ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
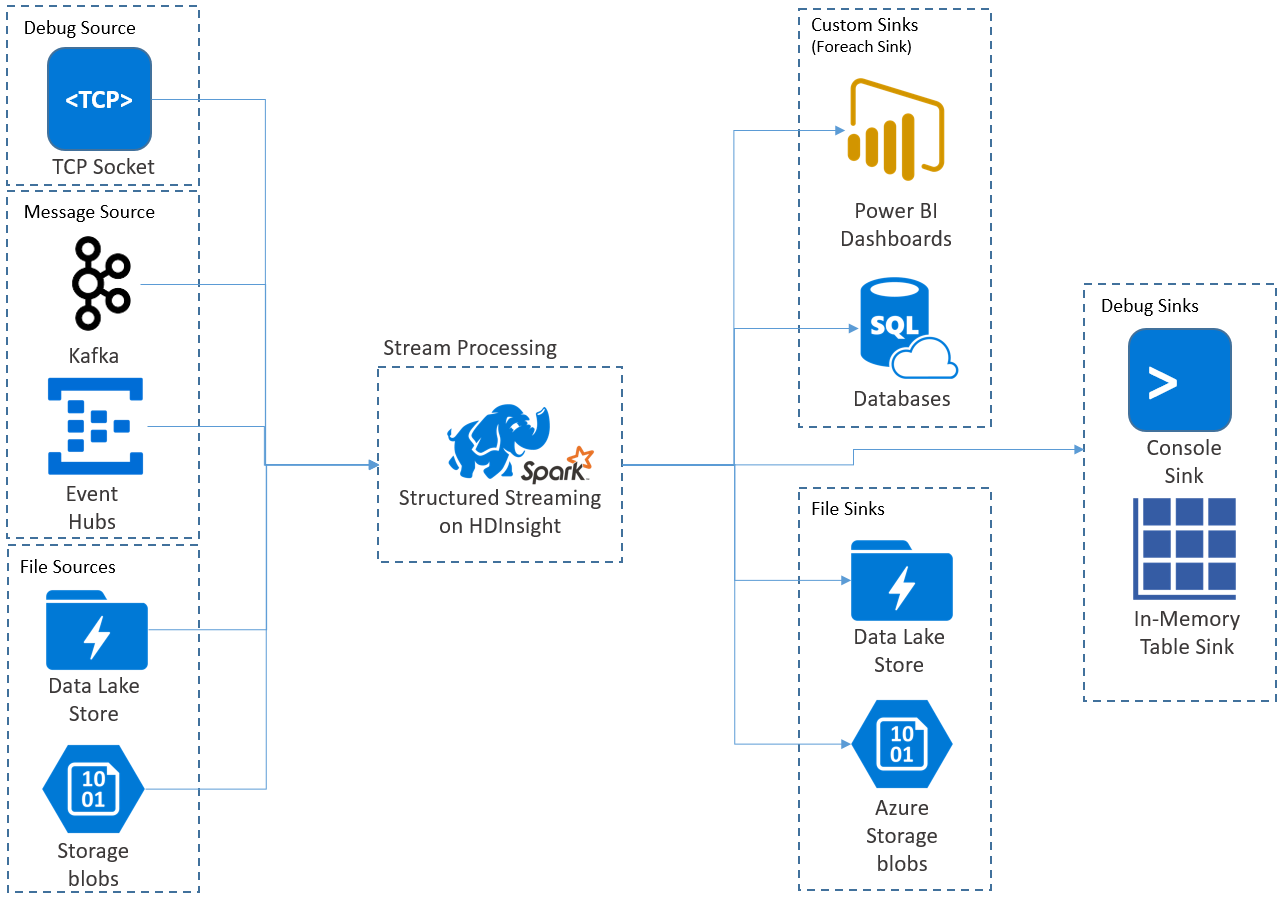
يتيح لك البث المنظم Apache Spark تنفيذ تطبيقات قابلة لتغيير الحجم وعالية المعدل نقل ومتسامحة مع الأخطاء لمعالجة تدفقات البيانات. تم بناء الدفق المهيكل على محرك Spark SQL، وهو يعمل على تحسين التركيبات من Spark SQL Data Frames ومجموعات البيانات حتى تتمكن من كتابة استعلامات الدفق بنفس الطريقة التي تكتب بها الاستعلامات المجمعة.
يتم تشغيل تطبيقات التدفق المهيكل على مجموعات HDInsight Spark، وتتصل بالبيانات المتدفقة من Apache Kafkaأو مقبس TCP (لأغراض التصحيح) أو Azure Storage أو Azure Data Lake Storage. يتيح لك الخياران الأخيران، اللذان يعتمدان على خدمات التخزين الخارجية، مشاهدة الملفات الجديدة المضافة إلى التخزين ومعالجة محتوياتها كما لو تم دفقها.
يُنشئ التدفق المهيكل استعلاماً طويل المدى تقوم خلاله بتطبيق العمليات على بيانات الإدخال، مثل التحديد، والإسقاط، والتجميع، ووضع النوافذ، والانضمام إلى دفق DataFrame مع DataFrames المرجعية. بعد ذلك، يمكنك إخراج النتائج إلى تخزين الملفات (Azure Storage Blobs، أو Data Lake Storage) أو إلى أي مستودع بيانات باستخدام التعليمات البرمجية المخصصة (مثل: SQL Database، أو Power BI). كما يوفر Structured Streaming الإخراج إلى وحدة التحكم لتصحيح الأخطاء داخليًا، وإلى جدول ذاكرة؛ بحيث يمكنك مشاهدة البيانات التي تم إنشاؤها لتصحيح الأخطاء في HDInsight.
إشعار
يحل Spark Structured Streaming محل Spark Streaming (DStreams). من الآن فصاعداً، سيتلقى Structured Streaming تحسينات وصيانة، بينما ستكون DStreams في وضع الصيانة فقط. لا يعد Structured Streaming حالياً مكتملاً للميزات مثل DStreams للمصادر والأحواض التي يدعمها خارج الصندوق، لذا قم بتقييم متطلباتك لاختيار خيار معالجة Spark Stream المناسب.
تدفق البيانات في جداول
يمثل Spark Structured Streaming دفقاً من البيانات كجدول غير محدود في العمق، أي أن الجدول يستمر في النمو مع وصول بيانات جديدة. تتم معالجة جدول الإدخال هذا بشكل مستمر بواسطة استعلام طويل المدى، ويتم إرسال النتائج إلى جدول الإخراج:

في Structured Streaming، تصل البيانات إلى النظام، ويتم استيعابها على الفور في جدول إدخال. تكتب الاستعلامات (باستخدام واجهات برمجة تطبيقات DataFrame وDataset) التي تنفذ العمليات مقابل جدول الإدخال. ينتج عن إخراج الاستعلام جدول آخر، جدول النتائج. يحتوي جدول النتائج على نتائج الاستعلام الخاص بك، والتي يمكنك من خلالها رسم بيانات لمستودع بيانات خارجي؛ مثل: قاعدة بيانات ارتباطية. يتم التحكم في توقيت معالجة البيانات من جدول الإدخال بواسطة فاصل التشغيل. بشكل افتراضي، الفاصل الزمني للتشغيل هو صفر؛ لذلك يحاول Structured Streaming معالجة البيانات بمجرد وصولها. في الممارسة العملية، هذا يعني أنه بمجرد انتهاء Structured Streaming من معالجة تشغيل الاستعلام السابق، فإنه يبدأ تشغيل معالجة أخرى لأي بيانات تم تلقيها حديثًا. يمكنك تكوين المشغل لتشغيله في فاصل زمني؛ بحيث تتم معالجة بيانات متدفقة على دفعات وفق توقيت محدد.
قد تحتوي البيانات الموجودة في جداول النتائج على البيانات الجديدة فقط منذ آخر مرة تمت فيها معالجة الاستعلام (وضع الإلحاق)، أو قد يتم تحديث الجدول في كل مرة توجد فيها بيانات جديدة بحيث يتضمن الجدول جميع بيانات الإخراج منذ بدء استعلام الدفق (الوضع الكامل).
وضع الإلحاق
في وضع الإلحاق، تكون الصفوف فقط التي تمت إضافتها إلى جدول النتائج منذ آخر مرة لتشغيل استعلام موجودة في جدول النتائج، ومكتوبة على وحدة تخزين خارجية. على سبيل المثال، يقوم الاستعلام الأبسط بنسخ جميع البيانات من جدول الإدخال إلى جدول النتائج دون تغيير. في كل مرة ينقضي الفاصل الزمني للتشغيل، تتم معالجة البيانات الجديدة، وتظهر الصفوف التي تمثل تلك البيانات الجديدة في جدول النتائج.
ضع في اعتبارك سيناريو تقوم فيه بمعالجة القياس عن بعد من مستشعرات درجة الحرارة، مثل منظم الحرارة. افترض أن المشغل الأول تمت معالجته حدثاً واحداً في الوقت 00:01 للجهاز 1 بقراءة درجة حرارة 95 درجة. في المشغل الأول للاستعلام، يظهر فقط الصف مع الوقت 00:01 في جدول النتائج. في الساعة 00:02 عند وصول حدث آخر، يكون الصف الجديد الوحيد هو الصف الذي يحتوي على الوقت 00:02 ولذا فإن جدول النتائج سيحتوي على هذا الصف فقط.
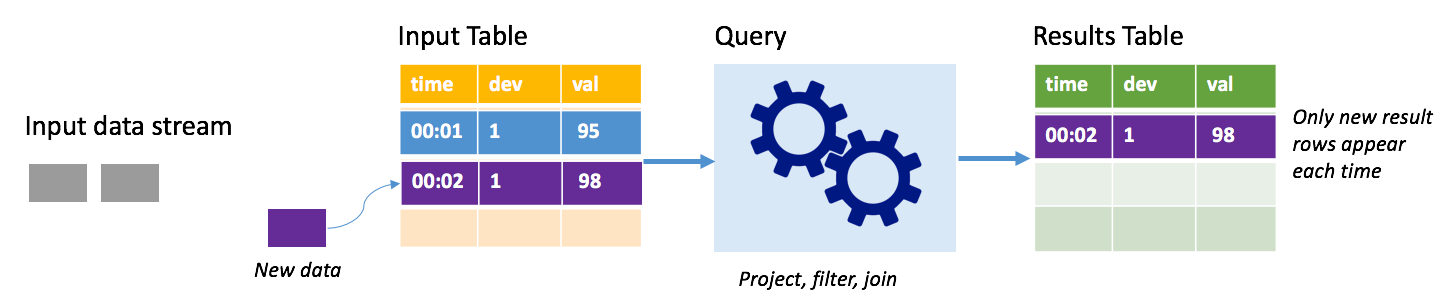
عند استخدام وضع الإلحاق، يكون الاستعلام الخاص بك تطبيق عمليات الإسقاط (تحديد الأعمدة التي يهتم بها) أو التصفية (انتقاء الصفوف التي تتطابق مع شروط معينة فقط) أو الربط (تعزيز البيانات ببيانات من جدول بحث ثابت). يجعل وضع الإلحاق من السهل دفع نقاط البيانات الجديدة ذات الصلة فقط إلى وحدة التخزين الخارجية.
الوضع الكامل
ضع في اعتبارك نفس السيناريو، هذه المرة باستخدام الوضع الكامل. في الوضع الكامل، يتم تحديث جدول الإخراج بأكمله على كل مشغل؛ بحيث يتضمن الجدول البيانات ليس فقط من تشغيل المشغل الأحدث؛ ولكن من كافة عمليات التشغيل. يمكنك استخدام الوضع الكامل لنسخ البيانات دون تغيير من جدول الإدخال إلى جدول النتائج. في كل تشغيل يتم تشغيله، تظهر صفوف النتائج الجديدة جنباً إلى جنب مع جميع الصفوف السابقة. سينتهي جدول نتائج الإخراج بتخزين جميع البيانات التي تم جمعها منذ بدء الاستعلام، وستنفد الذاكرة في النهاية. يخصص الوضع الكامل للاستخدام مع استعلامات التجميع التي تلخص البيانات الواردة بطريقة ما؛ لذلك مع كل مشغل يتم تحديث جدول النتائج بملخص جديد.
افترض حتى الآن أن هناك ما يعادل خمس ثوانٍ من البيانات تمت معالجتها بالفعل، وأن الوقت قد حان لمعالجة البيانات للثانية السادسة. يحتوي جدول الإدخال على أحداث للوقت 00:01 والوقت 00:03. الهدف من هذا الاستعلام النموذجي هو إعطاء متوسط درجة حرارة الجهاز كل خمس ثوانٍ. يطبق تنفيذ هذا الاستعلام إجمالياً يأخذ جميع القيم التي تقع داخل كل نافذة مدتها 5 ثوانٍ، ويقيس متوسط درجة الحرارة، وينتج صفاً لمتوسط درجة الحرارة خلال تلك الفترة. في نهاية أول إطار زمني مدته 5 ثوانٍ، هناك مجموعتان: (00:01, 1, 95)، و (00:03, 1, 98). لذلك بالنسبة للنافذة 00: 00-00: 05 ينتج التجميع مجموعة ذات متوسط درجة حرارة 96.5 درجة. في النافذة التالية ذات الخمس ثوانٍ، توجد نقطة بيانات واحدة فقط في الوقت 00:06، وبالتالي فإن متوسط درجة الحرارة الناتجة هو 98 درجة. في الوقت 00:10، باستخدام الوضع الكامل، يحتوي جدول النتائج على صفوف لكلا الإطارين الزمنيين 00:00-00:05 و00:05-00:10؛ لأن الاستعلام ينتج كافة الصفوف المجمعة، وليس الجديدة فقط. لذلك يستمر جدول النتائج في النمو مع إضافة نوافذ جديدة.
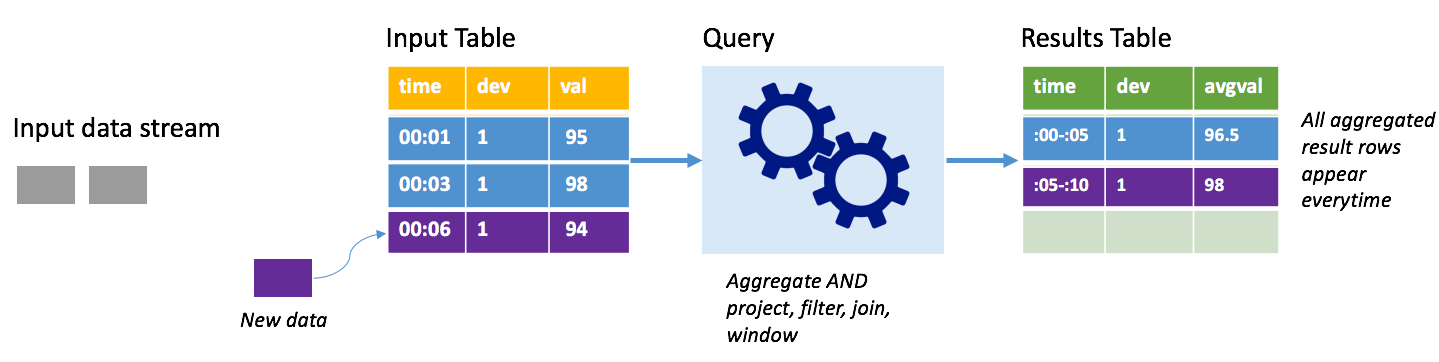
لن تتسبب جميع الاستعلامات التي تستخدم الوضع الكامل في زيادة حجم الجدول من دون حدود. ضع في اعتبارك في المثال السابق أنه بدلاً من حساب متوسط درجة الحرارة حسب النافذة الزمنية، تم حساب متوسطها بدلاً من ذلك حسب معرف الجهاز. يحتوي جدول النتائج على عدد ثابت من الصفوف (واحد لكل جهاز) بمتوسط درجة حرارة الجهاز عبر جميع نقاط البيانات المستلمة من هذا الجهاز. عند تلقي درجات حرارة جديدة، يتم تحديث جدول النتائج بحيث تكون المعدلات في الجدول محدثة دائماً.
مكونات تطبيق Spark Structured Streaming
يمكن لاستعلام مثال بسيط تلخيص قراءات درجة الحرارة بنوافذ مدتها ساعة. في هذه الحالة، يتم تخزين البيانات في ملفات JSON في Azure Storage (مرفق كمخزن افتراضي لمجموعة HDInsight):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
يتم تخزين ملفات JSON هذه في المجلد الفرعي temps أسفل حاوية مجموعة HDInsight.
تحديد مصدر الإدخال
قم أولاً بتكوين DataFrame الذي يصف مصدر البيانات وأي إعدادات يطلبها هذا المصدر. يستمد هذا المثال من ملفات JSON في Azure Storage ويطبق مخططاً عليها في وقت القراءة.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
قم بتطبيق الاستعلام
بعد ذلك، قم بتطبيق استعلام يحتوي على العمليات المطلوبة مقابل Streaming DataFrame. في هذه الحالة، يقوم التجميع بتجميع كل الصفوف في نوافذ مدتها ساعة واحدة، ثم يحسب درجات الحرارة الدنيا والمتوسطة والحد الأقصى في تلك النافذة التي تبلغ مدتها ساعة واحدة.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
تحديد بالوعة الإخراج
بعد ذلك، حدد وجهة الصفوف التي تمت إضافتها إلى جدول النتائج داخل كل فترة تشغيل. يقوم هذا المثال بإخراج جميع الصفوف إلى جدول في الذاكرة temps يمكنك الاستعلام عنه لاحقاً باستخدام SparkSQL. يضمن وضع الإخراج الكامل إخراج جميع الصفوف لجميع النوافذ في كل مرة.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
ابدأ الاستعلام
ابدأ الاستعلام المتدفق وقم بتشغيله حتى يتم استلام إشارة الإنهاء.
val query = streamingOutDF.start()
عرض النتائج
أثناء تشغيل الاستعلام، في نفس SparkSession، يمكنك تشغيل استعلام SparkSQL مقابل الجدول temps حيث يتم تخزين نتائج الاستعلام.
select * from temps
ينتج عن هذا الاستعلام نتائج مشابهة لما يلي:
| window | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u"start": u"2016-07-26T02:00:00.000Z"، u"end"... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
للحصول على تفاصيل حول Spark Structured Stream API، جنباً إلى جنب مع مصادر بيانات الإدخال والعمليات وأحواض الإخراج التي تدعمها، راجع دليل البرمجة الهيكلية لـ Apache Spark.
نقاط التفتيش وسجلات الكتابة المسبقة
لتوفير المرونة والتسامح مع الأخطاء، يعتمد Structured Streaming على checkpointing لضمان استمرار معالجة الدفق دون انقطاع، حتى مع فشل العقد. في HDInsight، ينشئ Spark نقاط فحص للتخزين الدائم، إما تخزين Azure أو تخزين بحيرة البيانات. تقوم نقاط التحقق هذه بتخزين معلومات التقدم حول الاستعلام المتدفق. بالإضافة إلى ذلك، يستخدم Structured Streaming سجل الكتابة المسبقة (WAL). يلتقط WAL البيانات التي تم إدخالها والتي تم استلامها ولكن لم تتم معالجتها بواسطة طلب بحث. إذا حدث فشل وتمت إعادة المعالجة من WAL، فلن يتم فقد أي أحداث مستلمة من المصدر.
توزيع تطبيقات Spark Streaming
تقوم عادةً بإنشاء تطبيق Spark Streaming محلياً في ملف JAR ثم توزيعه على Spark على HDInsight عن طريق نسخ ملف JAR إلى وحدة التخزين الافتراضية المرفقة بمجموعة HDInsight الخاصة بك. يمكنك بدء تطبيقك باستخدام واجهات برمجة تطبيقات REST Apache Livy المتوفرة من مجموعتك باستخدام عملية POST. يتضمن نص POST مستند JSON الذي يوفر المسار إلى JAR الخاص بك، واسم الفئة التي تحدد طريقتها الرئيسية تطبيق الدفق وتشغله، واختيارياً متطلبات الموارد للوظيفة (مثل عدد المنفذين والذاكرة والنوى)، وأي إعدادات تكوين يتطلبها رمز التطبيق الخاص بك.
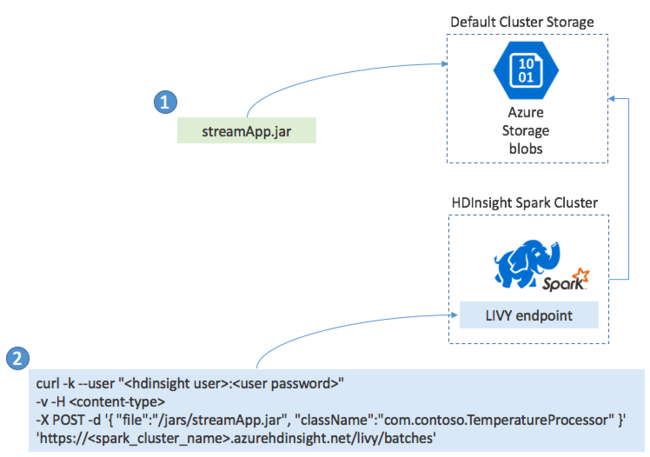
يمكن أيضاً التحقق من حالة جميع التطبيقات من خلال طلب GET مقابل نقطة نهاية LIVY. أخيراً، يمكنك إنهاء تطبيق قيد التشغيل عن طريق إصدار طلب DELETE مقابل نقطة نهاية LIVY. للحصول على تفاصيل حول LIVY API، راجع المهام عن بُعد باستخدام Apache LIVY