قم بالوصول إلى سجلات تطبيق Apache Hadoop YARN على HDInsight المستند إلى Linux
تعرف على كيفية الوصول إلى سجلات تطبيقات Apache Hadoop YARN (مفاوض موارد آخر) على مجموعة Apache Hadoop في Azure HDInsight.
ما هو Apache YARN؟
يدعم YARN نماذج برمجة متعددة (يعد Apache Hadoop MapReduce أحدها) عن طريق فصل إدارة الموارد عن جدولة/مراقبة التطبيق. يستخدم YARN ResourceManager (RM) عالمياً NodeManagers (NMs) لكل عامل ApplicationMasters لكل تطبيق (AMs). يتفاوض AM لكل تطبيق على الموارد (وحدة المعالجة المركزية، والذاكرة، والقرص، والشبكة) لتشغيل التطبيق الخاص بك مع RM. يعمل RM مع NMs لمنح هذه الموارد، والتي يتم منحها كـ حاويات. تعد AM مسؤولة عن تتبع تقدم الحاويات المعينة لها من قِبل RM. قد يتطلب التطبيق العديد من الحاويات حسب طبيعة التطبيق.
قد يتكون كل تطبيق من عدة محاولات تطبيق. إذا فشل أحد التطبيقات، فقد يتم إعادة المحاولة كمحاولة جديدة. كل محاولة تعمل في حاوية. بمعنى ما، توفر الحاوية سياق وحدة العمل الأساسية التي يقوم بها تطبيق YARN. يتم تنفيذ جميع الأعمال التي يتم إجراؤها في سياق الحاوية على عقدة العامل الفردية التي تم توفير الحاوية عليها. راجع Hadoop: كتابة تطبيقات YARN، أو Apache Hadoop YARN لمزيد من المراجع.
لتوسيع نطاق مجموعتك لدعم إنتاجية معدل نقل أكبر، يمكنك استخدام مقياس تلقائي أو قياس مجموعاتك يدوياً باستخدام عدة لغات مختلفة.
خادم الجدول الزمني YARN
يوفر Apache Hadoop YARN Timeline Server معلومات عامة عن التطبيقات المكتملة
يتضمن YARN Timeline Server النوع التالي من البيانات:
- معرف التطبيق، معرف فريد للتطبيق
- المستخدم الذي بدأ التطبيق
- معلومات عن محاولات إكمال الطلب
- الحاويات المستخدمة من قِبل أي محاولة تطبيق معينة
تطبيقات وسجلات YARN
تعد سجلات التطبيق (وسجلات الحاوية المرتبطة) بالغة الأهمية في تصحيح أخطاء تطبيقات Hadoop التي تحدث المشكلات. يوفر YARN إطاراً رائعاً لجمع وتجميع وتخزين سجلات التطبيق باستخدام تجميع السجل.
تجعل ميزة تجميع السجلات الوصول إلى سجلات التطبيق أكثر حتمية. يتم تجميع السجلات عبر تجميع الحاويات على عقدة عامل وتخزينها كملف سجل مجمع واحد لكل عقدة عامل. يتم تخزين السجل على نظام الملفات الافتراضي بعد انتهاء التطبيق. قد يستخدم تطبيقك مئات أو آلاف الحاويات، ولكن يتم دائماً تجميع سجلات جميع الحاويات التي يتم تشغيلها على عقدة عاملة واحدة في ملف واحد. لذلك هناك سجل واحد فقط لكل عقدة عامل يستخدمها التطبيق الخاص بك. يتم تمكين تجميع السجل افتراضياً على مجموعات HDInsight الإصدار 3.0 وما بعده. توجد السجلات المجمعة في التخزين الافتراضي للمجموعة. المسار التالي هو مسار HDFS إلى السجلات:
/app-logs/<user>/logs/<applicationId>
المسار، user هو اسم المستخدم الذي بدأ التطبيق. applicationId هو المعرف الفريد المعين للتطبيق بواسطة YARN RM.
السجلات المجمعة غير قابلة للقراءة مباشرة، لأنها مكتوبة TFileبتنسيق ثنائي مفهرس بواسطة الحاوية. استخدم سجلات YARN ResourceManager أو أدوات CLI لعرض هذه السجلات كنص عادي للتطبيقات أو الحاويات ذات الأهمية.
سجلات الغزل في مجموعة ESP
يجب إضافة تكوينين إلى mapred-site المخصص في Ambari.
من متصفح ويب، انتقل إلى
https://CLUSTERNAME.azurehdinsight.net، حيثCLUSTERNAMEهو اسم نظام المجموعة.من Ambari UI، انتقل إلى MapReduce2>Configs>>Custom mapred-site.
أضف واحدة من مجموعات الخصائص التالية:
المجموعة 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*المجموعة 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>احفظ التغييرات وأعد تشغيل جميع الخدمات المتأثرة.
أدوات YARN CLI
استخدم الأمر ssh للاتصال بنظام المجموعة الخاص بك. قم بتحرير الأمر التالي عن طريق استبدال CLUSTERNAME باسم نظام المجموعة الخاص بك، ثم أدخل الأمر :
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netأدرج جميع معرفات التطبيقات الخاصة بتطبيقات Yarn قيد التشغيل حالياً باستخدام الأمر التالي:
yarn topلاحظ معرّف التطبيق من العمود
APPLICATIONIDالذي سيتم تنزيل سجلاته.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC Serverيمكنك عرض هذه السجلات كنص عادي عن طريق تشغيل أحد الأوامر التالية:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>حدد معلومات <applicationId> و<user-who-started-the-application> و<containerId> و<worker-node-address> عند تشغيل هذه أوامر.
أوامر عينة أخرى
قم بتنزيل سجلات حاويات Yarn لجميع التطبيقات الرئيسية باستخدام الأمر التالي. تنشئ هذه الخطوة ملف السجل المسمى
amlogs.txtبتنسيق نصي.yarn logs -applicationId <application_id> -am ALL > amlogs.txtقم بتنزيل سجلات حاوية Yarn لأحدث تطبيق رئيسي فقط باستخدام الأمر التالي:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtقم بتنزيل سجلات حاوية YARN لأول تطبيقين رئيسيين باستخدام الأمر التالي:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtقم بتنزيل جميع سجلات حاوية Yarn باستخدام الأمر التالي:
yarn logs -applicationId <application_id> > logs.txtقم بتنزيل سجل حاوية الغزل لحاوية معينة باستخدام الأمر التالي:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
واجهة ResourceManager المستخدم للغزل
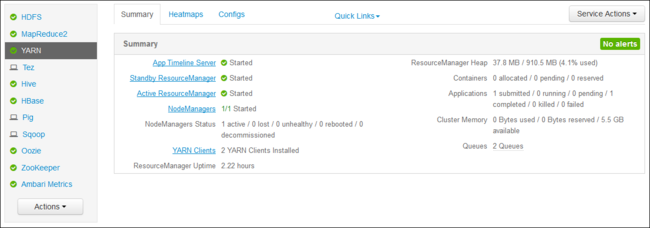
تعمل واجهة مستخدم YARN ResourceManager على العقدة الرئيسية للمجموعة. يتم الوصول إليه من خلال واجهة مستخدم ويب Ambari. استخدم الخطوات التالية لعرض سجلات YARN:
في متصفح الويب لديك، انتقل إلى
https://CLUSTERNAME.azurehdinsight.net. استبدل CLUSTERNAME باسم مجموعة HDInsight الخاصة بك.من قائمة الخدمات على اليسار، حدد YARN.
من القائمة المنسدلة روابط سريعة، حدد واحداً من عُقد رأس نظام المجموعة ثم حدد
ResourceManager Log.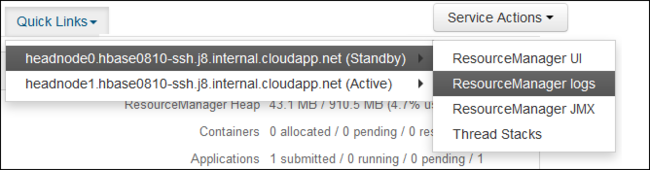
يتم تقديمك بقائمة من الروابط إلى سجلات YARN.
الخطوات التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ