إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
هام
توفر هذه المقالة معلومات حول استخدام Azure Machine Learning SDK v1. تم إهمال SDK v1 اعتبارا من 31 مارس 2025. سينتهي الدعم المقدم له في 30 يونيو 2026. يمكنك تثبيت واستخدام SDK v1 حتى ذلك التاريخ. ستستمر مهام سير العمل الحالية باستخدام SDK v1 في العمل بعد تاريخ انتهاء الدعم. ومع ذلك ، يمكن أن يتعرضوا لمخاطر أمنية أو تغييرات كسر في حالة حدوث تغييرات معمارية في المنتج.
نوصي بالانتقال إلى SDK v2 قبل 30 يونيو 2026. لمزيد من المعلومات حول SDK v2، راجع ما هو Azure Machine Learning CLI وPython SDK v2؟ومرجع SDK v2.
إذا كنت تتساءل عن خوارزمية التعلم الآلي التي يجب استخدامها، فإن الإجابة تعتمد في المقام الأول على جانبين من سيناريو علم البيانات:
ماذا تريد أن تفعل ببياناتك؟ على وجه التحديد، ما هو سؤال العمل الذي تريد الإجابة عليه من خلال التعلم من بياناتك السابقة؟
ما هي متطلبات سيناريو علم البيانات الخاص بك؟ ما هي الميزات والدقة ووقت التدريب والخطية والمعلمات التي يدعمها الحل الخاص بك؟
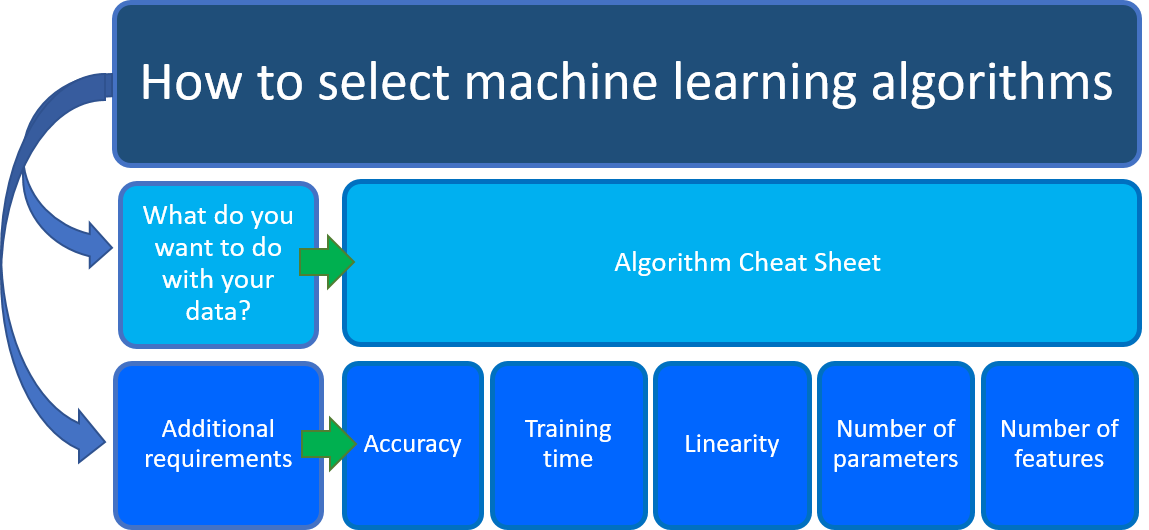
ملاحظة
يدعم مصمم التعلم الآلي من Azure نوعين من المكونات: المكونات الكلاسيكية التي تم إنشاؤها مسبقا (v1) والمكونات المخصصة (v2). هذان النوعان من المكونات غير متوافقين.
المكونات الكلاسيكية التي تم إنشاؤها مسبقا هي في المقام الأول لمعالجة البيانات ومهام التعلم الآلي التقليدية مثل الانحدار والتصنيف. يستمر دعم هذا النوع من المكونات لكنه لن يضاف إليه أي مكونات جديدة.
تسمح لك المكونات المخصصة بتضمين التعليمات البرمجية الخاصة بك كمكون. وهي تدعم مشاركة المكونات عبر مساحات العمل والتأليف السلس عبر واجهات Studio وCLI v2 وSDK v2.
للمشاريع الجديدة، نوصي بشدة باستخدام مكونات مخصصة متوافقة مع AzureML V2 وستتلقى تحديثات جديدة.
تنطبق هذه المقالة على المكونات الكلاسيكية التي تم إنشاؤها مسبقا وغير متوافقة مع CLI v2 وSDK v2.
ورقة المعلومات المرجعية لخوارزمية التعلم الآلي من Azure
تساعدك ورقة المعلومات المرجعية لخوارزمية التعلم الآلي من Azure في الاعتبار الأول: ما الذي تريد فعله ببياناتك؟ في ورقة المعلومات المرجعية، ابحث عن المهمة التي تريد القيام بها ثم ابحث عن خوارزمية مصمم التعلم الآلي من Azure لحل التحليلات التنبؤية.
ملاحظة
يمكنك تنزيل ورقة المعلومات المرجعية لخوارزمية التعلم الآلي.
يقدم المصمم مجموعة شاملة من الخوارزميات، بما في ذلك:
- غابة القرار متعددة الفئات
- أنظمة التوصية
- انحدار الشبكة العصبية
- شبكة عصبية متعددة الفئات
- تجميع K-means
تم تصميم كل خوارزمية لمعالجة نوع مختلف من مشكلة التعلم الآلي. للحصول على قائمة كاملة مع توثيق حول كيفية عمل كل خوارزمية وكيفية ضبط المعاملات لتحسين الخوارزمية، راجع الخوارزمية ومرجع المكونات.
إلى جانب هذه الإرشادات، ضع في اعتبارك متطلبات أخرى عند اختيار خوارزمية تعلم الآلة. فيما يلي عوامل أخرى يجب أخذها في الاعتبار، مثل الدقة، وقت التدريب، الخطية، عدد المعلمات وعدد الميزات.
مقارنة خوارزميات التعلم الآلي
تقوم بعض الخوارزميات بافتراضات معينة حول بنية البيانات أو النتائج المرجوة. إذا وجدت النموذج الذي يناسب احتياجاتك، يمكن أن يعطي نتائج أكثر فائدة، أو توقعات أكثر دقة، أو أوقات تدريب أسرع.
يلخص الجدول التالي بعض أهم خصائص الخوارزميات من مجموعات التصنيف والانحدار والتجمع:
| خوارزمية | دقة | وقت التدريب | الخطي | البارامترات | تلاحظ |
|---|---|---|---|---|---|
| عائلة التصنيف | |||||
| الانحدار اللوجستي من فئتين | جيد | سريع | نعم | 4 | |
| غابة القرار من طبقتين | ممتاز | متوسط | لا | 5 | إظهار أوقات تسجيل أبطأ. ننصح بعدم العمل مع الفئة متعددة الفئات الواحدة ضد الجميع، بسبب أوقات التسجيل البطيئة الناتجة عن قفل الخيوط في تراكم توقعات الشجرة. |
| شجرة قرارات معززة من طبقتين | ممتاز | متوسط | لا | 6 | بصمة ذاكرة كبيرة |
| شبكة عصبية من فئتين | جيد | متوسط | لا | 8 | |
| متوسط perceptron من فئتين | جيد | متوسط | نعم | 4 | |
| جهاز متجه دعم من فئتين | جيد | سريع | نعم | 5 | جيد لمجموعات الميزات الكبيرة |
| الانحدار اللوجستي متعدد الطبقات | جيد | سريع | نعم | 4 | |
| غابة قرارات متعددة الطبقات | ممتاز | متوسط | لا | 5 | إظهار أوقات تسجيل أبطأ |
| شجرة قرارات متعددة الطبقات معززة | ممتاز | متوسط | لا | 6 | يميل إلى تحسين الدقة مع بعض المخاطر الصغيرة للتغطية الأقل |
| شبكة عصبية متعددة الفئات | جيد | متوسط | لا | 8 | |
| فئة متعددة واحدة مقابل الكل | - | - | - | - | راجع خصائص الأسلوب من فئتين المحدد |
| عائلة الانحدار | |||||
| الانحدار الخطي | جيد | سريع | نعم | 4 | |
| انحدار غابة القرار | ممتاز | متوسط | لا | 5 | |
| تراجع شجرة القرار المعزز | ممتاز | متوسط | لا | 6 | بصمة ذاكرة كبيرة |
| انحدار الشبكة العصبية | جيد | متوسط | لا | 8 | |
| مجموعة تكوين أنظمة المجموعات | |||||
| تكوين أنظمة المجموعات في K-means | ممتاز | متوسط | نعم | 8 | خوارزمية تجميع |
متطلبات سيناريو علم البيانات
بعد أن تعرف ما تريد فعله ببياناتك، عليك تحديد متطلبات أخرى لسيناريو علم البيانات الخاص بك.
حدد الخيارات وربما المفاضلات مع المتطلبات التالية:
- الدقة
- وقت التدريب
- الخطي
- عدد المعلمات
- عدد الميزات
الدقة
تقيس الدقة في التعلم الآلي فعالية النموذج كنسبة من النتائج الحقيقية إلى إجمالي الحالات. في المصمم، يحسب مكون Evaluate Model مجموعة من مقاييس التقييم القياسية للصناعة. يمكنك استخدام هذا المكون لقياس دقة النموذج المدرب.
الحصول على أدق إجابة ممكنة ليس ضروريا دائما. في بعض الأحيان يكون التقريب كافيا، اعتمادا على ما تريد استخدامه من أجله. إذا كان الأمر كذلك، فقد تتمكن من خفض وقت المعالجة بشكل كبير من خلال الالتزام بأساليب تقريبية أكثر. كما تميل الأساليب التقريبية بشكل طبيعي إلى تجنب الإفراط في الماحتواء.
هناك ثلاث طرق لاستخدام مكون Evaluate Model:
- قم بتوليد درجات على بيانات التدريب الخاصة بك لتقييم النموذج.
- إنشاء درجات على النموذج، ولكن مقارنة هذه الدرجات بالنتائج في مجموعة اختبار محجوزة.
- قارن الدرجات لنموذجين مختلفين ولكن مرتبطين، باستخدام نفس مجموعة البيانات.
للحصول على قائمة كاملة بالمقاييس والنهج التي يمكنك استخدامها لتقييم دقة نماذج التعلم الآلي، راجع تقييم مكون النموذج.
وقت التدريب
في التعلم الخاضع للإشراف، يعني التدريب استخدام البيانات التاريخية لإنشاء نموذج تعلم آلي يقلل من الأخطاء. يختلف عدد الدقائق أو الساعات اللازمة لتدريب نموذج بشكل كبير بين الخوارزميات. وغالبا ما يرتبط وقت التدريب ارتباطا وثيقا بالدقة؛ واحد عادة ما يصاحب الآخر.
بالإضافة إلى ذلك، تكون بعض الخوارزميات أكثر حساسية لعدد نقاط البيانات من غيرها. قد تختار خوارزمية معينة لأن لديك تقييدا زمنيا، خاصة عندما تكون مجموعة البيانات كبيرة.
في المصمم، عادة ما يكون إنشاء نموذج التعلم الآلي واستخدامه عملية مكونة من ثلاث خطوات:
تكوين نموذج، عن طريق اختيار نوع معين من الخوارزمية، ثم تعريف معلماته أو المعلمات الفائقة.
قم بتوفير مجموعة بيانات مسماة وتحتوي على بيانات متوافقة مع الخوارزمية. قم بتوصيل كل من البيانات والنموذج بمكون Train Model.
بعد اكتمال التدريب، استخدم النموذج المدرب مع أحد مكونات التسجيل لإجراء تنبؤات على البيانات الجديدة.
الخطي
تعني الخطية في الإحصائيات والتعلم الآلي أن هناك علاقة خطية بين متغير وثابت في مجموعة البيانات الخاصة بك. على سبيل المثال، تفترض خوارزميات التصنيف الخطي أن خطا مستقيما أو نظيره الأعلى الأبعاد يمكن أن يفصل الفئات.
تستخدم الكثير من خوارزميات التعلم الآلي الخطية. في مصمم التعلم الآلي من Azure، تتضمن ما يلي:
تفترض خوارزميات الانحدار الخطي أن اتجاهات البيانات تتبع خطا مستقيما. هذا الافتراض ليس سيئا لبعض المشاكل، ولكنه يقلل من الدقة بالنسبة للآخرين. على الرغم من عيوبها، فإن الخوارزميات الخطية شائعة كاستراتيجية أولى. وهي تميل إلى أن تكون بسيطة خوارزمية وسريعة للتدريب.
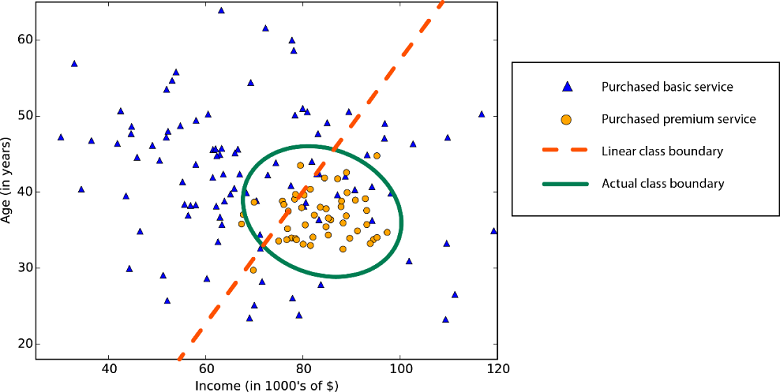
حد الفئة غير الخطية: سيؤدي الاعتماد على خوارزمية تصنيف خطية إلى دقة منخفضة.
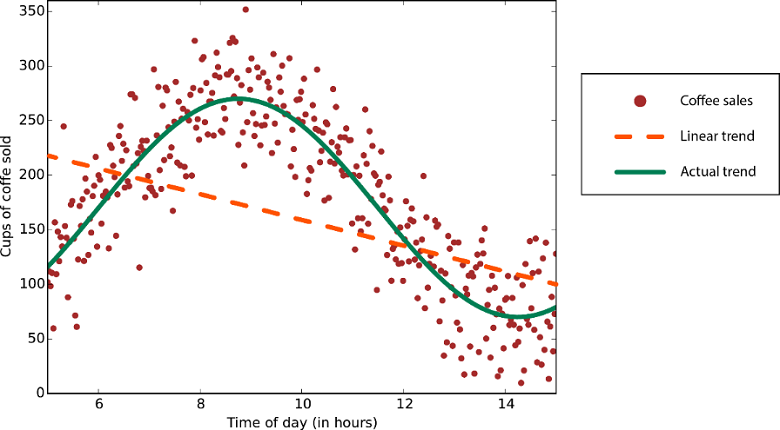
البيانات ذات الاتجاه غير الخطي: سيؤدي استخدام أسلوب انحدار خطي إلى حدوث أخطاء أكبر بكثير مما هو ضروري.
عدد المعلمات
المعلمات هي المقابض التي يحصل عالم البيانات على تسليمها عند إعداد خوارزمية. هي أرقام تؤثر على سلوك الخوارزمية. تشمل الأمثلة تحمل الأخطاء أو عدد التكرارات، والخيارات بين أشكال سلوك الخوارزمية.
وقت التدريب ودقة الخوارزمية يمكن أن يكونا حساسين للحصول على الإعدادات الصحيحة تماما. عادة ما تتطلب الخوارزميات التي تحتوي على أعداد كبيرة من المعلمات التجربة الأكبر والخطأ للعثور على مجموعة جيدة.
بدلا من ذلك، هناك مكون Tune Model Hyperparameters في المصمم. الهدف من هذا المكون هو تحديد المعلمات الفائقة المثلى لنموذج التعلم الآلي. ينشئ المكون نماذج متعددة ويختبرها باستخدام مجموعات مختلفة من الإعدادات. وهو يقارن المقاييس على جميع النماذج للحصول على مجموعات من الإعدادات.
بينما هذه الطريقة طريقة رائعة للتأكد من أنك تمتد لفضاء المعلمات، إلا أن الوقت المطلوب لتدريب النموذج يزداد بشكل أسي مع عدد المعلمات. الجانب الإيجابي هو أن وجود العديد من المعلمات يشير عادة إلى أن الخوارزمية لديها مرونة أكبر. يمكن أن يحقق في كثير من الأحيان دقة جيدة جدا، شريطة أن تتمكن من العثور على المجموعة الصحيحة من إعدادات المعلمة.
عدد الميزات
في التعلم الآلي، الميزة هي متغير قابل للقياس الكمي للظاهرة التي تحاول تحليلها. بالنسبة إلى أنواع معينة من البيانات، يمكن أن يكون عدد الميزات كبيرا جدا مقارنة بعدد نقاط البيانات. غالبا ما يكون هذا الوضع هو الحال مع علم الوراثة أو البيانات النصية.
يمكن أن يؤدي عدد كبير من الميزات إلى تصغير بعض خوارزميات التعلم، ما يجعل وقت التدريب طويلا بشكل غير مهني. أجهزة متجهات الدعم مناسبة تماما للسيناريوهات ذات عدد كبير من الميزات. لهذا السبب، تستخدم في العديد من التطبيقات من استرجاع المعلومات إلى تصنيف النصوص والصور. يمكن استخدام أجهزة المتجهات الداعمة لكل من مهام التصنيف والانحدار.
يشير تحديد الميزة إلى عملية تطبيق الاختبارات الإحصائية على المدخلات، نظرا لمخرجات محددة. الهدف هو تحديد الأعمدة الأكثر توقعا للإخراج. يوفر مكون Filter Based Feature Selection في المصمم خوارزميات تحديد ميزات متعددة للاختيار من بينها. يتضمن المكون أساليب الارتباط مثل ارتباط Pearson وقيم كاي تربيع.
يمكنك أيضا استخدام مكون Permutation Feature Importance لحساب مجموعة من درجات أهمية الميزة لمجموعة البيانات الخاصة بك. يمكنك بعد ذلك استخدام هذه الدرجات لمساعدتك في تحديد أفضل الميزات لاستخدامها في نموذج.