إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
توضح هذه المقالة مرئيات Azure Databricks القديمة. راجع المرئيات في دفاتر ملاحظات Databricks للحصول على دعم المرئيات الحالي.
يدعم Azure Databricks أيضا مكتبات المرئيات في Python وR ويسمح لك بتثبيت مكتبات الجهات الخارجية واستخدامها.
إنشاء مرئيات قديمة
لإنشاء مرئيات قديمة من خلية نتائج، انقر فوق + "Legacy Visualization" وحددها.
تدعم المرئيات القديمة مجموعة غنية من أنواع المخططات:
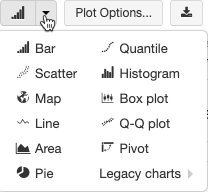
اختيار نوع مخطط قديم وتكوينه
لاختيار مخطط شريطي، انقر فوق أيقونة  المخطط الشريطي :
المخطط الشريطي :
لاختيار نوع رسم آخر، انقر على ![]() يمين المخطط الشريطي واختر نوع الرسم.
يمين المخطط الشريطي واختر نوع الرسم.
شريط أدوات المخطط القديم
يحتوي كل من المخططات الخطية والشريطية على شريط أدوات مضمن يدعم مجموعة غنية من التفاعلات من جانب العميل.
لتكوين مخطط، انقر فوق خيارات الرسم....
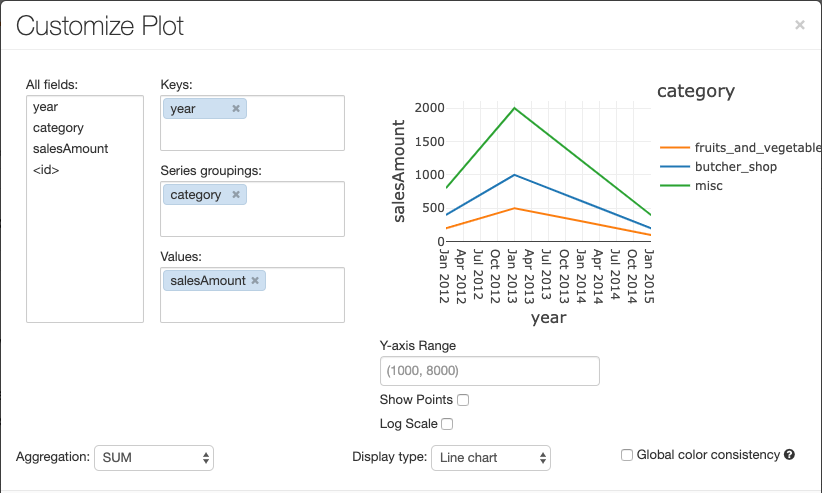
يحتوي المخطط الخطي على بعض خيارات المخطط المخصص: تعيين نطاق محور Y، وإظهار النقاط وإخفائها، وعرض المحور Y بمقياس سجل.
للحصول على معلومات حول أنواع المخططات القديمة، راجع:
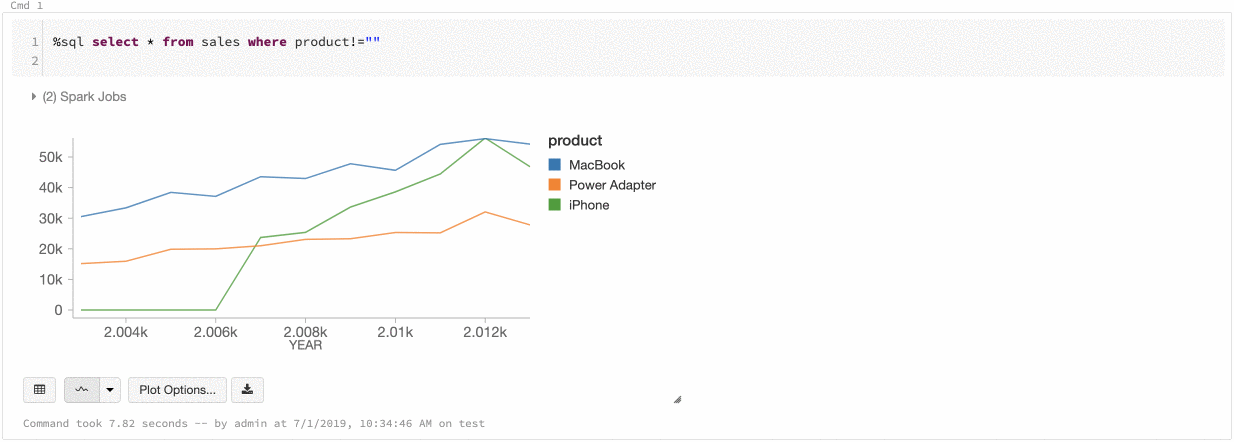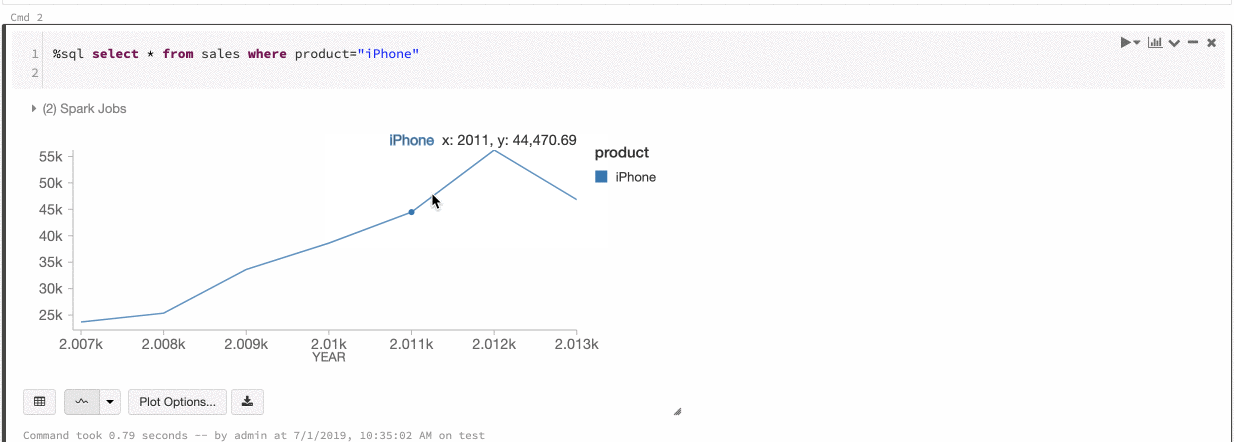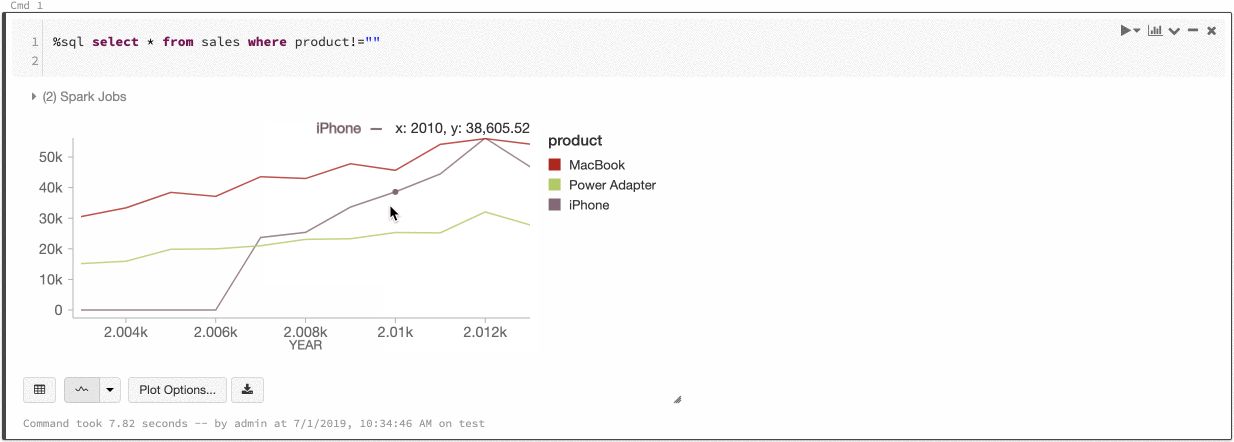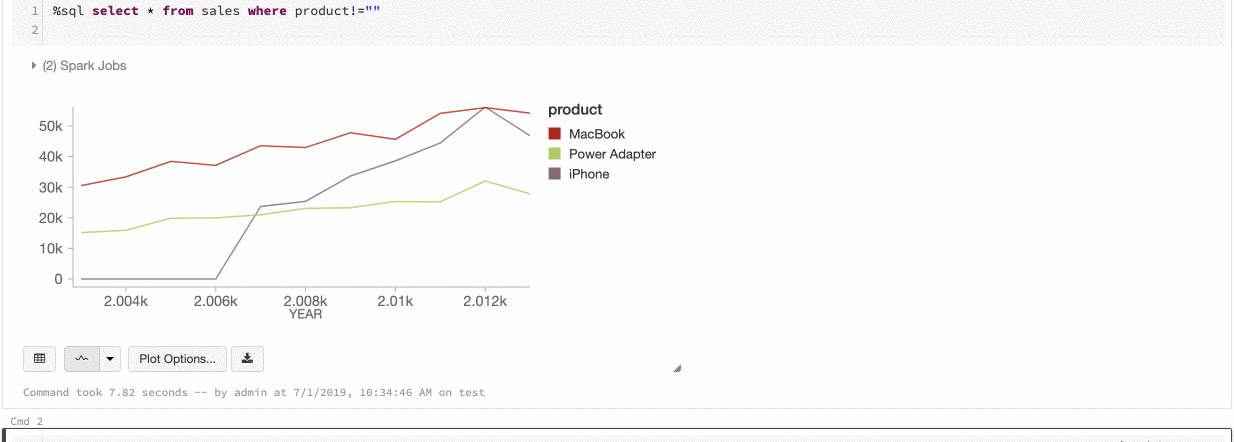
تناسق الألوان عبر المخططات
يدعم Azure Databricks نوعين من تناسق الألوان عبر المخططات القديمة: مجموعة السلاسل والمخططات العمومية.
يقوم تناسق ألوان مجموعة السلاسل بتعيين نفس اللون لنفس القيمة إذا كان لديك سلسلة بنفس القيم ولكن في أوامر مختلفة (على سبيل المثال، A = ["Apple", "Orange", "Banana"] وB = ["Orange", "Banana", "Apple"]). يتم فرز القيم قبل الرسم، لذلك يتم فرز وسيلتي الإيضاح بنفس الطريقة (["Apple", "Banana", "Orange"])، ويتم إعطاء نفس القيم الألوان نفسها. ومع ذلك، إذا كان لديك سلسلة C = ["Orange", "Banana"]، فلن يكون اللون متناسقا مع المجموعة A لأن المجموعة ليست هي نفسها. ستقوم خوارزمية الفرز بتعيين اللون الأول إلى "موز" في المجموعة C ولكن اللون الثاني إلى "موز" في المجموعة A. إذا كنت تريد أن تكون هذه السلسلة متناسقة مع الألوان، يمكنك تحديد أن المخططات يجب أن تحتوي على تناسق ألوان عمومي.
في تناسق الألوان العمومية ، يتم تعيين كل قيمة دائما إلى نفس اللون بغض النظر عن القيم التي تحتويها السلسلة. لتمكين هذا لكل مخطط، حدد خانة الاختيار تناسق اللون العمومي.
إشعار
لتحقيق هذا التناسق، يتم تجزئة Azure Databricks مباشرة من القيم إلى الألوان. لتجنب الاصطدامات (حيث تذهب قيمتان إلى اللون نفسه بالضبط)، فإن التجزئة هي لمجموعة كبيرة من الألوان، والتي لها تأثير جانبي لا يمكن ضمان الألوان الجميلة المظهر أو التي يمكن تمييزها بسهولة؛ مع العديد من الألوان هناك لا بد أن يكون بعض التي هي مشابهة جدا تبحث.
مرئيات التعلم الآلي
بالإضافة إلى أنواع المخططات القياسية، تدعم المرئيات القديمة معلمات ونتائج التدريب على التعلم الآلي التالية:
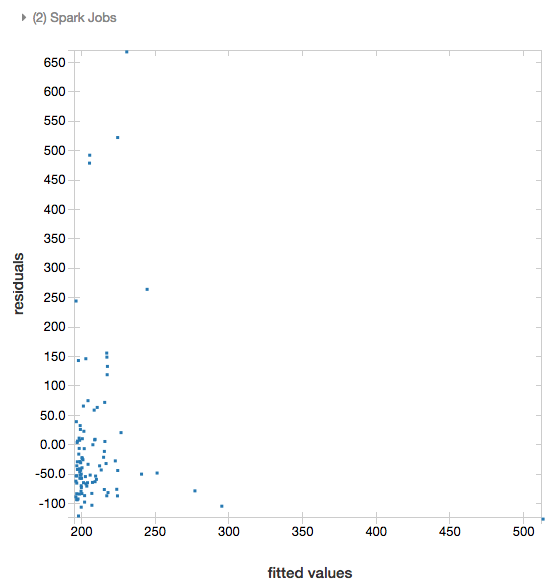
المخلفات
بالنسبة للتراجعات الخطية واللوجستية، يمكنك تقديم مخطط ملائم مقابل رسم متبق . للحصول على هذا المخطط، قم بتوفير النموذج وDataFrame.
يقوم المثال التالي بتشغيل انحدار خطي على سكان المدينة لإيواء بيانات سعر البيع ثم يعرض القيم المتبقية مقابل البيانات المجهزة.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
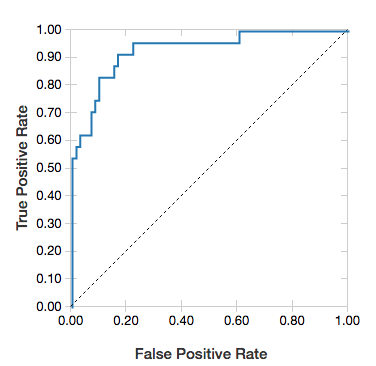
منحنيات ROC
بالنسبة للتراجعات اللوجستية، يمكنك تقديم منحنى ROC . للحصول على هذا الرسم، قم بتوفير النموذج والبيانات المعدة مسبقا التي هي إدخال إلى fit الأسلوب والمعلمة "ROC".
يطور المثال التالي مصنفا يتنبأ بما إذا كان الفرد يكسب <=50 ألف أو >50 ألف في السنة من سمات مختلفة للفرد. تستمد مجموعة بيانات البالغين من بيانات التعداد، وتتألف من معلومات حول 48842 فردا ودخلهم السنوي.
يستخدم مثال التعليمات البرمجية في هذا القسم ترميزا واحدا ساخنا.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
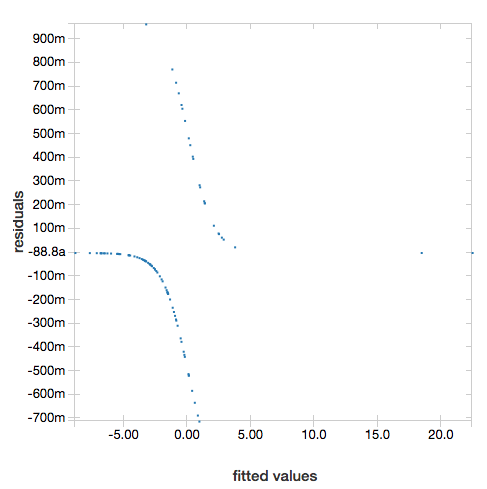
لعرض القيم المتبقية، احذف المعلمة "ROC" :
display(lrModel, preppedDataDF)
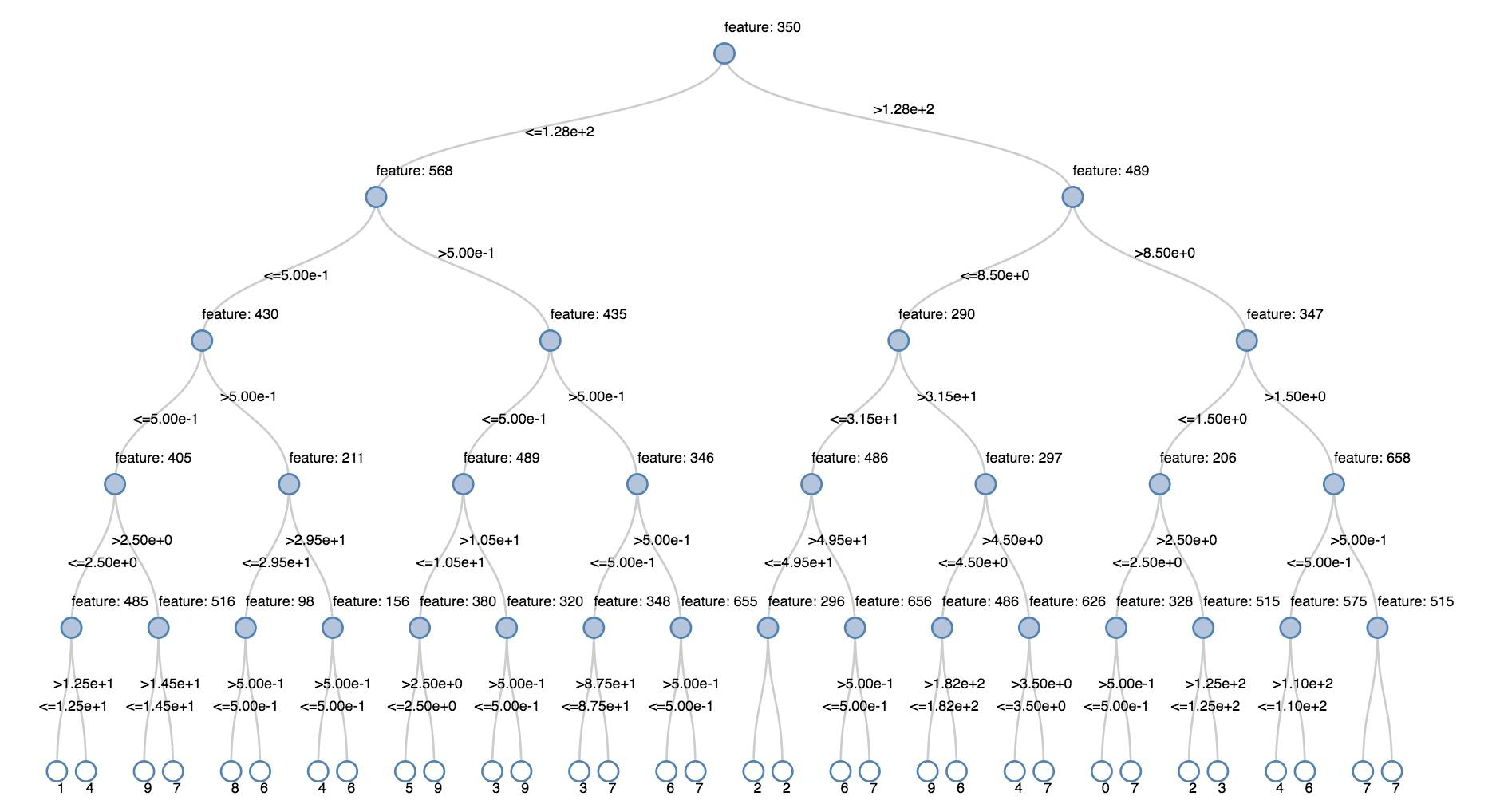
أشجار القرار
تدعم المرئيات القديمة عرض شجرة قرارات.
للحصول على هذا التصور، قم بتوفير نموذج شجرة القرار.
تقوم الأمثلة التالية بتدريب شجرة للتعرف على الأرقام (0 - 9) من مجموعة بيانات MNIST لصور الأرقام المكتوبة بخط اليد ثم تعرض الشجرة.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
إطارات البيانات المتدفقة المنظمة
لتصور نتيجة استعلام الدفق في الوقت الحقيقي، يمكنك display Structured Streaming DataFrame في Scala وPython.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display يدعم المعلمات الاختيارية التالية:
streamName: اسم استعلام البث.trigger(Scala) وprocessingTime(Python): يحدد عدد المرات التي يتم فيها تشغيل استعلام الدفق. إذا لم يتم تحديده، يتحقق النظام من توفر البيانات الجديدة بمجرد اكتمال المعالجة السابقة. لتقليل التكلفة في الإنتاج، توصي Databricks بتعيين فاصل زمني للمشغل دائما . الفاصل الزمني الافتراضي للمشغل هو 500 مللي ثانية.checkpointLocation: الموقع الذي يكتب فيه النظام جميع معلومات نقطة التحقق. إذا لم يتم تحديده، يقوم النظام تلقائيا بإنشاء موقع نقطة تفتيش مؤقت على DBFS. لكي يستمر الدفق في معالجة البيانات من حيث توقفت، يجب توفير موقع نقطة تحقق. توصي Databricks بتحديد الخيار دائماcheckpointLocationفي الإنتاج.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
لمزيد من المعلومات حول هذه المعلمات، راجع بدء تشغيل استعلامات الدفق.
displayHTML دالة
تدعم دفاتر ملاحظات لغة البرمجة Azure Databricks (Python وR وSca) رسومات HTML باستخدام الدالة displayHTML ؛ يمكنك تمرير أي تعليمة برمجية HTML أو CSS أو JavaScript. تدعم هذه الدالة الرسومات التفاعلية باستخدام مكتبات JavaScript مثل D3.
للحصول على أمثلة لاستخدام displayHTML، راجع:
إشعار
displayHTML يتم تقديم iframe من المجال databricksusercontent.com، وتتضمن بيئة الاختبار المعزولة iframe السمة allow-same-origin . databricksusercontent.com يجب أن يكون الوصول إليها من المستعرض الخاص بك. إذا كانت شبكة شركتك محظورة حاليا، فيجب إضافتها إلى قائمة السماح.
الصور
يتم عرض الأعمدة التي تحتوي على أنواع بيانات الصور بتنسيق HTML منسق. يحاول Azure Databricks عرض الصور المصغرة للصور للأعمدة DataFrame المطابقة ل Spark ImageSchema.
يعمل عرض الصور المصغرة لأي صور تمت قراءتها بنجاح من خلال الدالة spark.read.format('image') . بالنسبة لقيم الصور التي تم إنشاؤها من خلال وسائل أخرى، يدعم Azure Databricks عرض 1 أو 3 أو 4 صور قناة (حيث تتكون كل قناة من بايت واحد)، مع القيود التالية:
- صور قناة واحدة:
modeيجب أن يكون الحقل مساويا ل 0.heightwidthيجب أن تصف الحقول و وnChannelsبدقة بيانات الصورة الثنائية فيdataالحقل. - صور من ثلاث قنوات:
modeيجب أن يكون الحقل مساويا ل 16.heightwidthيجب أن تصف الحقول و وnChannelsبدقة بيانات الصورة الثنائية فيdataالحقل.dataيجب أن يحتوي الحقل على بيانات بكسل في مجموعات ثلاثية البايت، مع ترتيب القناة(blue, green, red)لكل بكسل. - صور من أربع قنوات:
modeيجب أن يكون الحقل مساويا ل 24.heightwidthيجب أن تصف الحقول و وnChannelsبدقة بيانات الصورة الثنائية فيdataالحقل.dataيجب أن يحتوي الحقل على بيانات بكسل في مجموعات من أربعة بايت، مع ترتيب القناة(blue, green, red, alpha)لكل بكسل.
مثال
لنفترض أن لديك مجلدا يحتوي على بعض الصور:

إذا قرأت الصور في DataFrame ثم عرضت DataFrame، فإن Azure Databricks تعرض الصور المصغرة للصور:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

المرئيات في Python
في هذا القسم:
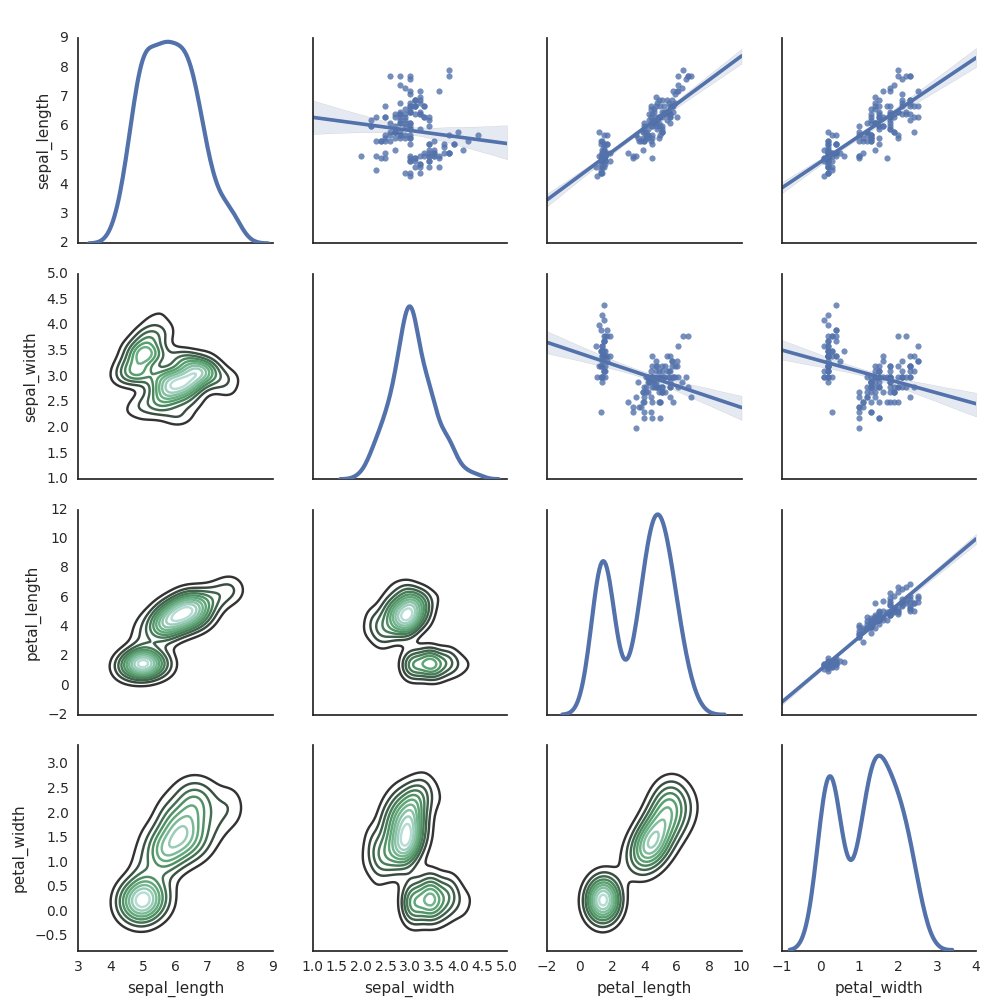
سيبورن
يمكنك أيضا استخدام مكتبات Python الأخرى لإنشاء مخططات. يتضمن Databricks Runtime مكتبة المرئيات البحرية . لإنشاء مخطط بحر، قم باستيراد المكتبة، وإنشاء مخطط، وتمرير المخطط إلى الدالة display .
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
مكتبات Python الأخرى
المرئيات في R
لرسم البيانات في R، استخدم الدالة display كما يلي:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
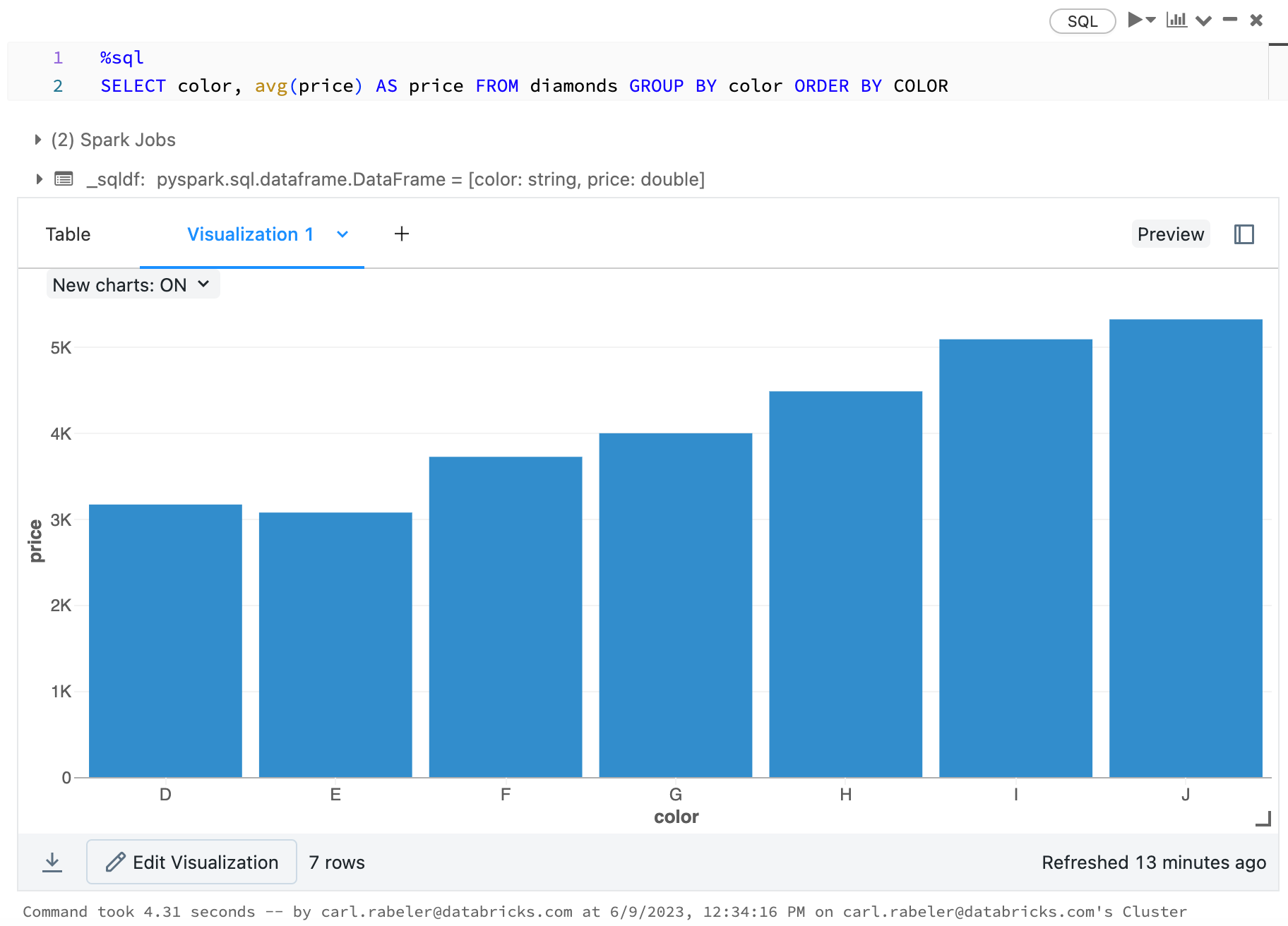
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
يمكنك استخدام دالة رسم R الافتراضية.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
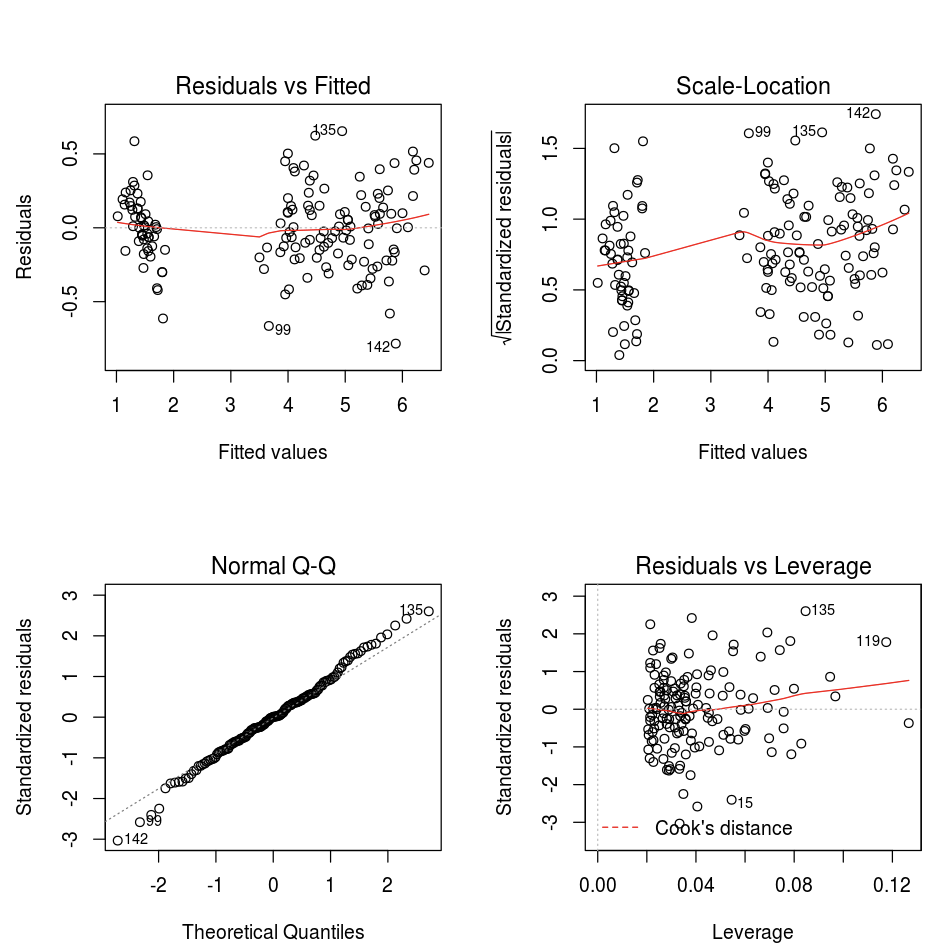
يمكنك أيضا استخدام أي حزمة مرئيات R. يلتقط دفتر ملاحظات R الرسم الناتج ك .png ويعرضه مضمنا.
في هذا القسم:
lattice
تدعم حزمة Lattice الرسوم البيانية trellis - الرسوم البيانية التي تعرض متغيرا أو العلاقة بين المتغيرات، والمكيفة على متغير واحد أو أكثر.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
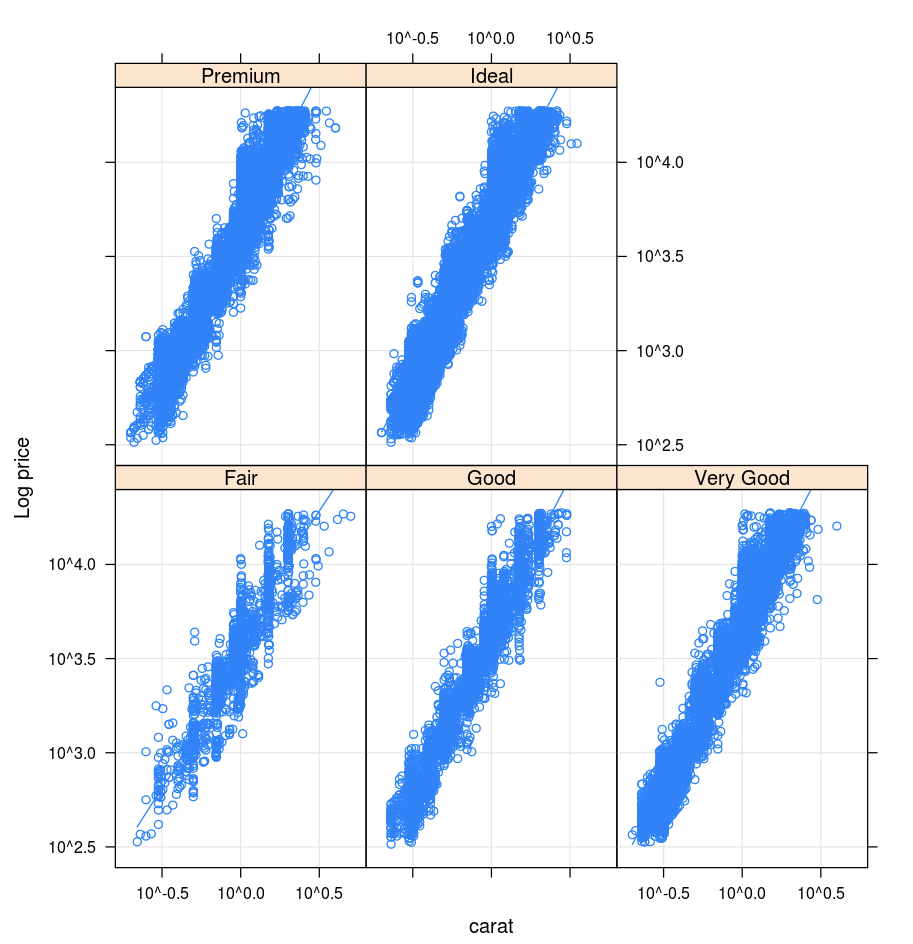
DandEFA
تدعم حزمة DandEFA مخططات الهندباء.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
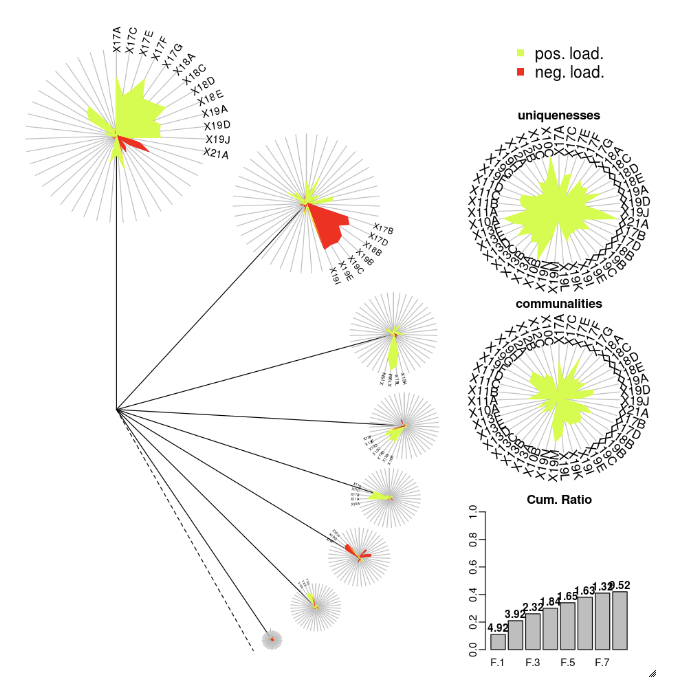
Plotly
تعتمد حزمة Plotly R على htmlwidgets ل R. للحصول على إرشادات التثبيت ودفتر ملاحظات، راجع htmlwidgets.
مكتبات R الأخرى
المرئيات في Scala
لرسم البيانات في Scala، استخدم الدالة display كما يلي:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
دفاتر ملاحظات الغوص العميق ل Python وSc scala
للتعمق في مرئيات Python، راجع دفتر الملاحظات:
للتعمق في مرئيات Scala، راجع دفتر الملاحظات: