استثناءات OutOfMemoryError لـ Apache Spark في Azure HDInsight
توضح هذه المقالة خطوات استكشاف الأخطاء وإصلاحها، والحلول المحتملة للمشكلات عند استخدام مكونات Apache Spark في مجموعات Azure HDInsight.
السيناريو: استثناء OutOfMemoryError لـ Apache Spark
المشكلة
فشل تطبيق Apache Spark مع استثناء OutOfMemoryError لم تتم معالجته. قد تتلقى رسالة خطأ مشابهة لما يلي:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
السبب
السبب الأكثر احتمالاً لهذا الاستثناء هو عدم تخصيص كومة ذاكرة مؤقتة كافية لأجهزة Java الظاهرية (JVMs). يتم تشغيل JVMs هذه كمنفذات أو برامج تشغيل كجزء من تطبيق Apache Spark.
نوع الحل
حدد الحد الأقصى لحجم البيانات التي يعالجها تطبيق Spark. قم بعمل تقدير للحجم بناءً على الحجم الأقصى لبيانات الإدخال، والبيانات الوسيطة المنتجة عن طريق تحويل بيانات الإدخال وبيانات الإخراج الناتجة عن المزيد من تحويل البيانات الوسيطة. إذا لم يكن التقدير الأولي كافيا، فقم بزيادة الحجم قليلا، ثم التكرار حتى تهدأ أخطاء الذاكرة.
تأكد من أن مجموعة HDInsight التي سيتم استخدامها بها موارد كافية من حيث الذاكرة وأيضاً النوى لاستيعاب تطبيق Spark. يمكن تحديد ذلك من خلال عرض قسم Cluster Metrics في YARN UI الخاصة بنظام المجموعة لقيم الذاكرة المستخدمة مقابل إجمالي الذاكرة وVCores المستخدمة مقابل إجمالي VCores.

اضبط تكوينات Spark التالية على القيم المناسبة. موازنة متطلبات التطبيق مع الموارد المتاحة في الكتلة. يجب ألا تتجاوز هذه القيم 90٪ من الذاكرة والذاكرات الأساسية المتوفرة كما عرضها YARN، ويجب أن تفي أيضا بالحد الأدنى من متطلبات الذاكرة لتطبيق Spark:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)إجمالي الذاكرة المستخدمة من قبل جميع المنفذين =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)إجمالي الذاكرة المستخدمة من قبل السائق =
spark.driver.memory + spark.yarn.driver.memoryOverhead
السيناريو: خطأ مساحة كومة Java عند محاولة فتح خادم محفوظات Apache Spark
المشكلة
تتلقى الخطأ التالي عند فتح الأحداث في خادم Spark History:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
السبب
غالباً ما تحدث هذه المشكلة بسبب نقص الموارد عند فتح ملفات حدث شرارة كبيرة. يتم تعيين حجم كومة Spark افتراضياً على 1 غيغابايت، ولكن قد تتطلب ملفات أحداث Spark الكبيرة أكثر من ذلك.
إذا كنت ترغب في التحقق من حجم الملفات التي تحاول تحميلها، يمكنك تنفيذ الأوامر التالية:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
نوع الحل
يمكنك زيادة ذاكرة خادم Spark History عن طريق تحرير خاصية SPARK_DAEMON_MEMORY في تكوين Spark وإعادة تشغيل جميع الخدمات.
يمكنك القيام بذلك من داخل واجهة مستخدم متصفح Ambari عن طريق تحديد قسم Spark2 / Config / Advanced spark2-env.
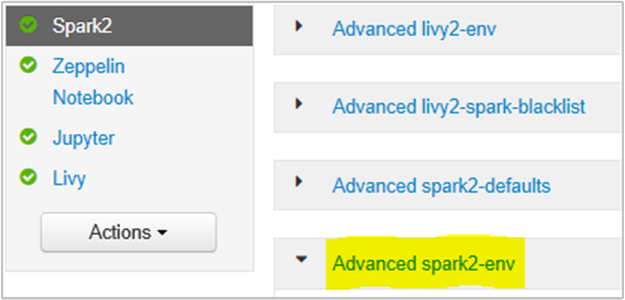
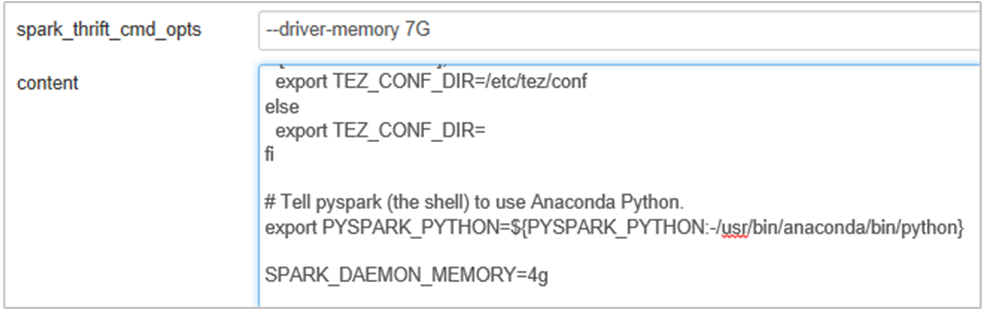
أضف الخاصية التالية لتغيير ذاكرة خادم Spark History من 1g إلى 4g: SPARK_DAEMON_MEMORY=4g.
تأكد من إعادة تشغيل جميع الخدمات المتأثرة من Ambari.
السيناريو: فشل Livy Server في البدء على مجموعة Apache Spark
المشكلة
لا يمكن بدء تشغيل Livy Server على Apache Spark [(Spark 2.1 على Linux (HDI 3.6)]. تؤدي محاولة إعادة التشغيل إلى ظهور مكدس الأخطاء التالي، من سجلات Livy:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
السبب
java.lang.OutOfMemoryError: unable to create new native thread يسلط الضوء على عدم قدرة نظام التشغيل على تعيين المزيد من مؤشرات الترابط الأصلية إلى JVMs. تم التأكيد على أن هذا الاستثناء ناتج عن انتهاك حد عدد مؤشرات الترابط لكل عملية.
عند إنهاء Livy Server بشكل غير متوقع، يتم أيضا إنهاء جميع الاتصالات إلى مجموعات Spark، مما يعني أن جميع المهام والبيانات ذات الصلة يتم فقدانها. تم تقديم آلية استرداد جلسة HDP 2.6، يقوم Livy بتخزين تفاصيل الجلسة في Zookeeper ليتم استردادها بعد عودة Livy Server.
عندما يتم إرسال عدد كبير من الوظائف عبر Livy، كجزء من التوفر العالي ل Livy Server يخزن حالات الجلسة هذه في ZK (على مجموعات HDInsight) واسترداد تلك الجلسات عند إعادة تشغيل خدمة Livy. عند إعادة التشغيل بعد الإنهاء غير المتوقع، تقوم Livy بإنشاء مؤشر ترابط واحد لكل جلسة عمل وهذا يتراكم بعض جلسات العمل المراد استردادها مما يتسبب في إنشاء عدد كبير جدا من مؤشرات الترابط.
نوع الحل
احذف جميع الإدخالات باستخدام الخطوات التالية.
احصل على عنوان IP الخاص بعقد zookeeper باستخدام
grep -R zk /etc/hadoop/confأدرج الأمر أعلاه جميع zookeepers لنظام مجموعة
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>احصل على كل عنوان IP لعقد zookeeper باستخدام ping أو يمكنك أيضا الاتصال ب zookeeper من عقدة الرأس باستخدام اسم zookeeper
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181بمجرد اتصالك ب zookeeper، قم بتنفيذ الأمر التالي لسرد جميع الجلسات التي تتم محاولة إعادة تشغيلها.
في معظم الحالات يمكن أن تكون هذه قائمة أكثر من 8000 جلسة ####
ls /livy/v1/batchالأمر التالي هو إزالة جميع الجلسات المراد استعادتها. #####
rmr /livy/v1/batch
انتظر حتى يكتمل الأمر أعلاه ويعيد المؤشر الموجه ثم أعد تشغيل خدمة Livy من Ambari، والتي يجب أن تنجح.
إشعار
DELETE الجلسة الحية بمجرد اكتمال تنفيذها. لن يتم حذف جلسات مجموعة Livy تلقائياً بمجرد اكتمال تطبيق شرارة، وهو حسب التصميم. جلسة Livy هي كيان تم إنشاؤه بواسطة طلب POST على خادم Livy REST. يلزم إجراء مكالمة DELETE لحذف هذا الكيان. أو يجب أن ننتظر بدء تشغيل GC.
الخطوات التالية
إذا لم تشاهد مشكلتك أو لم تتمكن من حلها، فتفضل بزيارة إحدى القنوات التالية للحصول على مزيد من الدعم:
احصل على إجابات من خبراء Azure عبر دعم مجتمع Azure.
تواصل مع @AzureSupport - حساب Microsoft Azure الرسمي لتحسين تجربة العملاء. توصيل الموارد المناسبة إلى مجتمع Azure: الإجابات، والدعم، والخبراء.
إذا كنت بحاجة إلى مزيد من المساعدة، فيمكنك إرسال طلب دعم من مدخل Microsoft Azure. حدد Support من شريط القائمة أو افتح المحور Help + support. لمزيد من المعلومات التفصيلية، راجع كيفية إنشاء طلب دعم Azure. يتم تضمين الوصول إلى إدارة الاشتراك ودعم الفواتير في اشتراك Microsoft Azure، ويتم توفير الدعم التقني من خلال إحدى خطط دعم Azure.