قابلية الوصول العالية والإصلاح بعد كارثة
كخطوة أولى نحو تنفيذ حل IoT مرن، يجب على المهندسين المعماريين والمطورين ومالكي الأعمال تحديد أهداف وقت التشغيل للحلول التي يقومون ببنائها. يمكن تحديد هذه الأهداف بشكل أساسي استنادًا إلى أهداف أعمال محددة لكل سيناريو. في هذا السياق، توضح المقالة Azure استمرارية الأعمال التوجيه الفني إطار عمل عام لمساعدتك في التفكير في استمرارية العمل والإصلاح بعد الكارثة. يوفر ورق الإصلاح بعد كارثة وقابلية الوصول العالية لتطبيقات Azure إرشادات البنية حول إستراتيجيات تطبيقات Azure لتحقيق قابلية الوصول العالية (HA) والإصلاح بعد كارثة (DR).
تتناول هذه المقالة ميزات قابلية الوصول العالية والإصلاح بعد الكارثة التي تقدمها خدمة IoT Hub على وجه التحديد. المجالات الواسعة التي تمت مناقشتها في هذه المقالة هي:
- قابلية الوصول العالية داخل المنطقة
- الإصلاح بعد كارثة عبر المناطق
- تحقيق قابلية الوصول العالية عبر المناطق
اعتمادا على أهداف وقت التشغيل التي تحددها لحلول IoT الخاصة بك، يجب عليك تحديد أي من الخيارات الموضحة في هذه المقالة تناسب أهداف عملك بشكل أفضل. يتطلب دمج أي من بدائل HA / الإصلاح بعد كارثة في حل إنترنت الأشياء الخاص بك تقييماً دقيقاً للمفاضلات بين:
- مستوى المرونة الذي تحتاجه
- تعقيد التنفيذ والصيانة
- تأثير COGS
قابلية الوصول العالية داخل المنطقة
توفر خدمة IoT Hub قابلية وصول عالية داخل المناطق، وذلك بتنفيذ التكرار في جميع طبقات الخدمة تقريباً. يتم تحقيق اتفاقية مستوى الخدمة التي نشرتها خدمة IoT Hub من خلال الاستفادة من هذه التكرارات. لا يتطلب مطورو حل IoT أي عمل إضافي للاستفادة من ميزات قابلية الوصول العالية هذه. على الرغم من أن IoT Hub يوفر ضمان وقت تشغيل عاليًا بشكل معقول، فإنه لا يزال من المتوقع حدوث حالات فشل عابرة كما هو الحال مع أي نظام أساسي للحوسبة الموزعة. إذا كنت بدأت للتو في ترحيل حلولك إلى السحابة من حل محلي، فإن تركيزك يحتاج إلى التحول من تحسين "متوسط الوقت بين حالات الفشل" إلى "متوسط الوقت للاسترداد". بمعنى آخر، يجب اعتبار حالات الفشل المؤقتة أمرًا طبيعيًا أثناء العمل مع السحابة في المزيج. يجب تضمين أنماط إعادة المحاولة المناسبة في المكونات التي تتفاعل مع تطبيق سحابي للتعامل مع حالات الفشل العابرة.
مجموعات التوافر
يدعم IoT Hub مناطق توفر Azure. منطقة التوفر هي عرض عالي التوفر يحمي التطبيقات والبيانات من حالات فشل مراكز البيانات. تتكون المنطقة التي تدعم منطقة التوفر من ثلاث مناطق تدعم تلك المنطقة. توفر كل منطقة مركز بيانات واحدا أو أكثر، كل منها في موقع فعلي فريد مع طاقة وتبريد وشبكة مستقلة. يوفر هذا التكوين النسخ المتماثل والتكرار داخل المنطقة.
توفر مناطق التوفر ميزتين: مرونة البيانات وتوزيعات أكثر سلاسة.
تأتي مرونة البيانات من استبدال خدمات التخزين الأساسية بالتخزين المدعوم بمناطق التوفر. تعد مرونة البيانات مهمة لحلول IoT لأن هذه الحلول غالبا ما تعمل في بيئات معقدة وديناميكية وغير مؤكدة حيث يمكن أن يكون للفشل أو الاضطرابات عواقب كبيرة. سواء كان حل IoT يدعم أرضية التصنيع أو بيئات البيع بالتجزئة أو المطاعم أو أنظمة الرعاية الصحية أو البنية الأساسية، فإن توفر البيانات وجودتها ضروريان للتعافي من الأعطال ولتقديم خدمات موثوقة ومتسقة.
تأتي عمليات النشر الأسلس من استبدال أجهزة مركز البيانات الأساسية بأجهزة أحدث تدعم مناطق التوفر. تقلل تحسينات الأجهزة هذه من تأثير العملاء من قطع اتصال الجهاز وإعادة الاتصال بالإضافة إلى وقت تعطل آخر متعلق بالنشر. ينشر فريق هندسة IoT Hub تحديثات متعددة لكل مركز IoT على الإطلاق، لكل من أسباب الأمان ولتوفيد تحسينات الميزات. يتم تقسيم الأجهزة المدعومة بمناطق التوفر إلى 15 مجال تحديث بحيث يصبح كل تحديث أكثر سلاسة، مع الحد الأدنى من التأثير على مهام سير العمل الخاصة بك. لمزيد من المعلومات حول مجالات التحديث، راجع مجموعات التوفر.
يتم تمكين دعم منطقة التوفر ل IoT Hub تلقائيا لموارد IoT Hub الجديدة التي تم إنشاؤها في مناطق Azure التالية:
| المنطقة | مرونة البيانات | عمليات نشر أكثر سلاسة |
|---|---|---|
| شرق أستراليا | ||
| جنوب البرازيل | ||
| وسط كندا | ||
| وسط الهند | ||
| Central US | ||
| شرق الولايات المتحدة | ||
| وسط فرنسا | ||
| وسط غرب ألمانيا | ||
| شرق اليابان | ||
| وسط كوريا | ||
| أوروبا الشمالية | ||
| شرق النرويج | ||
| قطر الوسطى | ||
| جنوب وسط الولايات المتحدة | ||
| جنوب شرق آسيا | ||
| جنوب المملكة المتحدة | ||
| أوروبا الغربية | ||
| West US 2 | ||
| غرب الولايات المتحدة الأمريكية 3 |
الإصلاح بعد كارثة عبر المناطق
قد تكون هناك بعض الحالات النادرة عندما يواجه مركز البيانات انقطاعات موسعة بسبب انقطاع التيار الكهربائي أو حالات فشل أخرى تنطوي على أصول مادية. هذه الأحداث نادرة حيث قد لا تساعد إمكانية قابلية الوصول العالية داخل المنطقة الموضحة سابقا دائما. يوفر IoT Hub حلولاً متعددة للتعافي من مثل هذه الانقطاعات الممتدة.
خيارات الاسترداد المتاحة للعملاء في مثل هذه الحالة هي تجاوز الفشل الذي بدأته Microsoftوتجاوز الفشل اليدوي. الفرق الأساسي بين الاثنين هو أن Microsoft تبدأ الأولى ويبدأ المستخدم الأخير. كما يوفر تجاوز الفشل اليدوي هدفًا أقل لوقت الاسترداد (RTO) مقارنة بخيار تجاوز الفشل الذي بدأته Microsoft. تتم مناقشة RTOs المحددة المقدمة مع كل خيار في الأقسام التالية. عند ممارسة أي من هذين الخيارين لتنفيذ تجاوز الفشل لمركز IoT من منطقته الأساسية، يصبح المركز يعمل بكامل طاقته في المنطقة المقترنة جغرافيًا المقابلة لـ Azure.
يوفر كلا خياري تجاوز الفشل هذين أهداف نقطة الاسترداد التالية (RPOs):
| نوع البيانات | أهداف نقطة الاسترداد (RPO) |
|---|---|
| تسجيل الهوية | فقدان البيانات من 0 إلى 5 دقائق |
| بيانات الجهاز المزدوج | فقدان البيانات من 0 إلى 5 دقائق |
| رسائل من مجموعة النظراء إلى الجهاز1 | فقدان البيانات من 0 إلى 5 دقائق |
| مهام الأصل1 والجهاز | فقدان البيانات من 0 إلى 5 دقائق |
| رسائل من جهاز إلى سحابة | يتم فقدان جميع الرسائل غير المقروءة |
| رسائل الملاحظات من السحابة إلى الجهاز | يتم فقدان جميع الرسائل غير المقروءة |
1لا يتم استرداد الرسائل من السحابة إلى الجهاز والمهام الأصلية كجزء من تجاوز الفشل اليدوي.
بمجرد اكتمال عملية تجاوز الفشل لمركز IoT، من المتوقع أن تستمر جميع العمليات من الجهاز والتطبيقات الخلفية في العمل دون الحاجة إلى تدخل يدوي. وهذا يعني أن رسائل الجهاز إلى السحابة يجب أن تستمر في العمل، وأن سجل الجهاز بأكمله سليم. يمكن استهلاك الأحداث المنبعثة عبر Event Grid عبر نفس الاشتراك (الاشتراكات) الذي تم تكوينه مسبقًا طالما أن اشتراكات Event Grid هذه لا تزال متوفرة. لا يلزم معالجة إضافية لنقاط النهاية المخصصة.
تنبيه
- يتغير الاسم المتوافق مع مراكز الأحداث ونقطة النهاية لنقطة نهاية الأحداث المضمنة في IoT Hub بعد تجاوز الفشل. عند تلقي رسائل بيانات تتبع الاستخدام من نقطة النهاية المضمنة باستخدام عميل مراكز الأحداث أو مضيف معالج الأحداث، يجب استخدام مركز IoT سلسلة الاتصال لتأسيس الاتصال. وهذا يضمن أن تطبيقاتك الخلفية تستمر في العمل دون الحاجة إلى تجاوز الفشل بعد التدخل اليدوي. إذا كنت تستخدم الاسم ونقطة النهاية المتوافقين مع Event Hub في التطبيق مباشرة، فستحتاج إلى إحضار نقطة النهاية الجديدة المتوافقة مع Event Hub بعد تجاوز الفشل لمتابعة العمليات. لمزيد من المعلومات، راجع تجاوز الفشل اليدوي ومركز الأحداث.
- إذا كنت تستخدم Azure Functions أو Azure Stream Analytics لتوصيل نقطة نهاية الأحداث المضمنة، فقد تحتاج إلى إجراء إعادة تشغيل. وذلك لأنه أثناء تجاوز الفشل لم تعد الإزاحات السابقة صالحة.
- عند التوجيه إلى وحدة التخزين، نوصي بإدراج النقاط الكبيرة أو الملفات ثم تكرارها للتأكد من قراءة جميع النقاط أو الملفات دون إجراء أي افتراضات بشأن التقسيم. من المحتمل أن يتغير نطاق القسم أثناء تجاوز الفشل الذي بدأته Microsoft أو تجاوز الفشل اليدوي. يمكنك استخدام List Blobs API لتعداد قائمة النقط الكبيرة أو List ADLS Gen2 API لقائمة الملفات. لمعرفة المزيد، راجع Azure Storage كنقطة نهاية توجيه.
تجاوز الفشل الذي بدأته Microsoft
تمارس Microsoft تجاوز الفشل الذي بدأه Microsoft في حالات نادرة للفشل عبر جميع مراكز IoT من منطقة متأثرة إلى المنطقة المقترنة جغرافيا المقابلة. هذه العملية هي خيار افتراضي ولا تتطلب أي تدخل من المستخدم. تحتفظ Microsoft بالحق في تحديد وقت ممارسة هذا الخيار. لا تتضمن هذه الآلية موافقة المستخدم قبل فشل لوحة الوصل الخاصة بالمستخدم. يحتوي تجاوز الفشل الذي بدأته Microsoft على هدف وقت الاسترداد (RTO) من 2 إلى 26 ساعة.
يرجع RTO الكبير إلى أنه يجب على Microsoft تنفيذ عملية تجاوز الفشل نيابة عن جميع العملاء المتأثرين في تلك المنطقة. إذا كنت تقوم بتشغيل حل IoT أقل أهمية يمكنه الحفاظ على وقت تعطل لمدة يوم تقريبا، فلا بأس بالنسبة لك أن تعتمد على هذا الخيار لتلبية أهداف التعافي من الكوارث الشاملة لحل IoT الخاص بك. يتم وصف إجمالي وقت تشغيل عمليات وقت التشغيل بالكامل بمجرد تشغيل هذه العملية، في قسم "وقت الاسترداد".
يمكن فقط للمستخدمين الذين ينشرون مراكز IoT في منطقتي جنوب البرازيل وجنوب شرق آسيا (سنغافورة) إلغاء الاشتراك في هذه الميزة. لمزيد من المعلومات، راجع تعطيل الإصلاح بعد الكارثة.
إشعار
لا يقوم Azure IoT Hub بتخزين بيانات العملاء أو معالجتها خارج المنطقة الجغرافية حيث تقوم بتوزيع مثيل الخدمة. لمزيد من المعلومات، راجع النسخ المتماثل عبر المناطق في Azure.
تجاوز الفشل اليدوي
إذا لم يتم استيفاء أهداف وقت تشغيل العمل من خلال RTO الذي يوفره تجاوز الفشل الذي بدأته Microsoft، ففكر في استخدام تجاوز الفشل اليدوي لتشغيل عملية تجاوز الفشل بنفسك. يمكن أن يكون RTO باستخدام هذا الخيار في أي مكان بين 10 دقائق إلى بضع ساعات. RTO هو حاليًا دالة لعدد الأجهزة المسجلة مقابل مثيل مركز IoT الذي تم تجاوز فشله. يمكنك أن تتوقع RTO للمحور الذي يستضيف ما يقرب من 100000 جهاز في الملعب لمدة 15 دقيقة. يتم وصف إجمالي وقت تشغيل عمليات وقت التشغيل بالكامل بمجرد تشغيل هذه العملية، في قسم "وقت الاسترداد".
يتوفر خيار تجاوز الفشل اليدوي دائمًا للاستخدام بصرف النظر عما إذا كانت المنطقة الأساسية تواجه وقت تعطل أم لا. لذلك، يمكن استخدام هذا الخيار لتنفيذ عمليات تجاوز الفشل المخطط لها. أحد الأمثلة على استخدام عمليات تجاوز الفشل المخطط لها هو إجراء تدريبات دورية لتجاوز الفشل. على الرغم من ذلك، هناك كلمة تحذير تشير إلى أن عملية تجاوز الفشل المخطط لها تؤدي إلى توقف المركز للفترة المحددة بواسطة RTO لهذا الخيار، كما تؤدي إلى فقدان البيانات كما هو محدد من قبل جدول RPO أعلاه. يمكنك التفكير في إعداد مثيل مركز IoT تجريبي لممارسة خيار تجاوز الفشل المخطط له بشكل دوري لاكتساب الثقة في قدرتك على تشغيل الحلول الشاملة وتشغيلها عند حدوث كارثة حقيقية.
يتوفر تجاوز الفشل اليدوي دون أي تكلفة إضافية لمراكز IoT التي تم إنشاؤها بعد 18 مايو 2017
للحصول على إرشادات خطوة بخطوة، راجع البرنامج التعليمي: تنفيذ تجاوز الفشل اليدوي لمركز IoT
تجاوز الفشل اليدوي ومراكز الأحداث
يتغير الاسم المتوافق مع مراكز الأحداث ونقطة النهاية لنقطة نهاية الأحداث المضمنة في IoT Hub بعد تجاوز الفشل اليدوي. وذلك لأن عميل Event Hubs ليس لديه رؤية في أحداث IoT Hub. وينطبق الشيء نفسه على العملاء الآخرين المستندين إلى السحابة مثل الوظائف وتحليلات Azure Stream. لاسترداد نقطة النهاية والاسم، يمكنك استخدام مدخل Microsoft Azure أو .NET SDK.
استخدام المدخل
لمزيد من المعلومات حول استخدام المدخل لاسترداد نقطة النهاية المتوافقة مع Event Hub والاسم المتوافق مع Event Hub، راجع الاتصال إلى نقطة النهاية المضمنة.
استخدم .NET عدة تطوير البرامج
لاستخدام سلسلة الاتصال IoT Hub لاستعادة نقطة النهاية المتوافقة مع مراكز الأحداث، استخدم عينة موجودة في https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubs. يستخدم مثال التعليمات البرمجية سلسلة الاتصال للحصول على نقطة نهاية مراكز الأحداث الجديدة وإعادة إنشاء الاتصال. يجب أن يكون لديك Visual Studio تثبيت.
تشغيل تدريبات الاختبار
لا ينبغي إجراء تدريبات الاختبار على مراكز IoT التي يتم استخدامها في بيئات الإنتاج الخاصة بك.
لا تستخدم تجاوز الفشل اليدوي لترحيل مركز IoT إلى منطقة مختلفة
لا يجب استخدام تجاوز الفشل اليدوي كآلية لترحيل لوحة الوصل بشكل دائم بين المناطق المقترنة بـ Azure الجغرافية. بافتراض أن الأجهزة كانت موجودة الأقرب إلى المنطقة الأساسية للمركز، سيزداد زمن الانتقال للعمليات التي يتم تنفيذها مقابل مركز IoT عندما يفشل المركز في الوصول إلى منطقة ثانوية.
إرجاع الموارد
يمكنك العودة إلى المنطقة الأساسية القديمة عن طريق تشغيل إجراء تجاوز الفشل مرة ثانية. إذا تم تنفيذ عملية تجاوز الفشل الأصلية للتعافي من انقطاع التيار الكهربائي الموسع في المنطقة الأساسية الأصلية، نوصي بفشل المركز مرة أخرى إلى الموقع الأصلي بمجرد استرداد هذا الموقع من حالة الانقطاع.
هام
- يسمح للمستخدمين فقط بإجراء عمليتين ناجحتين لتجاوز الفشل وعمليتين ناجحتين لإرجاع الموارد يوميًا.
- لا يسمح بالعودة إلى عمليات تجاوز الفشل/إرجاع الموارد. يجب الانتظار لمدة ساعة واحدة بين هذه العمليات.
وقت الاسترداد
في حين أن FQDN (وبالتالي سلسلة الاتصال) لمثيل مركز IoT يظل هو نفسه بعد تجاوز الفشل، يتغير عنوان IP الأساسي. وقت عمليات وقت التشغيل التي يتم تنفيذها مقابل مثيل مركز IoT الخاص بك لتصبح تعمل بشكل كامل بعد أن يمكن التعبير عن عملية تجاوز الفشل باستخدام الدالة التالية:
وقت الاسترداد = RTO [10 دقائق - ساعتان لتجاوز الفشل اليدوي | من 2 إلى 26 ساعة لتجاوز الفشل الذي بدأته Microsoft] + تأخير نشر DNS + الوقت الذي يستغرقه تطبيق العميل لتحديث أي عنوان IP لـ IoT Hub مخزن مؤقتًا.
هام
لا تقوم IoT SDKs بالتخزين المؤقت لعنوان IP لمركز IoT. نوصي بعدم تخزين عنوان IP لمركز IoT في ذاكرة التخزين المؤقت للتعليمات البرمجية للمستخدم مع SDKs.
تعطيل الإصلاح بعد كارثة
يوفر IoT Hub Microsoft-Initiated تجاوز الفشل وتجاوز الفشل اليدوي عن طريق نسخ البيانات نسخًا متماثلاً إلى المنطقة المقترنة لكل مركز IoT. بالنسبة إلى بعض المناطق، يمكنك تجنب النسخ المتماثل للبيانات خارج المنطقة عن طريق تعطيل التعافي من الكوارث عند إنشاء مركز IoT. تدعم المناطق التالية هذه الميزة:
- جنوب البرازيل؛ المنطقة المقترنة، جنوب وسط الولايات المتحدة.
- جنوب شرق آسيا (سنغافورة)؛ المنطقة المقترنة، شرق آسيا (منطقة هونغ كونغ الإدارية الخاصة).
لتعطيل الإصلاح بعد كارثة في المناطق المدعومة، تأكد من أن تمكين التعافي من الكوارث غير محدد عند إنشاء مركز IoT الخاص بك:
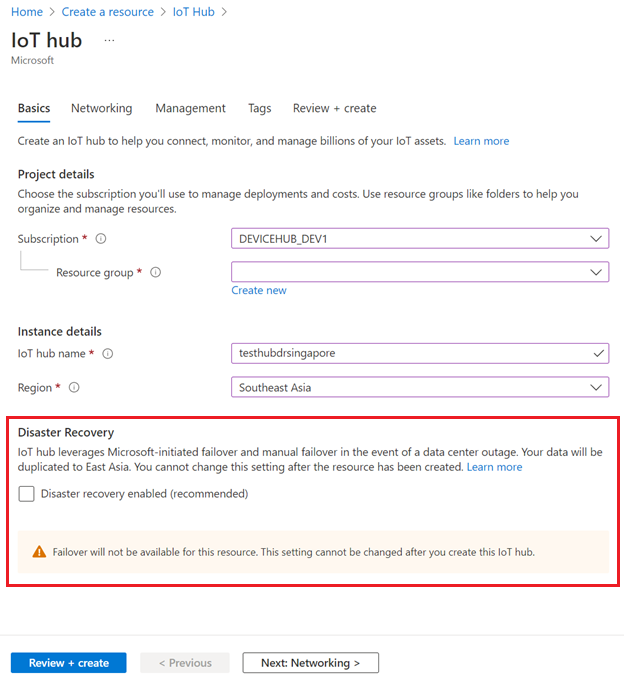
يمكنك أيضًا تعطيل الإصلاح بعد كارثة عند إنشاء مركز IoT باستخدام قالب ARM.
لن تتوفر إمكانية تجاوز الفشل إذا قمت بتعطيل التعافي من الكوارث لمركز IoT.
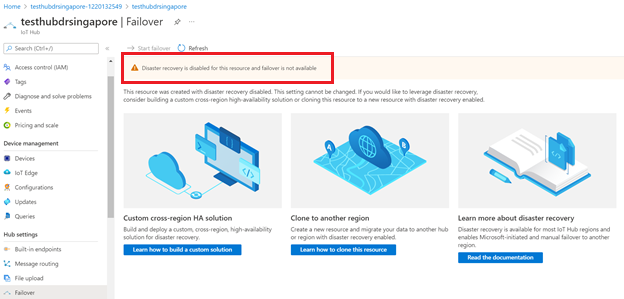
يمكنك فقط تعطيل الإصلاح بعد كارثة لتجنب النسخ المتماثل للبيانات خارج المنطقة المقترنة في جنوب البرازيل أو جنوب شرق آسيا عند إنشاء مركز IoT. إذا كنت ترغب في تكوين مركز IoT الحالي لتعطيل الإصلاح بعد كارثة، فأنت بحاجة إلى إنشاء مركز IoT جديد مع تعطيل التعافي من الكوارث وترحيل مركز IoT الحالي يدويًا. للحصول على إرشادات، راجع كيفية ترحيل مركز IoT.
تحقيق قابلية الوصول العالية عبر المنطقة
إذا لم تكن أهداف وقت تشغيل عملك راضية عن طريق هدف وقت الاسترداد (RTO) الذي توفره خيارات تجاوز الفشل التي بدأتها Microsoft أو خيارات تجاوز الفشل اليدوي، فيجب أن تفكر في تنفيذ آلية تجاوز الفشل التلقائي عبر المنطقة لكل جهاز. معالجة كاملة من طبولوجيا النشر في حلول IoT خارج نطاق هذه المقالة. تتناول المقالة نموذج توزيع تجاوز الفشل الإقليمي لقابلية الوصول العالية والتعافي من الكوارث.
في نموذج تجاوز الفشل الإقليمي، يتم تشغيل النهاية الخلفية للحل بشكل أساسي في موقع مركز بيانات واحد. يتم نشر مركز IoT ثانوي وواجهة خلفية في موقع مركز بيانات آخر. إذا كان مركز IoT في المنطقة الأساسية يعاني من انقطاع أو تمت مقاطعة اتصال الشبكة من الجهاز إلى المنطقة الأساسية، تستخدم الأجهزة نقطة نهاية خدمة ثانوية. يمكنك تحسين توفر الحل من خلال تنفيذ نموذج تجاوز الفشل عبر المناطق بدلاً من البقاء داخل منطقة واحدة.
على مستوى عال، لتنفيذ نموذج تجاوز الفشل الإقليمي مع IoT Hub، تحتاج إلى اتخاذ الخطوات التالية:
مركز IoT ثانوي ومنطق توجيه الجهاز: إذا تم تعطيل الخدمة في منطقتك الأساسية، يجب أن تبدأ الأجهزة في الاتصال بمنطقتك الثانوية. نظرًا إلى الطبيعة المدركة للحالة لمعظم الخدمات المعنية، فمن الشائع أن يقوم مسؤولو الحلول بتشغيل عملية تجاوز الفشل بين المناطق. أفضل طريقة لتوصيل نقطة النهاية الجديدة بالأجهزة، مع الحفاظ على التحكم في العملية، هي جعلها تتحقق بانتظام من خدمة concierge لنقطة النهاية النشطة الحالية. يمكن أن تكون خدمة concierge تطبيق ويب يتم نسخه نسخًا متماثلاً ويبقى قابلاً للوصول باستخدام تقنيات إعادة توجيه DNS (على سبيل المثال، باستخدام Azure Traffic Manager).
إشعار
خدمة مركز IoT ليست نوع نقطة نهاية مدعومًا في Azure Traffic Manager. التوصية هي دمج خدمة concierge المقترحة مع مدير نسبة استخدام الشبكة من Azure عن طريق جعلها تنفذ واجهة برمجة تطبيقات فحص صحة نقطة النهاية.
النسخ المتماثل لسجل الهوية: لكي يكون قابلاً للاستخدام، يجب أن يحتوي مركز IoT الثانوي على جميع هويات الجهاز التي يمكنها الاتصال بالحل. يجب أن يحتفظ الحل بالنسخ الاحتياطية المنسوخة جغرافيًا لهويات الجهاز، وتحميلها إلى مركز IoT الثانوي قبل تبديل نقطة النهاية النشطة للأجهزة. وظيفة تصدير هوية الجهاز لـ IoT Hub مفيدة في هذا السياق. لمزيد من المعلومات، راجع دليل مطور IoT Hub - سجل الهوية.
منطق الدمج: عندما تصبح المنطقة الأساسية متاحة مرة أخرى، يجب ترحيل جميع الحالة والبيانات التي تم إنشاؤها في الموقع الثانوي مرة أخرى إلى المنطقة الأساسية. تتعلق هذه الحالة والبيانات في الغالب بهويات الجهاز وبيانات تعريف التطبيق، والتي يجب دمجها مع مركز IoT الأساسي وأي مخازن أخرى خاصة بالتطبيق في المنطقة الأساسية.
لتبسيط هذه الخطوة، يجب استخدام عمليات متكررة. تقلل العمليات المتكررة من الآثار الجانبية من التوزيع المتسق النهائي للأحداث، ومن التكرارات أو التسليم غير النظامي للأحداث. بالإضافة إلى ذلك، يجب تصميم منطق التطبيق للتسامح مع التناقضات المحتملة أو الحالة غير المحدثة قليلاً. يمكن أن يحدث هذا الموقف بسبب الوقت الإضافي الذي يستغرقه النظام للشفاء بناء على أهداف نقطة الاسترداد (RPO).
اختر خيار الوصول العالية/الإصلاح بعد الكوارث الصحيح
فيما يلي ملخص لخيارات قابلية الوصول العالية/الإصلاح بعد الكوارث المعروضة في هذه المقالة، والتي يمكن استخدامها كإطار مرجعي لاختيار الخيار المناسب الذي يناسب الحل الخاص بك.
| خيار الوصول العالية/الإصلاح بعد الكوارث | هدف وقت الاسترداد (RTO) | هدف نقطة الاسترداد (RPO) | هل يُتطلب تدخل يدوي؟ | تعقيدات التنفيذ | تأثير التكلفة |
|---|---|---|---|---|---|
| تجاوز الفشل الذي بدأته Microsoft | 2 - 26 ساعة | الرجوع إلى جدول RPO أعلاه | لا | بلا | بلا |
| تجاوز الفشل اليدوي | 10 دقائق - ساعتان | الرجوع إلى جدول RPO أعلاه | نعم | منخفض جدًا. تحتاج فقط إلى تشغيل هذه العملية من المدخل. | بلا |
| عبر المنطقة HA | < دقيقة واحدة | يعتمد على تكرار النسخ المتماثل لحل قابلية الوصول العالية المخصص | لا | درجة عالية | > 1x تكلفة مركز IoT 1 |
الخطوات التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ