إعداد AutoML لتدريب نماذج الرؤية الحاسوبية باستخدام Python (v1)
ينطبق على: Python SDK azureml v1
Python SDK azureml v1
هام
تتطلب أوامر Azure CLI الواردة في هذه المقالة ملحق azure-cli-ml، أو الإصدار 1، التعلم الآلي من Microsoft Azure. سينتهي دعم ملحق الإصدار 1 في 30 سبتمبر 2025. ستتمكن من تثبيت ملحق v1 واستخدامه حتى ذلك التاريخ.
نوصي بالانتقال إلى ملحق ml أو الإصدار 2 قبل 30 سبتمبر 2025. لمزيد من المعلومات حول ملحق v2، راجع ملحق Azure ML CLI وPython SDK v2.
هام
تُعد هذه الميزة قيد الإصدار الأولي العام في الوقت الحالي. يتم توفير إصدار المعاينة هذا من دون اتفاقية مستوى الخدمة. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة. لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
في هذه المقالة، ستتعلم كيفية تدريب نماذج رؤية الكمبيوتر على بيانات الصور باستخدام التعلم الآلي المؤتمت في Python SDK للتعلم التعلم الآلي من Azure.
يدعم التعلم الآلي التلقائي تدريب النموذج لمهام رؤية الكمبيوتر، مثل تصنيف الصور وكشف العناصر وتجزئة المثيل. يتم حاليا دعم تأليف نماذج AutoML لمهام رؤية الكمبيوتر عبر Python SDK للتعلم الآلي من Azure. يمكن الوصول إلى عمليات تشغيل الاختبارات والنماذج والمخرجات الناتجة من واجهة مستخدم استوديو التعلم الآلي من Azure. تعرّف على المزيد حول التعلم الآلي التلقائي لمهام رؤية الكمبيوتر على بيانات الصورة.
إشعار
يتوفر التعلم الآلي التلقائي لمهام رؤية الكمبيوتر فقط عبر Python SDK للتعلم الآلي من Azure.
المتطلبات الأساسية
مساحة عمل للتعلم الآلي من Microsoft Azure. لإنشاء مساحة العمل، انظر إنشاء موارد مساحة العمل .
تم تثبيت Python SDK للتعلم الآلي من Azure. لتثبيت SDK، يمكنك إما
إنشاء مثيل حساب، والذي يثبت SDK تلقائياً ويكوّنه مسبقاً لعمليات سير عمل التعلم الآلي. اطّلع على إنشاء مثيل حساب للتعلم الآلي من Azure وإدارته للحصول على مزيد من المعلومات.
ثبّت
automlالحزمة بنفسك، التي تتضمن التثبيت التلقائي لـ SDK.
إشعار
تتوافق Python 3.7 و3.8 فقط مع دعم التعلم الآلي التلقائي لمهام رؤية الكمبيوتر.
تحديد نوع المهمة
يدعم التعلم الآلي التلقائي للصور أنواع المهام التالية:
| نوع المهمة | بناء جملة تكوين AutoMLImage |
|---|---|
| تصنيف الصور | ImageTask.IMAGE_CLASSIFICATION |
| تصنيف الصور متعدد التسميات | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| كشف عنصر الصورة | ImageTask.IMAGE_OBJECT_DETECTION |
| تجزئة مثيل الصورة | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
نوع المهمة هذا يشير إلى معلمة مطلوبة، ويتم تمريرها باستخدام المعلمة task في AutoMLImageConfig.
على سبيل المثال:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
بيانات التدريب والتحقق من الصحة
من أجل إنشاء نماذج رؤية الكمبيوتر، تحتاج إلى إحضار بيانات الصورة المسماة كإدخال لتدريب النموذج في شكل TabularDataset للتعلم الآلي من Azure. يمكنك إما استخدام TabularDataset الذي قمت بتصديره من مشروع تسمية البيانات، أو إنشاء TabularDataset جديد ببيانات التدريب المسماة.
إذا كانت بيانات التدريب بتنسيق مختلف (مثل pascal VOC أو COCO)، يمكنك تطبيق البرامج النصية المساعدة المضمنة مع نماذج دفاتر الملاحظات لتحويل البيانات إلى JSONL. تعرّف على المزيد حول كيفية إعداد البيانات لمهام رؤية الكمبيوتر باستخدام التعلم الآلي المؤتمت.
تحذير
يتم دعم إنشاء TabularDatasets من البيانات بتنسيق JSONL باستخدام SDK فقط لهذه الإمكانية. إنشاء مجموعة البيانات عبر واجهة المستخدم غير مدعوم في الوقت الحالي. اعتباراً من الآن، لا تتعرف واجهة المستخدم على نوع بيانات StreamInfo، وهو نوع البيانات المُستخدم لعناوين URL للصور بتنسيق JSONL.
إشعار
يجب أن تحتوي مجموعة بيانات التدريب على 10 صور على الأقل لتتمكن من إرسال تشغيل AutoML.
نماذج مخططات JSONL
تعتمد بنية TabularDataset على المهمة الموجودة. بالنسبة إلى أنواع مهام رؤية الكمبيوتر، تتكون من الحقول التالية:
| الحقل | الوصف |
|---|---|
image_url |
يحتوي على مسار الملف كعنصر StreamInfo |
image_details |
تتكون معلومات بيانات تعريف الصورة من الارتفاع والعرض والتنسيق. هذا الحقل اختياري، وبالتالي قد يكون موجودًا أو غير موجود. |
label |
تمثيل json لتسمية الصورة حسب نوع المهمة. |
فيما يلي نموذج ملف JSONL لتصنيف الصور:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
تمثل التعليمة البرمجية التالية نموذج ملف JSONL لكشف العناصر:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
استهلاك البيانات
بمجرد أن تكون بياناتك بتنسيق JSONL، يمكنك إنشاء TabularDataset مع التعليمات البرمجية التالية:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
لا يفرض التعلم الآلي التلقائي أي قيود على حجم بيانات التدريب أو التحقق من الصحة لمهام رؤية الكمبيوتر. يقتصر الحد الأقصى لحجم مجموعة البيانات فقط على طبقة التخزين خلف مجموعة البيانات (على سبيل المثال، مخزن الكائنات الثنائية كبيرة الحجم). لا يوجد حد أدنى لعدد الصور أو التسميات. ومع ذلك، نوصي بالبدء بما لا يقل عن 10-15 عينة لكل تسمية لضمان تدريب نموذج الإخراج بشكل كافٍ. كلما ارتفع العدد الإجمالي للتسميات/الفئات، زادت العينات التي تحتاجها لكل تسمية.
بيانات التدريب مطلوبة ويتم تمريرها باستخدام المعلمة training_data. يمكنك اختيارياً تحديد TabularDataset أخرى كمجموعة بيانات التحقق من الصحة لاستخدامها للنموذج الخاص بك مع المعلمة validation_data من AutoMLImageConfig. إذا لم يتم تحديد مجموعة بيانات التحقق من الصحة، فسيتم استخدام 20% من بيانات التدريب الخاصة بك للتحقق من الصحة بشكل افتراضي، إلا إذا قمت بتمرير الوسيطة validation_size بقيمة مختلفة.
على سبيل المثال:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
حساب لتشغيل التجربة
يمكن توفير هدف حساب للتعلم الآلي التلقائي لإجراء تدريب نموذج. تتطلب نماذج التعلم الآلي التلقائي لمهام رؤية الكمبيوتر وحدات SKU لـ GPU ودعم مجموعات NC وND. نوصي بسلسلة NCsv3 (مع وحدات معالجة الرسومات v100) لتدريب أسرع. يعمل هدف الحساب مع وحدة SKU متعددة لـ GPU في جهاز ظاهري على الاستفادة من وحدات معالجة الرسومات المتعددة لتسريع التدريب أيضاً. بالإضافة إلى ذلك، عند إعداد هدف حساب مع عقد متعددة، يمكنك إجراء تدريب أسرع على النموذج من خلال التوازي عند ضبط المعلمات الفائقة لنموذجك.
إشعار
إذا كنت تستخدم مثيل حساب كهدف حساب، فيرجى التأكد من عدم تشغيل مهام AutoML متعددة في نفس الوقت. أيضا، يرجى التأكد من تعيين إلى max_concurrent_iterations 1 في موارد التجربة.
يتمثل هدف الحساب في معلمة مطلوبة، ويتم تمريرها باستخدام المعلمة compute_target من AutoMLImageConfig. على سبيل المثال:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
تكوين خوارزميات النموذج والمعلمات الفائقة
مع دعم مهام رؤية الكمبيوتر، يمكنك التحكم في خوارزمية النموذج ومسح المعلمات الفائقة. يتم تمرير خوارزميات النموذج هذه والمعلمات الفائقة كمساحة معلمة للمسح.
خوارزمية النموذج مطلوبة، ويتم تمريرها عبر المعلمة model_name. يمكنك إما تحديد واحد من model_name أو الاختيار بين عدة.
خوارزميات النموذج المدعومة
يلخص الجدول التالي النماذج المدعومة لكل مهمة رؤية كمبيوتر.
| مهمة | خوارزميات النموذج | صيغة أوامر سلسلة حرفيةdefault_model* المشار إليه بـ * |
|---|---|---|
| تصنيف الصورة (متعدد الفئات ومتعددة التسميات) |
MobileNet: نماذج خفيفة الوزن لتطبيقات الجوال ResNet: الشبكات المتبقية ResNeSt: شبكات تقسيم الانتباه SE-ResNeXt50: شبكات الضغط والتحفيز ViT: شبكات محول الرؤية |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (صغير) vitb16r224* (قاعدة) vitl16r224 (كبير) |
| كشف الكائنات | YOLOv5: نموذج الكشف عن الكائنات في مرحلة واحدة RCNN ResNet FPN أسرع: نموذجان للكشف عن الكائنات في المرحلة RetinaNet ResNet FPN: معالجة عدم توازن الفئة مع فقدان التركيز ملاحظة: ارجع إلى model_sizeالمعلمة الفائقة لأحجام نموذج YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| تجزئة مثيل الصورة | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
بالإضافة إلى التحكم في خوارزمية النموذج، يمكنك أيضاً ضبط المعلمات الفائقة المستخدمة لتدريب النموذج. في حين أن العديد من المعلمات الفائقة المكشوفة غير محددة للنموذج، هناك مثيلات تكون فيها المعلمات الفائقة خاصة بالمهمة أو خاصة بالنموذج. تعرّف على المزيد حول المعلمات الفائقة المتوفرة لهذه المثيلات.
زيادة البيانات
بشكل عام، يمكن أن يتحسن أداء نموذج التعلم العميق في كثير من الأحيان بمزيد من البيانات. زيادة البيانات هي تقنية عملية لتضخيم حجم البيانات وتقلب مجموعة البيانات مما يساعد على منع الإفراط في الملاءمة وتحسين قدرة النموذج على التعميم على البيانات غير المرئية. يطبق التعلم الآلي التلقائي تقنيات مختلفة لزيادة البيانات حسب مهمة رؤية الكمبيوتر، قبل تغذية الصور المدخلة إلى النموذج. أما حالياً، لا يوجد معلمة فائقة مكشوفة للتحكم في زيادة البيانات.
| مهمة | مجموعة البيانات المتأثرة | تطبيق تقنية (تقنيات) زيادة البيانات |
|---|---|---|
| تصنيف الصور (متعدد الفئات ومتعدد الملصقات) | التدريب التحقق من الصحة واختباره |
تغيير الحجم والقص العشوائي، والعكس الأفقي، وتشويه الألوان (السطوع والتباين والتشبع واللون)، والتطبيع باستخدام متوسط ImageNet من خلال القناة والانحراف المعياري تغيير الحجم وقص المركز والتسوية |
| كشف العنصر وتجزئة المثيل | التدريب التحقق من الصحة واختباره |
اقتصاص عشوائي حول المربعات المحيطة، والتوسيع، والعكس الأفقي، والتطبيع، وتغيير الحجم التسوية وتغيير الحجم |
| كشف العنصر باستخدام yolov5 | التدريب التحقق من الصحة واختباره |
فسيفساء، أفين عشوائي (تدوير، ترجمة، مقياس، مقص)، انعكاس أفقي تغيير حجم تنسيق letterbox |
تكوين إعدادات تجربتك
قبل إجراء مسح كبير للبحث عن النماذج المثالية والمعلمات الفائقة، نوصي بتجربة القيم الافتراضية للحصول على أساس. بعد ذلك، يمكنك استكشاف العديد من المعلمات الفائقة لنفس النموذج قبل مسح نماذج متعددة ومعلماتها. بهذه الطريقة، يمكنك استخدام نهج أكثر تكراراً، لأنه مع نماذج متعددة ومعلمات فائقة متعددة لكل منها، تزيد مساحة البحث بشكل كبير وتحتاج إلى المزيد من التكرارات للعثور على التكوينات المثالية.
إذا كنت ترغب في استخدام قيم المعلمات الفائقة الافتراضية لخوارزمية معينة (مثل yolov5)، يمكنك تحديد التكوين لتشغيل صورة AutoML على النحو التالي:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
بمجرد إنشاء نموذج أساسي، قد ترغب في تحسين أداء النموذج من أجل مسح خوارزمية النموذج ومساحة المعلمة الفائقة. يمكنك استخدام تكوين العينة التالي لمسح المعلمات الفائقة لكل خوارزمية، والاختيار من بين مجموعة من قيم learning_rate وoptimizer وlr_scheduler وما إلى ذلك، لإنشاء نموذج مع القياس الأساسي الأمثل. إذا لم يتم تحديد قيم المعلمة الفائقة، فاستخدم القيم الافتراضية للخوارزمية المحددة.
المقياس الأساسي
يعتمد القياس الأساسي المستخدم لتحسين النموذج وضبط المعلمات الفائقة على نوع المهمة. استخدام قيم القياس الأساسية الأخرى غير مدعوم حالياً.
accuracyلـ IMAGE_CLASSIFICATIONiouلـ IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionلـ IMAGE_OBJECT_DETECTIONmean_average_precisionلـ IMAGE_INSTANCE_SEGMENTATION
موازنة التجربة
يمكنك اختيارياً تحديد الحد الأقصى للموازنة الزمنية لتجربة AutoML Vision باستخدام experiment_timeout_hours - مقدار الوقت بالساعات قبل إنهاء التجربة. إذا لم يتم تحديد أي شيء، فإن مهلة التجربة الافتراضية هي سبعة أيام (بحد أقصى 60 يوماً).
مسح معلمات فائقة لنموذجك
عند تدريب نماذج رؤية الكمبيوتر، يعتمد أداء النموذج اعتماداً كبيراً على قيم المعلمة الفائقة المحددة. في كثير من الأحيان، قد ترغب في ضبط المعلمات الفائقة للحصول على الأداء الأمثل. مع دعم مهام رؤية الكمبيوتر في التعلم الآلي التلقائي، يمكنك مسح المعلمات الفائقة للعثور على الإعدادات المثالية لنموذجك. تطبق هذه الميزة إمكانات ضبط المعلمات الفائقة في التعلم الآلي من Microsoft Azure. تعرّف على كيفية ضبط المعلمات الفائقة.
تحديد مساحة البحث عن المعلمة
يمكنك تحديد خوارزميات النموذج والمعلمات الفائقة لمسح مساحة المعلمة.
- اطّلع على تكوين خوارزميات النموذج والمعلمات الفائقة لقائمة خوارزميات النموذج المدعومة لكل نوع مهمة.
- اطّلع على المعلمات الفائقة المعلمات الفائقة لمهام رؤية الكمبيوتر لكل نوع مهمة لرؤية الكمبيوتر.
- اطّلع على تفاصيل حول التوزيعات المدعومة للمعلمات الفائقة المنفصلة والمستمرة.
أساليب أخذ العينات للمسح
عند مسح المعلمات الفائقة، عليك تحديد أسلوب أخذ العينات لاستخدامه للمسح على مساحة المعلمة المحددة. يتم حاليًا دعم أساليب أخذ العينات التالية مع المعلمة hyperparameter_sampling:
إشعار
حاليا يدعم أخذ العينات العشوائية والشبكية فقط مسافات المعلمات الفائقة الشرطية.
نُهج الإنهاء المبكر
يمكنك إنهاء عمليات التشغيل ضعيفة الأداء تلقائياً باستخدام نهج الإنهاء المبكر. يعمل الإنهاء المبكر على تحسين الكفاءة الحسابية، مما يوفر موارد الحساب التي كان يمكن إنفاقها بخلاف ذلك على تكوينات أقل رجاءً. يدعم التعلم الآلي التلقائي للصور نُهج الإنهاء المبكر التالية باستخدام المعلمة early_termination_policy. إذا لم يتم تحديد نهج إنهاء، يتم تشغيل جميع التكوينات حتى الاكتمال.
تعرّف على المزيد حول كيفية تكوين نهج الإنهاء المبكر لمسح المعلمات الفائقة.
موارد للمسح
يمكنك التحكم في الموارد التي تم إنفاقها على مسح المعلمات الفائقة عن طريق تحديد iterations وmax_concurrent_iterations للمسح.
| المعلمة | التفاصيل |
|---|---|
iterations |
المعلمة المطلوبة للحد الأقصى لعدد التكوينات التي يجب مسحها. يجب أن يكون عدداً صحيحاً بين 1 و1000. عند استكشاف المعلمات الفائقة الافتراضية لخوارزمية نموذج معينة فقط، قم بتعيين هذه المعلمة إلى 1. |
max_concurrent_iterations |
الحد الأقصى لعدد عمليات التشغيل التي يمكن تشغيلها بشكل متزامن. إذا لم يتم تحديدها، يتم تشغيل جميع عمليات التشغيل بالتوازي. في حال عدم التحديد، يجب أن يكون عدداً صحيحاً بين 1 و100. ملاحظة: يتم تحديد عدد عمليات التشغيل المتزامنة على الموارد المتوفرة في هدف الحساب المحدد. تأكد من أن هدف الحساب لديه الموارد المتاحة للتزامن المطلوب. |
إشعار
للحصول على عينة تكوين مسح كاملة، يرجى الرجوع إلى هذا البرنامج التعليمي.
الوسيطات
يمكنك تمرير الإعدادات أو المعلمات الثابتة التي لا تتغير أثناء مسح مساحة المعلمة مثل الوسيطات. يتم تمرير الوسيطات في أزواج اسم - قيمة، ويجب أن يكون الاسم مسبوقاً بشرطة مزدوجة.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
تدريب تزايدي (اختياري)
بمجرد الانتهاء من تشغيل التدريب، لديك خيار مواصلة تدريب النموذج عن طريق تحميل نقطة تفتيش النموذج المدربة. يمكنك إما استخدام نفس مجموعة البيانات أو مجموعة مختلفة للتدريب التزايدي.
هناك خياران متاحان للتدريب التزايدي. بإمكانك،
- تمرير معرّف التشغيل الذي تريد تحميل نقطة التحقق منه.
- تمرير نقاط التحقق من خلال FileDataset.
تمرير نقطة التحقق عبر معرّف التشغيل
للعثور على معرّف التشغيل من النموذج المطلوب، يمكنك استخدام التعليمة البرمجية التالية.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
لتمرير نقطة تحقق عبر معرّف التشغيل، عليك استخدام المعلمة checkpoint_run_id.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
تمرير نقطة التحقق عبر FileDataset
لتمرير نقطة تحقق عبر FileDataset، تحتاج إلى استخدام المعلمتين checkpoint_dataset_id وcheckpoint_filename.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
إرسال التشغيل
عندما يكون العنصر AutoMLImageConfig جاهزاً، يمكنك إرسال التجربة.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
المخرجات ومقاييس التقييم
تنشئ عمليات تشغيل تدريب التعلم الآلي التلقائي ملفات نموذج الإخراج ومقاييس التقييم والسجلات وبيانات التوزيع الاصطناعية، مثل ملف التسجيل وملف البيئة الذي يمكن عرضه من علامة تبويب المخرجات والسجلات والمقاييس الخاصة بالتشغيلات التابعة.
تلميح
تحقق من كيفية الانتقال إلى نتائج الوظيفة من قسم عرض نتائج التشغيل.
للحصول على تعريفات وأمثلة للمخططات البيانية عن الأداء والمقاييس المقدمة لكل تشغيل، اطّلع على تقييم نتائج تجربة التعلم الآلي التلقائي
تسجيل النموذج وتوزيعه
بمجرد اكتمال التشغيل، يمكنك تسجيل النموذج الذي تم إنشاؤه من أفضل تشغيل (التكوين الذي أدى إلى أفضل قياس أساسي)
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
بعد تسجيل النموذج الذي تريد استخدامه، يمكنك توزيعه كخدمة ويب على مثيلات حاوية Azure (ACI) أو Azure Kubernetes Service (AKS). مثيلات حاويات Azure (ACI) هي الخيار الأمثل لاختبار عمليات النشر، في حين أن AKS هي أكثر ملاءمة للاستخدام والإنتاج على نطاق واسع.
يوزع هذا المثال النموذج كخدمة ويب في AKS. للتوزيع في AKS، قم أولاً بإنشاء نظام مجموعة حساب AKS أو استخدام نظام مجموعة AKS موجود. يمكنك استخدام وحدات SKU لوحدة معالجة الرسومات أو وحدة المعالجة المركزية الظاهرية لمجموعة التوزيع لديك.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
بعد ذلك، يمكنك تحديد تكوين الاستدلال، الذي يصف كيفية إعداد خدمة الويب التي تحتوي على نموذجك. يمكنك استخدام البرنامج النصي لتسجيل النقاط والبيئة من تشغيل التدريب في تكوين الاستدلال الخاص بك.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
يمكنك بعد ذلك نشر النموذج كخدمة ويب AKS.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
بدلاً من ذلك، يمكنك توزيع النموذج من واجهة مستخدم استوديو التعلم الآلي من Microsoft Azure. انتقل إلى النموذج الذي ترغب في توزيعه في علامة التبويب النماذج لتشغيل التعلم الآلي التلقائي، وحدد توزيع.
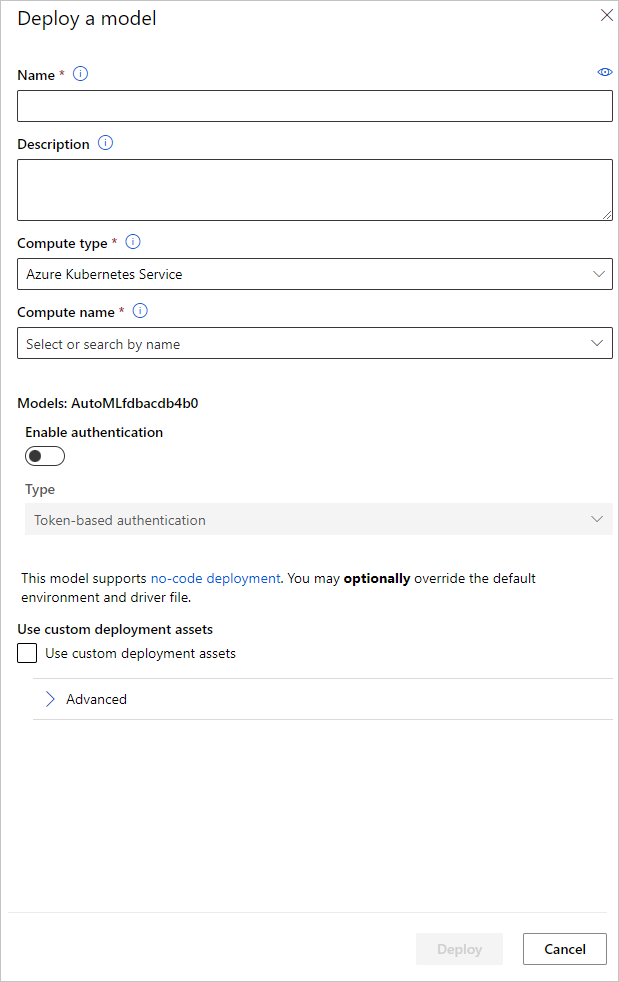
بإمكانك تكوين اسم نقطة نهاية توزيع النموذج ونظام مجموعة الاستدلال لاستخدامها لتوزيع نموذجك في جزء توزيع نموذج.
تحديث تكوين الاستدلال
في الخطوة السابقة، قمنا بتنزيل ملف تسجيل النقاط outputs/scoring_file_v_1_0_0.py من أفضل نموذج إلى ملف score.py المحلي، واستخدمناه لإنشاء عنصر InferenceConfig. يمكن تعديل هذا البرنامج النصي لتغيير إعدادات الاستدلال الخاصة بالنموذج إذا لزم الأمر بعد تنزيله وقبل إنشاء InferenceConfig. على سبيل المثال، هذا هو قسم التعليمات البرمجية الذي يقوم بتهيئة النموذج في ملف تسجيل النقاط:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
تحتوي كل مهمة من المهام (وبعض النماذج) على مجموعة من المعلمات في القاموس model_settings. بشكل افتراضي، نستخدم نفس القيم للمعلمات التي تم استخدامها أثناء التدريب والتحقق من الصحة. اعتماداً على السلوك الذي نحتاجه عند استخدام النموذج للاستدلال، يمكننا تغيير هذه المعلمات. يمكنك العثور أدناه على قائمة المعلمات لكل نوع مهمة ونموذج.
| مهمة | اسم المعلمة | الإعداد الافتراضي |
|---|---|---|
| تصنيف الصور (متعدد الفئات ومتعدد الملصقات) | valid_resize_sizevalid_crop_size |
256 224 |
| كشف الكائنات | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
الكشف عن العناصر باستخدام yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 متوسطة 0.1 0.5 |
| تجزئة مثيل الصورة | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 خطأ JPG |
للحصول على وصف مفصل حول المعلمات الفائقة الخاصة بالمهمة، يرجى الرجوع إلى المعلمات الفائقة لمهام رؤية الكمبيوتر في التعلم الآلي التلقائي.
إذا كنت تريد استخدام التجانب، وتريد التحكم في سلوك التجانب، تتوفر المعلمات التالية: tile_grid_size وtile_overlap_ratio وtile_predictions_nms_thresh. لمزيد من التفاصيل حول هذه المعلمات، يرجى التحقق من تدريب نموذج اكتشاف عنصر صغير باستخدام AutoML.
مثال دفاتر الملاحظات
راجع أمثلة التعليمات البرمجية التفصيلية وحالات الاستخدام في مستودع دفتر الملاحظات GitHub لعينات التعلم الآلي. يرجى التحقق من المجلدات مع بادئة "صورة" لعينات مُحددة لبناء نماذج تصور الكمبيوتر.
الخطوات التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ