استكشاف أخطاء Apache Hadoop HDFS وإصلاحها باستخدام Azure HDInsight
تعرف على أهم المشكلات والحلول عند العمل مع نظام الملفات الموزعة Hadoop (HDFS). للحصول على قائمة كاملة بالأوامر، راجع دليل أوامر HDFS ودليل Shell System Shell.
قم بالوصول إلى HDFS المحلي من سطر الأوامر والتعليمات البرمجية للتطبيق بدلاً من استخدام تخزين Azure Blob أو تخزين Azure Data Lake من داخل نظام مجموعة HDInsight.
في موجه الأوامر، استخدم
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...حرفياً، كما في الأمر التالي:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userمن التعليمات البرمجية المصدر، استخدم URI
hdfs://mycluster/حرفياً، كما في نموذج التطبيق التالي:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }قم بتشغيل ملف jar. المترجم (على سبيل المثال، ملف باسم
java-unit-tests-1.0.jar) على نظام مجموعة HDInsight باستخدام الأمر التالي:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
عند استخدام الأمرين hadoop أو hdfs dfs لكتابة ملفات بحجم 12 غيغابايت تقريباً أو أكبر على نظام مجموعة HBase، قد تصادف الخطأ التالي:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
HBase على مجموعات HDInsight الافتراضي إلى حجم كتلة 256 كيلو بايت عند الكتابة إلى تخزين Azure. أثناء عمله مع واجهات برمجة تطبيقات HBase أو واجهات برمجة تطبيقات REST، فإنه ينتج عنه خطأ عند استخدام أدوات سطر الأوامر hadoop أو hdfs dfs.
استخدم fs.azure.write.request.size لتحديد حجم كتلة أكبر. يمكنك إجراء هذا التعديل على أساس كل استخدام باستخدام المعلمة -D. الأمر التالي هو مثال على استخدام هذه المعلمة مع الأمر hadoop :
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
يمكنك أيضاً زيادة قيمة fs.azure.write.request.size بشكل عام باستخدام Apache Ambari. يمكن استخدام الخطوات التالية لتغيير القيمة في Ambari Web UI:
في المستعرض الخاص بك، انتقل إلى Ambari Web UI لمجموعتك. عنوان URL هو
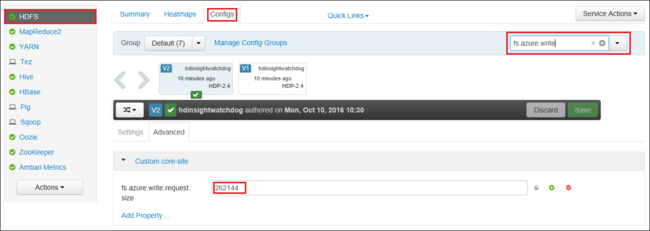
https://CLUSTERNAME.azurehdinsight.net، حيثCLUSTERNAMEهو اسم مجموعتك. عند المطالبة، أدخل اسم المسؤول وكلمة المرور للنظام مجموعة.من الجانب الأيسر من الشاشة، حدد HDFS، ثم حدد علامة التبويب Configs.
في الحقل ...Filter، أدخل
fs.azure.write.request.size.قم بتغيير القيمة من 262144 (256 كيلو بايت) إلى القيمة الجديدة. على سبيل المثال، 4194304 (4 ميجابايت).
لمزيد من المعلومات حول استخدام Ambari، راجع إدارة مجموعات HDInsight باستخدام Apache Ambari Web UI.
يعرض الأمر -du أحجام الملفات والأدلة الموجودة في الدليل المحدد أو طول الملف في حال كان ممخزون ملف.
ينتج عن الخيار -s ملخصاً مجمعاً لأطوال الملفات التي يتم عرضها.
يقوم الخيار -h بتنسيق أحجام الملفات.
مثال:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
يحذف الأمر -rm الملفات المحددة كوسائط.
مثال:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
إذا لم تشاهد مشكلتك أو لم تتمكن من حلها، فتفضل بزيارة إحدى القنوات التالية للحصول على مزيد من الدعم:
احصل على إجابات من خبراء Azure عبر دعم مجتمع Azure.
تواصل مع @AzureSupport - حساب Microsoft Azure الرسمي لتحسين تجربة العملاء. توصيل الموارد المناسبة إلى مجتمع Azure: الإجابات، والدعم، والخبراء.
إذا كنت بحاجة إلى مزيد من المساعدة، فيمكنك إرسال طلب دعم من مدخل Microsoft Azure. حدد Support من شريط القائمة أو افتح المحور Help + support. لمزيد من المعلومات التفصيلية، راجع كيفية إنشاء طلب دعم Azure. يتم تضمين الوصول إلى إدارة الاشتراك ودعم الفواتير في اشتراك Microsoft Azure، ويتم توفير الدعم التقني من خلال إحدى خطط دعم Azure.