استخدم Pig مع Apache Hadoop على HDInsight
تعلم كيفية استخدام Apache Pig مع HDInsight.
Apache Pig هي منصة لإنشاء برامج لـ Apache Hadoop باستخدام لغة إجرائية تعرف باسم Pig Latin. Pig هو بديل Java لخلق حلول MapReduce، وهو مشمول مع Azure HDInsight. استخدم الجدول التالي لتكتشف الطرق المختلفة التي يمكن استخدام Pig بها مع HDInsight:
لماذا تستخدم Apache Pig
أحد التحديات التي تواجه معالجة البيانات باستخدام MapReduce في Hadoop هو تطبيق منطق المعالجة باستخدام خريطة فقط ودالة التقليل. للمعالجة المعقدة، غالبا ما تضطر لتقسيم المعالجة إلى عمليات MapReduce متعددة التي ترتبط معًا لتحقيق النتيجة المرجوة.
يسمح Pig بتعريف المعالجة على أنها سلسلة من التحولات التي تتدفق خلالها البيانات لإنتاج الإخراج المطلوب.
تسمح لغة Pig Latin بوصف تدفق البيانات من الإدخال الخام من خلال تحويل واحد أو أكثر لإنتاج الإخراج المطلوب. تتبع برامج Pig Lattin هذا النمط العام:
تحميل: قراءة البيانات التي يعالجها نظام الملفات.
تحويل: معالجة البيانات.
تفريغ أو تخزين: إظهار البيانات على الشاشة أو تخزينها للمعالجة.
الوظائف المعرفة بواسطة المستخدم
تدعم Pig Latin أيضًا الدالات المعرفة من قبل المستخدم (UDF)، التي تسمح لك باستدعاء المكونات الخارجية التي تنفذ المنطق الذي يصعب نمذجته في Pig Latin.
لمزيد من المعلومات عن Pig Latin، راجع دليل مراجع Pig Latin 1ودليل مرجع Pig Latin 2.
مثال على البيانات
يوفر HDInsight مختلف مجموعات البيانات المثال، التي تُخزن في /example/dataو/HdiSamples والدلائل. هذه الدلائل في التخزين الافتراضي لنظام المجموعة الخاصة بك. يستخدم مثال Pig في هذا المستند ملف log4j من /example/data/sample.log.
يتكون كل سجل داخل الملف من سطر من الحقول التي تحتوي على [LOG LEVEL] حقل لعرض النوع والشدة، على سبيل المثال:
2012-02-03 20:26:41 SampleClass3 [ERROR] verbose detail for id 1527353937
في المثال السابق، مستوى السجل خطأ.
إشعار
يمكنك أيضا إنشاء ملف log4j باستخدام أداة تسجيل Apache Log4j ثم تحميل هذا الملف إلى الكائن ثنائي كبير الحجم الخاص بك. راجع تحميل البيانات إلى HDInsight للحصول على تعليمات. لمزيد من المعلومات عن كيفية استخدام الكائن ثنائي كبير الحجم في Azure Storage مع HDInsight، راجع استخدام Azure Blob Storage مع HDInsight.
مثال الوظيفة
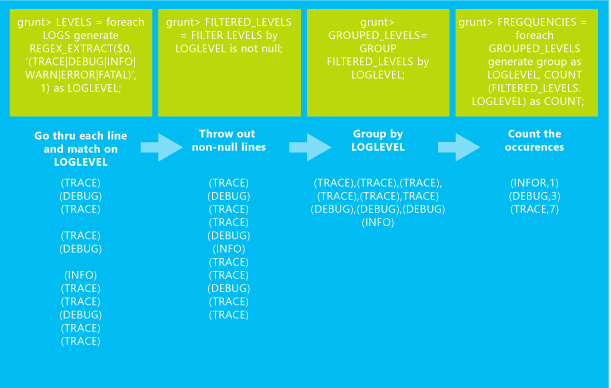
تحمل الوظيفة Pig Latin التالية sample.log الملف من التخزين الافتراضي لنظام مجموعة HDInsight الخاصة بك. ثم ينفذ سلسلة من التحويلات التي ينتج عنها عدد المرات التي حدث فيها كل مستوى تسجيل في بيانات الإدخال. تُكتب النتائج إلى STDOUT.
LOGS = LOAD 'wasb:///example/data/sample.log';
LEVELS = foreach LOGS generate REGEX_EXTRACT($0, '(TRACE|DEBUG|INFO|WARN|ERROR|FATAL)', 1) as LOGLEVEL;
FILTEREDLEVELS = FILTER LEVELS by LOGLEVEL is not null;
GROUPEDLEVELS = GROUP FILTEREDLEVELS by LOGLEVEL;
FREQUENCIES = foreach GROUPEDLEVELS generate group as LOGLEVEL, COUNT(FILTEREDLEVELS.LOGLEVEL) as COUNT;
RESULT = order FREQUENCIES by COUNT desc;
DUMP RESULT;
تعرض الصورة التالية ملخصًا لما يفعله كل تحويل بالبيانات.
تشغيل وظيفة Pig Latin
يمكن ل HDInsight تشغيل وظائف Pig Latin باستخدام أساليب مختلفة. استخدم الجدول التالي لتحديد الطريقة المناسبة لك ثم اتبع الارتباط للإرشادات التفصيلية.
Pig and SQL Server Integration Services
يمكنك استخدام خدمات تكامل SQL Server (SSIS) لتشغيل وظيفة Pig. توفر حزمة ميزة Azure لـ SSIS المكونات التالية التي تعمل مع وظائف Pig على HDInsight.
تعرف على المزيد عن حزمة ميزة Azure لـ SSIS هنا.
الخطوات التالية
الآن بعد أن تعلمت كيفية استخدام Pig مع HDInsight، استخدم الارتباطات التالية لاستكشاف طرق أخرى للعمل مع Azure HDInsight.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ