الوصول إلى البيانات في وظيفة
ينطبق على: ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
في هذه المقالة، سوف تتعرف على:
- كيفية قراءة البيانات من تخزين Azure في مهمة التعلم الآلي Azure.
- كيفية كتابة البيانات من مهمة Azure التعلم الآلي إلى Azure Storage.
- الفرق بين وضعي التحميل والتنزيل.
- كيفية استخدام هوية المستخدم والهوية المدارة للوصول إلى البيانات.
- إعدادات التحميل المتوفرة في وظيفة.
- إعدادات التحميل الأمثل للسيناريوهات الشائعة.
- كيفية الوصول إلى أصول بيانات V1.
المتطلبات الأساسية
اشتراك Azure. في حال لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانيّاً قبل البدء. جرّب الإصدار المجاني أو المدفوع من «التعلم الآلي» من Azure.
مساحة عمل التعلم الآلي من Microsoft Azure
التشغيل السريع
قبل استكشاف الخيارات التفصيلية المتاحة لك عند الوصول إلى البيانات، نصف أولا مقتطفات التعليمات البرمجية ذات الصلة للوصول إلى البيانات.
قراءة البيانات من تخزين Azure في مهمة التعلم الآلي Azure
في هذا المثال، يمكنك إرسال مهمة Azure التعلم الآلي التي تصل إلى البيانات من حساب تخزين كائن ثنائي كبير الحجم عام. ومع ذلك، يمكنك تكييف القصاصة البرمجية للوصول إلى بياناتك الخاصة في حساب Azure Storage خاص. تحديث المسار كما هو موضح هنا. يعالج Azure التعلم الآلي المصادقة بسلاسة على التخزين السحابي، مع مرور Microsoft Entra. عند إرسال وظيفة، يمكنك اختيار:
- هوية المستخدم: تمرير هوية Microsoft Entra للوصول إلى البيانات
- الهوية المدارة: استخدم الهوية المدارة لهدف الحساب للوصول إلى البيانات
- بلا: لا تحدد هوية للوصول إلى البيانات. استخدام بلا عند استخدام مخازن البيانات المستندة إلى بيانات الاعتماد (مفتاح/رمز SAS المميز) أو عند الوصول إلى البيانات العامة
تلميح
إذا كنت تستخدم مفاتيح أو رموز SAS المميزة للمصادقة، نقترح عليك إنشاء مخزن بيانات Azure التعلم الآلي، لأن وقت التشغيل سيتصل تلقائيا بالتخزين دون التعرض للمفتاح/الرمز المميز.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data. Supported paths include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# We set the path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
كتابة البيانات من مهمة Azure التعلم الآلي إلى Azure Storage
في هذا المثال، يمكنك إرسال مهمة Azure التعلم الآلي التي تكتب البيانات إلى Azure التعلم الآلي Datastore الافتراضي. يمكنك اختياريا تعيين name قيمة أصل البيانات لإنشاء أصل بيانات في الإخراج.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the input and output URI paths for the data. Supported paths include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment name (name can be set without setting version)
# name = "<name_of_data_asset>",
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
وقت تشغيل بيانات Azure التعلم الآلي
عند إرسال مهمة، يتحكم وقت تشغيل بيانات Azure التعلم الآلي في تحميل البيانات، من موقع التخزين إلى هدف الحساب. تم تحسين وقت تشغيل بيانات Azure التعلم الآلي للسرعة والكفاءة لمهام التعلم الآلي. وتشمل الفوائد الرئيسية ما يلي:
- أحمال البيانات المكتوبة بلغة Rust، وهي لغة معروفة بالسرعة العالية وكفاءة الذاكرة العالية. بالنسبة لتنزيلات البيانات المتزامنة، يتجنب Rust مشكلات Python Global Interpreter Lock (GIL)
- خفيف الوزن؛ ليس لدى Rust أي تبعيات على تقنيات أخرى - على سبيل المثال JVM. ونتيجة لذلك، يتم تثبيت وقت التشغيل بسرعة، ولا يستنزف موارد إضافية (وحدة المعالجة المركزية، الذاكرة) على هدف الحساب
- تحميل بيانات متعددة العمليات (متوازية)
- الإحضار المسبق للبيانات كمهمة خلفية على وحدة المعالجة المركزية (وحدات المعالجة المركزية)، لتمكين الاستخدام الأفضل لوحدة معالجة الرسومات (وحدات) GPU عند القيام بالتعلم العميق
- معالجة المصادقة السلسة للتخزين السحابي
- يوفر خيارات لتحميل البيانات (الدفق) أو تنزيل جميع البيانات. لمزيد من المعلومات، تفضل بزيارة قسمي جبل (دفق) وتنزيل.
- التكامل السلس مع fsspec - واجهة pythonic موحدة لأنظمة الملفات المحلية والنائية والمضمنة وتخزين البايت.
تلميح
نقترح عليك الاستفادة من وقت تشغيل بيانات Azure التعلم الآلي، بدلا من إنشاء إمكانية التحميل/التنزيل الخاصة بك في التعليمات البرمجية للتدريب (العميل). لقد لاحظنا قيود معدل نقل التخزين عندما تستخدم التعليمات البرمجية للعميل Python لتنزيل البيانات من التخزين، بسبب مشكلات تأمين المترجم العام (GIL ).
المسارات
عند توفير إدخال/إخراج بيانات إلى مهمة، يجب تحديد معلمة path تشير إلى موقع البيانات. يعرض هذا الجدول مواقع البيانات المختلفة التي يدعمها Azure التعلم الآلي، ويعرض path أيضا أمثلة المعلمات:
| الموقع | الأمثلة |
|---|---|
| مسار على الكمبيوتر المحلي | ./home/username/data/my_data |
| مسار على خادم http(s) عام | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| مسار على Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| مسار على Azure التعلم الآلي Datastore | azureml://datastores/<data_store_name>/paths/<path> |
| مسار إلى أصل بيانات | azureml:<my_data>:<version> |
الأوضاع
عند تشغيل وظيفة باستخدام مدخلات/مخرجات البيانات، يمكنك التحديد من خيارات الوضع هذه:
ro_mount: تحميل موقع التخزين، للقراءة فقط على هدف حساب القرص المحلي (SSD).rw_mount: تحميل موقع التخزين، كقراءة وكتابة على هدف حساب القرص المحلي (SSD).download: قم بتنزيل البيانات من موقع التخزين إلى هدف حساب القرص المحلي (SSD).upload: تحميل البيانات من هدف الحساب إلى موقع التخزين.eval_mount/eval_download:هذه الأوضاع فريدة من نوعها ل MLTable. في بعض السيناريوهات، يمكن أن ينتج عن MLTable ملفات قد تكون موجودة في حساب تخزين مختلف عن حساب التخزين الذي يستضيف ملف MLTable. أو، يمكن ل MLTable مجموعة فرعية أو تبديل البيانات الموجودة في مورد التخزين. تصبح طريقة عرض المجموعة الفرعية/التبديل العشوائي مرئية فقط إذا كان وقت تشغيل بيانات Azure التعلم الآلي يقيم بالفعل ملف MLTable. على سبيل المثال، يوضح هذا الرسم التخطيطي كيفية استخدام MLTable معeval_mountأوeval_downloadيمكنه التقاط صور من حاويتي تخزين مختلفتين، وملف تعليقات توضيحية موجود في حساب تخزين مختلف، ثم تحميل/تنزيل إلى نظام الملفات لهدف الحساب البعيد.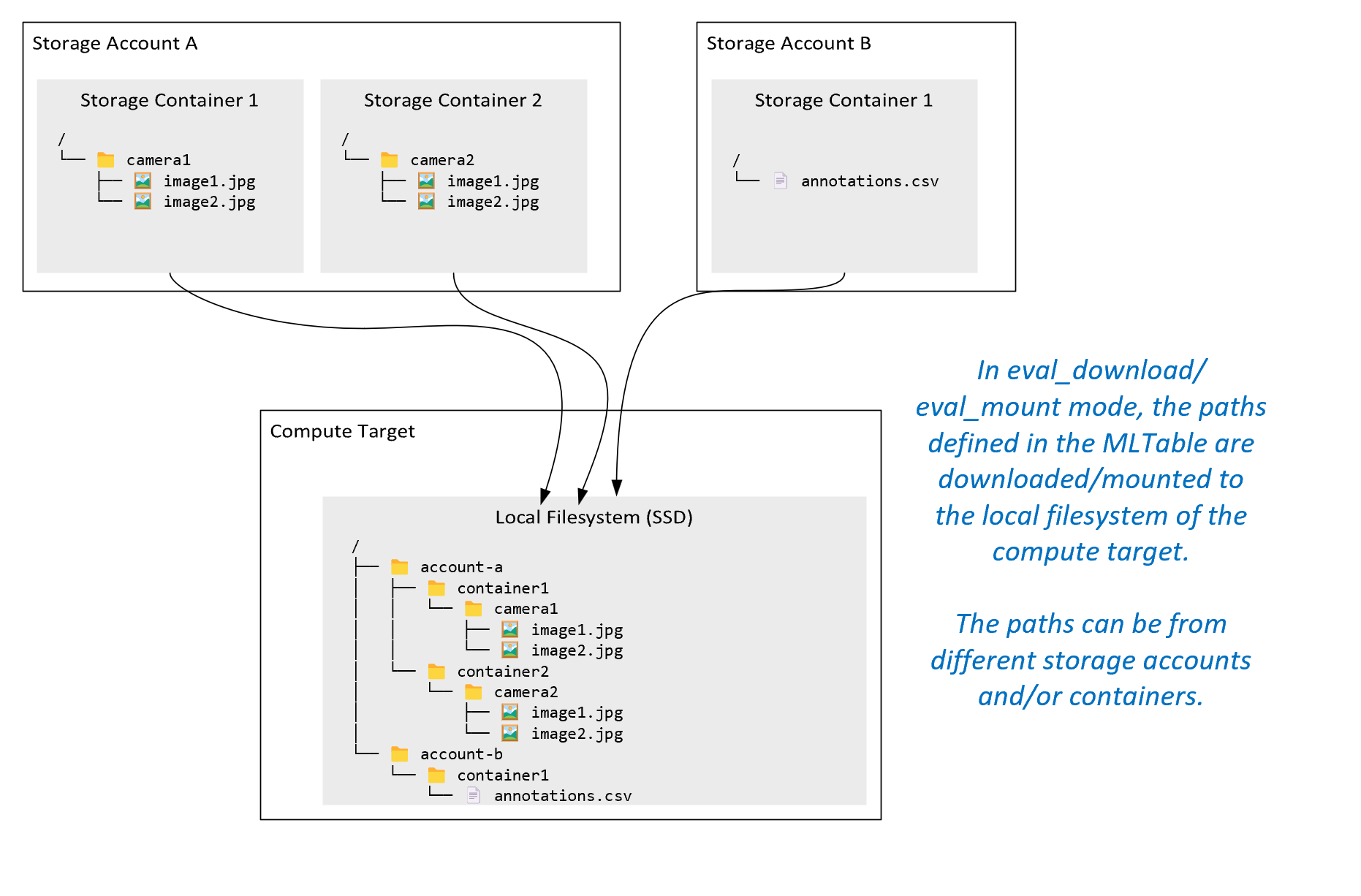
camera1يمكن بعد ذلك الوصول إلى المجلد والمجلدcamera2والملفannotations.csvعلى نظام ملفات هدف الحساب في بنية المجلد:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: قد ترغب في قراءة البيانات مباشرة من URI من خلال واجهات برمجة التطبيقات الأخرى، بدلا من الانتقال من خلال وقت تشغيل بيانات Azure التعلم الآلي. على سبيل المثال، قد تحتاج إلى الوصول إلى البيانات على مستودع s3 (مع عنوان URL مستضاف ظاهريا أو نمطhttpsالمسار) باستخدام عميل boto s3. يمكنك الحصول على URI للإدخل كسلسلة معdirectالوضع . ترى استخدام الوضع المباشر في Spark Jobs، لأن الأساليبspark.read_*()تعرف كيفية معالجة معرفات URI. بالنسبة للوظائف غير المتعلقة ب Spark ، تقع على عاتقك مسؤولية إدارة بيانات اعتماد الوصول. على سبيل المثال، يجب عليك الاستفادة بشكل صريح من حساب MSI، أو الوصول إلى الوسيط.

يوضح هذا الجدول الأوضاع المحتملة لمختلف مجموعات النوع/الوضع/الإدخال/الإخراج:
| نوع | إدخال/إخراج | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
الإدخال | √ | √ | √ | ||||
uri_file |
الإدخال | √ | √ | √ | ||||
mltable |
الإدخال | √ | √ | √ | √ | √ | ||
uri_folder |
الإخراج | √ | √ | |||||
uri_file |
الإخراج | √ | √ | |||||
mltable |
الإخراج | √ | √ | √ |
تنزيل
في وضع التنزيل، يتم نسخ جميع بيانات الإدخال إلى القرص المحلي (SSD) لهدف الحساب. يبدأ وقت تشغيل بيانات Azure التعلم الآلي البرنامج النصي لتدريب المستخدم، بمجرد نسخ جميع البيانات. عند بدء تشغيل البرنامج النصي للمستخدم، فإنه يقرأ البيانات من القرص المحلي، تماما مثل أي ملفات أخرى. عند انتهاء المهمة، تتم إزالة البيانات من قرص هدف الحساب.
| المزايا | أضرار |
|---|---|
| عند بدء التدريب، تتوفر جميع البيانات على القرص المحلي (SSD) لهدف الحساب، للبرنامج النصي للتدريب. لا يلزم وجود تفاعل تخزين / شبكة Azure. | يجب أن تتلاءم مجموعة البيانات تماما مع قرص هدف الحساب. |
| بعد بدء تشغيل البرنامج النصي للمستخدم، لا توجد تبعيات على موثوقية التخزين / الشبكة. | يتم تنزيل مجموعة البيانات بأكملها (إذا كان التدريب يحتاج إلى تحديد جزء صغير فقط من البيانات عشوائيا، فسيتم إهدار جزء كبير من التنزيل). |
| يمكن أن يتوازي وقت تشغيل بيانات Azure التعلم الآلي مع التنزيل (فرق كبير في العديد من الملفات الصغيرة) والحد الأقصى لمعدل نقل الشبكة / التخزين. | تنتظر المهمة حتى يتم تنزيل جميع البيانات إلى القرص المحلي لهدف الحساب. بالنسبة لوظيفة التعلم العميق المقدمة، فإن وحدات معالجة الرسومات الخامة حتى تصبح البيانات جاهزة. |
| لا يمكن تجنب الحمل الذي تمت إضافته بواسطة طبقة FUSE (roundtrip: استدعاء مساحة المستخدم في البرنامج النصي للمستخدم → kernel → البرنامج الخفي لدمج مساحة المستخدم → استجابة kernel → البرنامج النصي للمستخدم في مساحة المستخدم) | لا تنعكس تغييرات التخزين على البيانات بعد الانتهاء من التنزيل. |
متى تستخدم التنزيل
- البيانات صغيرة بما يكفي لاحتواءها على قرص هدف الحساب دون تداخل مع التدريب الآخر
- يستخدم التدريب معظم أو كل مجموعة البيانات
- يقرأ التدريب الملفات من مجموعة بيانات أكثر من مرة
- يجب أن ينتقل التدريب إلى مواقع عشوائية لملف كبير
- لا بأس من الانتظار حتى يتم تنزيل جميع البيانات قبل بدء التدريب
إعدادات التنزيل المتوفرة
يمكنك ضبط إعدادات التنزيل مع متغيرات البيئة هذه في وظيفتك:
| اسم متغير البيئة | نوع | القيمة الافتراضية | الوصف |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
عدد مؤشرات الترابط المتزامنة التي يمكن استخدامها |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | عدد محاولات إعادة المحاولة للتخزين / http الطلب الفردي للاسترداد من الأخطاء العابرة. |
في وظيفتك، يمكنك تغيير الإعدادات الافتراضية أعلاه عن طريق تعيين متغيرات البيئة - على سبيل المثال:
للإيجاز، نعرض فقط كيفية تحديد متغيرات البيئة في الوظيفة.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
تنزيل مقاييس الأداء
حجم الجهاز الظاهري لهدف الحساب الخاص بك له تأثير على وقت تنزيل بياناتك. على وجه التحديد:
- عدد الذاكرات الأساسية. كلما زاد عدد الذاكرات الأساسية المتوفرة، زاد التزامن، وبالتالي زادت سرعة التنزيل بشكل أسرع.
- النطاق الترددي المتوقع للشبكة. يحتوي كل جهاز ظاهري في Azure على الحد الأقصى لمعدل النقل من بطاقة واجهة الشبكة (NIC).
إشعار
بالنسبة للأجهزة الظاهرية ل A100 GPU، يمكن لوقت تشغيل بيانات Azure التعلم الآلي تشبع NIC (بطاقة واجهة الشبكة) عند تنزيل البيانات إلى هدف الحساب (~24 Gbit/s): الحد الأقصى النظرية لمعدل النقل الممكن.
يوضح هذا الجدول أداء التنزيل الذي يمكن لوقت تشغيل بيانات Azure التعلم الآلي التعامل معه لملف 100 غيغابايت على جهاز Standard_D15_v2 ظاهري (20cores، 25 Gbit/s Network throughput):
| بنية البيانات | التنزيل فقط (بالثواني) | تنزيل MD5 وحسابه (بالثواني) | معدل النقل الذي تم تحقيقه (Gbit/s) |
|---|---|---|---|
| ملفات 10 × 10 غيغابايت | 55.74 | 260.97 | 14.35 غيغابت/ثانية |
| ملفات 100 × 1 غيغابايت | 58.09 | 259.47 | 13.77 غيغابت/ثانية |
| ملف 1 × 100 غيغابايت | 96.13 | 300.61 | 8.32 غيغابت/ثانية |
يمكننا أن نرى أن ملفا أكبر، مقسما إلى ملفات أصغر، يمكن أن يحسن أداء التنزيل بسبب التوازي. نوصي بتجنب الملفات التي تصبح صغيرة جدا (أقل من 4 ميغابايت) لأن الوقت اللازم لإرسال طلبات التخزين يزيد، بالنسبة للوقت الذي يقضيه في تنزيل الحمولة. لمزيد من المعلومات، اقرأ العديد من مشاكل الملفات الصغيرة.
تحميل (دفق)
في وضع التحميل، تستخدم إمكانية بيانات Azure التعلم الآلي ميزة FUSE (نظام الملفات في مساحة المستخدم) Linux، لإنشاء نظام ملفات محاكى. بدلا من تنزيل جميع البيانات إلى القرص المحلي (SSD) لهدف الحساب، يمكن أن يتفاعل وقت التشغيل مع إجراءات البرنامج النصي للمستخدم في الوقت الفعلي. على سبيل المثال، "open file"، "read 2-كيلوبايت chunk from position X"، "list directory content".
| المزايا | أضرار |
|---|---|
| يمكن استخدام البيانات التي تتجاوز سعة القرص المحلي المستهدف للحساب (لا تقتصر على أجهزة الحوسبة) | حمل إضافي لوحدة LINUX FUSE. |
| لا تأخير في بداية التدريب (على عكس وضع التنزيل). | التبعية على سلوك التعليمات البرمجية للمستخدم (إذا كانت التعليمات البرمجية للتدريب التي تقرأ بشكل تسلسلي ملفات صغيرة في تحميل مؤشر ترابط واحد تطلب أيضا بيانات من التخزين، فقد لا تزيد من سرعة نقل الشبكة أو التخزين). |
| المزيد من الإعدادات المتوفرة لضبط سيناريو الاستخدام. | لا يوجد دعم للنوافذ. |
| تتم قراءة البيانات المطلوبة للتدريب فقط من التخزين. |
متى تستخدم Mount
- البيانات كبيرة، ولا تتناسب مع القرص المحلي المستهدف للحساب.
- لا تحتاج كل عقدة حساب فردية في نظام مجموعة إلى قراءة مجموعة البيانات بأكملها (ملف عشوائي أو صفوف في تحديد ملف csv، وما إلى ذلك).
- يمكن أن تصبح التأخيرات في انتظار تنزيل جميع البيانات قبل بدء التدريب مشكلة (وقت GPU الخامل).
إعدادات التحميل المتوفرة
يمكنك ضبط إعدادات التحميل مع متغيرات البيئة هذه في وظيفتك:
| اسم متغير Env | نوع | القيمة الافتراضية | الوصف |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | غير معين (ذاكرة التخزين المؤقت لا تنتهي صلاحيتها أبدا) | الوقت، بالمللي ثانية، مطلوب للحفاظ على getattr نتائج المكالمة في ذاكرة التخزين المؤقت، وتجنب الطلبات اللاحقة لهذه المعلومات من التخزين مرة أخرى. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 ميغابايت | مخصص لتكوين النظام، للحفاظ على سلامة الحوسبة. بغض النظر عن القيم التي تحتوي عليها الإعدادات الأخرى، لا يستخدم وقت تشغيل بيانات Azure التعلم الآلي البايت الأخير RESERVED_FREE_DISK_SPACE من مساحة القرص. |
DATASET_MOUNT_CACHE_SIZE |
usize | غير محدود | يتحكم في مقدار مساحة تحميل القرص التي يمكن استخدامها. تحدد القيمة الموجبة القيمة المطلقة بالبايت. تحدد القيمة السالبة مقدار مساحة القرص التي يجب تركها حرة. يوفر هذا الجدول المزيد من خيارات ذاكرة التخزين المؤقت للقرص. يدعم KB، MB و GB المعدلات للراحة. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | يبدأ تحميل وحدة التخزين في تشذيب ذاكرة التخزين المؤقت عند تعبئة ذاكرة التخزين المؤقت حتى AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. يجب أن يكون بين 0 و1. يؤدي تعيينه < 1 إلى تشغيل تشذيب ذاكرة التخزين المؤقت في الخلفية في وقت سابق. |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0.7 | يحاول تقليم ذاكرة التخزين المؤقت تحرير (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) مساحة ذاكرة التخزين المؤقت على الأقل. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 ميجا بايت | حجم كتلة القراءة المتدفقة. عندما يكون الملف كبيرا بما فيه الكفاية، اطلب على الأقل DATASET_MOUNT_READ_BLOCK_SIZE من البيانات من التخزين، وذاكرة التخزين المؤقت حتى عندما تكون عملية القراءة المطلوبة من الدمج أقل. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | عدد الكتل المراد الإحضار المسبق لها (تؤدي كتلة القراءة k إلى تشغيل الإحضار المسبق في الخلفية للكتل k+1، ...، k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
عدد مؤشرات الترابط المسبقة في الخلفية. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
منطقي | true | تمكين التخزين المؤقت المستند إلى الكتلة. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 ميغابايت | ينطبق على التخزين المؤقت المستند إلى الحظر فقط. يمكن استخدام حجم التخزين المؤقت المستند إلى كتلة ذاكرة الوصول العشوائي. القيمة 0 تعطل التخزين المؤقت للذاكرة تماما. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
منطقي | صحيح | ينطبق على التخزين المؤقت المستند إلى الحظر فقط. عند التعيين إلى صحيح، يستخدم التخزين المؤقت المستند إلى الكتلة محرك الأقراص الثابت المحلي لذاكرة التخزين المؤقت للكتل. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 ميغابايت | ينطبق على التخزين المؤقت المستند إلى الحظر فقط. يكتب التخزين المؤقت المستند إلى الكتلة كتلة مخزنة مؤقتا إلى قرص محلي في الخلفية. يتحكم هذا الإعداد في مقدار تحميل الذاكرة الذي يمكن استخدامه لتخزين الكتل في انتظار المسح إلى ذاكرة التخزين المؤقت للقرص المحلي. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
ينطبق على التخزين المؤقت المستند إلى الحظر فقط. عدد مؤشرات الترابط الخلفية التي تستخدم التخزين المؤقت المستند إلى الكتلة لكتابة الكتل التي تم تنزيلها إلى القرص المحلي لهدف الحساب. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | الوقت بالثوان لإنهاء unmount جميع العمليات المعلقة (على سبيل المثال، مسح المكالمات) قبل إنهاء حلقة رسالة التحميل بقوة. |
في وظيفتك، يمكنك تغيير الإعدادات الافتراضية أعلاه عن طريق تعيين متغيرات البيئة، على سبيل المثال:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
وضع الفتح المستند إلى الحظر
يقسم الوضع المفتوح المستند إلى الكتلة كل ملف إلى كتل بحجم محدد مسبقا (باستثناء الكتلة الأخيرة). طلب قراءة من موضع محدد يطلب كتلة مقابلة من التخزين، ويعيد البيانات المطلوبة على الفور. تؤدي القراءة أيضا إلى تشغيل الإحضار المسبق في الخلفية للكتل التالية N ، باستخدام مؤشرات ترابط متعددة (محسنة للقراءة التسلسلية). يتم تخزين الكتل التي تم تنزيلها مؤقتا في ذاكرة تخزين مؤقت لطبقتين (ذاكرة الوصول العشوائي والقرص المحلي).
| المزايا | أضرار |
|---|---|
| تسليم سريع للبيانات إلى البرنامج النصي للتدريب (أقل حظرا للتقسيمات التي لم يتم طلبها بعد). | قد تهدر القراءات العشوائية الكتل مسبقة التوجيه. |
| المزيد من عمليات تفريغ العمل إلى مؤشرات ترابط الخلفية (الإحضار المسبق / التخزين المؤقت). ويمكن بعد ذلك متابعة التدريب. | تمت إضافة حمل للتنقل بين ذاكرات التخزين المؤقت، مقارنة بالقراءة المباشرة من ملف على ذاكرة التخزين المؤقت للقرص المحلي (على سبيل المثال، في وضع ذاكرة التخزين المؤقت للملفات بالكامل). |
| تتم قراءة البيانات المطلوبة فقط (بالإضافة إلى الإحضار المسبق) من التخزين. | |
| بالنسبة للبيانات الصغيرة بما يكفي، يتم استخدام ذاكرة التخزين المؤقت السريعة المستندة إلى ذاكرة الوصول العشوائي. |
متى تستخدم وضع الفتح المستند إلى الكتلة
يوصى به لمعظم السيناريوهات إلا عندما تحتاج إلى قراءات سريعة من مواقع الملفات العشوائية. في هذه الحالات، استخدم وضع فتح ذاكرة التخزين المؤقت للملفات روبوت Who le.
روبوت Who وضع فتح ذاكرة التخزين المؤقت للملفات
عند فتح ملف ضمن مجلد تحميل (على سبيل المثال، f = open(path, args)) في وضع الملف بأكمله، يتم حظر الاستدعاء حتى يتم تنزيل الملف بأكمله في مجلد ذاكرة التخزين المؤقت الهدف للحساب على القرص. تتم إعادة توجيه جميع استدعاءات القراءة اللاحقة إلى الملف المخزن مؤقتا، لذلك لا يلزم وجود تفاعل تخزين. إذا لم تتوفر مساحة كافية لذاكرة التخزين المؤقت لاحتواء الملف الحالي، يحاول التحميل اقتطاعه عن طريق حذف الملف الأقل استخداما مؤخرا من ذاكرة التخزين المؤقت. في الحالات التي لا يمكن فيها احتواء الملف على القرص (فيما يتعلق بإعدادات ذاكرة التخزين المؤقت)، يعود وقت تشغيل البيانات إلى وضع الدفق.
| المزايا | أضرار |
|---|---|
| لا توجد موثوقية التخزين / تبعيات معدل النقل بعد فتح الملف. | يتم حظر المكالمة المفتوحة حتى يتم تنزيل الملف بأكمله. |
| قراءات عشوائية سريعة (قراءة أجزاء من أماكن عشوائية من الملف). | تتم قراءة الملف بأكمله من التخزين، حتى عندما لا تكون هناك حاجة إلى بعض أجزاء الملف. |
متى يتم استخدامها
عند الحاجة إلى قراءات عشوائية للملفات الكبيرة نسبيا التي تتجاوز 128 ميغابايت.
الاستخدام
تعيين متغير DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED البيئة إلى false في وظيفتك:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
تحميل: سرد الملفات
عند العمل مع ملايين الملفات، تجنب إدخال قائمة متكررة - على سبيل المثال ls -R /mnt/dataset/folder/. تؤدي القائمة المتكررة إلى تشغيل العديد من الاستدعاءات لسرد محتويات الدليل للدليل الأصل. ثم يتطلب استدعاء متكرر منفصل لكل دليل في الداخل، على جميع المستويات التابعة. عادة ما يسمح Azure Storage بإعادة 5000 عنصر فقط لكل طلب قائمة واحدة. ونتيجة لذلك، تتطلب 1,000,000 / 5000 + 1,000,000 = 1,000,200 القائمة المتكررة لمجلدات 1M التي تحتوي على 10 ملفات كل منها طلبات للتخزين. وبالمقارنة، سيحتاج 1000 مجلد يحتوي على 10000 ملف فقط إلى 1001 طلب للتخزين للحصول على قائمة متكررة.
يقوم Azure التعلم الآلي تحميل مقابض الإدراج بطريقة كسولة. لذلك، لسرد العديد من الملفات الصغيرة، من الأفضل استخدام استدعاء مكتبة عميل تكرارية (على سبيل المثال، os.scandir() في Python) بدلا من استدعاء مكتبة العميل الذي يقوم بإرجاع القائمة الكاملة (على سبيل المثال، os.listdir() في Python). تقوم مكالمة مكتبة العميل التكرارية بإرجاع منشئ، ما يعني أنه لا يحتاج إلى الانتظار حتى يتم تحميل القائمة بأكملها. ومن ثم يمكن أن تستمر بشكل أسرع.
يقارن هذا الجدول الوقت اللازم ل Python os.scandir() والوظائف os.listdir() لسرد مجلد يحتوي على ~4M ملفات في بنية مسطحة:
| Metric | os.scandir() |
os.listdir() |
|---|---|---|
| حان الوقت للحصول على الإدخال الأول (بالثواني) | 0.67 | 553.79 |
| حان الوقت للحصول على أول 50 ألف إدخال (ثوان) | 9.56 | 562.73 |
| حان الوقت للحصول على جميع الإدخالات (بالثواني) | 558.35 | 582.14 |
إعدادات التحميل الأمثل للسيناريوهات الشائعة
بالنسبة لبعض السيناريوهات الشائعة، نعرض إعدادات التحميل المثلى التي تحتاج إلى تعيينها في وظيفة Azure التعلم الآلي.
قراءة ملف كبير بشكل تسلسلي مرة واحدة (معالجة الأسطر في ملف csv)
قم بتضمين إعدادات التحميل هذه في environment_variables قسم وظيفة Azure التعلم الآلي:
إشعار
لاستخدام الحوسبة بلا خادم، احذف compute="cpu-cluster", في هذه التعليمة البرمجية.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
قراءة ملف كبير مرة واحدة من مؤشرات ترابط متعددة (معالجة ملف csv مقسم في مؤشرات ترابط متعددة)
قم بتضمين إعدادات التحميل هذه في environment_variables قسم وظيفة Azure التعلم الآلي:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
قراءة الملايين من الملفات الصغيرة (الصور) من مؤشرات ترابط متعددة مرة واحدة (تدريب فترة واحدة على الصور)
قم بتضمين إعدادات التحميل هذه في environment_variables قسم وظيفة Azure التعلم الآلي:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
قراءة ملايين الملفات الصغيرة (الصور) من مؤشرات ترابط متعددة عدة مرات (تدريب فترات متعددة على الصور)
قم بتضمين إعدادات التحميل هذه في environment_variables قسم وظيفة Azure التعلم الآلي:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
قراءة ملف كبير مع بحث عشوائي (مثل تقديم قاعدة بيانات الملفات من المجلد المثبت)
قم بتضمين إعدادات التحميل هذه في environment_variables قسم وظيفة Azure التعلم الآلي:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
تشخيص اختناقات تحميل البيانات وحلها
عند تنفيذ مهمة Azure التعلم الآلي مع البيانات، mode يحدد إدخال كيفية قراءة وحدات البايت من التخزين وتخزينها مؤقتا على قرص SSD المحلي الهدف للحساب. بالنسبة لوضع التنزيل، يتم تخزين جميع البيانات مؤقتا على القرص، قبل أن تبدأ التعليمات البرمجية للمستخدم في تنفيذها. لذلك، عوامل مثل
- عدد مؤشرات الترابط المتوازية
- عدد الملفات
- حجم الملف
لها تأثير على سرعات التنزيل القصوى. للتركيب، يجب أن تبدأ التعليمات البرمجية للمستخدم في فتح الملفات قبل أن تبدأ البيانات في ذاكرة التخزين المؤقت. تؤدي إعدادات التحميل المختلفة إلى سلوك مختلف في القراءة والتخزين المؤقت. العوامل المختلفة لها تأثير على السرعة التي يتم تحميل البيانات من التخزين:
- منطقة البيانات المراد حسابها: يجب أن تكون مواقع هدف التخزين والحوسبة هي نفسها. إذا كان هدف التخزين والحوسبة موجودا في مناطق مختلفة، يتدهور الأداء لأنه يجب نقل البيانات عبر المناطق. لمزيد من المعلومات حول كيفية التأكد من أن بياناتك تتعايش مع الحوسبة، تفضل بزيارة Colocate data with compute.
- حجم هدف الحساب: تحتوي الحسابات الصغيرة على عدد أساسي أقل (أقل توازيا) وعرض نطاق ترددي متوقع أصغر للشبكة مقارنة بأحجام الحوسبة الأكبر - يؤثر كلا العاملين على أداء تحميل البيانات.
- على سبيل المثال، إذا كنت تستخدم حجم جهاز ظاهري صغير، مثل
Standard_D2_v2(2 نواة، 1500 ميغابت في الثانية NIC)، وحاولت تحميل 50000 ميغابايت (50 غيغابايت) من البيانات، فإن أفضل وقت لتحميل البيانات يمكن تحقيقه سيكون ~270 ثانية (بافتراض تشبع NIC بمعدل نقل 187.5 ميغابايت/ثانية). في المقابل،Standard_D5_v2سيقوم (16 نواة، 12000 ميجابت في الثانية) بتحميل نفس البيانات في ~33 ثانية (على افتراض أنك تشبع بطاقة واجهة الشبكة بمعدل نقل 1500-MB/s).
- على سبيل المثال، إذا كنت تستخدم حجم جهاز ظاهري صغير، مثل
- طبقة التخزين: بالنسبة لمعظم السيناريوهات - بما في ذلك نماذج اللغات الكبيرة (LLM) - يوفر التخزين القياسي أفضل ملف تعريف للتكلفة/الأداء. ومع ذلك، إذا كان لديك العديد من الملفات الصغيرة، فإن التخزين المتميز يوفر ملف تعريف أفضل للتكلفة/الأداء. لمزيد من المعلومات، اقرأ خيارات Azure Storage.
- تحميل التخزين: إذا كان حساب التخزين تحت حمولة عالية - على سبيل المثال، العديد من عقد GPU في نظام مجموعة تطلب البيانات - فإنك تخاطر بالضغط على سعة الخروج للتخزين. لمزيد من المعلومات، اقرأ تحميل التخزين. إذا كان لديك العديد من الملفات الصغيرة التي تحتاج إلى الوصول بالتوازي، فقد تصل إلى حدود الطلب للتخزين. اقرأ معلومات محدثة حول حدود كل من سعة الخروج وطلبات التخزين في أهداف المقياس لحسابات التخزين القياسية.
- نمط الوصول إلى البيانات في التعليمات البرمجية للمستخدم: عند استخدام وضع التحميل، يتم جلب البيانات استنادا إلى إجراءات الفتح/القراءة في التعليمات البرمجية الخاصة بك. على سبيل المثال، عند قراءة مقاطع عشوائية من ملف كبير، يمكن أن تؤدي إعدادات الإحضار المسبق للبيانات الافتراضية للتركيبات إلى تنزيلات الكتل التي لن تتم قراءتها. قد تحتاج إلى ضبط بعض الإعدادات للوصول إلى الحد الأقصى لمعدل النقل. لمزيد من المعلومات، اقرأ إعدادات التحميل الأمثل للسيناريوهات الشائعة.
استخدام السجلات لتشخيص المشكلات
للوصول إلى سجلات وقت تشغيل البيانات من وظيفتك:
- حدد علامة التبويب Outputs+Logs من صفحة المهمة.
- حدد المجلد system_logs متبوعا بمجلد data_capability.
- يجب أن تشاهد ملفي سجل:
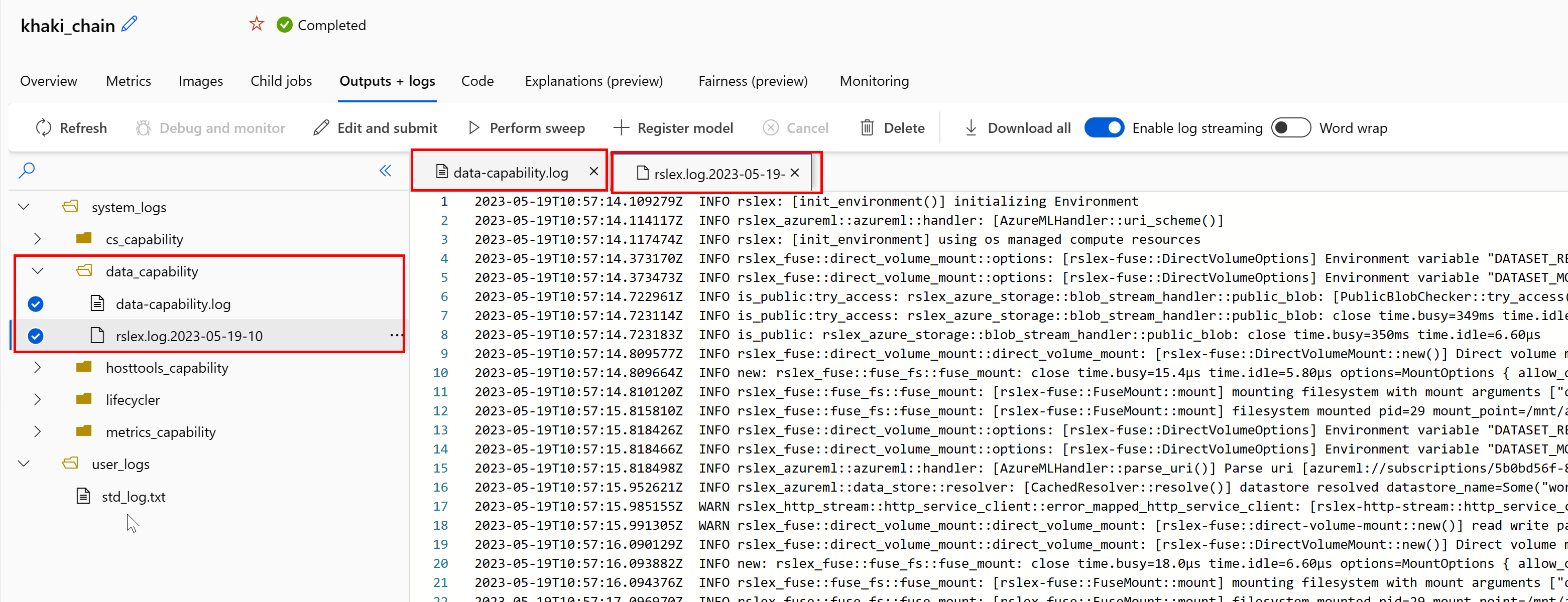

يعرض ملف السجل data-capability.log معلومات عالية المستوى حول الوقت المستغرق في مهام تحميل البيانات الرئيسية. على سبيل المثال، عند تنزيل البيانات، يسجل وقت التشغيل أوقات بدء نشاط التنزيل وانتهاءه:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
إذا كان معدل نقل التنزيل جزءا صغيرا من النطاق الترددي المتوقع للشبكة لحجم الجهاز الظاهري، يمكنك فحص ملف السجل rslex.log.<الطابع> الزمني. يحتوي هذا الملف على جميع عمليات التسجيل الدقيقة من وقت التشغيل المستند إلى Rust؛ على سبيل المثال، التوازي:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
يوفر ملف rslex.log تفاصيل حول جميع نسخ الملف، سواء اخترت أوضاع التحميل أو التنزيل أم لا. كما يصف الإعدادات (متغيرات البيئة) المستخدمة. لبدء تصحيح الأخطاء، تحقق مما إذا كنت تقوم بتعيين إعدادات التحميل الأمثل للسيناريوهات الشائعة.
مراقبة تخزين Azure
في مدخل Microsoft Azure، يمكنك تحديد حساب التخزين الخاص بك، ثم Metrics، لمشاهدة مقاييس التخزين:

ثم تقوم برسم SuccessE2ELatency مع SuccessServerLatency. إذا أظهرت المقاييس ارتفاع SuccessE2ELatency وانخفاض SuccessServerLatency، فلديك مؤشرات ترابط محدودة متوفرة، أو تشغيل موارد منخفضة مثل وحدة المعالجة المركزية أو الذاكرة أو النطاق الترددي للشبكة، يجب عليك:
- استخدم طريقة عرض المراقبة في Azure التعلم الآلي studio للتحقق من استخدام وحدة المعالجة المركزية والذاكرة لمهمتك. إذا كنت منخفضة في وحدة المعالجة المركزية والذاكرة، ففكر في زيادة حجم الجهاز الظاهري المستهدف للحوسبة.
- ضع في اعتبارك الزيادة
RSLEX_DOWNLOADER_THREADSإذا كنت تقوم بالتنزيل ولا تستخدم وحدة المعالجة المركزية والذاكرة. إذا كنت تستخدم التحميل، يجب زيادةDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTللقيام بالمزيد من الجلب المسبق، وزيادةDATASET_MOUNT_READ_THREADSلمزيد من مؤشرات ترابط القراءة.
إذا أظهرت المقاييس نجاحE2ELatency منخفضا وS successServerLatency منخفضا، ولكن العميل يواجه زمن انتقال عاليا، فلديك تأخير في طلب التخزين الذي يصل إلى الخدمة. يجب عليك التحقق من:
- ما إذا كان عدد مؤشرات الترابط المستخدمة للتحميل/التنزيل (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) معينا منخفضا جدا، بالنسبة إلى عدد الذاكرات الأساسية المتوفرة على هدف الحساب. إذا كان الإعداد منخفضا جدا، فقم بزيادة عدد مؤشرات الترابط. - ما إذا كان عدد مرات إعادة المحاولة للتنزيل (
AZUREML_DATASET_HTTP_RETRY_COUNT) معينا مرتفعا جدا. إذا كان الأمر كذلك، فقم بتقليص عدد مرات إعادة المحاولة.
مراقبة استخدام القرص أثناء مهمة
من استوديو Azure التعلم الآلي، يمكنك أيضا مراقبة الإدخال/الإخراج للقرص الهدف للحساب والاستخدام أثناء تنفيذ المهمة. انتقل إلى وظيفتك، وحدد علامة التبويب Monitoring . توفر علامة التبويب هذه رؤى حول موارد وظيفتك، على أساس متجدد لمدة 30 يوما. على سبيل المثال:

إشعار
تدعم مراقبة الوظيفة موارد الحوسبة التي يديرها Azure التعلم الآلي فقط. لن تحتوي الوظائف التي يقل وقت تشغيلها عن 5 دقائق على بيانات كافية لملء طريقة العرض هذه.
لا يستخدم وقت تشغيل بيانات Azure التعلم الآلي البايت الأخير RESERVED_FREE_DISK_SPACE من مساحة القرص، للحفاظ على سلامة الحساب (القيمة الافتراضية هي 150MB). إذا كان القرص ممتلئا، فإن التعليمات البرمجية تكتب الملفات إلى القرص دون الإعلان عن الملفات كإخراج. لذلك، تحقق من التعليمات البرمجية للتأكد من أن البيانات لا تتم كتابتها بشكل خاطئ إلى قرص مؤقت. إذا كان يجب كتابة الملفات إلى القرص المؤقت، وأصبح هذا المورد ممتلئا، ففكر في:
- زيادة حجم الجهاز الظاهري إلى واحد يحتوي على قرص مؤقت أكبر
- تعيين TTL على البيانات المخزنة مؤقتا (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL)، لإزالة البيانات من القرص
تجميع البيانات باستخدام الحوسبة
تنبيه
إذا كان التخزين والحساب في مناطق مختلفة، يتدهور أداؤك لأنه يجب نقل البيانات عبر المناطق. وهذا يزيد من التكاليف. تأكد من أن حساب التخزين وموارد الحوسبة في نفس المنطقة.
إذا تم تخزين بياناتك وAzure التعلم الآلي Workspace في مناطق مختلفة، نوصي بنسخ البيانات إلى حساب تخزين في نفس المنطقة باستخدام الأداة المساعدة azcopy. يستخدم AzCopy واجهات برمجة التطبيقات من خادم إلى خادم، بحيث تنسخ البيانات مباشرة بين خوادم التخزين. لا تستخدم عمليات النسخ هذه النطاق الترددي للشبكة لجهاز الكمبيوتر الخاص بك. يمكنك زيادة معدل نقل هذه العمليات مع AZCOPY_CONCURRENCY_VALUE متغير البيئة. لمعرفة المزيد، راجع زيادة التزامن.
تحميل التخزين
يمكن أن يصبح حساب تخزين واحد مقيدا عندما يأتي تحت حمولة عالية، عندما:
- تستخدم وظيفتك العديد من عقد GPU
- يحتوي حساب التخزين الخاص بك على العديد من المستخدمين/التطبيقات المتزامنة التي تصل إلى البيانات أثناء تشغيل وظيفتك
يوضح هذا القسم العمليات الحسابية لتحديد ما إذا كان التقييد قد يصبح مشكلة لحمل العمل الخاص بك، وكيفية التعامل مع تخفيضات التقييد.
حساب حدود النطاق الترددي
يحتوي حساب Azure Storage على حد خروج افتراضي يبلغ 120 جيجابت/ثانية. تحتوي أجهزة Azure الظاهرية على نطاقات ترددية مختلفة للشبكة، والتي لها تأثير على العدد النظري لعقد الحوسبة اللازمة للضغط على الحد الأقصى لسعة الخروج الافتراضية للتخزين:
| الحجم | بطاقة GPU | vCPU | الذاكرة: جيبي | تخزين درجة الحرارة (SSD) جيبي | عدد بطاقات GPU | ذاكرة وحدة معالجة الرسومات: جيبي بايت | النطاق الترددي المتوقع للشبكة (Gbit/s) | الحد الأقصى الافتراضي للخروج لحساب التخزين (Gbit/s)* | عدد العقد التي تصل إلى سعة الخروج الافتراضية |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
تحتوي كل من وحدات SKU A100/V100 على حد أقصى لعرض النطاق الترددي للشبكة لكل عقدة من 24 Gbit/s. إذا كانت كل عقدة تقرأ البيانات من حساب واحد يمكنها القراءة بالقرب من الحد الأقصى النظري البالغ 24 جيجابت/ثانية، فستحدث سعة الخروج بخمس عقد. قد يبدأ استخدام ست عقد حسابية أو أكثر في تدهور معدل نقل البيانات عبر جميع العقد.
هام
إذا كان حمل العمل الخاص بك يحتاج إلى أكثر من 6 عقد من A100/V100، أو كنت تعتقد أنك ستتجاوز سعة الخروج الافتراضية للتخزين (120Gbit/s)، فاتصل بالدعم (عبر مدخل Azure) واطلب زيادة حد خروج التخزين.
التحجيم عبر حسابات تخزين متعددة
قد تتجاوز الحد الأقصى لسعة الخروج للتخزين، و/أو قد تصل إلى حدود معدل الطلب. إذا حدثت هذه المشكلات، نقترح عليك الاتصال بالدعم أولا، لزيادة هذه الحدود على حساب التخزين.
إذا لم تتمكن من زيادة الحد الأقصى لسعة الخروج أو حد معدل الطلب، يجب أن تفكر في نسخ البيانات عبر حسابات تخزين متعددة. انسخ البيانات إلى حسابات متعددة باستخدام Azure Data Factory أو Azure Storage Explorer أو azcopy، وقم بتحميل جميع الحسابات في مهمة التدريب الخاصة بك. يتم تنزيل البيانات التي يتم الوصول إليها على التحميل فقط. لذلك، يمكن للتعليمات البرمجية RANK للتدريب الخاص بك قراءة من متغير البيئة، لاختيار أي من الإدخالات المتعددة التي يتم تحميلها للقراءة منها. يمر تعريف وظيفتك في قائمة حسابات التخزين:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
يمكن بعد ذلك استخدام RANK تعليمة python البرمجية التدريبية للحصول على حساب التخزين الخاص بتلك العقدة:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
العديد من الملفات الصغيرة مشكلة
تتضمن قراءة الملفات من التخزين تقديم طلبات لكل ملف. يختلف عدد الطلبات لكل ملف، استنادا إلى أحجام الملفات وإعدادات البرنامج الذي يتعامل مع قراءة الملف.
عادة ما تتم قراءة الملفات في كتل من 1-4 ميغابايت في الحجم. تتم قراءة الملفات الأصغر من كتلة مع طلب واحد (GET file.jpg 0-4MB)، والملفات الأكبر من كتلة لها طلب واحد يتم إجراؤه لكل كتلة (GET file.jpg 0-4MB، GET file.jpg 4-8 ميغابايت). يوضح هذا الجدول أن الملفات الأصغر من كتلة 4 ميغابايت تؤدي إلى المزيد من طلبات التخزين مقارنة بالملفات الأكبر:
| # الملفات | حجم الملف | إجمالي حجم البيانات | حجم الكتلة | # طلبات التخزين |
|---|---|---|---|---|
| 2,000,000 | 500 كيلوبايت | 1 تيرابايت | 4 ميجابايت | 2,000,000 |
| 1,000 | 1 غيغابايت | 1 تيرابايت | 4 ميجابايت | 256000 |
بالنسبة للملفات الصغيرة، يتضمن الفاصل الزمني لزمن الانتقال في الغالب معالجة طلبات التخزين، بدلا من نقل البيانات. لذلك، نقدم هذه التوصيات لزيادة حجم الملف:
- بالنسبة للبيانات غير المنظمة (الصور والنص والفيديو وما إلى ذلك)، أرشفة الملفات الصغيرة (zip/tar) معا، لتخزينها كملف أكبر يمكن قراءته في مجموعات متعددة. يمكن فتح هذه الملفات المؤرشفة الأكبر في مورد الحساب، ويمكن ل PyTorch Archive DataPipes استخراج الملفات الأصغر.
- بالنسبة إلى البيانات المنظمة (CSV وparquet وما إلى ذلك)، افحص عملية ETL الخاصة بك، للتأكد من دمج الملفات لزيادة الحجم. يحتوي
repartition()Spark على أساليب وcoalesce()للمساعدة في زيادة أحجام الملفات.
إذا لم تتمكن من زيادة أحجام الملفات، فاستكشف خيارات Azure Storage.
خيارات Azure Storage
يوفر Azure Storage مستويين - قياسي ومميز:
| التخزين | السيناريو |
|---|---|
| Azure Blob - قياسي (HDD) | يتم تنظيم بياناتك في الكائنات الثنائية كبيرة الحجم - الصور والفيديو وما إلى ذلك. |
| Azure Blob - Premium (SSD) | معدلات المعاملات المرتفعة أو الكائنات الأصغر أو متطلبات زمن انتقال التخزين المنخفض باستمرار |
تلميح
بالنسبة إلى "العديد" من الملفات الصغيرة (كيلوبايت الحجم)، نوصي باستخدام premium (SSD) لأن تكلفة التخزين أقل من تكاليف تشغيل حساب GPU.
قراءة أصول بيانات V1
يشرح هذا القسم كيفية قراءة V1 FileDataset وكيانات TabularDataset البيانات في وظيفة V2.
قراءة FileDataset
في Input الكائن ، حدد ك typeAssetTypes.MLTABLE و mode ك InputOutputModes.EVAL_MOUNT:
إشعار
لاستخدام الحوسبة بلا خادم، احذف compute="cpu-cluster", في هذه التعليمة البرمجية.
لمزيد من المعلومات حول كائن MLClient وخيارات تهيئة كائن MLClient وكيفية الاتصال بمساحة عمل، تفضل بزيارة الاتصال إلى مساحة عمل.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
قراءة TabularDataset
في Input الكائن ، حدد ك typeAssetTypes.MLTABLE، و mode ك InputOutputModes.DIRECT:
إشعار
لاستخدام الحوسبة بلا خادم، احذف compute="cpu-cluster", في هذه التعليمة البرمجية.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint