ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
عمليات البنية الأساسية لبرنامج ربط العمليات التجارية للبيانات تكشف عن العديد من حلول التحليلات للبيانات. كما يوحي الاسم، تأخذ البنية الأساسية لبرنامج ربط العمليات التجارية البيانات الأولية، وتنظفها، وتعيد تشكيلها حسب الحاجة، ثم تقوم بإجراء الحسابات أو التجميعات بشكل نموذجي قبل تخزين البيانات المعالجة. يستهلك العملاء أو التقارير أو واجهات برمجة التطبيقات البيانات المعالجة. يجب أن توفر البنية الأساسية لبرنامج ربط العمليات التجارية بيانات نتائج قابلة للتكرار، سواء في جدول زمني أو عند تشغيلها من البيانات الجديدة.
توضح هذه المقالة كيفية تشغيل عمليات البنية الأساسية لبرنامج ربط العمليات التجارية بالبيانات الخاصة بك للتكرار، وذلك باستخدام Oozie الذي يعمل على أنظمة مجموعات HDInsight Hadoop. سيناريو المثال يرشدك عبر البنية الأساسية لبرنامج ربط العمليات التجارية ببيانات تقوم بإعداد بيانات السلسلة الزمنية لرحلة الطيران ومعالجتها.
في السيناريو التالي، بيانات الإدخال ما هي إلا ملف ثابت يحتوي على دُفعة من بيانات الطيران لمدة شهر واحد. تتضمن بيانات الرحلة هذه معلومات مثل مطار المنشأ والوجهة، والأميال المقطوعة جواً، وأوقات المغادرة والوصول، وما إلى ذلك. الهدف من هذه البنية الأساسية لبرنامج ربط العمليات التجارية هو تلخيص الأداء اليومي لمسار الطيران، حيث يكون لكل مسار طيران سجل واحد لكل يوم مع متوسط عمليات التأخير في المغادرة والوصول بالدقائق، وإجمالي الأميال المقطوعة جواً في ذلك اليوم.
| YEAR | MONTH | DAY_OF_MONTH | المزود | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
ينتظر مثال البنية الأساسية لبرنامج ربط العمليات التجارية حتى تصل بيانات الرحلة لفترة زمنية جديدة، ثم يخزن معلومات الرحلة التفصيلية في مستودع بيانات Apache Hive لإجراء تحليلات طويلة الأجل. كما تقوم البنية الأساسية لبرنامج ربط العمليات التجارية بإنشاء مجموعة بيانات أصغر بكثير تلخص بيانات الرحلة اليومية فقط. يتم إرسال بيانات ملخص الرحلة اليومية هذه إلى قاعدة بيانات لغة الاستعلامات المركبة لتقديم تقارير، لموقع إنترنت مثلاً.
يوضح الرسم التخطيطي التالي هذا المثال:
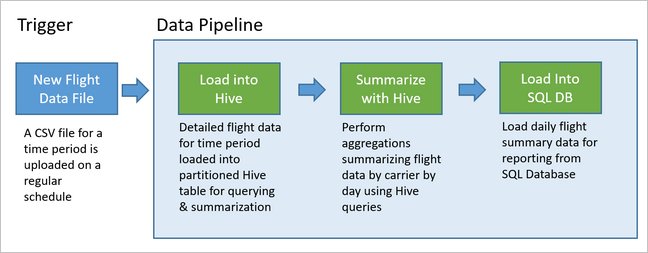
نظرة عامة على إحدى حلول Apache Oozie
يستخدم البنية الأساسية لبرنامج ربط العمليات التجارية Apache Oozie المستخدَم على نظام مجموعة HDInsight Hadoop.
تصف Oozie عمليات البنية الأساسية لبرنامج ربط العمليات التجارية من حيث الإجراءات، وسير العمل، والمنسقين. تحدد الإجراءات العمل الفعلي المراد تنفيذه، مثل تشغيل استعلام Apache Hive. تحدد عمليات سير العمل تسلسل الإجراءات. يحدد المنسقون الجدول الزمني لموعد تشغيل سير العمل. يمكن للمنسقين أيضاً الانتظار عند توفر بيانات جديدة قبل تشغيل مثيل لسير العمل.
الرسم البياني التالي يظهر تصميم رفيع المستوى لنموذج البنية الأساسية لبرنامج ربط العمليات التجارية Oozie هذا.
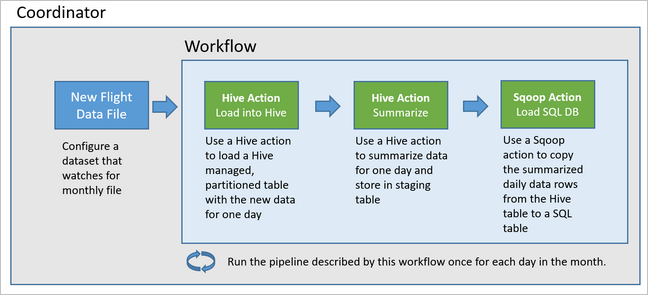
تزويد موارد Azure
يتطلب هذه البنية الأساسية لبرنامج ربط العمليات التجارية بقاعدة بيانات SQL Azure ونظام مجموعة HDInsight Hadoop في نفس الموقع. تخزن قاعدة بيانات Azure SQL كلاً من مجمل البيانات التي تنتجها البنية الأساسية لبرنامج ربط العمليات التجارية ومخزن بيانات تعريف Oozie.
توفير قاعدة بيانات Azure SQL
إنشاء قاعدة بيانات Azure SQL. اطلع على إنشاء قاعدة بيانات Azure SQL في مدخل Microsoft Azure.
للتأكد من أن نظام مجموعة HDInsight الخاصة بك يمكنه الوصول إلى قاعدة بيانات Azure SQL المتصلة، قم بتكوين قواعد جدار حماية قاعدة بيانات Azure SQL للسماح لخدمات وموارد Azure بالوصول إلى الخادم. يمكنك تمكين هذا الخيار في مدخل Microsoft Azure عن طريق تحديد إعداد جدار حماية الخادم، وتحديد تشغيل أسفل السماح لـ Azure للخدمات والموارد بالوصول إلى هذا الخادم لقاعدة بيانات Azure SQL. للحصول على مزيدٍ من المعلومات، راجع إنشاء وإدارة قواعد جدار حماية IP.
استخدم محرر استعلام لتنفيذ بيانات SQL التالية لإنشاء الجدول
dailyflightsالذي سيخزن البيانات الملخصة الناتجة عن كل مرة تشغيل للبنية الأساسية لبرنامج ربط العمليات التجارية.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
قاعدة بيانات Azure SQL الخاصة بك جاهزة الآن.
بند مجموعة Apache Hadoop
إنشاء نظام مجموعة Apache Hadoop مع metastore مخصص. أثناء إنشاء نظام المجموعة من المدخل، من علامة التبويب تخزين، تأكد من تحديدك لقاعدة بيانات SQL الخاصة بك ضمن إعدادات Metastore. لمزيد من المعلومات حول تحديد metastore، اطلع على تحديد metastore مخصص أثناء إنشاء نظام المجموعة. لمزيد من المعلومات حول إنشاء نظام مجموعة، اطلع على بدء استخدام HDInsight على نظام Linux.
التحقق من إعداد توجيه لأسفل لـ SSH
لاستخدام وحدة تحكم ويب Oozie لعرض حالة منسقك ونماذج سير العمل، قم بإعداد نفق SSH إلى نظام مجموعة HDInsight الخاصة بك. لمزيد من المعلومات، اطلع على نفق SSH.
إشعار
يمكنك أيضاً استخدام Chrome بملحق Foxy Proxy لاستعراض موارد الويب الخاصة بنظام مجموعتك عبر نفق SSH. كوِّنه إلى وكيل كل طلب خلال المضيف localhost على مدخل نفق 9876. يتوافق هذا الأسلوب مع نظام Windows الفرعي لـ Linux، المعروف أيضاً بـ Bash على نظام تشغيل Windows 10.
قم بتشغيل الأمر التالي لفتح نفق SSH إلى نظام مجموعتك، حيث
CLUSTERNAMEهو اسم نظام مجموعتك:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netتحقق من تشغيل النفق من خلال التنقل إلى Ambari على عقدة الرأس الخاصة بك عن طريق التصفح إلى:
http://headnodehost:8080للوصول إلى وحدة تحكم ويب Oozie من داخل Ambari، انتقل إلى Oozie>ارتباطات سريعة> [خادم نشط] >واجهة مستخدم الويب لـ Oozie.
تكوين Apache Hive
تحميل البيانات
تنزيل نموذج ملف CSV الذي يحتوي على بيانات الرحلة لمدة شهر واحد. تنزيل ملف ZIP
2017-01-FlightData.zipمن مستودع HDInsight GitHub وفك ضغط الملف CSV2017-01-FlightData.csv.انسخ ملف CSV هذا إلى حساب تخزين Azure المرفق بنظام مجموعتك HDInsight وضعه في المجلد
/example/data/flights.استخدم SCP لنسخ الملفات من جهازك المحلي إلى التخزين المحلي لعقدة رأس نظام مجموعة HDInsight.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvاستخدم الأمر ssh للاتصال بنظام المجموعة الخاص بك. حرر الأمر أدناه عن طريق استبدال
CLUSTERNAMEباسم نظام مجموعتك ثم إدخال الأمر:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netمن جلسة ssh الخاصة بك، استخدم الأمر HDFS لنسخ الملف من التخزين المحلي لعقدة الرأس إلى Azure Storage.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
إنشاء جداول
بيانات العينة متوفرة الآن. ومع ذلك، يتطلب التدفق جدولي Apache Hive للمعالجة، واحد للبيانات الواردة (rawFlights) وواحد للبيانات الملخصة (flights). قم بإنشاء هذه الجداول في Ambari كما يلي.
سجل الدخول إلى Ambari عن طريق الانتقال إلى
http://headnodehost:8080.من قائمة الخدمات، حدد Apache Hive.
حدد الانتقال إلى العرض بجوار علامة Hive View 2.0.
في مساحة نص الاستعلام، قم بلصق العبارات التالية لإنشاء الجدول
rawFlights. يقدم الجدولrawFlightsمخطط للقراءة لملفات CSV داخل/example/data/flightsالمجلد في Azure Storage.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'في شريط الأدوات، حدد تنفيذ لإنشاء الجدول.
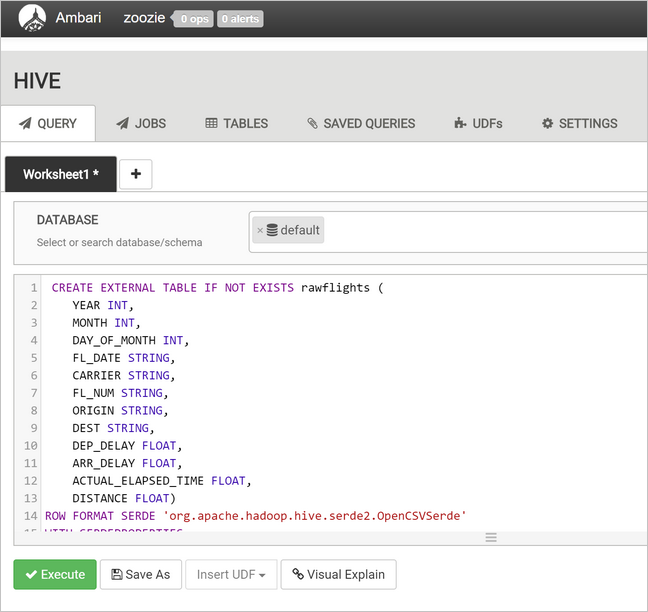
لإنشاء الجدول
flights، استبدل النص في مساحة نص الاستعلام بالعبارات التالية. الجدولflightsهو جدول يديره Apache Hive الذي يقسم البيانات المحملة داخلها حسب السنة والشهر واليوم من الشهر. وسيحتوي هذا الجدول على جميع بيانات الرحلات الجوية التاريخية، مع أدنى مستوى من النقاوة في بيانات المصدر لسجل واحد لكل رحلة.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );في شريط الأدوات، حدد تنفيذ لإنشاء الجدول.
إنشاء سير العمل Oozie
عادة ما تعالج البنية الأساسية لبرنامج ربط العمليات التجارية بالبيانات على دفعات حسب فاصل زمني محدد. في هذه الحالة، تقوم البنية الأساسية لبرنامج ربط العمليات التجارية بمعالجة بيانات الرحلة يومياً. يسمح هذا الأسلوب بإدخال ملفات CSV لكي تصل يومياً أو أسبوعياً أو شهرياً أو سنوياً.
تقوم عينة سير العمل بمعالجة بيانات الرحلة يوماً بعد يوم، في ثلاث خطوات رئيسية:
- قم بتشغيل استعلام Apache Hive لاستخراج البيانات الخاصة بنطاق تاريخ ذلك اليوم من مصدر ملف CSV الذي يمثله الجدول
rawFlightsوإدخال البيانات في الجدولflights. - قم بتشغيل استعلام Apache Hive لإنشاء جدول التقسيم المرحلي بشكل ديناميكي في Apache Hive لهذا اليوم، والذي يحتوي على نسخة من بيانات الرحلة التي تم تلخيصها حسب اليوم وشركة الجوَّال.
- استخدم Apache Sqoop لنسخ جميع البيانات من جدول التقسيم المرحلي اليومي في Apache Hive إلى جدول الوجهة
dailyflightsفي قاعدة بيانات Azure SQL. يقوم Sqoop بقراءة سجلات المصدر من البيانات خلف جدول Apache Hive الموجودة في Azure Storage ثم تحميلها في قاعدة بيانات SQL باستخدام اتصال JDBC.
يتم تنسيق هذه الخطوات الثلاث بواسطة سير عمل Oozie.
من محطة العمل المحلية، قم بإنشاء ملف يسمى
job.properties. استخدم النص أدناه كمحتويات بدء الملف. ثم قم بتحديث قيم بيئتك المحددة. يلخص الجدول الموجود أسفل النص كل خاصية من الخصائص ويشير إلى المكان الذي يمكنك العثور فيه على قيم بيئتك الخاصة.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03الخاصية مصدر القيمة nameNode المسار الكامل لحاوية Azure Storage المرفقة بنظام مجموعة HDInsight الخاصة بك. jobTracker اسم المضيف الداخلي لعقدة الرأس لنظام مجموعة YARN النشطة الخاصة بك. في الصفحة الرئيسية Ambari حدد YARN من قائمة الخدمات ثم اختر Resource Manager النشط. يتم عرض URI لاسم المضيف في أعلى الصفحة. إلحاق المنفذ 8050. queueName اسم قائمة انتظار YARN المستخدمة عند جدولة إجراءات Apache Hive. اترك الإعداد الافتراضي كما هو. oozie.use.system.libpath اتركها كقيمة حقيقية. appBase المسار إلى المجلد الفرعي في Azure Storage حيث تقوم بتوزيع سير عمل Oozie وملفات الدعم. مسار التطبيق Oozie.wf موقع سير عمل Oozie workflow.xmlلتشغيله.hiveScriptLoadPartition المسار فيAzure Storage إلى ملف استعلام Apache Hive hive-load-flights-partition.hql.hiveScriptCreateDailyTable المسار فيAzure Storage إلى ملف استعلام Apache Hive hive-create-daily-summary-table.hql.hiveDailyTableName اسم تم إنشاؤه ديناميكياً لاستخدامه لجدول التقسيم المرحلي. hiveDataFolder المسار في Azure Storage إلى البيانات المضمنة في جدول التقسيم المرحلي. sqlDatabaseConnectionString سلسلة اتصال بناء الجملة JDBC إلى قاعدة بيانات Azure SQL. sqlDatabaseTableName اسم الجدول في قاعدة بيانات Azure SQL التي يتم إدراج سجلات الملخص فيها. يُترك كـ dailyflights.year مكون السنة من اليوم الذي يتم حساب ملخصات الرحلة له. اتركه كما هو. month مكون الشهر من اليوم الذي يتم حساب ملخصات الرحلة له. اتركه كما هو. من الأيام مكون يوم الشهر من اليوم الذي يتم حساب ملخصات الرحلة له. اتركه كما هو. من محطة العمل المحلية، قم بإنشاء ملف يسمى
hive-load-flights-partition.hql. استخدم التعليمات البرمجية أدناه كمحتويات للملف.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};تستخدم متغيرات Oozie بناء الجملة
${variableName}. يتم ضبط هذه المتغيرات في الملفjob.properties. يستبدل Oozie القيم الفعلية في وقت التشغيل.من محطة العمل المحلية، قم بإنشاء ملف يسمى
hive-create-daily-summary-table.hql. استخدم التعليمات البرمجية أدناه كمحتويات للملف.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};ينشئ هذا الاستعلام جدول التقسيم المرحلي الذي سيقوم بتخزين البيانات الملخصة ليوم واحد فقط، دون عبارة SELECT التي تحسب متوسط عمليات التأخير وإجمالي المسافة المقطوعة جواً بواسطة المزود حسب اليوم. البيانات المدرجة في هذا الجدول المخزنة في موقع معروف (المسار المشار إليه بواسطة متغير hiveDataFolder) بحيث يمكن استخدامه كمصدر لـ Sqoop في الخطوة التالية.
من محطة العمل المحلية، قم بإنشاء ملف يسمى
workflow.xml. استخدم التعليمات البرمجية أدناه كمحتويات للملف. يتم التعبير عن هذه الخطوات أعلاه كإجراءات منفصلة في ملف Oozie لسير العمل.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
يتم الوصول إلى استعلامات Apache Hive بواسطة مسارها فيAzure Storage أما عن القيم المتغيرة المتبقية فسيوفرها الملف job.properties. يقوم هذا الملف بتكوين سير العمل لتشغيله بتاريخ 3 يناير 2017.
توزيع وتشغيل سير عمل Oozie
استخدم SCP من جلسة مشاركتك لنشر سير عمل Oozie (workflow.xml)، واستعلامات Apache Hive (hive-load-flights-partition.hql وhive-create-daily-summary-table.hql)، وتكوين المهمة (job.properties). يمكن أن يوجد الملف في Oozie فقط job.properties على التخزين المحلي لعقدة الرأس. يجب تخزين جميع الملفات الأخرى في HDFS، وفي هذه الحالةAzure Storage. يعتمد الإجراء Sqoop المستخدم من قبل سير العمل على برنامج تشغيل JDBC للاتصال بقاعدة بيانات SQL، والتي يجب نسخها من عقدة الرأس إلى HDFS.
قم بإنشاء المجلد الفرعي
load_flights_by_dayأسفل مسار المستخدم في التخزين المحلي لعقدة الرأس. من جلسة ssh المفتوحة الخاصة بك، نفذ الأمر التالي:mkdir load_flights_by_dayانسخ جميع الملفات في الدليل الحالي (ملفات
workflow.xmlوjob.properties) حتى المجلد الفرعيload_flights_by_day. من محطة العمل المحلية الخاصة بك قم بتنفيذ الأمر التالي:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayانسخ ملفات سير العمل إلى HDFS. من جلسة ssh المفتوحة الخاصة بك، نفذ الأوامر التالية:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayانسخ
mssql-jdbc-7.0.0.jre8.jarمن عقدة الرأس المحلية إلى مجلد سير العمل في HDFS. راجع الأمر حسب الحاجة إذا كان نظام المجموعة يحتوي على ملف jar مختلف. مراجعةworkflow.xmlحسب الحاجة لتعكس ملف jar مختلف. من جلسة ssh المفتوحة الخاصة بك، نفذ الأمر التالي:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayتشغيل سير العمل. من جلسة ssh المفتوحة الخاصة بك، نفذ الأمر التالي:
oozie job -config job.properties -runمراقبة الحالة باستخدام وحدة تحكم ويب Oozie. من داخل Ambari، حدد Oozie، وارتباطات سريعة، ثم وحدة تحكم الويب Oozie. ضمن علامة التبويب مهام سير العمل، حدد جميع الوظائف.
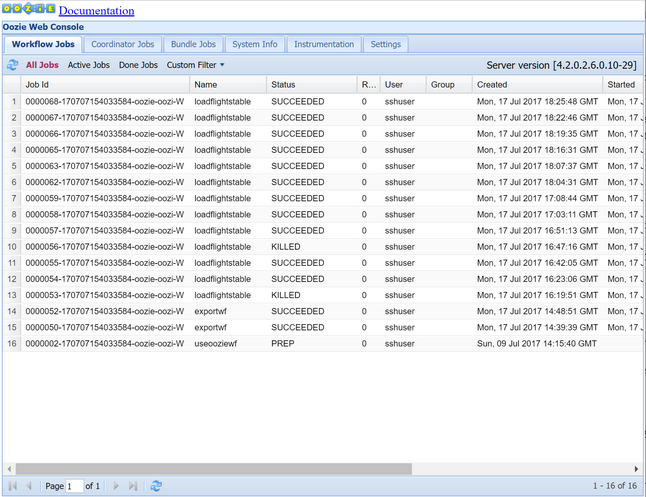
عندما تكون الحالة هي SUCCEEDED، استعلم عن جدول قاعدة بيانات SQL لعرض السجلات المدرجة. باستخدام مدخل Microsoft Azure، انتقل إلى الجزء الخاص بقاعدة بيانات SQL، وحدد الأدوات، وافتح محرر الاستعلام.
SELECT * FROM dailyflights
الآن وبعد أن أصبح سير العمل قيد التشغيل ليوم الاختبار الفردي، يمكنك تضمين سير العمل هذا مع منسق يقوم بجدولته بحيث يتم تشغيله يومياً.
تشغيل سير العمل مع منسق
لجدولة سير العمل هذا بحيث يتم تشغيله يومياً (أو كل الأيام في نطاق تاريخ)، يمكنك استخدام منسق. يتم تعريف المنسق بواسطة ملف XML، على سبيل المثال coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
كما ترى، يقوم المنسق فقط بتمرير غالبية معلومات التكوين إلى مثيل سير العمل. ومع ذلك، هناك بعض العناصر الهامة للاستدعاء.
النقطة 1: تتحكم السمات
startوendالموجودة على العنصرcoordinator-appنفسه في الفاصل الزمني الذي يعمل خلاله المنسق.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>يكون المنسق مسؤول عن جدولة الإجراءات ضمن نطاق التاريخ
startوend، وفقاً للفاصل الزمني المحدد بواسطة السمةfrequency. يقوم كل إجراء مجدول بدوره بتشغيل سير العمل كما تم تكوينه. في تعريف المنسق أعلاه، تم تكوين المنسق لتشغيل الإجراءات من 1 يناير 2017 إلى 5 يناير 2017. يتم ضبط التردد ليوم واحد عن طريق تعبير تردد لغة تعبير Oozie${coord:days(1)}. ينتج عن هذا المنسق جدولة إجراء (ومن ثم سير العمل) مرة واحدة في اليوم. بالنسبة لنطاقات التاريخ التي كانت موجودة في الماضي، كما في هذا المثال، ستتم جدولة الإجراء ليتم تشغيله دون تأخير. يسمى بداية التاريخ الذي تتم فيه جدولة الإجراء لتشغيله بالوقت الاسمي. على سبيل المثال، لمعالجة بيانات 1 يناير 2017، سيقوم المنسق بجدولة الإجراءات بوقت اسمي 2017-01-01:T00:0000 بتوقيت جرينتش.النقطة 2: ضمن نطاق التاريخ لسير العمل، يحدد العنصر
datasetمكان البحث في HDFS عن البيانات لنطاق تاريخ معين، ويكِّون كيفية تحديد Oozie ما إذا كانت البيانات متوفرة حتى الآن للمعالجة.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>يتم بناء المسار إلى البيانات في HDFS ديناميكياً وفقاً للتعبير المقدم في العنصر
uri-template. في هذا المنسق، يتم استخدام تكرار يوم واحد أيضاً مع مجموعة البيانات. بينما يتحكم عنصر المنسق في تواريخ البدء والانتهاء عند جدولة الإجراءات (ويحدد أوقاتها الاسمية)، يتحكم كل منinitial-instanceوfrequencyفي مجموعة البيانات في حساب التاريخ المستخدم في إنشاءuri-template. في هذه الحالة، قم بتعيين المثيل الأولي إلى يوم واحد قبل بدء المنسق للتأكد من أنه يلتقط بيانات اليوم الأول (1 يناير 2017). يتم تقديم حساب تاريخ مجموعة البيانات من قيمةinitial-instance(12/31/2016) التي تتقدم بزيادات في تكرار مجموعة البيانات (يوم واحد) حتى تجد أحدث تاريخ لا يجتاز الوقت الاسمي الذي حدده المنسق (2017-01-01T00:00:00 GMT للإجراء الأول).يشير عنصر
done-flagالفارغ إلى أنه عندما يتحقق Oozie من وجود بيانات الإدخال في الوقت المحدد، فإنه يحدد البيانات سواء كانت متاحة من خلال وجود دليل أو ملف. في هذه الحالة، وجود ملف csv. إذا كان ملف csv موجوداً، يفترض Oozie أن البيانات جاهزة ويشغل مثيل سير عمل لمعالجة الملف. إذا لم يتواجد ملف csv، يفترض Oozie أن البيانات ليست جاهزة بعد وأن تشغيل سير العمل يذهب إلى حالة الانتظار.النقطة 3: يحدد العنصر
data-inالطابع الزمني المعين لاستخدامه كوقت اسمي عند استبدال القيم فيuri-templateلمجموعة البيانات المقترنة.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>في هذه الحالة، اضبط المثيل على التعبير
${coord:current(0)}، والذي يُترجم إلى استخدام الوقت الاسمي للإجراء كما هو مقرر أصلاً بواسطة المنسق. بمعنى آخر، عندما يقوم المنسق بجدولة الإجراء للتشغيل بوقت اسمي هو 01/01/2017، فإن 01/01/2017 هو التاريخ الذي يتم استخدامه لاستبدال متغيري السنة (2017) والشهر(01) في قالب URI. بمجرد حساب قالب URI لهذا المثال، يتحقق Oozie مما إذا كان الدليل أو الملف المتوقع متاحاً ويقوم بجدولة التشغيل التالي لسير العمل وفقاً لذلك.
تتحد النقاط الثلاث السابقة لتنتج موقفاً يقوم فيه المنسق بجدولة معالجة بيانات المصدر بشكل يومي.
النقطة 1: يبدأ المنسق بتاريخ اسمي 2017-01-01.
النقطة 2: يبحث Oozie عن البيانات المتوفرة في
sourceDataFolder/2017-01-FlightData.csv.النقطة 3: عندما يعثر Oozie على هذا الملف، فإنه يقوم بجدولة مثيل لسير العمل الذي سيقوم بمعالجة البيانات ل 1 يناير 2017. يواصل Oozie عندئذ المعالجة لـ 2017-01-02. يتكرر هذا التقييم حتى 2017-01-05 ولكن لا يشمله.
كما هو الحال مع مهام سير العمل، يتم تحديد تكوين المنسق في ملف job.properties، والذي يحتوي على مجموعة شاملة من الإعدادات المستخدمة بواسطة سير العمل.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
الخصائص الجديدة الوحيدة التي تم تقديمها في هذا الملف job.properties هي:
| الخاصية | مصدر القيمة |
|---|---|
| oozie.coord.application.path | يشير إلى موقع الملف coordinator.xml الذي يحتوي على منسق Oozie لتشغيله. |
| hiveDailyTableNamePrefix | البادئة المستخدمة لاسم الجدول عند الإنشاء الديناميكي لجدول التقسيم المرحلي. |
| hiveDataFolderPrefix | بادئة المسار حيث سيتم تخزين جميع جداول التقسيم المرحلي. |
توزيع منسق Oozie وتشغيله
لتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية مع منسق، تابع بطريقة مماثلة لسير العمل، باستثناء أنك تعمل من مجلد بمستوى واحد أعلى من المجلد الذي يحتوي على سير العمل الخاص بك. يفصل اصطلاح المجلد هذا بين المنسقين ومهام سير العمل على القرص، بحيث يمكنك ربط منسق واحد بمهام سير عمل فرعية مختلفة.
استخدم SCP من جهازك المحلي لنسخ ملفات المنسق حتى التخزين المحلي لعقدة الرأس في نظام مجموعتك.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~SSH في عقدة رأسك.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netنسخ ملفات المنسق إلى HDFS.
hdfs dfs -put ./* /oozie/تشغيل المنسق.
oozie job -config job.properties -runتحقق من الحالة باستخدام وحدة تحكم الويب Oozie، هذه المرة حدد علامة التبويب مهام المنسق، ثم جميع المهام.
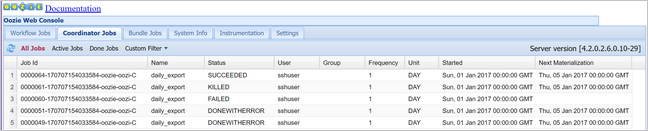
حدد نسخة منسق لعرض قائمة الإجراءات المجدولة. في هذه الحالة، يجب أن تشاهد أربعة إجراءات بأوقات اسمية في النطاق من 1 يناير 2017 إلى 4 يناير 2017.
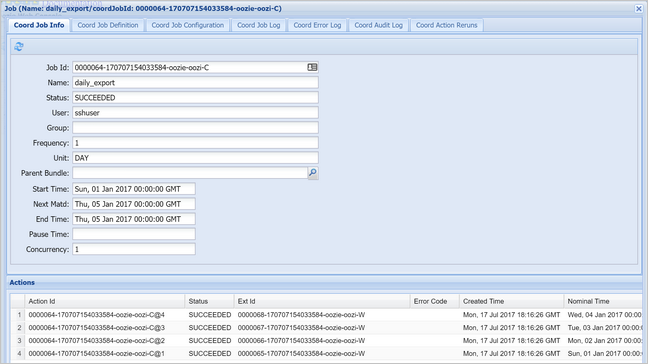
يتوافق كل إجراء في هذه القائمة مع مثيل من سير العمل الذي يعالج قيمة البيانات ليوم واحد، حيث يُشار إلى بداية ذلك اليوم بالوقت الاسمي.