استخدام حزمة قابلية تفسير Python لشرح نماذج التعلم الآلي والتنبؤات (معاينة)
ينطبق على: Python SDK azureml v1
Python SDK azureml v1
في دليل الإرشاد هذا، ستتعلم استخدام حزمة التفسير الخاصة بالتعلم الآلي من Microsoft Azure Python SDK لأداء المهام التالية:
اشرح سلوك النموذج بالكامل أو التنبؤات الفردية على جهازك الشخصي محلياً.
تمكين التقنيات القابلية للتفسير للميزات المهندسة.
اشرح سلوك النموذج بأكمله والتنبؤات الفردية في Azure.
تحميل التفسيرات إلى محفوظات تشغيل التعلم الآلي في Azure.
استخدم لوحة معلومات المرئيات للتفاعل مع تفسيرات النموذج، في كل من Jupyter Notebook وفي أستوديو التعلم الآلي من Microsoft Azure.
وزع شرحاً للدرجات جنباً إلى جنب مع نموذجك لملاحظة التفسيرات أثناء الاستنتاج.
هام
تُعد هذه الميزة قيد الإصدار الأولي العام في الوقت الحالي. يجري توفير إصدار المعاينة هذا دون اتفاقية على مستوى الخدمة، ولا نوصي باستخدامه لأحمال عمل الإنتاج. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة.
لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
لمزيد من المعلومات بشأن أساليب التفسير المدعومة ونماذج التعلم الآلي، راجع إمكانية تفسير النماذج في التعلم الآلي من Microsoft Azure ونماذج من دفاتر الملاحظات.
للحصول على إرشادات بشأن كيفية تمكين القابلية للتفسير للنماذج المدربة على التعلم الآلي، راجع التفسير: تفسيرات نموذجية لنماذج التعلم الآلي التلقائية (إصدار أولي).
توليد قيمة أهمية الميزة على جهازك الشخصي
يوضح المثال التالي كيفية استخدام حزمة التفسير على جهازك الشخصي دون الاتصال بخدمات Azure.
ثبّت حزمة
azureml-interpret.pip install azureml-interpretتدريب نموذج العينة في دفتر Jupyter المحلي.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)اتصل بالشرح محليا.
- لتكوين عنصر توضيحي، قم بتمرير النموذج الخاص بك وبعض بيانات التدريب إلى دالة إنشاء الشرح.
- لجعل التفسيرات والمرئيات الخاصة بك أكثر إفادة، يمكنك اختيار تمرير أسماء الميزات وأسماء فئات الإخراج إذا كنت تقوم بالتصنيف.
توضح كتل التعليمة البرمجية التالية كيفية إنشاء مثيل لعنصر توضيح باستخدام
TabularExplainer،MimicExplainer، وPFIExplainerمحلياً.TabularExplainerيستدعي أحد توضيحات SHAP الثلاثة الموجودة أسفل (TreeExplainer،DeepExplainerأوKernelExplainer).TabularExplainerيقوم تلقائياً بتحديد أنسب واحد لحالة الاستخدام الخاصة بك، ولكن يمكنك استدعاء كل من المفسرين الثلاثة الأساسيين مباشرة.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)أو
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)أو
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
شرح سلوك النموذج بالكامل (شرح عمومي)
راجع المثال التالي لمساعدتك في الحصول على القيم الإجمالية (عمومي) لأهمية الميزة.
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
اشرح تنبؤاً فردياً (تفسير محلي)
احصل على قيم أهمية الميزة الفردية لنقاط البيانات المختلفة عن طريق اتصال تفسيرات لمثيل فردي أو مجموعة مثيلات.
إشعار
PFIExplainer لا يدعم التفسيرات المحلية.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
تحويلات الميزات الأولية
يمكنك اختيار الحصول على تفسيرات من حيث الميزات الأولية غير المحولة بدلاً من الميزات الهندسية. بالنسبة إلى هذا الخيار، تقوم بتمرير البنية الأساسية لبرنامج ربط العمليات التجارية تحويل الميزات إلى الشرح في train_explain.py. بخلاف ذلك، يقدم الشرح تفسيرات من حيث الميزات الهندسية.
تنسيق التحويلات المدعومة هو نفسه الموضح في sklearn-pandas. بشكل عام، يتم دعم أي تحويلات طالما أنها تعمل في عمود واحد بحيث يكون من الواضح أنها تحويلات من شخص إلي متعدد.
احصل على شرح للميزات الأولية باستخدام sklearn.compose.ColumnTransformer أو مع قائمة مجموعات المحولات المجهزة. يستخدم المثال التالي sklearn.compose.ColumnTransformer.
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
إذا كنت تريد تشغيل المثال بقائمة مجموعات المحولات المجهزة، فاستخدم التعليمة البرمجية التالية:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
توليد قيم أهمية الميزة عبر عمليات التشغيل عن بعد
يوضح المثال التالي كيف يمكنك استخدام فئة ExplanationClient لتمكين إمكانية تفسير النموذج لعمليات التشغيل عن بُعد. إنها تشبه من الناحية المفاهيمية العملية المحلية، إلا إنك:
- استخدم
ExplanationClientفي التشغيل البعيد لتحميل سياق التفسير. - قم بتنزيل السياق لاحقاً في بيئة محلية.
ثبّت حزمة
azureml-interpret.pip install azureml-interpretقم بإنشاء برنامج نصي للتدريب في Jupyter Notebook محلي. على سبيل المثال،
train_explain.pyfrom azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')قم بإعداد التعلم الآلي من Microsoft Azure Compute كهدف حسابي وأرسل تشغيل التدريب الخاص بك. راجع إنشاء وإدارة مجموعات حوسبة التعلم الآلي من Microsoft Azure للحصول على الإرشادات. قد تجد أيضاً أن نماذج المفكرات مفيدة.
قم بتنزيل الشرح في دفتر Jupyter المحلي الخاص بك.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
الرسوم المرئية
بعد تنزيل التوضيحات في دفتر Jupyter Notebooks المحلي لديك، يمكنك استخدام المرئيات في لوحة معلومات التفسيرات لفهم وتفسير النموذج الخاص بك. لتحميل أداة لوحة معلومات التفسيرات في Jupyter Notebook، استخدم التعليمة البرمجية التالية:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
تدعم المرئيات التفسيرات على كل من الميزات الهندسية والأولية. تستند التفسيرات الأولية إلى الميزات من مجموعة البيانات الأصلية وتستند التفسيرات المهندسة إلى الميزات من مجموعة البيانات مع تطبيق هندسة الميزات.
عند محاولة تفسير نموذج فيما يتعلق بمجموعة البيانات الأصلية، يوصى باستخدام تفسيرات أولية لأن أهمية كل ميزة ستتوافق مع عمود من مجموعة البيانات الأصلية. أحد السيناريوهات التي قد تكون فيها التفسيرات المهندسة مفيدة عند فحص تأثير الفئات الفردية من ميزة فئوية. إذا تم تطبيق ترميز واحد ساخن على ميزة فئوية، فستتضمن التفسيرات الهندسية الناتجة قيمة أهمية مختلفة لكل فئة، واحدة لكل ميزة هندسية ساخنة. يمكن أن يكون هذا الترميز مفيداً عند تضييق نطاق أي جزء من مجموعة البيانات يكون أكثر إفادة للنموذج.
إشعار
يتم حساب التفسيرات الهندسية والخام بالتسلسل. أولاً، يتم إنشاء تفسير هندسي بناءً على النموذج والبنية الأساسية لبرنامج ربط العمليات التجارية بالتوصيف. ثم يتم إنشاء التفسير الأولي بناءً على هذا التفسير الهندسي من خلال تجميع أهمية الميزات الهندسية التي جاءت من نفس الميزة الأولية.
إنشاء مجموعات البيانات وتحريرها وعرضها
يعرض الشريط العلوي الإحصائيات الإجمالية بشأن النموذج والبيانات الخاصة بك. يمكنك تقسيم بياناتك إلى مجموعات نموذجية أو مجموعات فرعية للتحقيق أو المقارنة بين أداء وتفسيرات نموذجك عبر هذه المجموعات الفرعية المحددة. من خلال مقارنة إحصائيات وتفسيرات مجموعة البيانات الخاصة بك عبر هذه المجموعات الفرعية، يمكنك الحصول على فكرة عن سبب حدوث الأخطاء المحتملة في مجموعة مقابل أخرى.

فهم سلوك النموذج بالكامل (شرح عمومي)
توفر علامات التبويب الثلاث الأولى من لوحة معلومات الشرح تحليلاً شاملاً للنموذج المدرب جنباً إلى جنب مع تنبؤاته وتفسيراته.
أداء النموذج
قم بتقييم أداء النموذج الخاص بك عن طريق استكشاف توزيع قيم التنبؤ وقيم قياسات أداء النموذج الخاص بك. يمكنك إجراء مزيد من التحقيق في النموذج الخاص بك من خلال النظر في تحليل مقارن لأدائه عبر مجموعات أو مجموعات فرعية مختلفة من مجموعة البيانات الخاصة بك. قم بتحديد عوامل التصفية على طول قيمة y وقيمة x لتقطيع أبعاد مختلفة. اعرض قياسات مثل الدقة، الدقة، الاسترجاع، المعدل الإيجابي الخاطئ (FPR)، والمعدل السلبي الخاطئ (FNR).

مستكشف مجموعة البيانات
استكشف إحصائيات مجموعة البيانات الخاصة بك عن طريق تحديد عوامل تصفية مختلفة على طول المحاور X وY وcolor لتقسيم بياناتك على أبعاد مختلفة. قم بإنشاء مجموعات نموذجية لمجموعة البيانات أعلاه لتحليل إحصائيات مجموعة البيانات باستخدام عوامل التصفية مثل النتيجة المتوقعة وميزات مجموعة البيانات ومجموعات الأخطاء. استخدم رمز الترس في الزاوية العلوية اليسرى من الرسم البياني لتغيير أنواع الرسم البياني.

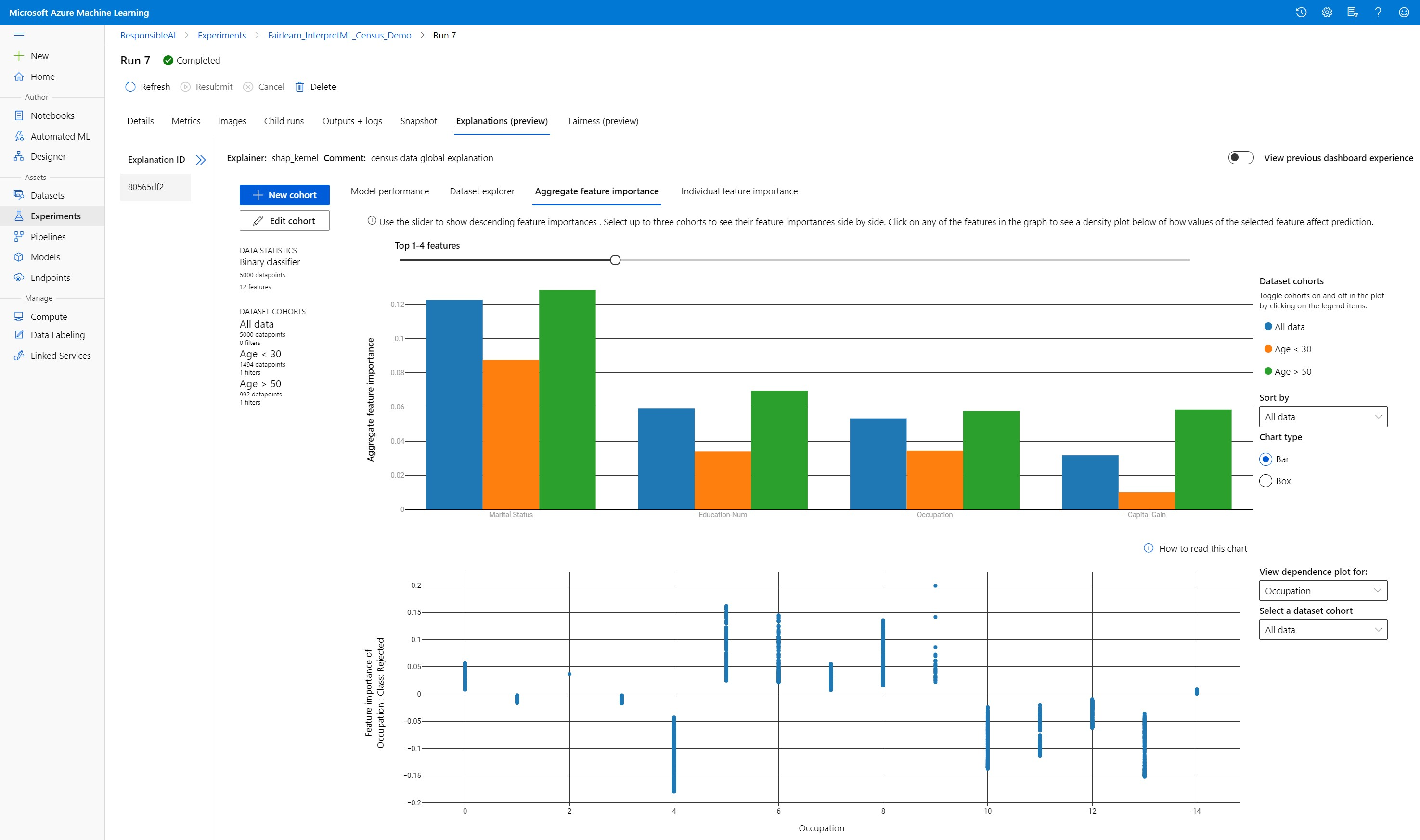
إجمالي أهمية الميزة
استكشف ميزات top-k المهمة التي تؤثر على تنبؤات النموذج الإجمالية (المعروفة أيضاً باسم التفسير العمومي). استخدم شريط التمرير لإظهار قيم أهمية الميزة التنازلية. حدد ما يصل إلى ثلاث مجموعات نموذجية لرؤية قيم أهمية الميزة الخاصة بهم جنباً إلى جنب. حدد أياً من أشرطة المعالم في الرسم البياني لترى كيف تؤثر قيم الميزة المحددة على توقع نموذج التأثير في مخطط التبعية أدناه.

فهم التنبؤات الفردية (تفسير محلي)
تتيح لك علامة التبويب الرابعة من علامة تبويب التفسير التنقل في نقطة بيانات فردية ومواردها المميزة الفردية. يمكنك تحميل مخطط أهمية الميزة الفردية لأي نقطة بيانات بالنقر فوق أي من نقاط البيانات الفردية في مخطط التبعثر الرئيسي أو تحديد نقطة بيانات معينة في معالج اللوحة على اليمين.
| الارض | الوصف |
|---|---|
| أهمية الميزة الفردية | يُظهر ميزات top-k المهمة للتنبؤ الفردي. يساعد في توضيح السلوك المحلي للنموذج الأساسي في نقطة بيانات محددة. |
| تحليل التخمين | يسمح بالتغييرات على قيم الميزات لنقطة البيانات الحقيقية المحددة ومراقبة التغييرات الناتجة على قيمة التنبؤ من خلال إنشاء نقطة بيانات افتراضية مع قيم الميزة الجديدة. |
| التوقع الشرطي الفردي (ICE) | يسمح بتغيير قيمة الميزة من قيمة دنيا إلى قيمة قصوى. يساعد في توضيح كيفية تغير تنبؤ نقطة البيانات عندما تتغير الميزة. |

إشعار
هذه تفسيرات تستند إلى العديد من التقديرات وليست "سبب" التنبؤات. دون القوة الرياضية الصارمة للاستدلال السببي، لا ننصح المستخدمين باتخاذ قرارات واقعية بناءً على اضطرابات ميزات أداة What-If. هذه الأداة في المقام الأول لفهم النموذج الخاص بك وتصحيح الأخطاء.
التصور في أستوديو التعلم الآلي من Microsoft Azure
إذا أكملت خطوات القابلية للتفسير عن بُعد (تحميل التفسيرات التي تم إنشاؤها إلى Azure Machine Learning Run History)، يمكنك عرض المرئيات على لوحة معلومات التفسيرات في أستوديو التعلم الآلي من Microsoft Azure. لوحة المعلومات هذه هي نسخة أبسط من أداة لوحة المعلومات التي تم إنشاؤها داخل دفتر Jupyter الخاص بك. ماذا - إذا تم تعطيل إنشاء جيل البيانات ورسومات ICE نظراً لعدم وجود حوسبة نشطة في أستوديو التعلم الآلي من Microsoft Azure يمكنه إجراء عمليات حسابية في الوقت الحقيقي.
إذا كانت مجموعة البيانات والتفسيرات العامة والمحلية متوفرة، فإن البيانات تملأ كل علامات التبويب. ومع ذلك، إذا كان التفسير العمومي متاحاً فقط، فسيتم تعطيل علامة التبويب أهمية الميزة الفردية.
اتبع أحد هذه المسارات للوصول إلى لوحة معلومات التفسيرات في أستوديو التعلم الآلي من Microsoft Azure:
جزء التجارب (إصدار أولي)
- حدد Experiments في الجزء الأيمن لمشاهدة قائمة بالتجارب التي أجريتها على التعلم الآلي من Azure.
- حدد تجربة معينة لعرض جميع عمليات التشغيل في تلك التجربة.
- حدد تشغيلاً، ثم علامة التبويب Explanations إلى لوحة معلومات التفسير المرئي.
جزء النماذج
- إذا قمت بتسجيل نموذجك الأصلي باتباع الخطوات الواردة في توزيع النماذج باستخدام التعلم الآلي من Microsoft Azure، يمكنك تحديد Models في الجزء الأيمن لعرضها.
- حدد نموذجاً، ثم علامة التبويب Explanations لعرض لوحة المعلومات في التفسيرات.

التفسير في وقت الاستدلال
يمكنك توزيع الشرح مع النموذج الأصلي واستخدامه في وقت الاستدلال لتوفير قيم أهمية الميزة الفردية (التفسير المحلي) لأي نقطة بيانات جديدة. نحن نقدم أيضاً تفسيرات تسجيل درجات أخف وزناً لتحسين أداء القابلية للتفسير في وقت الاستدلال، وهو مدعوم حالياً فقط في التعلم الآلي من Microsoft Azure SDK. تشبه عملية توزيع شرح درجات أخف وزناً توزيع نموذج وتتضمن الخطوات التالية:
قم بإنشاء عنصر شرح. على سبيل المثال، يمكنك استخدام
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)أنشئ شرحاً للتسجيل باستخدام عنصر التفسير.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)تكوين وتسجيل صورة تستخدم نموذج شرح النقاط.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')كخطوة اختيارية، يمكنك استرداد شرح الدرجات من السحابة واختبار التفسيرات.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)وزع الصورة إلى هدف محسوب باتباع الخطوات التالية:
إذا لزم الأمر، فقم بتسجيل نموذج التنبؤ الأصلي الخاص بك عن طريق اتباع الخطوات الواردة في توزيع النماذج باستخدام التعلم الآلي من Microsoft Azure.
قم بإنشاء ملف تسجيل.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}حدد deployment configuration.
يعتمد هذا التكوين على متطلبات النموذج الخاص بك. يحدد المثال التالي التكوين الذي يستخدم نواة واحدة لوحدة المعالجة المركزية وواحدة GB من الذاكرة.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')قم بإنشاء ملف مع تبعيات البيئة.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())قم بإنشاء ملف dockerfile مخصص مع تثبيت g ++.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++وزع الصورة التي تم إنشاؤها.
تستغرق هذه العملية حوالي خمس دقائق.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
اختبار التوزيع.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)عملية تنظيف.
لحذف خدمة ويب تم توزيعها، استخدم
service.delete().
استكشاف الأخطاء وإصلاحها
البيانات المتفرقة غير مدعومة: تتقاطع/تبطئ لوحة معلومات شرح النموذج إلى حد كبير مع وجود عدد كبير من الميزات، لذلك لا ندعم حالياً تنسيق البيانات المتفرقة. بالإضافة إلى ذلك، ستظهر مشكلات الذاكرة العامة مع مجموعات البيانات الكبيرة وعدد كبير من الميزات.
مصفوفة ميزات التفسيرات المدعومة
| علامة تبويب الشرح المدعوم | الميزات الخام (كثيفة) | الميزات الأولية (قليلة) | الميزات الهندسية (كثيفة) | الميزات الهندسية (قليلة) |
|---|---|---|---|---|
| أداء النموذج | مدعوم (لا يتوقع) | مدعوم (لا يتوقع) | مدعوم | مدعوم |
| مستكشف مجموعة البيانات | مدعوم (لا يتوقع) | غير مدعومة. نظراً لعدم تحميل البيانات المتفرقة ولأن واجهة المستخدم تواجه مشكلات في عرض البيانات المتفرقة. | مدعوم | غير مدعومة. نظراً لعدم تحميل البيانات المتفرقة ولأن واجهة المستخدم تواجه مشكلات في عرض البيانات المتفرقة. |
| إجمالي أهمية الميزة | مدعوم | مدعوم | مدعوم | مدعوم |
| أهمية الميزة الفردية | مدعوم (لا يتوقع) | غير مدعومة. نظراً لعدم تحميل البيانات المتفرقة ولأن واجهة المستخدم تواجه مشكلات في عرض البيانات المتفرقة. | مدعوم | غير مدعومة. نظراً لعدم تحميل البيانات المتفرقة ولأن واجهة المستخدم تواجه مشكلات في عرض البيانات المتفرقة. |
نماذج التنبؤ غير مدعومة بتفسيرات النموذج: القابلية للتفسير، أفضل تفسير للنموذج، غير متاح لتجارب التنبؤ AutoML التي توصي بالخوارزميات التالية كأفضل نموذج: TCNForecaster، AutoArima، Prophet، ExponentialSmoothing، Average، Naive، المتوسط الموسمي والسذاجة الموسمية. تدعم نماذج التراجع الخاصة بالتنبؤ الآلي لـAutoML التفسيرات. ومع ذلك، في لوحة معلومات التفسير، لا يتم دعم علامة التبويب "أهمية الميزة الفردية" للتنبؤ بسبب التعقيد في البنية الأساسية لبرنامج ربط بيانات العمليات التجارية.
الشرح المحلي لفهرس البيانات: لا تدعم لوحة معلومات التفسير ربط قيم الأهمية المحلية بمعرف سجل من مجموعة بيانات التحقق من الصحة إذا كانت مجموعة البيانات هذه أكبر من 5000 نقطة بيانات حيث تختزل لوحة المعلومات عينات البيانات بشكل عشوائي. ومع ذلك، تعرض لوحة المعلومات قيماً لميزة مجموعة البيانات الأولية لكل نقطة بيانات يتم تمريرها إلى لوحة المعلومات ضمن علامة التبويب أهمية الميزة الفردية. يمكن للمستخدمين تعيين عمليات الاستيراد المحلية مرة أخرى إلى مجموعة البيانات الأصلية من خلال مطابقة قيم ميزة مجموعة البيانات الأولية. إذا كان حجم مجموعة بيانات التحقق من الصحة أقل من 5000 عينة، فستتوافق الميزة
indexفي Azure التعلم الآلي studio مع الفهرس في مجموعة بيانات التحقق من الصحة.مخططات What-if/ICE غير مدعومة في الأستوديو: مخططات What-If والتوقع الشرطي الفردي (ICE) غير مدعومة في التعلم الآلي من Microsoft Azure ضمن علامة تبويب التفسيرات نظراً لأن التفسير الذي تم تحميله يحتاج إلى حساب نشط لإعادة حساب تنبؤات واحتمالات الميزات المضطربة. يتم دعمه حالياً في دفاتر Jupyter عند تشغيله كعنصر واجهة المستخدم باستخدام SDK.
الخطوات التالية
تقنيات قابلية تفسير النموذج في Azure التعلم الآلي
تحقق من عينات دفاتر الملاحظات الخاصة بقابلية تفسير التعلم الآلي من Microsoft Azure