عرض التعليمات البرمجية للتدريب لنموذج التعلم الآلي التلقائي
في هذه المقالة، ستتعلم كيفية عرض التعليمات البرمجية للتدريب التي تم إنشاؤها من أي نموذج مدرب للتعلم الآلي التلقائي.
يتيح لك إنشاء التعليمات البرمجية لنماذج التعلم الآلي المدربة رؤية التفاصيل التالية التي يستخدمها التعلم الآلي التلقائي لتدريب وبناء النموذج لتشغيل معين.
- ما قبل معالجة البيانات
- تحديد الخوارزمية
- التمييز
- المعلمات الفائقة
يمكنك تحديد أي نموذج تعلم آلي مدرب تلقائي، أو تشغيل موصى به أو تابع، وعرض التعليمة البرمجية لتدريب Python الذي تم إنشاؤه الذي أنشأ هذا النموذج المحدد.
باستخدام التعليمات البرمجية للتدريب الخاص بالنموذج الذي تم إنشاؤه، يمكنك،
- التعرف على عملية التمييز والمقاييس الفائقة التي تستخدمها خوارزمية النموذج.
- تعقب/إصدار/تدقيق النماذج المدربة. قم بتخزين التعليمات البرمجية التي تم إصدارها لتعقب التعليمات البرمجية التدريبية المحددة المستخدمة مع النموذج الذي سيتم توزيعه إلى الإنتاج.
- تخصيص التعليمات البرمجية للتدريب عن طريق تغيير المعلمات الفائقة أو تطبيق مهارات/خبرة التعلم الآلي والخوارزميات، وإعادة تدريب نموذج جديد باستخدام التعليمات البرمجية المخصصة.
يوضح الرسم التخطيطي التالي أنه يمكنك إنشاء التعليمات البرمجية لتجارب التعلم الآلي مع جميع أنواع المهام. أولًا حدد نموذجًا. سيتم تمييز النموذج الذي حددته، ثم يقوم التعلم الآلي من Microsoft Azure بنسخ ملفات التعليمات البرمجية المستخدمة لإنشاء النموذج، وعرضها في مجلد دفاتر الملاحظات المشترك. من هنا، يمكنك عرض التعليمات البرمجية وتخصيصها حسب الحاجة.
المتطلبات الأساسية
مساحة عمل للتعلم الآلي من Microsoft Azure. لإنشاء مساحة العمل، انظر إنشاء موارد مساحة العمل .
تفترض هذه المقالة بعض الإلمام بإعداد تجربة تعلم آلي تلقائي. اتبع البرنامج التعليمي أو كيفية للاطلاع على أنماط تصميم تجربة التعلم الآلي الرئيسية.
يتوفر إنشاء التعليمات البرمجية التلقائية ل ML فقط للتجارب التي يتم تشغيلها على أهداف الحوسبة التعلم الآلي Azure البعيدة. إنشاء التعليمات البرمجية غير مدعوم لعمليات التشغيل المحلية.
سيتم تمكين إنشاء التعليمات البرمجية لجميع عمليات تشغيل التعلم الآلي المؤتمتة التي يتم تشغيلها من خلال Azure التعلم الآلي studio أو SDKv2 أو CLIv2.
الحصول على التعليمات البرمجية التي تم إنشاؤها وبيانات النموذج الاصطناعية
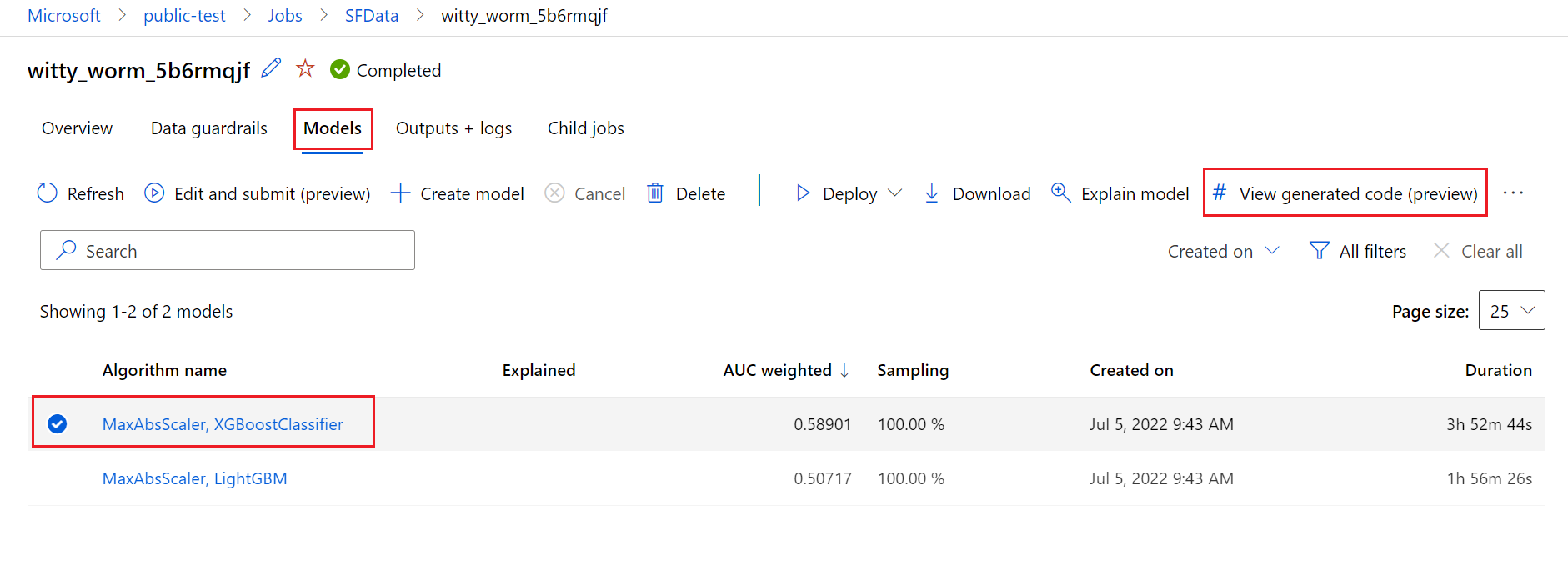
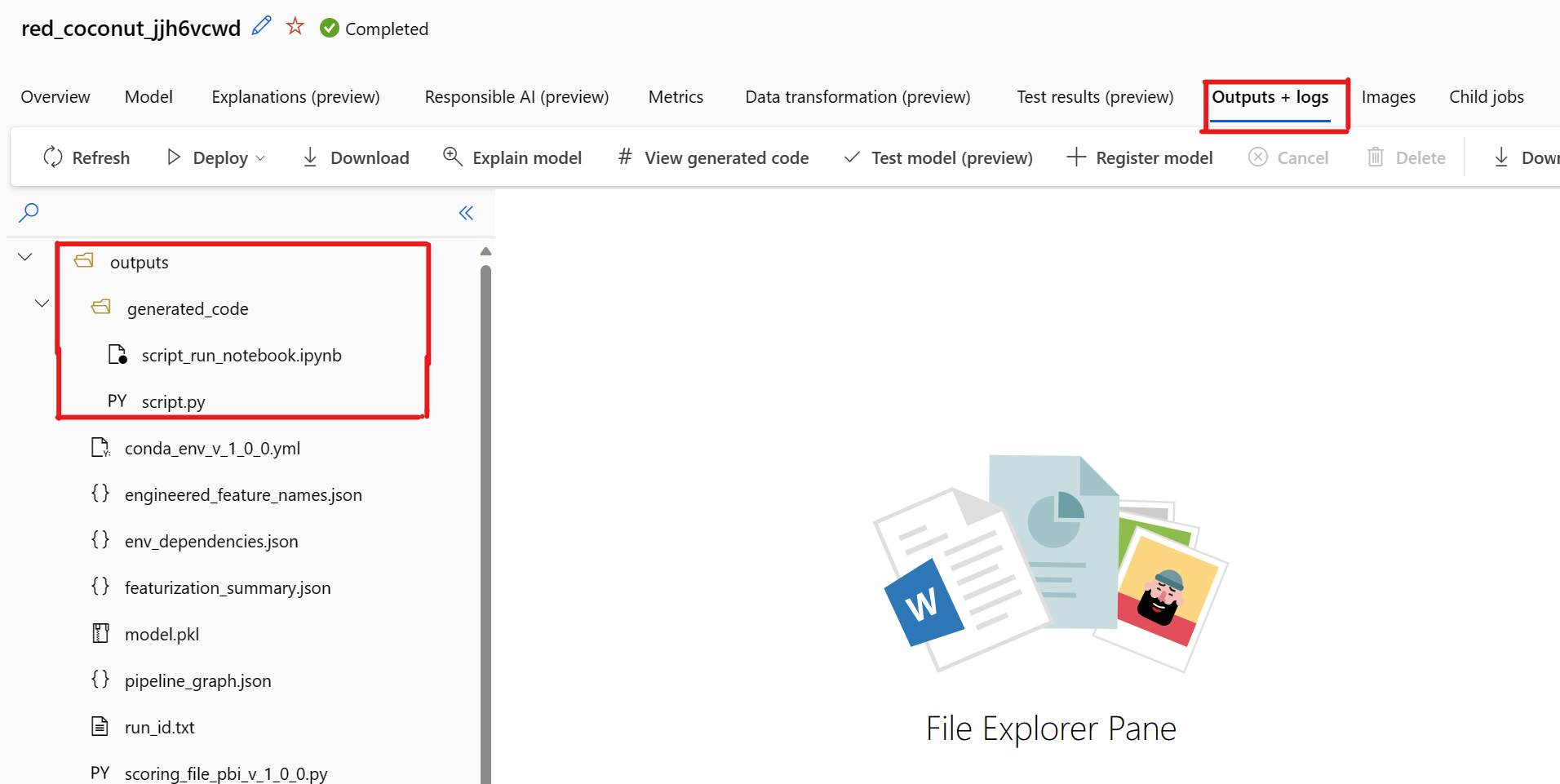
بشكل افتراضي، يقوم كل نموذج مدرب للتعلم الآلي التلقائي بإنشاء تعليمة برمجية للتدريب الخاص به بعد اكتمال التدريب. يحفظ التعلم الآلي التلقائي هذه التعليمات البرمجية في التجربة outputs/generated_code لهذا النموذج المحدد. يمكنك عرضها في واجهة مستخدم Azure التعلم الآلي studio في علامة التبويب Outputs + logs للنموذج المحدد.
script.py يشير إلى التعليمة البرمجية للتدريب الخاص بالنموذج الذي من المحتمل أن ترغب في تحليله بخطوات التمييز والخوارزمية المحددة المستخدمة والمقاييس الفائقة.
دفتر ملاحظات script_run_notebook.ipynb مع رمز لوحة المرجل لتشغيل التعليمات البرمجية للتدريب للنموذج (script.py) في Azure التعلم الآلي الحوسبة من خلال Azure التعلم الآلي SDKv2.
بعد اكتمال تشغيل التدريب التلقائي على التعلم الآلي، يمكنك الوصول إلى script.py الملفات و script_run_notebook.ipynb عبر واجهة مستخدم Azure التعلم الآلي studio.
للقيام بذلك، انتقل إلى علامة التبويب Models في صفحة التشغيل الأصل لتجربة التعلم الآلي التلقائية. بعد تحديد أحد النماذج المدربة، يمكنك تحديد الزر عرض التعليمات البرمجية التي تم إنشاؤها. يعيد هذا الزر توجيهك إلى ملحق مدخل دفاتر الملاحظات، حيث يمكنك عرض التعليمات البرمجية التي تم إنشاؤها لهذا النموذج المحدد وتحريرها وتشغيلها.
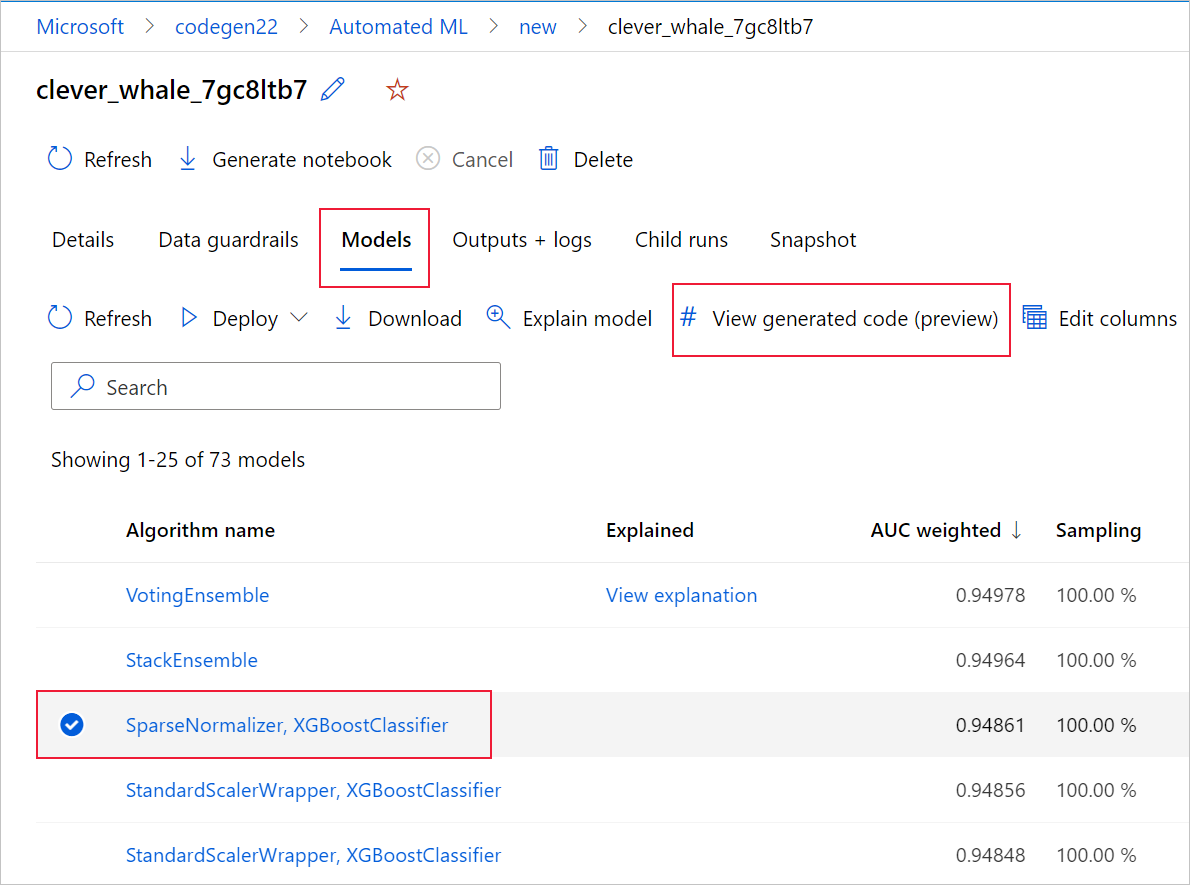
يمكنك أيضا الوصول إلى التعليمات البرمجية التي تم إنشاؤها للنموذج من أعلى صفحة التشغيل التابع بمجرد الانتقال إلى صفحة التشغيل التابعة لنموذج معين.
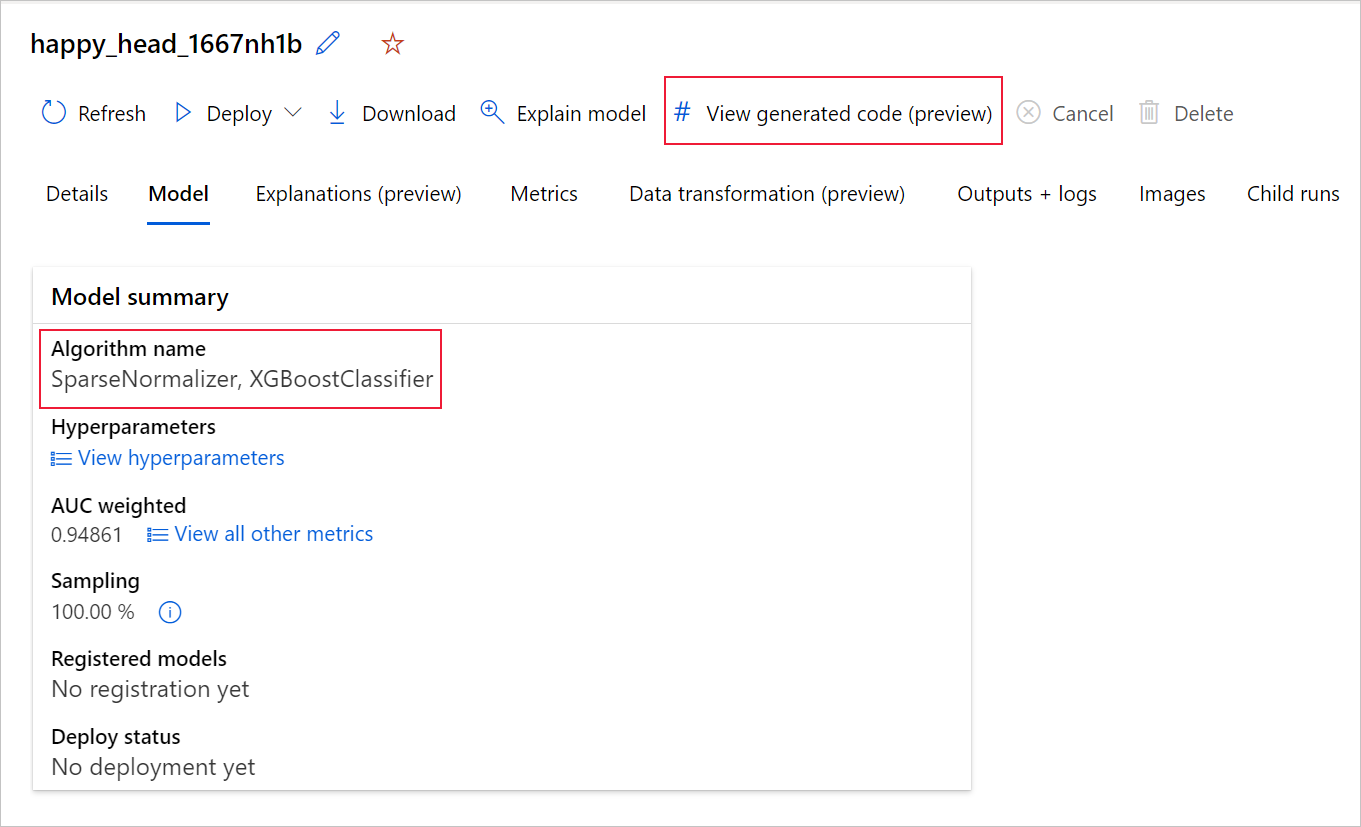
إذا كنت تستخدم Python SDKv2، يمكنك أيضا تنزيل "script.py" و"script_run_notebook.ipynb" عن طريق استرداد أفضل تشغيل عبر MLFlow وتنزيل البيانات الاصطناعية الناتجة.
القيود
هناك مشكلة معروفة عند تحديد عرض التعليمات البرمجية التي تم إنشاؤها. يفشل هذا الإجراء في إعادة التوجيه إلى مدخل دفاتر الملاحظات عندما يكون التخزين خلف VNet. كحل بديل، يمكن للمستخدم تنزيل script.py وملفات script_run_notebook.ipynb يدويا عن طريق الانتقال إلى علامة التبويب Outputs + Logs ضمن مجلد outputs>generated_code. يمكن تحميل هذه الملفات يدويا إلى مجلد دفاتر الملاحظات لتشغيلها أو تحريرها. اتبع هذا الارتباط لمعرفة المزيد حول VNets في Azure التعلم الآلي.
script.py
يحتوي الملف script.py على المنطق الأساسي اللازم لتدريب نموذج باستخدام المعلمات الفائقة المستخدمة مسبقاً. في حين أن الغرض من تنفيذه في سياق تشغيل برنامج نصي Azure التعلم الآلي، مع بعض التعديلات، يمكن أيضا تشغيل التعليمات البرمجية للتدريب الخاص بالنموذج بشكل مستقل في البيئة المحلية الخاصة بك.
يمكن تقسيم البرنامج النصي تقريباً إلى العديد من الأجزاء التالية: تحميل البيانات وإعداد البيانات وتمييز البيانات ومواصفات المعالج المسبق/الخوارزمية والتدريب.
تحميل البيانات
تقوم الدالة get_training_dataset() بتحميل مجموعة البيانات المستخدمة مسبقاً. يفترض أن البرنامج النصي يتم تشغيله في برنامج نصي Azure التعلم الآلي يعمل ضمن نفس مساحة العمل مثل التجربة الأصلية.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
عند التشغيل كجزء من تشغيل برنامج نصي، يسترد Run.get_context().experiment.workspace مساحة العمل الصحيحة. ومع ذلك، إذا تم تشغيل هذا البرنامج النصي داخل مساحة عمل مختلفة أو تشغيله محليا، تحتاج إلى تعديل البرنامج النصي لتحديد مساحة العمل المناسبة بشكل صريح.
بمجرد استرداد مساحة العمل، يتم استرداد مجموعة البيانات الأصلية بواسطة معرفها. يمكن أيضاً تحديد مجموعة بيانات أخرى بنفس البنية تماماً بواسطة المعرف أو الاسم مع get_by_id() أو get_by_name()، على التوالي. يمكنك العثور على المعرف لاحقاً في البرنامج النصي، في قسم مشابه للتعليمات البرمجية التالية.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
يمكنك أيضا اختيار استبدال هذه الدالة بأكملها بآلية تحميل البيانات الخاصة بك؛ القيود الوحيدة هي أن القيمة المرجعة يجب أن تكون إطار بيانات Pandas، وأن البيانات يجب أن يكون لها نفس الشكل كما هو الحال في التجربة الأصلية.
التعليمات البرمجية لإعداد البيانات
تقوم الدالة prepare_data() بتنظيف البيانات وتقسيم الميزة وأعمدة وزن العينة وإعداد البيانات لاستخدامها في التدريب.
يمكن أن تختلف هذه الدالة اعتمادا على نوع مجموعة البيانات ونوع مهمة التجربة: التصنيف أو الانحدار أو التنبؤ بالسلاسل الزمنية أو الصور أو مهام NLP.
يوضح المثال التالي أنه بشكل عام، يتم تمرير إطار البيانات من خطوة تحميل البيانات. يتم استخراج عمود التسمية ونماذج الأوزان، إذا تم تحديدها في الأصل، ويتم إسقاط الصفوف التي تحتوي على NaN من بيانات الإدخال.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
إذا كنت ترغب في إجراء المزيد من إعداد البيانات، يمكن القيام بذلك في هذه الخطوة عن طريق إضافة التعليمات البرمجية المخصصة لإعداد البيانات.
التعليمة البرمجية لتمييز البيانات
تحدد الدالة generate_data_transformation_config() خطوة التمييز في مسار scikit-learn النهائي. تتم هنا إعادة إنتاج العوامل المميزة من التجربة الأصلية، جنبًا إلى جنب مع معلماتها.
على سبيل المثال، يمكن أن يستند تحويل البيانات المحتمل الذي يمكن أن يحدث في هذه الدالة إلى ملصقات، مثل SimpleImputer() وCatImputer()، أو محولات مثل StringCastTransformer() وLabelEncoderTransformer().
فيما يلي محول من النوع StringCastTransformer() الذي يمكن استخدامه لتحويل مجموعة من الأعمدة. في هذه الحالة، المجموعة المشار إليها بواسطة column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
إذا كان لديك العديد من الأعمدة التي تحتاج إلى تطبيق نفس الميزات/التحويل (على سبيل المثال، 50 عمودا في عدة مجموعات أعمدة)، تتم معالجة هذه الأعمدة عن طريق التجميع استنادا إلى النوع.
في المثال التالي، لاحظ أن كل مجموعة لديها معين فريد مطبق. ثم يتم تطبيق محدد التعيين هذا على كل عمود من أعمدة تلك المجموعة.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
يتيح لك هذا الأسلوب الحصول على تعليمات برمجية أكثر بساطة، من خلال عدم وجود كتلة تعليمات برمجية لمحول لكل عمود، والذي يمكن أن تكون مرهقة بشكل خاص حتى عندما تكون لديك عشرات أو مئات الأعمدة في مجموعة البيانات الخاصة بك.
مع مهام التصنيف والتراجع، يتم استخدام [FeatureUnion] لعوامل التمييز.
بالنسبة لنماذج التنبؤ بالسلاسل الزمنية، يتم جمع العديد من المميزات المدركة للسلاسل الزمنية في مسار scikit-learn، ثم يتم تضمينها في TimeSeriesTransformer.
يحدث أي مستخدم يقدم ميزات لنماذج التنبؤ بالسلاسل الزمنية قبل تلك التي يوفرها التعلم الآلي التلقائي.
التعليمات البرمجية لمواصفات المعالج المسبق
تحدد الدالة generate_preprocessor_config()، إذا كانت موجودة، خطوة معالجة مسبقة يجب إجراؤها بعد التمييز في مسار scikit-learn النهائي.
عادةً، تتكون خطوة المعالجة المسبقة هذه فقط من توحيد/تسوية البيانات التي يتم إنجازها باستخدام sklearn.preprocessing.
يحدد التعلم الآلي التلقائي خطوة المعالجة المسبقة فقط لنماذج التصنيف والانحدار غير القابلة للانحدار.
فيما يلي مثال على التعليمات البرمجية التي تم إنشاؤها للمعالج المسبق:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
التعليمات البرمجية لمواصفات الخوارزمية والمعلمات الفائقة
من المحتمل أن تكون الخوارزمية والتعليمات البرمجية لمواصفات المعلمات الفائقة هو أكثر ما يهتم به العديد من محترفي التعلم الآلي.
تحدد الدالة generate_algorithm_config() الخوارزمية الفعلية والمقاييس الفائقة لتدريب النموذج كمرحلة أخيرة من مسار scikit-learn النهائي.
يستخدم المثال التالي خوارزمية XGBoostClassifier مع المعلمات الفائقة المحددة.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
تستخدم التعليمات البرمجية التي تم إنشاؤها في معظم الحالات حزم وفئات البرامج مفتوحة المصدر (OSS). هناك مثيلات حيث يتم استخدام فئات برنامج تضمين وسيط لتبسيط التعليمات البرمجية الأكثر تعقيداً. على سبيل المثال، يمكن تطبيق مصنف XGBoost والمكتبات الأخرى شائعة الاستخدام، مثل LightGBM أو خوارزميات Scikit-Learn.
بصفتك محترف التعلم الآلي، يمكنك تخصيص التعليمات البرمجية لتكوين هذه الخوارزمية عن طريق تعديل المعلمات الفائقة حسب الحاجة استنادا إلى مهاراتك وخبراتك لتلك الخوارزمية ومشكلة التعلم الآلي الخاصة بك.
بالنسبة لنماذج الفرق، يتم تحديد generate_preprocessor_config_N() (إذا لزم الأمر) وgenerate_algorithm_config_N() لكل متعلم في نموذج المجموعة، حيث يمثل N موضع كل متعلم في قائمة نموذج المجموعة. بالنسبة لنماذج مجموعة المكدس، يتم تعريف متعلم التعريف generate_algorithm_config_meta().
التعليمات البرمجية للتدريب الشامل
يصدر إنشاء التعليمات البرمجية build_model_pipeline() وtrain_model() لتحديد مسار scikit-learn واستدعاء fit()، على التوالي.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
يتضمن مسار scikit-learn خطوة التمييز، والمعالج المسبق (إذا تم استخدامه)، والخوارزمية أو النموذج.
بالنسبة لنماذج التنبؤ بالسلاسل الزمنية، يتم التفاف مسار scikit-learn في ForecastingPipelineWrapper، والذي يحتوي على بعض المنطق الإضافي اللازم للتعامل بشكل صحيح مع بيانات السلسلة الزمنية اعتماداً على الخوارزمية المطبقة.
بالنسبة لجميع أنواع المهام، نستخدم PipelineWithYTransformer في الحالات التي يحتاج فيها عمود التسمية إلى ترميز.
بمجرد أن يكون لديك مسار scikit-Learn، كل ما تبقى للاستدعاء هو الأسلوب fit() لتدريب النموذج:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
تتمثل القيمة المرجعة من train_model() في النموذج المجهز/المدرب على بيانات الإدخال.
التعليمات البرمجية الرئيسية التي تقوم بتشغيل جميع الدالات السابقة هي ما يلي:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
بمجرد حصولك على النموذج المدرب، يمكنك استخدامه لإجراء تنبؤات باستخدام أسلوب predict(). إذا كانت تجربتك لنموذج سلسلة زمنية، فاستخدم أسلوب forecast() للتنبؤات.
y_pred = model.predict(X)
وأخيراً، يتم تسلسل النموذج وحفظه كملف .pkl يسمى "model.pkl":
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
script_run_notebook.ipynb يعمل دفتر الملاحظات كطريقة سهلة للتنفيذ script.py على حساب Azure التعلم الآلي.
يشبه دفتر الملاحظات هذا نماذج دفاتر ملاحظات التعلم الآلي الموجودة، ومع ذلك، هناك بعض الاختلافات الرئيسية كما هو موضح في الأقسام التالية.
البيئة
عادةً ما يتم تعيين بيئة التدريب لتشغيل التعلم الآلي التلقائي بواسطة SDK. ومع ذلك، عند تشغيل برنامج نصي مخصص مثل التعليمات البرمجية التي تم إنشاؤها، لم يعد التعلم الآلي التلقائي يقود العملية، لذلك يجب تحديد البيئة حتى تنجح مهمة الأمر.
يعيد إنشاء التعليمات البرمجية استخدام البيئة التي تم استخدامها في تجربة التعلم الآلي الأصلية، إن أمكن. يضمن القيام بذلك أن تشغيل البرنامج النصي للتدريب لا يفشل بسبب التبعيات المفقودة، ولديه فائدة جانبية لعدم الحاجة إلى إعادة إنشاء صورة Docker، ما يوفر الوقت وموارد الحساب.
إذا قمت بإجراء تغييرات على script.py ذلك تتطلب تبعيات إضافية، أو كنت ترغب في استخدام البيئة الخاصة بك، تحتاج إلى تحديث البيئة وفقا script_run_notebook.ipynb لذلك.
إرسال التجربة
نظرا لأن التعليمات البرمجية التي تم إنشاؤها لم تعد مدفوعة ب ML تلقائي، بدلا من إنشاء مهمة AutoML وإرسالها، تحتاج إلى إنشاء Command Job وتوفير التعليمات البرمجية التي تم إنشاؤها (script.py) إليها.
يحتوي المثال التالي على المعلمات والتبعيات العادية اللازمة لتشغيل مهمة أمر، مثل الحوسبة والبيئة وما إلى ذلك.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
الخطوات التالية
- تعرف على المزيد حول طريقة توزيع النموذج ومكانه.
- تعرف على كيفية تمكين ميزات قابلية التفسير تحديدًا في تجارب التعلم الآلي المؤتمت.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ