مكون Partition and Sample
توضح هذه المقالة مكونا في مصمم التعلم الآلي Azure.
استخدم مكون Partition and Sample لإجراء أخذ العينات على مجموعة بيانات أو لإنشاء أقسام من مجموعة البيانات الخاصة بك.
أخذ العينات هو أداة مهمة في التعلم الآلي لأنه يتيح لك تقليل حجم مجموعة البيانات مع الحفاظ على نفس نسبة القيم. يدعم هذا المكون العديد من المهام ذات الصلة والمهمة في التعلم الآلي:
تقسيم البيانات الخاصة بك إلى أقسام فرعية متعددة من نفس الحجم.
يمكنك استخدام الأقسام للتحقق المشترك، أو لتعيين حالات لمجموعات عشوائية.
فصل البيانات إلى مجموعات ثم العمل مع البيانات من مجموعة معينة.
بعد تعيين الحالات عشوائياً لمجموعات مختلفة، قد تحتاج إلى تعديل الميزات المرتبطة بمجموعة واحدة فقط.
أخذ العينات.
يمكنك استخراج نسبة مئوية من البيانات، أو تطبيق عينات عشوائية، أو اختيار عمود لاستخدامه في موازنة مجموعة البيانات وإجراء أخذ عينات طبقية على قيمها.
إنشاء مجموعة بيانات أصغر للاختبار.
إذا كان لديك الكثير من البيانات، فقد ترغب في استخدام الصفوف n الأولى فقط أثناء إعداد مسار التدفق، ثم التبديل إلى استخدام مجموعة البيانات الكاملة عند إنشاء النموذج الخاص بك. يمكنك أيضاً استخدام أخذ العينات لإنشاء مجموعة بيانات أصغر لاستخدامها في التطوير.
تكوين المكون
يدعم هذا المكون الطرق التالية لتقسيم بياناتك إلى أقسام أو لأخذ العينات. اختر الطريقة أولاً، ثم قم بتعيين الخيارات الإضافية التي تتطلبها الطريقة.
- الرأس
- أخذ نماذج
- تعيين للطيات
- اختر أضعاف
احصل على صفوف TOP N من مجموعة بيانات
استخدم هذا الوضع للحصول على أول ن من الصفوف فقط. يكون هذا الخيار مفيداً إذا كنت تريد اختبار تدفق على عدد صغير من الصفوف، ولا تحتاج إلى موازنة البيانات أو أخذ عينات منها بأي شكل من الأشكال.
أضف مكوِّن Partition and Sample إلى مسار التدفق الخاص بك في الواجهة، وقم بتوصيل مجموعة البيانات.
وضع التقسيم أو العينة: عيِّن هذا الخيار على Head.
عدد الصفوف المراد تحديدها: أدخل عدد الصفوف المراد عرضها.
يجب أن يكون عدد الصفوف عدداً صحيحاً غير سالب. إذا كان عدد الصفوف المحددة أكبر من عدد الصفوف في مجموعة البيانات، يتم إرجاع مجموعة البيانات بأكملها.
إرسال المسار.
يُخرج المكون مجموعة بيانات واحدة تحتوي فقط على عدد محدد من الصفوف. تتم قراءة الصفوف دائماً من أعلى مجموعة البيانات.
قم بإنشاء عينة من البيانات
يدعم هذا الخيار أخذ العينات العشوائية البسيطة أو العينات العشوائية الطبقية. إنه مفيد إذا كنت تريد إنشاء مجموعة بيانات نموذجية أصغر للاختبار.
أضف مكوِّن Partition and Sample إلى مسار التدفق الخاص بك، وقم بتوصيل مجموعة البيانات.
Partition or sample mode: عيِّن هذا الخيار على Sampling.
Rate of sampling: أدخل قيمة بين 0 و1. تحدد هذه القيمة النسبة المئوية للصفوف من مجموعة البيانات المصدر التي يجب تضمينها في مجموعة بيانات الإخراج.
على سبيل المثال، إذا كنت تريد فقط نصف مجموعة البيانات الأصلية، فأدخل
0.5للإشارة إلى أن معدل أخذ العينات يجب أن يكون 50 بالمائة.يتم خلط صفوف مجموعة بيانات الإدخال ووضعها بشكل انتقائي في مجموعة بيانات الإخراج، وفقاً للنسبة المحددة.
Random seed for sampling: اختيارياً، أدخل عدداً صحيحاً لاستخدامه كقيمة أولية.
هذا الخيار مهم إذا كنت تريد تقسيم الصفوف بالطريقة نفسها في كل مرة. القيمة الافتراضية هي 0، ما يعني أنه يتم إنشاء أولية البداية بناءً على ساعة النظام. يمكن أن تؤدي هذه القيمة إلى نتائج مختلفة قليلاً في كل مرة تقوم فيها بتشغيل مسار التدفق.
Stratified split for sampling: حدد هذا الخيار إذا كان من المهم أن يتم تقسيم الصفوف في مجموعة البيانات بالتساوي بواسطة بعض الأعمدة الرئيسية قبل أخذ العينات.
في tratification key column for sampling، حدد strata column واحداً لاستخدامه عند قسمة مجموعة البيانات. يتم بعد ذلك تقسيم الصفوف في مجموعة البيانات على النحو التالي:
جميع صفوف الإدخال مجمعة (طبقية) حسب القيم الموجودة في عمود الطبقات المحدد.
يتم تبديل الصفوف داخل كل مجموعة.
تتم إضافة كل مجموعة بشكل انتقائي إلى مجموعة بيانات الإخراج لتلبية النسبة المحددة.
إرسال المسار.
باستخدام هذا الخيار، يُخرج المكون مجموعة بيانات واحدة تحتوي على عينة تمثيلية من البيانات. لم يتم إخراج الجزء المتبقي غير المستند إلى عينات من مجموعة البيانات.
تقسيم البيانات إلى أقسام
استخدم هذا الخيار عندما تريد تقسيم مجموعة البيانات إلى مجموعات فرعية من البيانات. يكون هذا الخيار مفيداً أيضاً عندما تريد إنشاء عدد مخصص من الطيات للتحقق المتبادل، أو لتقسيم الصفوف إلى عدة مجموعات.
أضف مكوِّن Partition and Sample إلى مسار التدفق الخاص بك، وقم بتوصيل مجموعة البيانات.
في Partition or sample mode، حدد Assign to Folds.
Use replacement in the partitioning: حدد هذا الخيار إذا كنت تريد إعادة صف العينة إلى مجموعة الصفوف لإعادة الاستخدام المحتملة. نتيجة لذلك، قد يتم تعيين نفس الصف لعدة طيات.
إذا كنت لا تستخدم الاستبدال (الخيار الافتراضي)، فلن تتم إعادة صف العينة إلى مجموعة الصفوف لإعادة الاستخدام المحتملة. نتيجة لذلك، يمكن تخصيص كل صف لطية واحدة فقط.
Randomized split: حدد هذا الخيار إذا كنت تريد أن يتم تخصيص الصفوف بشكل عشوائي للطيات.
إذا لم تحدد هذا الخيار، فسيتم تخصيص الصفوف للطيات من خلال طريقة round-robin.
البذور العشوائية: اختيارياً، أدخل عدداً صحيحاً لاستخدامه كقيمة أولية. هذا الخيار مهم إذا كنت تريد تقسيم الصفوف بالطريقة نفسها في كل مرة. وإلا، فإن القيمة الافتراضية لـ 0 تعني أنه سيتم استخدام بداية عشوائية.
Specify the partitioner method: وضح كيف تريد تقسيم البيانات لكل قسم، باستخدام هذه الخيارات:
التقسيم بالتساوي: استخدم هذا الخيار لوضع عدد متساوٍ من الصفوف في كل قسم. لتحديد عدد أقسام الإخراج، أدخل عدداً صحيحاً في المربع Specify number of folds to split evenly into.
قسم بنسب مخصصة: استخدم هذا الخيار لتحديد حجم كل قسم على هيئة قائمة مفصولة بفواصل.
على سبيل المثال، افترض أنك تريد إنشاء ثلاثة أقسام. سيحتوي القسم الأول على 50 بالمائة من البيانات. سيحتوي القسمان المتبقيان على 25 بالمائة من البيانات. في المربع List of proportions separated by comma، أدخل هذه الأرقام: .5، .25، .25.
يجب أن يصل مجموع جميع أحجام الأقسام إلى 1 بالضبط.
إذا أدخلت أرقاماً تضيف ما يصل إلى أقل من 1، فسيتم إنشاء قسم إضافي لاستيعاب الصفوف المتبقية. على سبيل المثال، إذا أدخلت القيمتين .2 و.3، فسيتم إنشاء قسم ثالث لاستيعاب نسبة 50 بالمائة المتبقية من جميع الصفوف.
إذا أدخلت أرقاماً تضيف ما يصل إلى أكثر من 1، فسيظهر خطأ عند تشغيل مسار التدفق.
Stratified split: حدد هذا الخيار إذا كنت تريد أن يتم تقسيم الصفوف إلى طبقات عند الانقسام، ثم اختر strata column.
إرسال المسار.
باستخدام هذا الخيار، يُخرج المكون مجموعات بيانات متعددة. يتم تقسيم مجموعات البيانات وفقاً للقواعد التي حددتها.
استخدم البيانات من قسم محدد مسبقاً
استخدم هذا الخيار عندما تقوم بتقسيم مجموعة بيانات إلى أقسام متعددة وتريد الآن تحميل كل قسم بدوره لمزيد من التحليل أو المعالجة.
أضف مكوِّن Partition and Sample إلى مسار التدفق.
قم بتوصيل المكون بإخراج مثيل سابق من Partition and Sample. يجب أن يكون هذا المثيل قد استخدم خيار Assign to Folds لإنشاء عدد من الأقسام.
Partition or sample mode: حدد Pick Fold.
Specify which fold to be sampled from: حدد القسم الذي تريد استخدامه عن طريق إدخال الفهرس الخاص به. مؤشرات التقسيم تستند إلى 1. على سبيل المثال، إذا قسمت مجموعة البيانات إلى ثلاثة أجزاء، فستحتوي الأقسام على المؤشرات 1 و2 و3.
إذا أدخلت قيمة فهرس غير صالحة، يظهر خطأ وقت التصميم: "خطأ 0018: مجموعة البيانات تحتوي على بيانات غير صالحة."
بالإضافة إلى تجميع مجموعة البيانات حسب الطيات، يمكنك فصل مجموعة البيانات إلى مجموعتين: الطية المستهدفة وكل شيء آخر. للقيام بذلك، أدخل فهرس الطية الواحدة، ثم حدد الخيار Pick complement of the selected fold للحصول على كل شيء ما عدا البيانات الموجودة في الطية المحددة.
إذا كنت تعمل باستخدام أقسام متعددة، فتجب إضافة المزيد من مثيلات المكون Partition and Sample للتعامل مع كل قسم.
على سبيل المثال، تم تعيين مكون Partition and Sample في الصف الثاني على Assign to Folds، ويتم تعيين المكون في الصف الثالث على Pick Fold.
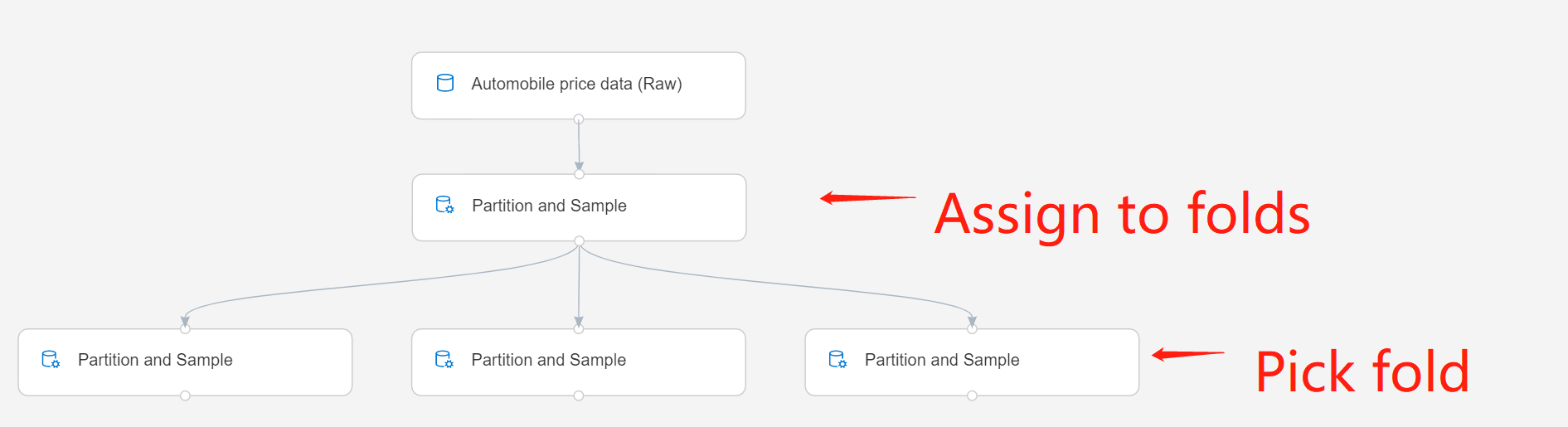
إرسال المسار.
باستخدام هذا الخيار، يُخرج المكون مجموعة بيانات واحدة تحتوي فقط على الصفوف المخصصة لتلك الطية.
ملاحظة
لا يمكنك عرض تسميات الطيات مباشرة. هي موجودة فقط في بيانات التعريف.
الخطوات التالية
راجع مجموعة المكونات المتوفرة للتعلم الآلي من Azure.