخدام التجميع:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
يحدث المثال السابق باستمرار جدولا يحتوي على العدد الإجمالي للأحداث حسب العميل.
بالنسبة للتطبيقات ذات متطلبات زمن الانتقال الأكثر تساهلا، يمكنك حفظ موارد الحوسبة باستخدام مشغلات لمرة واحدة. استخدم هذه لتحديث جداول تجميع الملخصات في جدول زمني معين، ومعالجة البيانات الجديدة التي وصلت فقط منذ التحديث الأخير.
Upsert من تدفق الاستعلامات باستخدام foreachBatch
يمكنك استخدام مزيج من merge وكتابة foreachBatch upserts المعقدة من استعلام دفق إلى جدول Delta. راجع استخدام foreachBatch للكتابة إلى متلقي البيانات العشوائية.
يحتوي هذا النمط على العديد من التطبيقات، بما في ذلك ما يلي:
- كتابة تجميعات الدفق في "وضع التحديث": هذا أكثر كفاءة بكثير من "وضع الإكمال".
- كتابة دفق تغييرات قاعدة البيانات في جدول Delta: يمكن استخدام استعلام الدمج لكتابة بيانات التغيير لتطبيق دفق من التغييرات باستمرار على جدول
foreachBatchDelta. - كتابة دفق من البيانات في جدول Delta مع إلغاء التكرار: يمكن استخدام
foreachBatchاستعلام الدمج للإدراج فقط لإلغاء التكرار لكتابة البيانات باستمرار (مع التكرارات) إلى جدول Delta مع إلغاء التكرار التلقائي.
إشعار
- تأكد من أن عبارة
foreachBatchداخل غيرmergeمتكررة حيث يمكن لإعادة تشغيل استعلام الدفق تطبيق العملية على نفس الدفعة من البيانات عدة مرات. - عند
mergeاستخدام فيforeachBatch، قد يتم الإبلاغ عن معدل بيانات الإدخال للاستعلام المتدفق (يتم الإبلاغ عنه من خلالStreamingQueryProgressالرسم البياني لمعدل دفتر الملاحظات) كمضاعف للمعدل الفعلي الذي يتم فيه إنشاء البيانات في المصدر. وذلك لأنmergeيقرأ بيانات الإدخال عدة مرات مما يتسبب في ضرب مقاييس الإدخال. إذا كان هذا ازدحاما، يمكنك تخزين DataFrame الدفعي مؤقتا قبلmergeثم فكه بعدmerge.
يوضح المثال التالي كيف يمكنك استخدام SQL داخل foreachBatch لإنجاز هذه المهمة:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
يمكنك أيضا اختيار استخدام واجهات برمجة تطبيقات Delta Lake لإجراء عمليات رفع البث، كما في المثال التالي:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
يكتب الجدول غير الفعال في foreachBatch
إشعار
توصي Databricks بتكوين كتابة دفق منفصلة لكل متلقي ترغب في تحديثه. يؤدي استخدام foreachBatch للكتابة إلى جداول متعددة إلى تسلسل عمليات الكتابة، ما يقلل من التوازي ويزيد من زمن الانتقال الكلي.
تدعم جداول Delta الخيارات التالية DataFrameWriter لإجراء عمليات الكتابة إلى جداول متعددة ضمن foreachBatch غير متكرر:
txnAppId: سلسلة فريدة يمكنك تمريرها على كل كتابة DataFrame. على سبيل المثال، يمكنك استخدام معرف StreamingQuery كtxnAppId.txnVersion: رقم متزايد بشكل رتيبة يعمل كنسخة معاملة.
يستخدم Delta Lake الجمع بين txnAppId و txnVersion لتحديد الكتابات المكررة وتجاهلها.
إذا تمت مقاطعة كتابة دفعة مع فشل، فإن إعادة تشغيل الدفعة تستخدم نفس التطبيق ومعرف الدفعة لمساعدة وقت التشغيل على تحديد عمليات الكتابة المكررة وتجاهلها بشكل صحيح. يمكن أن يكون معرف التطبيق (txnAppId) أي سلسلة فريدة أنشأها المستخدم ولا يجب أن يكون مرتبطا بمعرف الدفق. راجع استخدام foreachBatch للكتابة إلى متلقي البيانات العشوائية.
تحذير
إذا قمت بحذف نقطة التحقق المتدفقة وإعادة تشغيل الاستعلام باستخدام نقطة تحقق جديدة، يجب توفير .txnAppId تبدأ نقاط التحقق الجديدة بمعرف دفعة من 0. يستخدم Delta Lake معرف الدفعة ومفتاحا txnAppId فريدا، ويتخطى الدفعات ذات القيم التي تمت رؤيتها بالفعل.
يوضح مثال التعليمات البرمجية التالي هذا النمط:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}