إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
تقارن هذه المقالة التعلم العميق بالتعلم الآلي وتصف كيف تتناسب مع الفئة الأوسع من الذكاء الاصطناعي. تعرف على حلول التعلم العميق التي يمكنك بناءها على التعلم الآلي من Azure، مثل الكشف عن الاحتيال، والتعرف على الصوت والوجه، وتحليل المشاعر، والتنبؤ بالسلاسل الزمنية.
للحصول على إرشادات حول اختيار الخوارزميات للحلول الخاصة بك، راجع ورقة المعلومات المرجعية لخوارزمية التعلم الآلي.
نماذج المسبك في التعلم الآلي من Microsoft Azure هي نماذج تعلم عميق مدربة مسبقا يمكن ضبطها لحالات استخدام محددة. لمزيد من المعلومات، راجع استكشاف نماذج مايكروسوفت فاوندري في التعلم الآلي في Azureوكيفية استخدام نماذج الأساس مفتوحة المصدر التي تم تنسيقها بواسطة Azure Machine Learning.
التعلم العميق والتعلم الآلي الذكاء الاصطناعي
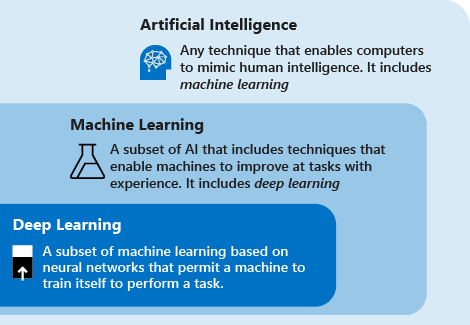
تصف التعريفات التالية العلاقات بين التعلم العميق والتعلم الآلي الذكاء الاصطناعي:
التعلم العميق هو مجموعة فرعية من التعلم الآلي التي تستند إلى الشبكات العصبية الاصطناعية. عملية التعلمعميقة لأن بنية الشبكات العصبية الاصطناعية تتكون من عدة مدخلات ومخرجات وطبقات مخفية. تحتوي كل طبقة على وحدات تحول بيانات الإدخال إلى معلومات يمكن للطبقة التالية استخدامها لمهمة تنبؤية معينة. بسبب هذا الهيكل ، يمكن للآلة التعلم من خلال معالجة البيانات الخاصة بها.
التعلم الآلي هو مجموعة فرعية من الذكاء الاصطناعي يستخدم تقنيات (مثل التعلم العميق) التي تمكن الآلات من استخدام الخبرة لتحسين قدرتها على أداء المهام. تتكون عملية التعلم من الخطوات التالية:
- تغذية البيانات في خوارزمية. (في هذه الخطوة، يمكنك توفير معلومات إضافية للنموذج، على سبيل المثال، عن طريق إجراء استخراج الميزة.)
- استخدم هذه البيانات لتدريب نموذج.
- اختبار النموذج ونشره.
- استهلاك النموذج المنشور للقيام بمهمة تنبؤية تلقائية. (بمعنى آخر، قم باستدعاء النموذج المنشور واستخدامه لتلقي التنبؤات التي تم إرجاعها بواسطة النموذج.)
الذكاء الاصطناعي هو تقنية تمكن أجهزة الكمبيوتر من تقليد الذكاء البشري. ويشمل التعلم الآلي.
الذكاء الاصطناعي التوليدي هو مجموعة فرعية من الذكاء الاصطناعي الذي يستخدم تقنيات (مثل التعلم العميق) لإنشاء محتوى جديد. على سبيل المثال، يمكنك استخدام الذكاء الاصطناعي التوليدية لإنشاء صور أو نص أو صوت. تستخدم هذه النماذج كميات هائلة من المعرفة المدربة مسبقا لإنشاء هذا المحتوى.
باستخدام التعلم الآلي وتقنيات التعلم العميق، يمكنك إنشاء أنظمة الكمبيوتر والتطبيقات التي تقوم بمهام ترتبط عادة بالذكاء البشري. تتضمن هذه المهام التعرف على الصور والتعرف على الكلام وترجمة اللغة.
تقنيات التعلم العميق والتعلم الآلي
الآن بعد أن أصبح لديك فهم أساسي لكيفية اختلاف التعلم الآلي عن التعلم العميق ، دعنا نقارن بين التقنيتين. في التعلم الآلي ، يجب إخبار الخوارزمية بكيفية إجراء تنبؤ دقيق من خلال استهلاك المزيد من المعلومات. (على سبيل المثال، عن طريق إجراء استخراج الميزة.) في التعلم العميق ، يمكن للخوارزمية أن تتعلم كيفية إجراء تنبؤ دقيق من خلال معالجة البيانات الخاصة بها لأنها تستخدم بنية الشبكة العصبية الاصطناعية.
يقارن الجدول التالي الأسلوبين بمزيد من التفصيل:
| التعلّم الآلي | التعلم العميق | |
|---|---|---|
| عدد نقاط البيانات | يمكن استخدام كميات صغيرة من البيانات لإجراء تنبؤات. | يحتاج إلى استخدام كميات كبيرة من بيانات التدريب لإجراء تنبؤات. |
| تبعيات الأجهزة | يمكن أن تعمل على الأجهزة منخفضة النهاية. لا يحتاج إلى كمية كبيرة من القوة الحسابية. | يعتمد على الأجهزة المتطورة. يقوم بطبيعتها بعدد كبير من عمليات ضرب المصفوفة. يمكن لوحدة معالجة الرسومات تحسين هذه العمليات بكفاءة. |
| عملية التمييز | يتطلب تحديد الميزات وإنشاءها بدقة من قبل المستخدمين. | يتعلم ميزات عالية المستوى من البيانات وينشئ ميزات جديدة في حد ذاته. |
| نهج التعلم | يقسم عملية التعلم إلى خطوات أصغر. ثم يجمع بين النتائج من كل خطوة إلى إخراج واحد. | ينتقل خلال عملية التعلم عن طريق حل المشكلة على أساس شامل. |
| وقت التدريب | يستغرق التدريب بعض الوقت نسبيا، بدءا من بضع ثوان إلى بضع ساعات. | عادة ما يستغرق التدريب وقتا طويلا لأن خوارزمية التعلم العميق تتضمن العديد من الطبقات. |
| إخراج |
عادة ما يكون الإخراج قيمة رقمية، مثل درجة أو تصنيف. | يمكن أن يحتوي الإخراج على تنسيقات متعددة ، مثل نص أو نتيجة أو صوت. |
ما المقصود بنقل التعلم؟
غالبا ما يتطلب تدريب نماذج التعلم العميق كميات كبيرة من بيانات التدريب وموارد الحوسبة المتطورة (GPU وTPU) ووقت تدريب أطول. عندما لا يكون لديك أي من هذه الأشياء المتاحة لك ، يمكنك اختصار عملية التدريب باستخدام تقنية تعرف باسم تحويل التعلم.
التعلم عن طريق النقل هو أسلوب يطبق المعرفة المكتسبة من حل مشكلة واحدة لمشكلة مختلفة ولكنها ذات صلة.
نظرا لبنية الشبكات العصبية، عادة ما تحتوي المجموعة الأولى من الطبقات على ميزات ذات مستوى أدنى، بينما تحتوي المجموعة النهائية من الطبقات على ميزات ذات مستوى أعلى أقرب إلى المجال المعني. من خلال إعادة استخدام الطبقات النهائية للاستخدام في مجال أو مشكلة جديدة، يمكنك تقليل مقدار الوقت والبيانات وموارد الحوسبة اللازمة لتدريب النموذج الجديد بشكل كبير. على سبيل المثال ، إذا كان لديك بالفعل نموذج يتعرف على السيارات ، فيمكنك إعادة توظيف هذا النموذج باستخدام تعلم النقل للتعرف أيضا على الشاحنات والدراجات النارية وأنواع أخرى من المركبات.
لمعرفة كيفية تطبيق التعلم الانتقالي لتصنيف الصور باستخدام إطار عمل مفتوح المصدر في التعلم الآلي من Microsoft Azure، راجع تدريب نموذج PyTorch للتعلم العميق باستخدام نقل التعلم.
حالات استخدام التعلم العميق
بسبب بنية الشبكة العصبية الاصطناعية ، يتفوق التعلم العميق في تحديد الأنماط في البيانات غير المهيكلة مثل الصور والصوت والفيديو والنص. لهذا السبب، يغير التعلم العميق بسرعة العديد من الصناعات، بما في ذلك الرعاية الصحية والطاقة والتمويل والنقل. تعيد هذه الصناعات الآن التفكير في العمليات التجارية التقليدية.
يتم وصف بعض التطبيقات الأكثر شيوعا للتعلم العميق في الفقرات التالية. في التعلم الآلي من Microsoft Azure، يمكنك استخدام نموذج قمت بإنشائه من إطار عمل مفتوح المصدر أو إنشاء النموذج باستخدام الأدوات المتوفرة.
التعرف على الكيان المسمى
التعرف على الكيان المسمى هو أسلوب تعلم عميق يأخذ جزءا من النص كإدخل ويحوله إلى فئة محددة مسبقا. يمكن أن تكون هذه المعلومات الجديدة رمزا بريديا أو تاريخا أو معرف منتج. يمكن بعد ذلك تخزين المعلومات في مخطط منظم لإنشاء قائمة من العناوين أو بمثابة معيار لمحرك التحقق من صحة الهوية.
اكتشَاف الكَائنَات
تم تطبيق التعلم العميق في العديد من حالات استخدام الكشف عن الكائنات. يتم استخدام اكتشاف الكائنات لتحديد الكائنات في صورة (مثل السيارات أو الأشخاص) وتوفير موقع محدد لكل كائن باستخدام مربع محيط.
يتم استخدام الكشف عن الكائنات بالفعل في صناعات مثل الألعاب والبيع بالتجزئة والسياحة والسيارات ذاتية القيادة.
إنشاء تسمية توضيحية للصورة
مثل التعرف على الصورة، في التسمية التوضيحية للصورة، بالنسبة لصورة معينة، يجب أن ينشئ النظام تسمية توضيحية تصف محتويات الصورة. عندما يمكنك الكشف عن الكائنات وتسميةها في الصور الفوتوغرافية، فإن الخطوة التالية هي تحويل هذه التسميات إلى جمل وصفية.
عادة ما تستخدم تطبيقات التسمية التوضيحية للصور الشبكات العصبية الالتفافية لتحديد العناصر في صورة ثم تستخدم شبكة عصبية متكررة لتحويل التسميات إلى جمل متسقة.
الترجمة الآلية
تأخذ الترجمة الآلية الكلمات أو الجمل من لغة واحدة وتترجمها تلقائيا إلى لغة أخرى. كانت الترجمة الآلية موجودة لفترة طويلة، ولكن التعلم العميق يحقق نتائج مثيرة للإعجاب في مجالين محددين: الترجمة التلقائية للنص (وترجمة الكلام إلى نص) والترجمة التلقائية للصور.
مع تحويل البيانات المناسب، يمكن للشبكة العصبية فهم الإشارات النصية والصوتية والبصرية. يمكن استخدام الترجمة الآلية لتحديد قصاصات الصوت في ملفات صوتية أكبر ونسخ الكلمة المنطوقة أو الصورة كنص.
تحليلات النص
تتضمن التحليلات النصية القائمة على طرق التعلم العميق تحليل كميات كبيرة من البيانات النصية (على سبيل المثال ، المستندات الطبية أو إيصالات النفقات) ، والتعرف على الأنماط ، وإنشاء معلومات منظمة وموجزة منها.
تستخدم المؤسسات التعلم العميق لإجراء تحليل النص للكشف عن التداول من الداخل والامتثال للوائح الحكومية. مثال شائع آخر هو الاحتيال في التأمين: غالبا ما تستخدم التحليلات النصية لتحليل أعداد كبيرة من المستندات للتعرف على فرص احتيال مطالبة التأمين.
الشبكات العصبية الاصطناعية
يتم تشكيل الشبكات العصبية الاصطناعية بواسطة طبقات من العقد المتصلة. تستخدم نماذج التعلم العميق الشبكات العصبية التي تحتوي على عدد كبير من الطبقات.
تصف الأقسام التالية بعض طبولوجيا الشبكة العصبية الاصطناعية الشائعة.
شبكة التغذية العصبية
الشبكة العصبية الموجزة هي أبسط أنواع الشبكة العصبية الاصطناعية. في شبكة التغذية، تنتقل المعلومات في اتجاه واحد فقط من طبقة الإدخال إلى طبقة الإخراج. تحول الشبكات العصبية Feedforward إدخالا من خلال وضعه من خلال سلسلة من الطبقات المخفية. تتكون كل طبقة من مجموعة من الخلايا العصبية ، وكل طبقة متصلة بالكامل بجميع الخلايا العصبية في الطبقة التي تسبقها. تمثل آخر طبقة متصلة بالكامل (طبقة الإخراج) التنبؤات التي تم إنشاؤها.
الشبكة العصبية المتكررة (RNN)
الشبكات العصبية المتكررة هي شبكة عصبية اصطناعية مستخدمة على نطاق واسع. تحفظ هذه الشبكات إخراج الطبقة وتعيدها إلى طبقة الإدخال للمساعدة في التنبؤ بنتائج الطبقة. تتمتع الشبكات العصبية المتكررة بقدرات تعليمية قوية. يتم استخدامها على نطاق واسع للمهام المعقدة مثل التنبؤ بالسلاسل الزمنية وتعلم الكتابة اليدوية والتعرف على اللغة.
الشبكة العصبية الالتفافية (CNN)
الشبكة العصبية الالتفافية هي شبكة عصبية اصطناعية فعالة بشكل خاص، وتقدم بنية فريدة من نوعها. يتم تنظيم الطبقات في ثلاثة أبعاد: العرض والارتفاع والعمق. الخلايا العصبية في طبقة واحدة لا تتصل بجميع الخلايا العصبية في الطبقة التالية، ولكن فقط بمنطقة صغيرة من الخلايا العصبية للطبقة. يتم تقليل الإخراج النهائي إلى متجه واحد من درجات الاحتمال، منظم على طول بعد العمق.
تستخدم الشبكات العصبية التلافيفية في مجالات مثل التعرف على الفيديو والتعرف على الصور وأنظمة التوصية.
شبكة خصومية إنشاءية (GAN)
الشبكات التوليدية المتطفلة هي نماذج إنشاءية مدربة على إنشاء محتوى واقعي مثل الصور. إنها تتكون من شبكتين تعرفان باسم المولدوالتمييز. يتم تدريب كلتا الشبكتين في وقت واحد. أثناء التدريب، يستخدم المولد ضوضاء عشوائية لإنشاء بيانات اصطناعية جديدة تشبه البيانات الحقيقية بشكل وثيق. يأخذ التمييز الناتج من المولد كمدخلات ويستخدم بيانات حقيقية لتحديد ما إذا كان المحتوى الذي تم إنشاؤه حقيقيا أم اصطناعيا. كل شبكة تتنافس مع الأخرى. يحاول المولد إنشاء محتوى اصطناعي لا يمكن تمييزه عن المحتوى الحقيقي ، ويحاول المميز تصنيف المدخلات بشكل صحيح على أنها حقيقية أو اصطناعية. ثم يتم استخدام الإخراج لتحديث أوزان كلتا الشبكتين لمساعدتهما على تحقيق أهدافهما بشكل أفضل.
تستخدم شبكات الخصومة التوليدية لحل مشكلات مثل ترجمة الصورة إلى صورة وتطور العمر.
المحولات
المحولات هي بنى نموذجية مناسبة لحل المشكلات التي تحتوي على تسلسلات ، مثل بيانات النص أو السلاسل الزمنية. وهي تتكون من طبقات أداة الترميز وأداة فك التشفير. تأخذ أداة الترميز إدخالا وتقوم بتعيينه إلى تمثيل رقمي يحتوي على معلومات مثل السياق. يستخدم أداة فك التشفير معلومات من أداة الترميز لإنتاج إخراج مثل النص المترجم. ما يجعل المحولات مختلفة عن البنى الأخرى التي تحتوي على أدوات الترميز وفك التشفير هي الطبقات الفرعية للانتباه. يشير الانتباه إلى التركيز على أجزاء معينة من المدخلات بناء على أهمية سياقها فيما يتعلق بالمدخلات الأخرى في التسلسل. على سبيل المثال ، عندما يلخص نموذج مقالة إخبارية ، لا تكون جميع الجمل ذات صلة بوصف الفكرة الرئيسية. من خلال التركيز على الكلمات الرئيسية في جميع أنحاء المقالة، يمكن إجراء التلخيص في جملة واحدة، العنوان الرئيسي.
تستخدم المحولات لحل مشكلات معالجة اللغة الطبيعية مثل الترجمة وإنشاء النص والإجابة على الأسئلة وتلخيص النص.
بعض التطبيقات المعروفة للمحولات هي:
- تمثيلات أداة الترميز ثنائية الاتجاه من المحولات (BERT)
- محول توليدي مدرب مسبقا 2 (GPT-2)
- محول توليدي مدرب مسبقا 3 (GPT-3)
الخطوات التالية
تصف المقالات التالية المزيد من الخيارات لاستخدام نماذج التعلم العميق مفتوحة المصدر في التعلم الآلي من Microsoft Azure: