إعداد AutoML لتدريب نموذج التنبؤ بالسلاسل الزمنية باستخدام Python (SDKv1)
ينطبق على: Python SDK azureml v1
Python SDK azureml v1
في هذه المقالة، ستتعلم كيفية إعداد تدريب AutoML لنماذج التنبؤ بالسلاسل الزمنية باستخدام التعلم الآلي من Microsoft Azure التلقائي في Python SDK للتعلم الآلي من Azure.
للقيام بذلك عليك ما يلي:
- إعداد البيانات لنمذجة السلاسل الزمنية.
- تكوين معلمات سلسلة زمنية محددة في عنصر
AutoMLConfig. - تشغيل التنبؤات باستخدام بيانات السلاسل الزمنية.
للحصول على تجربة تعليمات برمجية منخفضة، راجع البرنامج التعليمي: التنبؤ بالطلب باستخدام التعلم الآلي التلقائي للحصول على مثال للتنبؤ بالسلاسل الزمنية باستخدام التعلم الآلي التلقائي في استوديو التعلم الآلي من Microsoft Azure.
على عكس أساليب السلاسل الزمنية الكلاسيكية، في التعلم الآلي التلقائي، تتم "محورية" قيم السلاسل الزمنية السابقة لتصبح أبعاداً إضافية للمتراجع جنباً إلى جنب مع أدوات التنبؤ الأخرى. يتضمن هذا النهج متغيرات سياقية متعددة وعلاقتها ببعضها البعض أثناء التدريب. نظراً لأن عوامل متعددة يمكن أن تؤثر على التنبؤ، فإن هذه الطريقة تتماشى بشكل جيد مع سيناريوهات التنبؤ في العالم الحقيقي. على سبيل المثال، عند التنبؤ بالمبيعات، فإن تفاعلات الاتجاهات التاريخية، وسعر الصرف، والسعر كلها تدفع نتائج المبيعات بشكل مشترك.
المتطلبات الأساسية
بالنسبة لهذه المقالة، تحتاج إلى،
مساحة عمل للتعلم الآلي من Microsoft Azure. لإنشاء مساحة العمل، انظر إنشاء موارد مساحة العمل .
تفترض هذه المقالة بعض الإلمام بإعداد تجربة تعلم آلي تلقائي. اتبع طريقة الاطّلاع على أنماط تصميم تجربة التعلم الآلي التلقائي الرئيسية.
هام
تتطلب أوامر Python الموجودة في هذه المقالة أحدث إصدار من حزمة
azureml-train-automl.- ثبّت أحدث حزمة
azureml-train-automlلبيئتك المحلية. - للحصول على تفاصيل حول أحدث حزمة
azureml-train-automl، راجع ملاحظات الإصدار.
- ثبّت أحدث حزمة
بيانات التدريب والتحقق من الصحة
يتمثل الفرق الأكثر أهمية بين نوع مهمة تراجع التنبؤ ونوع مهمة التراجع داخل التعلم الآلي التلقائي في تضمين ميزة في بيانات التدريب التي تمثل سلسلة زمنية صالحة. تحتوي السلسلة الزمنية العادية على تكرار محدد ومتسق جيداً، ولها قيمة في كل نقطة عينة في فترة زمنية مستمرة.
هام
عند تدريب نموذج للتنبؤ بالقيم المستقبلية، تأكد من إمكانية استخدام جميع الميزات المستخدمة في التدريب عند تشغيل التنبؤات للأفق المقصود. على سبيل المثال، عند إنشاء تنبؤ بالطلب، بما في ذلك ميزة لسعر الأسهم الحالي يمكن أن يزيد دقة التدريب بشكل كبير. ومع ذلك، إذا كنت تنوي التنبؤ بأفق طويل، فقد لا تتمكن من التنبؤ بدقة بقيم الأسهم المستقبلية المقابلة لنقاط السلسلة الزمنية المستقبلية، وقد تعاني دقة النموذج.
يمكنك تحديد بيانات تدريب منفصلة وبيانات التحقق من الصحة مباشرة في AutoMLConfig العنصر. تعرّف على المزيد حول AutoMLConfig.
للتنبؤ بالسلاسل الزمنية، يتم استخدام التحقق المقطعي من الأصل المتداول (ROCV) فقط للتحقق من الصحة بشكل افتراضي. يقسم التحقق المتقاطع من الأصل المتداول السلسلة إلى بيانات التدريب والتحقق باستخدام نقطة زمنية أصل. يؤدي تمرير الأصل في الوقت المناسب إلى إنشاء طيات التحقق المقطعي. تحافظ هذه الاستراتيجية على تكامل بيانات السلسلة الزمنية وتزيل مخاطر تسرب البيانات.
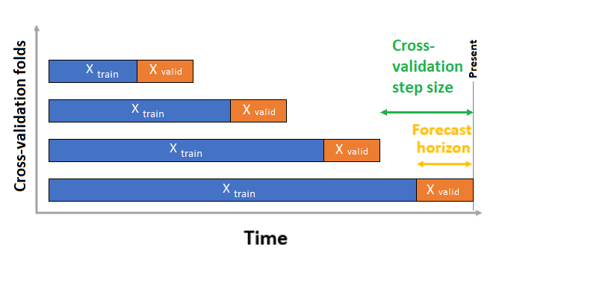
مرر بيانات التدريب والتحقق من الصحة كمجموعة بيانات واحدة إلى المعلمة training_data. تعيين عدد طيات التحقق من الصحة المتقاطعة مع المعلمة n_cross_validations وتعيين عدد الفترات بين طيتين متتاليتين للتحقق من الصحة المتقاطعة باستخدام cv_step_size. يمكنك أيضا ترك أي من المعلمتين أو كليهما فارغين وتعيين AutoML لهم تلقائيا.
ينطبق على: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
يمكنك أيضاً إحضار بيانات التحقق من الصحة لديك، ومعرفة المزيد في تكوين تقسيمات البيانات والتحقق المقطعي في AutoML.
تعرف على المزيد حول كيفية تطبيق AutoML للتحقق المقطعي لمنع النماذج الزائدة عن الحد.
تكوين التجربة
يحدد العنصر AutoMLConfig الإعدادات والبيانات اللازمة لمهمة التعلم الآلي التلقائي. يشبه تكوين نموذج التنبؤ إعداد نموذج تراجع قياسي، ولكن توجد نماذج معينة وخيارات تكوين وخطوات تمييز خاصة ببيانات السلسلة الزمنية.
النماذج المدعومة
يقوم التعلم الآلي المؤتمت تلقائيًا بتجربة نماذج وخوارزميات مختلفة كجزء من عملية إنشاء النموذج وضبطه. كمستخدم، ليست هناك حاجة لك لتحديد الخوارزمية. للتنبؤ بالتجارب، تعد كل من السلاسل الزمنية الأصلية ونماذج التعلم العميق جزءاً من نظام التوصيات.
تلميح
كما يتم اختبار نماذج التراجع التقليدية كجزء من نظام التوصية للتنبؤ بالتجارب. راجع قائمة كاملة بالنماذج المدعومة في الوثائق المرجعية لـ SDK.
إعدادات التكوين
على غرار مشكلة التراجع، يمكنك تحديد معلمات التدريب القياسية، مثل نوع المهمة وعدد التكرارات وبيانات التدريب وعدد عمليات التحقق المقطعي. تتطلب مهام التنبؤ المعلمتين time_column_name وforecast_horizon لتكوين تجربتك. إذا كانت البيانات تتضمن سلاسل زمنية متعددة، مثل بيانات المبيعات لمخازن متعددة أو بيانات طاقة عبر حالات مختلفة، فإن التعلم الآلي المؤتمت يكتشف هذا تلقائياً ويعين المعلمة time_series_id_column_names (إصدار أولي) نيابة عنك. يمكنك أيضاً تضمين معلمات إضافية لتكوين التشغيل بشكل أفضل، راجع قسم التكوينات الاختيارية لمزيد من التفاصيل حول ما يمكن تضمينه.
هام
التعريف التلقائي للسلسلة الزمنية قيد الإصدار الأولي العام حالياً. يتم توفير إصدار المعاينة هذا من دون اتفاقية مستوى الخدمة. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة. لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
| اسم المعلمة | الوصف |
|---|---|
time_column_name |
يستخدم لتحديد عمود التاريخ والوقت في بيانات الإدخال المستخدمة لإنشاء السلسلة الزمنية والاستدلال على ترددها. |
forecast_horizon |
يحدد عدد الفترات التي تريد التنبؤ بها. الأفق موجود في وحدات تردد السلسلة الزمنية. تعتمد الوحدات على الفاصل الزمني لبيانات التدريب، على سبيل المثال، شهريًا وأسبوعيًا يجب على المتنبئ توقعه. |
التعليمة البرمجية التالية،
ForecastingParametersيستخدم الفئة لتحديد معلمات التنبؤ لتدريب تجربتك- تقوم بتعيين
time_column_nameإلى الحقلday_datetimeفي مجموعة البيانات. - تقوم بتعيين
forecast_horizonإلى 50 من أجل التنبؤ بمجموعة الاختبار بأكملها.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
يتم تمرير forecasting_parameters بعد ذلك إلى العنصر القياسي AutoMLConfig جنباً إلى جنب مع نوع المهمة forecasting والمقياس الأساسي ومعايير الخروج وبيانات التدريب.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
تتأثر كمية البيانات المطلوبة لتدريب نموذج التنبؤ بنجاح باستخدام التعلم الآلي المؤتمت بالقيم forecast_horizon وn_cross_validations وtarget_lags أو target_rolling_window_size المحددة عند تكوين AutoMLConfig.
تحسب الصيغة التالية كمية البيانات التاريخية التي ستكون مطلوبة لإنشاء ميزات السلسلة الزمنية.
الحد الأدنى من البيانات التاريخية المطلوبة: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Error exception يتم رفع لأي سلسلة في مجموعة البيانات التي لا تفي بالكمية المطلوبة من البيانات التاريخية للإعدادات ذات الصلة المحددة.
خطوات التمييز
في كل تجربة للتعلم الآلي المؤتمت، يتم تطبيق تقنيات التحجيم التلقائي والتسوية على بياناتك بشكل افتراضي. تعد هذه التقنيات بمثابة أنواع من الخصائص المميزة التي تساعد بعض الخوارزميات الحساسة للميزات على مستويات مختلفة. تعرف على المزيد حول خطوات التمييز الافتراضية في التمييز في AutoML
ومع ذلك، يتم تنفيذ الخطوات التالية فقط بالنسبة إلى أنواع المهام forecasting:
- الكشف عن تكرار نموذج السلسلة الزمنية (على سبيل المثال، كل ساعة، كل يوم، كل أسبوع) وإنشاء سجلات جديدة للنقاط الزمنية الغائبة لجعل السلسلة مستمرة.
- حساب القيم المفقودة في الهدف (عبر التعبئة للأمام) وأعمدة الميزات (باستخدام قيم الأعمدة الوسيطة)
- إنشاء ميزات تستند إلى معرفات السلاسل الزمنية لتمكين التأثيرات الثابتة عبر سلاسل مختلفة
- إنشاء ميزات مستندة إلى الوقت للمساعدة في تعلم الأنماط الموسمية
- ترميز المتغيرات الفئوية إلى كميات رقمية
- اكتشف السلسلة الزمنية غير الثابتة واختلفها تلقائيا للتخفيف من تأثير جذور الوحدة.
لعرض القائمة الكاملة للميزات الهندسية المحتملة التي تم إنشاؤها من بيانات السلاسل الزمنية، راجع فئة TimeIndexFeaturizer.
إشعار
تصبح خطوات التخصيص الآلي للتعلم الآلي (تطبيع الميزات، ومعالجة البيانات المفقودة، وتحويل النص إلى رقمي، وما إلى ذلك) جزءًا من النموذج الأساسي. عند استخدام النموذج للتنبؤات، يتم تطبيق نفس خطوات التخصيص المطبقة أثناء التدريب على بيانات الإدخال تلقائياً.
تخصيص التمييز
يتوفر لديك أيضاً خيار تخصيص إعدادات التمييز للتأكد من أن البيانات والميزات المستخدمة لتدريب نموذج التعلم الآلي الخاص بك تؤدي إلى تنبؤات ذات صلة.
تتضمن التخصيصات المدعومة للمهام forecasting ما يلي:
| تخصيص | تعريف |
|---|---|
| تحديث الغرض من العمود | تجاوز نوع الميزة التي تم لها الكشف التلقائي للعمود المحدد. |
| تحديث معلمة المحول | تحديث معلّمات المحول المحدد. يدعم حالياً Imputer (fill_value والوسيط). |
| إسقاط الأعمدة | تحديد الأعمدة التي ينبغي إسقاطها من أن يتم تمييزها. |
لتخصيص العلامات المميزة باستخدام SDK، حدد "featurization": FeaturizationConfig في العنصر AutoMLConfig لديك. تعرف على المزيد حول التمييز المخصص.
إشعار
يتم إهمال وظيفة إسقاط الأعمدة اعتبارًا من الإصدار 1.19 من SDK. أسقِط الأعمدة من مجموعة البيانات الخاصة بك كجزء من تنظيف البيانات، قبل استهلاكها في تجربة التعلم الآلي من Microsoft Azure التلقائي.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
إذا كنت تستخدم استوديو التعلم الآلي من Azure لتجربتك، فشاهد كيفية تخصيص التمييز في الاستوديو.
التكوينات الاختيارية
تتوفر المزيد من التكوينات الاختيارية لمهام التنبؤ، مثل تمكين التعلم العميق وتحديد تجميع النوافذ المتداولة المستهدفة. تتوفر قائمة كاملة بمزيد من المعلمات في الوثائق المرجعية ForecastingParameters SDK.
تكرار تجميع البيانات المستهدفة
استخدم المعلمة frequency، freq، للمساعدة في تجنب حالات الفشل الناتجة عن البيانات غير المنتظمة. تتضمن البيانات غير المنتظمة البيانات التي لا تتبع إيقاعا معينا، مثل البيانات كل ساعة أو يوميا.
بالنسبة للبيانات غير المنتظمة للغاية أو لاحتياجات الأعمال المختلفة، يمكن للمستخدمين اختيارياً تعيين تردد التنبؤ المطلوب، freq، وتحديد target_aggregation_function لتجميع العمود الهدف من السلسلة الزمنية. يمكن أن يساعد استخدام هذين الإعدادين في العنصر الخاص بك AutoMLConfig في توفير بعض الوقت في إعداد البيانات.
تتضمن عمليات التجميع المدعومة لقيم العمود الهدف ما يلي:
| الوظيفة | الوصف |
|---|---|
sum |
مجموع القيم الهدف |
mean |
متوسط أو معدل القيم المستهدفة |
min |
الحد الأدنى لقيمة الهدف |
max |
الحد الأقصى لقيمة الهدف |
تمكين التعلم العميق
إشعار
يكون دعم DNN للتنبؤ في التعلم الآلي المؤتمت قيد الإصدار الأولي وغير مدعوم للتشغيلات المحلية أو عمليات التشغيل التي بدأت في Databricks.
يمكنك أيضاً تطبيق التعلم العميق مع الشبكات العصبية العميقة، DNNs، لتحسين درجات النموذج. يسمح التعلم العميق للتعلم الآلي بالتنبؤ ببيانات السلاسل الزمنية أحادية المتغيرات ومتعددة المتغيرات.
تتمتع نماذج التعلم العميق بثلاث قدرات جوهرية:
- يمكنها التعلم من التعيينات العشوائية من المدخلات إلى المخرجات
- وهي تدعم مدخلات ومخرجات متعددة
- يمكنهم استخراج الأنماط تلقائياً في بيانات الإدخال التي تمتد عبر تسلسلات طويلة.
لتمكين التعلم العميق، قم بتعيين enable_dnn=True في العنصر AutoMLConfig.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
تحذير
عند تمكين DNN للتجارب التي تم إنشاؤها باستخدام SDK، يتم تعطيل أفضل تفسيرات النموذج.
لتمكين DNN لتجربة AutoML التي تم إنشاؤها في استوديو التعلم الآلي من Microsoft Azure، راجع إعدادات نوع المهمة في طريقة استخدام واجهة مستخدم الاستوديو.
تجميع النوافذ المتداولة المستهدفة
غالبا ما تكون أفضل المعلومات الخاصة بالمتنبأ هي القيمة الأخيرة للهدف. تسمح لك تجميعات النوافذ المتداولة الهدف بإضافة تجميع متجدد لقيم البيانات كميزات. يساعد إنشاء هذه الميزات واستخدامها كبيانات سياقية إضافية في دقة نموذج التدريب.
على سبيل المثال، لنفترض أنك تريد التنبؤ بطلب الطاقة. قد تحتاج إلى إضافة ميزة نافذة متجددة لمدة ثلاثة أيام لحساب التغيرات الحرارية للمساحات الساخنة. في هذا المثال، قم بإنشاء هذه النافذة عن طريق الإعداد target_rolling_window_size= 3 في الدالة الإنشائية AutoMLConfig.
يعرض الجدول هندسة الميزات الناتجة التي تحدث عند تطبيق تجميع النافذة. يتم إنشاء أعمدة الحد الأدنى والحد الأقصى والمجموع على نافذة منزلقة مكونة من ثلاثة أعمدة استناداً إلى الإعدادات المحددة. يحتوي كل صف على ميزة محسوبة جديدة، في حالة الطابع الزمني لـ 8 سبتمبر 2017 الساعة 4:00 صباحاً، يتم حساب قيم الحد الأقصى والحد الأدنى والمجموع باستخدام قيم الطلب لـ 8 سبتمبر 2017 من 1:00 صباحاً إلى 3:00 صباحاً. هذه النافذة المكونة من ثلاث نوبات مخصصة لملء البيانات للصفوف المتبقية.

اعرض مثالاً على التعليمات البرمجية لـ Python التي تطبق ميزة تجميع النافذة المتداولة الهدف.
معالجة السلاسل القصيرة
يعتبر التعلم الآلي التلقائي سلسلة زمنية سلسلة قصيرة إذا لم تكن هناك نقاط بيانات كافية لإجراء مراحل التدريب والتحقق من صحة تطوير النموذج. يختلف عدد نقاط البيانات لكل تجربة، ويعتمد على max_horizon وعدد تقسيمات التحقق المقطعي وطول البحث عن النموذج، وهو الحد الأقصى للمحفوظات المطلوبة لإنشاء ميزات السلسلة الزمنية.
يوفر التعلم الآلي المؤتمت معالجة سلسلة قصيرة بشكل افتراضي باستخدام المعلمة short_series_handling_configuration في العنصر ForecastingParameters.
لتمكين معالجة السلسلة القصيرة، يجب أيضاً تعريف المعلمة freq. لتحديد تكرار كل ساعة، سنقوم بتعيين freq='H'. اعرض خيارات سلسلة التردد عن طريق زيارة قسم عناصر DataOffset لصفحة سلاسل pandas الزمنية. لتغيير السلوك الافتراضي، short_series_handling_configuration = 'auto'، قم بتحديث المعلمة short_series_handling_configuration في العنصر ForecastingParameter.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
يلخص الجدول التالي الإعدادات المتوفرة لـ short_series_handling_config.
| الإعدادات | الوصف |
|---|---|
auto |
القيمة الافتراضية لمعالجة السلاسل القصيرة. - إذا كانت جميع السلاسل قصيرة، فبادر بلوحة البيانات. - إذا لم تكن جميع السلاسل قصيرة، فقم بإفلات السلسلة القصيرة. |
pad |
في حالة short_series_handling_config = pad، فإن التعلم الآلي المؤتمت يضيف قيماً عشوائية إلى كل سلسلة قصيرة تم العثور عليها. يسرد ما يلي أنواع الأعمدة وما تتم إضافتها به: - أعمدة الكائنات مع NaNs - أعمدة رقمية مع 0 - أعمدة منطقية/منطقية مع False - تتم إضافة العمود الهدف بقيم عشوائية مع وسط صفر وانحراف معياري من 1. |
drop |
إذا short_series_handling_config = drop، فإن التعلم الآلي المؤتمت يسقط السلسلة القصيرة، ولن يتم استخدامه للتدريب أو التنبؤ. تنبؤات هذه السلسلة ترجع NaN. |
None |
لم تتم إضافة أي سلسلة أو إسقاطها |
تحذير
قد يؤثر ترك المساحة على دقة النموذج الناتج، لأننا نقدم بيانات اصطناعية فقط للحصول على التدريب السابق دون فشل. إذا كانت العديد من السلاسل قصيرة، فقد ترى أيضًا بعض التأثير في نتائج التفسير
الكشف عن السلاسل الزمنية غير الثابتة ومعالجتها
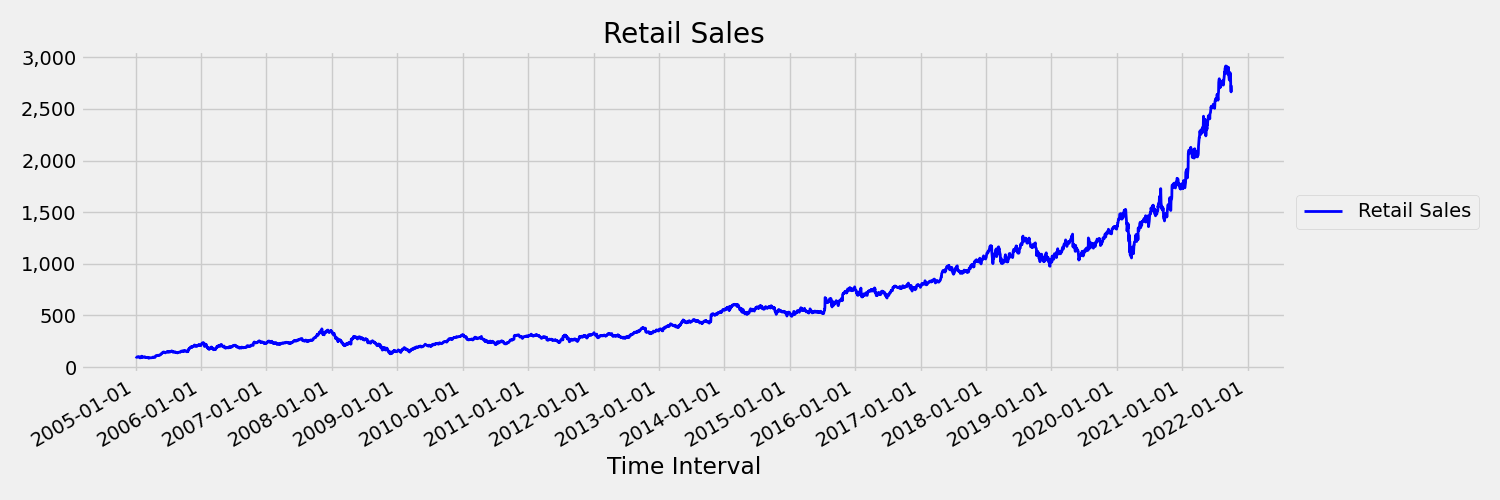
تسمى السلسلة الزمنية التي تتغير لحظاتها (الوسط والتباين) بمرور الوقت ب غير ثابتة. على سبيل المثال، السلاسل الزمنية التي تعرض الاتجاهات العشوائية ليست ثابتة بطبيعتها. لتصور هذا، ترسم الصورة أدناه سلسلة تتجه بشكل عام لأعلى. الآن، حساب ومقارنة قيم الوسط (المتوسط) للنصف الأول والثاني من السلسلة. هل هما متشابهان؟ هنا، يكون متوسط السلسلة في النصف الأول من المخطط أصغر مما كان عليه في النصف الثاني. حقيقة أن متوسط السلسلة يعتمد على الفاصل الزمني الذي يبحث فيه المرء، هو مثال على اللحظات المتغيرة زمنيا. هنا، وسط السلسلة هو اللحظة الأولى.
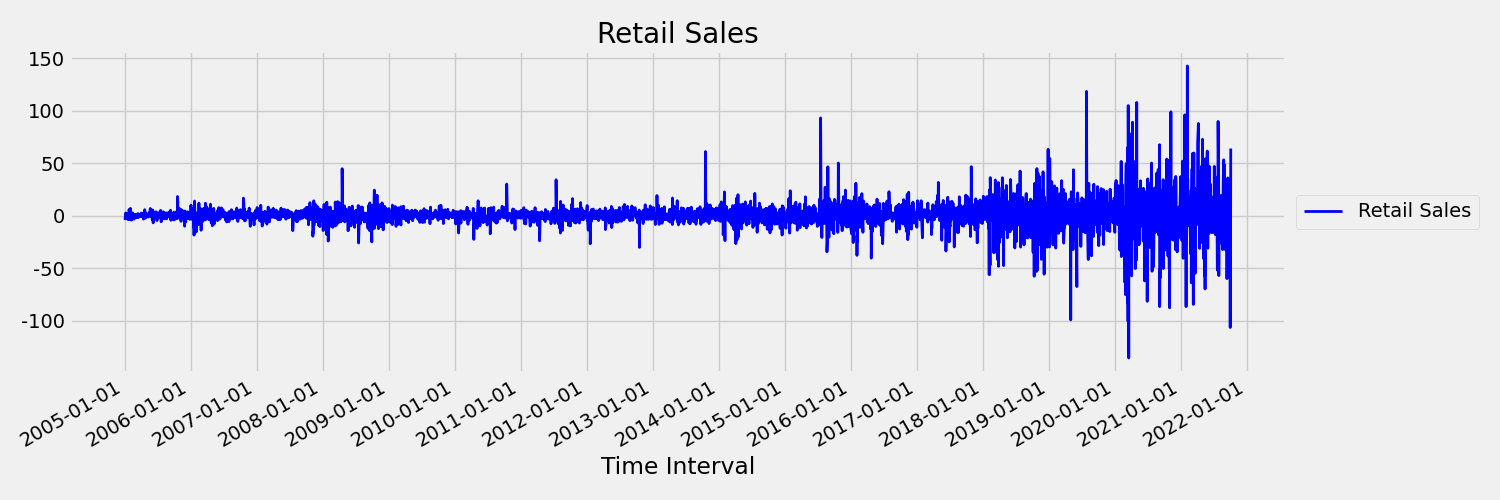
بعد ذلك، دعنا نفحص الصورة، التي ترسم السلسلة الأصلية في الاختلافات الأولى، $x_t = y_t - y_{t-1}$ حيث $x_t$ هو التغيير في مبيعات البيع بالتجزئة ويمثل $y_t$ و $y_{t-1}$ السلسلة الأصلية وتأخرها الأول، على التوالي. متوسط السلسلة ثابت تقريبا بغض النظر عن الإطار الزمني الذي ينظر إليه المرء. هذا مثال على سلسلة الأوقات الثابتة للطلب الأول. السبب في أننا أضفنا مصطلح الطلب الأول هو أن اللحظة الأولى (الوسط) لا تتغير مع الفاصل الزمني، ولا يمكن أن يقال الشيء نفسه عن التباين، وهي لحظة ثانية.
لا يمكن لنماذج التعلم الآلي من AutoML التعامل بطبيعتها مع الاتجاهات العشوائية، أو غيرها من المشاكل المعروفة المرتبطة بالسلسلة الزمنية غير الثابتة. ونتيجة لذلك، فإن دقتها من عينة التنبؤ "ضعيفة" إذا كانت هذه الاتجاهات موجودة.
يحلل AutoML تلقائيا مجموعة بيانات السلسلة الزمنية للتحقق مما إذا كانت ثابتة أم لا. عند اكتشاف سلسلة زمنية غير ثابتة، يطبق AutoML تحويلا مختلفا تلقائيا للتخفيف من تأثير السلسلة الزمنية غير الثابتة.
تشغيل التجربة
عندما يكون العنصر AutoMLConfig جاهزاً، يمكنك إرسال التجربة. بعد انتهاء النموذج، قم باسترداد أفضل تكرار تشغيل.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
التنبؤ بأفضل نموذج
استخدم أفضل تكرار للنموذج للتنبؤ بقيم البيانات التي لم يتم استخدامها لتدريب النموذج.
تقييم دقة النموذج مع تنبؤ متجدد
قبل وضع نموذج في الإنتاج، يجب تقييم دقته على مجموعة اختبار تم عقدها من بيانات التدريب. إجراء أفضل الممارسات هو ما يسمى بالتقييم المتداول، والذي يقلب التنبؤ المدرب إلى الأمام في الوقت المناسب خلال مجموعة الاختبار، متوسط مقاييس الخطأ عبر عدة نوافذ تنبؤ للحصول على تقديرات قوية إحصائيا لبعض مجموعة المقاييس المختارة. من الناحية المثالية، فإن مجموعة الاختبار للتقييم طويلة بالنسبة لأفق التنبؤ بالنموذج. وبخلاف ذلك، قد تكون تقديرات خطأ التنبؤ مزعجة إحصائيا، وبالتالي أقل موثوقية.
على سبيل المثال، افترض أنك تقوم بتدريب نموذج على المبيعات اليومية للتنبؤ بالطلب حتى أسبوعين (14 يوما) في المستقبل. إذا كانت هناك بيانات تاريخية كافية متاحة، فقد تحتفظ بالأشهر القليلة الأخيرة حتى لمدة سنة من البيانات لمجموعة الاختبار. يبدأ التقييم المتداول بإنشاء تنبؤ قبل 14 يوما للأسبوعين الأولين من مجموعة الاختبار. بعد ذلك، يتم تطوير المتنبأ بعدد من الأيام في مجموعة الاختبار وتنشئ تنبؤا آخر قبل 14 يوما من الموضع الجديد. تستمر العملية حتى تصل إلى نهاية مجموعة الاختبار.
لإجراء تقييم متجدد، يمكنك استدعاء rolling_forecast أسلوب fitted_model، ثم حساب المقاييس المطلوبة على النتيجة. على سبيل المثال، افترض أن لديك ميزات مجموعة اختبار في pandas DataFrame تسمى test_features_df والقيم الفعلية لمجموعة الاختبار للهدف في صفيف numpy يسمى test_target. يتم عرض تقييم متجدد باستخدام متوسط الخطأ التربيعي في نموذج التعليمات البرمجية التالي:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
في هذا النموذج، يتم تعيين حجم خطوة التنبؤ المتداول إلى واحد، ما يعني أن التنبؤ متقدم لفترة واحدة، أو يوم واحد في مثال توقع الطلب لدينا، في كل تكرار. وهكذا يعتمد العدد الإجمالي للتنبؤات التي يتم إرجاعها rolling_forecast على طول مجموعة الاختبار وحجم هذه الخطوة. لمزيد من التفاصيل والأمثلة، راجع وثائق rolling_forecast() والتنبؤ بعيدا عن دفتر ملاحظات بيانات التدريب.
التنبؤ في المستقبل
تسمح الدالة forecast_quantiles() بمواصفات متى يجب أن تبدأ التنبؤات، على عكس الأسلوب predict() الذي يستخدم عادة لمهام التصنيف والتراجع. ينشئ أسلوب forecast_quantiles() افتراضيا تنبؤ نقطة أو تنبؤ متوسط/متوسط، والذي لا يحتوي على مخروط من عدم اليقين حوله. تعرف على المزيد في التنبؤ بعيداً عن دفتر ملاحظات بيانات التدريب.
في المثال التالي، يمكنك أولاً استبدال كافة القيم في y_pred مع NaN. أصل التنبؤ في نهاية بيانات التدريب في هذه الحالة. ومع ذلك، إذا قمت باستبدال النصف الثاني فقط من y_pred مع NaN، فإن الدالة ستترك القيم الرقمية في النصف الأول غير معدلة، ولكن تتنبأ بالقيم NaN في النصف الثاني. ترجع الدالة كلاً من القيم المتوقعة والميزات المتوافقة.
يمكنك أيضاً استخدام المعلمة forecast_destination في الدالة forecast_quantiles() للتنبؤ بالقيم حتى تاريخ محدد.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
غالباً ما يرغب العملاء في فهم التنبؤات في كم معين للتوزيع. على سبيل المثال، عند استخدام التنبؤ للتحكم في المخزون، مثل عناصر البقالة أو الأجهزة الظاهرية لخدمة سحابية. في مثل هذه الحالات، عادة ما تكون نقطة التحكم شيئاً، مثل "نريد أن يكون العنصر في المخزون ولا ينفد 99% من الوقت". يوضح ما يلي كيفية تحديد القيم الكمية التي ترغب في رؤيتها لتوقعاتك، مثل القيمة المئوية 50 أو 95. إذا لم تحدد قيمة كمية، كما هو الحال في مثال التعليمات البرمجية المذكورة أعلاه، فسيتم إنشاء تنبؤات النسبة المئوية الخمسين فقط.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
يمكنك حساب مقاييس النموذج مثل، متوسط خطأ التربيع الجذر (RMSE) أو متوسط خطأ النسبة المئوية المطلقة (MAPE) لمساعدتك في تقدير أداء النماذج. راجع قسم تقييم في دفتر ملاحظات طلب مشاركة الدراجة للحصول على مثال.
بعد تحديد دقة النموذج الإجمالية، فإن الخطوة التالية الأكثر واقعية تتمثل في استخدام النموذج للتنبؤ بقيم مستقبلية غير معروفة.
قم بتوفير مجموعة بيانات بنفس تنسيق مجموعة الاختبار test_dataset، ولكن مع أوقات التاريخ المستقبلية، ومجموعة التنبؤ الناتجة تكون هي القيم المتوقعة لكل خطوة من خطوات السلسلة الزمنية. افترض أن آخر سجلات السلسلة الزمنية في مجموعة البيانات كانت لـ 12/31/2018. للتنبؤ بالطلب لليوم التالي (أو عدد الفترات التي تحتاج إلى التنبؤ بها، <= forecast_horizon)، قم بإنشاء سجل سلسلة زمنية واحدة لكل متجر لـ 01/01/2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
كرر الخطوات الضرورية لتحميل هذه البيانات المستقبلية إلى إطار بيانات، ثم قم بتشغيل best_run.forecast_quantiles(test_dataset) للتنبؤ بالقيم المستقبلية.
إشعار
التنبؤات في العينة غير مدعومة للتنبؤ باستخدام التعلم الآلي المؤتمت عند تمكين target_lags و/أو target_rolling_window_size.
التنبؤ على نطاق واسع
هناك سيناريوهات يكون فيها نموذج التعلم الآلي الوحيد غير كافٍ، وهناك حاجة إلى نماذج متعددة للتعلم الآلي. على سبيل المثال، التنبؤ بالمبيعات لكل متجر فردي لعلامة تجارية، أو تخصيص تجربة للمستخدمين الفرديين. يمكن أن يؤدي بناء نموذج لكل مثيل إلى نتائج محسنة على العديد من مشكلات التعلم الآلي.
يشكل التجميع مفهومًا في التنبؤ بالسلاسل الزمنية يسمح بدمج السلاسل الزمنية لتدريب نموذج فردي لكل مجموعة. يمكن أن يكون هذا النهج مفيداً بشكل خاص إذا كانت لديك سلسلة زمنية تتطلب سلاسة أو تعبئة أو كيانات في المجموعة يمكنها الاستفادة من التاريخ أو الاتجاهات من كيانات أخرى. العديد من النماذج والتنبؤ بالسلاسل الزمنية الهرمية تمثل حلولاً مدعومة بالتعلم الآلي التلقائي لسيناريوهات التنبؤ واسعة النطاق هذه.
العديد من النماذج
يتيح حل العديد من النماذج للتعلم الآلي من Azure مع التعلم الآلي المؤتمت للمستخدمين إمكانية تدريب وإدارة ملايين النماذج بشكل متوازٍ. العديد من النماذج يستخدم مسرع الحلول مسارات Azure التعلم الآلي لتدريب النموذج. على وجه التحديد، يتم استخدام عنصر Pipeline، ووParalleRunStep، ويتطلبان معلمات تكوين محددة تم تعيينها من خلال ParallelRunConfig.
يوضح الرسم التخطيطي التالي سير العمل لحل العديد من النماذج.

توضح التعليمات البرمجية التالية المعلمات الرئيسية التي يحتاجها المستخدمون لإعداد تشغيل العديد من النماذج الخاصة بهم. راجع دفتر ملاحظات التعلم الآلي - العديد من النماذج للحصول على مثال تنبؤ للعديد من النماذج
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
التنبؤ بالسلاسل الزمنية الهرمية
في معظم التطبيقات، يحتاج العملاء إلى فهم توقعاتهم على مستوى ماكرو وصغرى للأعمال. يمكن أن تتنبأ Forcasts بمبيعات المنتجات في مواقع جغرافية مختلفة، أو تفهم الطلب المتوقع على القوى العاملة للمؤسسات المختلفة في الشركة. القدرة على تدريب نموذج التعلم الآلي للتنبؤ بذكاء على بيانات التسلسل الهرمي يشكل أمرًا ضرورياً.
السلسلة الزمنية الهرمية هي بنية يتم فيها ترتيب كل سلسلة فريدة في تسلسل هرمي استنادا إلى أبعاد مثل الجغرافيا أو نوع المنتج. يوضح المثال التالي البيانات ذات السمات الفريدة التي تشكل تدرجًا هرمياً. يتم تحديد التسلسل الهرمي لدينا من خلال: نوع المنتج مثل سماعات الرأس أو الأجهزة اللوحية، وفئة المنتج، التي تقسم أنواع المنتجات إلى ملحقات وأجهزة، والمنطقة التي تباع فيها المنتجات.

لمزيد من تصور هذا، تحتوي المستويات الطرفية للتدرج الهرمي على جميع السلاسل الزمنية مع مجموعات فريدة من قيم السمات. يعتبر كل مستوى أعلى في التدرج الهرمي بعداً واحداً أقل لتعريف السلسلة الزمنية، ويجمع كل مجموعة من العقد التابعة من المستوى الأدنى إلى عقدة أصل.

تم إنشاء حل التدرج الزمني الهرمي أعلى حل العديد من النماذج ومشاركة إعداد تكوين مشابه.
توضح التعليمات البرمجية التالية المعلمات الرئيسية لإعداد عمليات تشغيل التنبؤ بالتسلسل الزمني الهرمي. راجع سلسلة زمنية هرمية - دفتر ملاحظات التعلم الآلي المؤتمت، للحصول على مثال شامل.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
مثال دفاتر الملاحظات
راجع نماذج دفاتر الملاحظات للتنبؤ للحصول على أمثلة تعليمات برمجية مفصلة لتكوين التنبؤ المتقدم بما في ذلك:
- الكشف عن العطلات والتميز
- التحقق المقطعي للأصل المتداول
- التأخر القابل للتكوين
- ميزات تجميع النافذة المتداولة
الخطوات التالية
- تعرف على المزيد حول كيفية توزيع نموذج التعلم الآلي إلى نقطة نهاية عبر الإنترنت.
- تعرف على قابلية التفسير: تفسيرات النموذج في التعلم الآلي المؤتمت (إصدار أولي).
- تعرف على كيفية إنشاء AutoML لنماذج التنبؤ.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ