إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
تتيح لك نقاط النهاية الدفعية نشر النماذج التي تقوم بتشغيل الاستدلال على كميات كبيرة من البيانات. تعمل نقاط النهاية هذه على تبسيط نماذج الاستضافة لتسجيل الدفعات، بحيث يمكنك التركيز على التعلم الآلي بدلا من البنية الأساسية.
استخدم نقاط النهاية الدفعية لنشر النماذج عندما:
- أنت تستخدم نماذج باهظة الثمن تستغرق وقتا أطول لتشغيل الاستدلال.
- يمكنك إجراء الاستدلال على كميات كبيرة من البيانات الموزعة في ملفات متعددة.
- لا تحتاج إلى زمن انتقال منخفض.
- يمكنك الاستفادة من التوازي.
توضح هذه المقالة كيفية استخدام نقطة نهاية دفعية لنشر نموذج التعلم الآلي الذي يحل مشكلة التعرف على الأرقام الكلاسيكية MNIST (المعهد الوطني المعدل للمعايير والتكنولوجيا). يقوم النموذج المنشور بإجراء استنتاج مجمعي على كميات كبيرة من البيانات، مثل ملفات الصور. تبدأ العملية بإنشاء نشر دفعي لنموذج تم إنشاؤه باستخدام Torch. يصبح هذا التوزيع هو الافتراضي في نقطة النهاية. لاحقا ، قم بإنشاء نشر ثان لنموذج تم إنشاؤه باستخدام TensorFlow (Keras) ، واختبر النشر الثاني ، وقم بتعيينه كنشر افتراضي لنقطة النهاية.
المتطلبات الأساسية
قبل اتباع الخطوات الواردة في هذه المقالة، تأكد من أن لديك المتطلبات الأساسية التالية:
اشتراك Azure. إذا لم يكن لديك اشتراك Azure، فبادر بإنشاء حساب مجاني قبل البدء. جرّب الإصدار المجاني أو المدفوع من «التعلم الآلي» من Azure.
مساحة عمل للتعلم الآلي من Microsoft Azure. إذا لم يكن لديك واحدة، فاستخدم الخطوات الواردة في مقالة كيفية إدارة مساحات العمل لإنشاء مساحة عمل.
لتنفيذ المهام التالية، تأكد من أن لديك هذه الأذونات في مساحة العمل:
لإنشاء/إدارة نقاط النهاية والنشرات الدفعية: استخدم دور المالك أو دور المساهم أو دور مخصص يسمح .
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*لإنشاء عمليات نشر ARM في مجموعة موارد مساحة العمل: استخدم دور المالك أو دور المساهم أو دور مخصص يسمح
Microsoft.Resources/deployments/writeفي مجموعة الموارد حيث يتم نشر مساحة العمل.
تحتاج إلى تثبيت البرنامج التالي للعمل مع Azure التعلم الآلي:
ينطبق على:
ملحق التعلم الآلي من Azure CLI v2 (الحالي)Azure CLI وملحق
ml.az extension add -n ml
استنساخ مستودع الأمثلة
يستند المثال في هذه المقالة إلى نماذج التعليمات البرمجية الموجودة في مستودع أمثلة azureml. لتشغيل الأوامر محليا دون الحاجة إلى نسخ/لصق YAML والملفات الأخرى، قم أولا باستنساخ المستودع ثم تغيير الدلائل إلى المجلد:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
إعداد النظام الخاص بك
الاتصال بمساحة العمل الخاصة بك
أولا، اتصل بمساحة عمل التعلم الآلي من Microsoft Azure حيث تعمل.
إذا لم تكن قد قمت بالفعل بتعيين الإعدادات الافتراضية لـAzure CLI، فاحفظ الإعدادات الافتراضية. لتجنب إدخال قيم الاشتراك ومساحة العمل ومجموعة الموارد والموقع عدة مرات، قم بتشغيل هذا الرمز
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
إنشاء حساب
تعمل نقاط النهاية الدفعية على مجموعات الحوسبة وتدعم كل من مجموعات حساب Azure التعلم الآلي (AmlCompute) ومجموعات Kubernetes. المجموعات هي مورد مشترك، لذلك، يمكن لنظام مجموعة واحدة استضافة عملية نشر دفعة واحدة أو العديد من عمليات التوزيع (جنبا إلى جنب مع أحمال العمل الأخرى، إذا رغبت في ذلك).
إنشاء حساب باسم batch-cluster، كما هو موضح في التعليمات البرمجية التالية. اضبط حسب الحاجة وقم بالرجوع إلى حسابك باستخدام azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
ملاحظة
لا يتم تحصيل رسوم منك مقابل الحساب في هذه المرحلة لأن نظام المجموعة يظل عند 0 عقدة حتى يتم استدعاء نقطة نهاية دفعية وإرسال مهمة تسجيل الدفعات. لمزيد من المعلومات حول تكاليف الحوسبة، راجع إدارة التكلفة وتحسينها ل AmlCompute.
إنشاء نقطة نهاية دفعية
نقطة نهاية الدفعة هي نقطة نهاية HTTPS يستدعيها العملاء لتشغيل مهمة تسجيل الدفعات تسجل وظيفة تسجيل الدفعات مدخلات متعددة. التوزيع الدفعي هو مجموعة من موارد الحوسبة التي تستضيف النموذج الذي يقوم بتسجيل نقاط الدفعات (أو الاستدلال الدفعي). يمكن أن تحتوي نقطة نهاية دفعية واحدة على عدة عمليات توزيع للدفعة. لمزيد من المعلومات حول نقاط النهاية الدفعية، راجع ما هي نقاط النهاية الدفعية؟.
تلميح
تعمل إحدى عمليات توزيع الدفعات كنشر افتراضي لنقطة النهاية. عند استدعاء نقطة النهاية، يقوم التوزيع الافتراضي بتسجيل نقاط الدفعات. لمزيد من المعلومات حول نقاط النهاية الدفعية وعمليات النشر، راجع نقاط النهاية الدفعية ونشر الدفعات.
قم بتسمية نقطة النهاية. يجب أن يكون اسم نقطة النهاية فريدا داخل منطقة Azure لأن الاسم مضمن في عنوان URI لنقطة النهاية. على سبيل المثال، يمكن أن تكون هناك نقطة نهاية دفعة واحدة فقط بالاسم
mybatchendpointفيwestus2.تكوين نقطة نهاية الدفعة
يعرف ملف YAML التالي نقطة نهاية دفعية. استخدم هذا الملف مع الأمر CLI لإنشاء نقطة نهاية دفعية.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningيصف الجدول التالي الخصائص الرئيسية لنقطة النهاية. للحصول على مخطط YAML لنقطة نهاية الدفعة الكاملة، راجع مخطط YAML نقطة نهاية الدفعة CLI (v2).
المفتاح الوصف nameاسم نقطة نهاية دفعية. يجب أن يكون فريدًا على مستوى منطقة Azure. descriptionوصف نقطة نهاية الدفعة. هذه الخاصية اختيارية. tagsالعلامات المراد تضمينها في نقطة النهاية. هذه الخاصية اختيارية. إنشاء نقطة النهاية:
إنشاء توزيع دفعة
توزيع النموذج هو مجموعة من الموارد المطلوبة لاستضافة النموذج الذي يقوم بالاستدلال الفعلي. لإنشاء توزيع نموذج دفعي، تحتاج إلى العناصر التالية:
- نموذج مسجل في مساحة العمل
- التعليمات البرمجية لتسجيل النموذج
- بيئة مع تثبيت تبعيات النموذج
- إعدادات الحوسبة والموارد التي تم إنشاؤها مسبقا
ابدأ بتسجيل النموذج الذي سيتم نشره - نموذج Torch لمشكلة التعرف على الأرقام الشائعة (MNIST). يمكن لنشر الدفعات نشر النماذج المسجلة في مساحة العمل فقط. يمكنك تخطي هذه الخطوة إذا كان النموذج الذي تريد نشره مسجلا بالفعل.
تلميح
ترتبط النماذج بالنشر، بدلا من نقطة النهاية. هذا يعني أن نقطة نهاية واحدة يمكن أن تخدم نماذج مختلفة (أو إصدارات نموذج) ضمن نفس نقطة النهاية طالما يتم نشر النماذج المختلفة (أو إصدارات النموذج) في عمليات نشر مختلفة.
الآن حان الوقت لإنشاء برنامج نصي لتسجيل النقاط. تتطلب عمليات نشر الدفعات برنامجا نصيا لتسجيل النقاط يشير إلى كيفية تنفيذ نموذج معين وكيفية معالجة بيانات الإدخال. تدعم نقاط النهاية الدفعية البرامج النصية التي تم إنشاؤها في Python. في هذه الحالة، يمكنك نشر نموذج يقرأ ملفات الصور التي تمثل الأرقام ويخرج الرقم المقابل. البرنامج النصي لتسجيل النقاط كما يلي:
ملاحظة
بالنسبة لنماذج MLflow، يقوم Azure التعلم الآلي تلقائيا بإنشاء البرنامج النصي لتسجيل النقاط، لذلك لا يطلب منك توفير واحد. إذا كان النموذج الخاص بك هو نموذج MLflow، يمكنك تخطي هذه الخطوة. لمزيد من المعلومات حول كيفية عمل نقاط النهاية الدفعية مع نماذج MLflow، راجع المقالة استخدام نماذج MLflow في عمليات نشر الدفعات.
تحذير
إذا كنت تقوم بنشر نموذج التعلم الآلي التلقائي (AutoML) ضمن نقطة نهاية دفعية، فلاحظ أن البرنامج النصي للتسجيل الذي يوفره AutoML يعمل فقط مع نقاط النهاية عبر الإنترنت وليس مصمما لتنفيذ الدفعات. للحصول على معلومات حول كيفية إنشاء برنامج نصي لتسجيل النقاط لتوزيع الدفعة، راجع البرامج النصية لتسجيل نقاط المؤلف لتوزيع الدفعات.
توزيع الشعلة/التعليمات البرمجية/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)قم بإنشاء بيئة يتم فيها تشغيل التوزيع الدفعي. يجب أن تتضمن البيئة الحزم
azureml-coreوazureml-dataset-runtime[fuse]، والتي تتطلبها نقاط النهاية الدفعية، بالإضافة إلى أي تبعية تتطلبها التعليمات البرمجية الخاصة بك للتشغيل. في هذه الحالة، تم التقاط التبعيات فيconda.yamlملف:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]هام
الحزم
azureml-coreوazureml-dataset-runtime[fuse]مطلوبة من قبل عمليات توزيع الدفعات ويجب تضمينها في تبعيات البيئة.حدد البيئة كما يلي:
انتقل إلى علامة التبويب البيئات في القائمة الجانبية.
حددإنشاء> مخصصة.
أدخل اسم البيئة، في هذه الحالة
torch-batch-env.بالنسبة إلى Select environment source، حدد Use existing docker image with optional conda file.
بالنسبة لمسار صورة سجل الحاوية، أدخل
mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04.حدد التالي للانتقال إلى قسم "تخصيص".
انسخ محتوى ملف deployment-torch/environment/conda.yaml من مستودع GitHub إلى المدخل.
اختر التالي حتى تصل إلى "صفحة المراجعة".
حدد إنشاء وانتظر حتى تصبح البيئة جاهزة.
تحذير
البيئات المنسقة غير مدعومة في عمليات النشر المجمعة. تحتاج إلى تحديد البيئة الخاصة بك. يمكنك دائما استخدام الصورة الأساسية لبيئة منسقة كبيئة لك لتبسيط العملية.
إنشاء تعريف نشر
نشر الشعلة/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoيصف الجدول التالي الخصائص الرئيسية لتوزيع الدفعة. للحصول على مخطط YAML لتوزيع الدفعة الكاملة، راجع مخطط توزيع الدفعة CLI (v2) YAML.
المفتاح الوصف nameاسم النشر. endpoint_nameاسم نقطة النهاية لإنشاء التوزيع ضمن. modelالنموذج الذي ينبغي استخدامه لتسجيل الدفعات. يعرف المثال نموذجا مضمنا باستخدام path. يسمح هذا التعريف بتحميل ملفات النموذج وتسجيلها تلقائيا باسم وإصدار تم إنشاؤها تلقائيا. راجع مخطط النموذج لمزيد من الخيارات. يجب عليك إنشاء النموذج بشكل منفصل والإشارة إليه هنا، كأفضل ممارسة لسيناريوهات الإنتاج. للإشارة إلى نموذج موجود، استخدم البناءazureml:<model-name>:<model-version>.code_configuration.codeالدليل المحلي الذي يحتوي على جميع التعليمات البرمجية المصدر Python لتسجيل النموذج. code_configuration.scoring_scriptملف Python في code_configuration.codeالدليل. يجب أن يحتوي هذا الملف على دالةinit()ودالةrun(). استخدم الدالةinit()لأي إعداد مكلف أو شائع (على سبيل المثال، لتحميل النموذج في الذاكرة).init()يتم استدعاؤه مرة واحدة فقط في بداية العملية. استخدمrun(mini_batch)لتسجيل نقاط كل إدخال؛ قيمةmini_batchهي قائمة بمسارات الملفات. يجب أن ترجع الدالةrun()pandas DataFrame أو صفيف. يشير كل عنصر تم إرجاعه إلى تشغيل واحد ناجح لعنصر الإدخال فيmini_batch. لمزيد من المعلومات حول كيفية تأليف برنامج نصي لتسجيل النقاط، راجع فهم البرنامج النصي لتسجيل النقاط.environmentالبيئة لتسجيل النموذج. يحدد المثال بيئة مضمنة باستخدام conda_fileوimage. يتم تثبيت التبعياتconda_fileأعلىimageملف . يتم تسجيل البيئة تلقائيا باسم وإصدار تم إنشاؤهما تلقائيا. راجع مخطط البيئة لمزيد من الخيارات. ينبغي، كأفضل ممارسة لسيناريوهات الإنتاج، إنشاء البيئة بشكل منفصل والإشارة إليها هنا. للإشارة إلى بيئة موجودة، استخدم بناء الجملةazureml:<environment-name>:<environment-version>.computeالحساب لتشغيل تسجيل نقاط الدفعة. يستخدم المثال الذي batch-clusterتم إنشاؤه في البداية ويشير إليه باستخدام بناء الجملةazureml:<compute-name>.resources.instance_countعدد المثيلات التي ينبغي استخدامها لكل مهمة تسجيل دفعة. settings.max_concurrency_per_instanceالحد الأقصى لعدد مرات التشغيل المتوازية scoring_scriptلكل مثيل.settings.mini_batch_sizeعدد الملفات التي يمكن لـ scoring_scriptمعالجتها في مكالمة واحدةrun().settings.output_actionكيفية تنظيم الإخراج في ملف الإخراج. append_rowيدمج جميعrun()نتائج الإخراج التي تم إرجاعها في ملف واحد يسمىoutput_file_name.summary_onlyلن يدمج نتائج الإخراج وسيحسبerror_thresholdفقط .settings.output_file_nameاسم ملف إخراج تسجيل الدفعات ل append_rowoutput_action.settings.retry_settings.max_retriesعدد المحاولات القصوى لفشل scoring_scriptrun().settings.retry_settings.timeoutالمهلة بالثوان لتسجيل scoring_scriptrun()دفعة صغيرة.settings.error_thresholdعدد حالات فشل تسجيل ملف الإدخال التي يجب تجاهلها. إذا كان عدد الأخطاء للإدخل بأكمله يتجاوز هذه القيمة، يتم إنهاء مهمة تسجيل الدفعات. يستخدم المثال -1، الذي يشير إلى السماح بأي عدد من حالات الفشل دون إنهاء مهمة تسجيل الدفعات.settings.logging_levelإسهاب السجل. القيم في تزايد الإسهاب هي: WARNING و INFO و DEBUG. settings.environment_variablesقاموس أزواج اسم-قيمة متغير البيئة لتعيينها لكل مهمة تسجيل دفعة. انتقل إلى علامة التبويب نقاط النهاية في القائمة الجانبية.
حدد علامة التبويب نقاط النهاية الدفعية>إنشاء.
امنح نقطة النهاية اسما، في هذه الحالة
mnist-batch. يمكنك تكوين بقية الحقول أو تركها فارغة.حدد التالي للانتقال إلى قسم "Model".
حدد نموذج mnist-classifier-torch.
حدد التالي للانتقال إلى صفحة "النشر".
امنح النشر اسما.
بالنسبة لإجراء الإخراج، تأكد من تحديد صف الإلحاق .
بالنسبة إلى اسم ملف الإخراج، تأكد من أن ملف إخراج تسجيل الدفعات هو الملف الذي تحتاجه. الافتراضي هو
predictions.csv.بالنسبة لحجم الدفعة المصغر، اضبط حجم الملفات التي سيتم تضمينها في كل دفعة صغيرة. يتحكم هذا الحجم في كمية البيانات التي يتلقاها البرنامج النصي للتسجيل لكل دفعة.
بالنسبة لمهلة تسجيل النقاط (بالثوان)، تأكد من أنك تعطي وقتا كافيا للتوزيع لتسجيل دفعة معينة من الملفات. إذا قمت بزيادة عدد الملفات، يجب عليك عادة زيادة قيمة المهلة أيضا. قد تتطلب النماذج الأكثر تكلفة (مثل تلك القائمة على التعلم العميق) قيما عالية في هذا المجال.
بالنسبة إلى الحد الأقصى للتزامن لكل مثيل، قم بتكوين عدد المنفذين الذين تريد الحصول عليه لكل مثيل حساب تحصل عليه في النشر. يضمن العدد الأعلى هنا درجة أعلى من التوازي ولكنه يزيد أيضا من ضغط الذاكرة على مثيل الحساب. ضبط هذه القيمة تماما مع حجم الدفعة المصغرة.
بمجرد الانتهاء، حدد التالي للانتقال إلى صفحة "Code + environment".
بالنسبة إلى "تحديد برنامج نصي لتسجيل النقاط للاستدلال"، استعرض للعثور على ملف البرنامج النصي لتسجيل النقاط وتحديده deployment-torch/code/batch_driver.py.
في قسم "Select environment"، حدد البيئة التي أنشأتها مسبقا torch-batch-env.
حدد التالي للانتقال إلى صفحة "الحساب".
حدد مجموعة الحوسبة التي أنشأتها في خطوة سابقة.
تحذير
يتم دعم مجموعات Azure Kubernetes في عمليات التوزيع المجمعة، ولكن فقط عند إنشائها باستخدام واجهة سطر الأوامر (CLI) للتعلم الآلي من Microsoft Azure أو Python SDK.
بالنسبة إلى عدد المثيلات، أدخل عدد مثيلات الحوسبة التي تريدها للنشر. في هذه الحالة، استخدم 2.
حدد التالي.
إنشاء النشر:
قم بتشغيل التعليمات البرمجية التالية لإنشاء نشر دفعة ضمن نقطة نهاية الدفعة، وتعيينها كنشر افتراضي.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultتلميح
تعين المعلمة
--set-defaultالتوزيع الذي تم إنشاؤه حديثا كتوزيع افتراضي لنقطة النهاية. إنها طريقة ملائمة لإنشاء توزيع افتراضي جديد لنقطة النهاية، وإنشاء التوزيع الأول بشكل خاص. كأفضل ممارسة لسيناريوهات الإنتاج، قد تحتاج إلى إنشاء نشر جديد دون تعيينه كافتراضي. تحقق من أن النشر يعمل كما تتوقع، ثم قم بتحديث النشر الافتراضي لاحقا. لمزيد من المعلومات حول تنفيذ هذه العملية، راجع قسم نشر نموذج جديد.تحقق من نقطة نهاية الدفعة وتفاصيل النشر.
حدد علامة التبويب نقاط النهاية الدفعية .
حدد نقطة نهاية الدفعة التي تريد عرضها.
تعرض صفحة تفاصيل نقطة النهاية تفاصيل نقطة النهاية جنبا إلى جنب مع جميع عمليات النشر المتوفرة في نقطة النهاية.
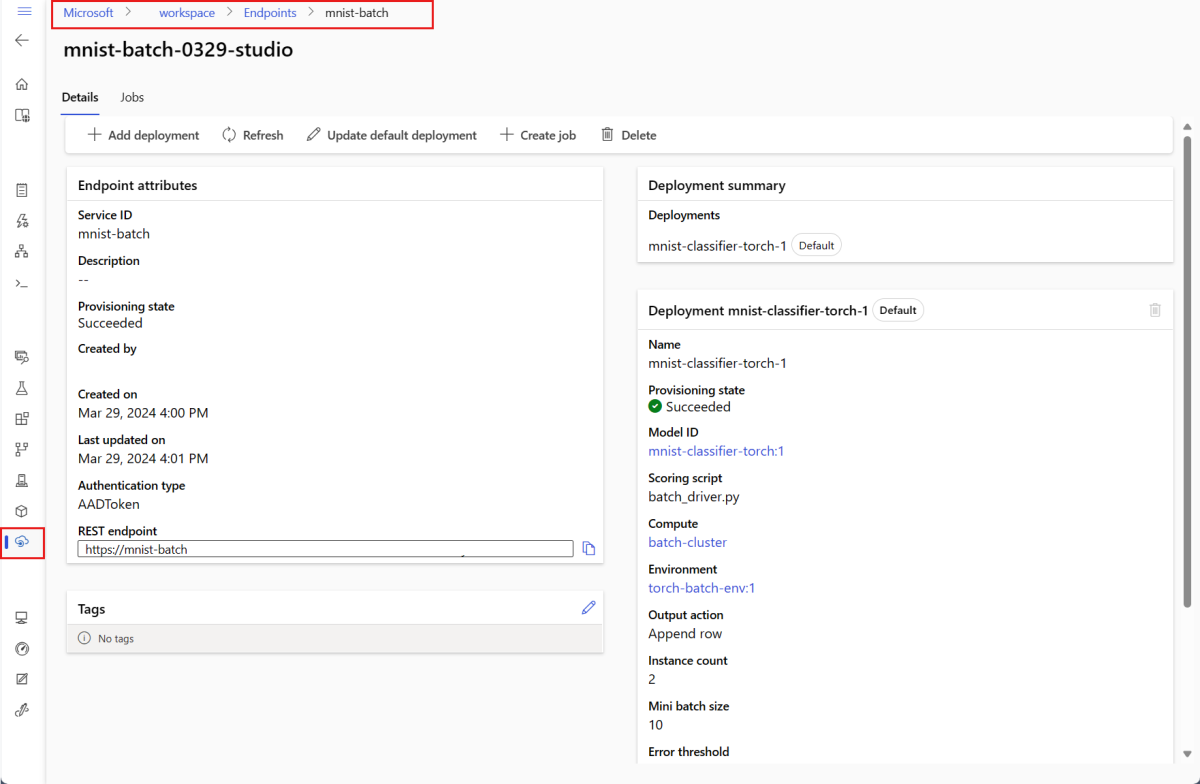

تشغيل نقاط النهاية الدفعية ونتائج الوصول
فهم تدفق البيانات
قبل تشغيل نقطة نهاية الدفعة، افهم كيفية تدفق البيانات عبر النظام:
المدخلات: البيانات المراد معالجتها (النتيجة). ويشمل ذلك ما يلي:
- الملفات المخزنة في Azure Storage (تخزين كائن ثنائي كبير الحجم، مستودع البيانات)
- المجلدات التي تحتوي على ملفات متعددة
- مجموعات البيانات المسجلة في التعلم الآلي من Microsoft Azure
المعالجة: يعالج النموذج المنشور بيانات الإدخال على دفعات (دفعات صغيرة) ويولد تنبؤات.
المخرجات: نتائج من النموذج، مخزنة كملفات في Azure Storage. بشكل افتراضي، يتم حفظ المخرجات في تخزين الكائن الثنائي كبير الحجم الافتراضي لمساحة العمل، ولكن يمكنك تحديد موقع مختلف.
استدعاء نقطة نهاية دفعية
استدعاء نقطة نهاية دُفعة لتشغيل مهمة تسجيل دُفعة يتم إرجاع الوظيفة name في استجابة الاستدعاء وتتتبع تقدم تسجيل الدفعات. حدد مسار بيانات الإدخال حتى تتمكن نقاط النهاية من تحديد موقع البيانات لتسجيل النقاط. يوضح المثال التالي كيفية بدء مهمة جديدة عبر عينة من بيانات مجموعة بيانات MNIST المخزنة في حساب تخزين Azure.
يمكنك تشغيل نقطة نهاية دفعية واستدعاءها باستخدام Azure CLI أو Azure التعلم الآلي SDK أو نقاط نهاية REST. لمزيد من المعلومات حول هذه الخيارات، راجع إنشاء الوظائف وبيانات الإدخال لنقاط نهاية الدفعات.
ملاحظة
كيف يعمل التوازي؟
توزع عمليات التوزيع المجمعة العمل على مستوى الملف. على سبيل المثال، يقوم المجلد الذي يحتوي على 100 ملف ودفعات مصغرة من 10 ملفات بإنشاء 10 دفعات من 10 ملفات لكل منها. يحدث هذا بغض النظر عن حجم الملف. إذا كانت الملفات كبيرة جدا بحيث لا يمكن معالجتها على دفعات صغيرة، فقم بتقسيمها إلى ملفات أصغر لزيادة التوازي أو تقليل عدد الملفات لكل دفعة صغيرة. لا تأخذ عمليات التوزيع الدفعية حاليا في الحسبان الانحرافات في توزيع حجم الملف.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $SAMPLE_INPUT_URI --input-type uri_folder --query name -o tsv)



تدعم نقاط النهاية الدفعية قراءة الملفات أو المجلدات الموجودة في مواقع مختلفة. لمعرفة المزيد حول الأنواع المدعومة وكيفية تحديدها، راجع الوصول إلى البيانات من مهام نقاط النهاية الدفعية.
مراقبة تقدم تنفيذ مهمة الدفعة
تستغرق مهام تسجيل الدفعات وقتا لمعالجة جميع المدخلات.
تتحقق التعليمات البرمجية التالية من حالة الوظيفة وتخرج ارتباطا إلى Azure التعلم الآلي studio لمزيد من التفاصيل.
az ml job show -n $JOB_NAME --web

فحص نتائج تسجيل الدُفعات
يتم تخزين مخرجات المهمة في التخزين السحابي، إما في تخزين الكائن الثنائي كبير الحجم الافتراضي لمساحة العمل، أو التخزين الذي حددته. لمعرفة كيفية تغيير الإعدادات الافتراضية، راجع تكوين موقع الإخراج. تسمح لك الخطوات التالية بعرض نتائج التسجيل في Azure Storage Explorer عند اكتمال المهمة:
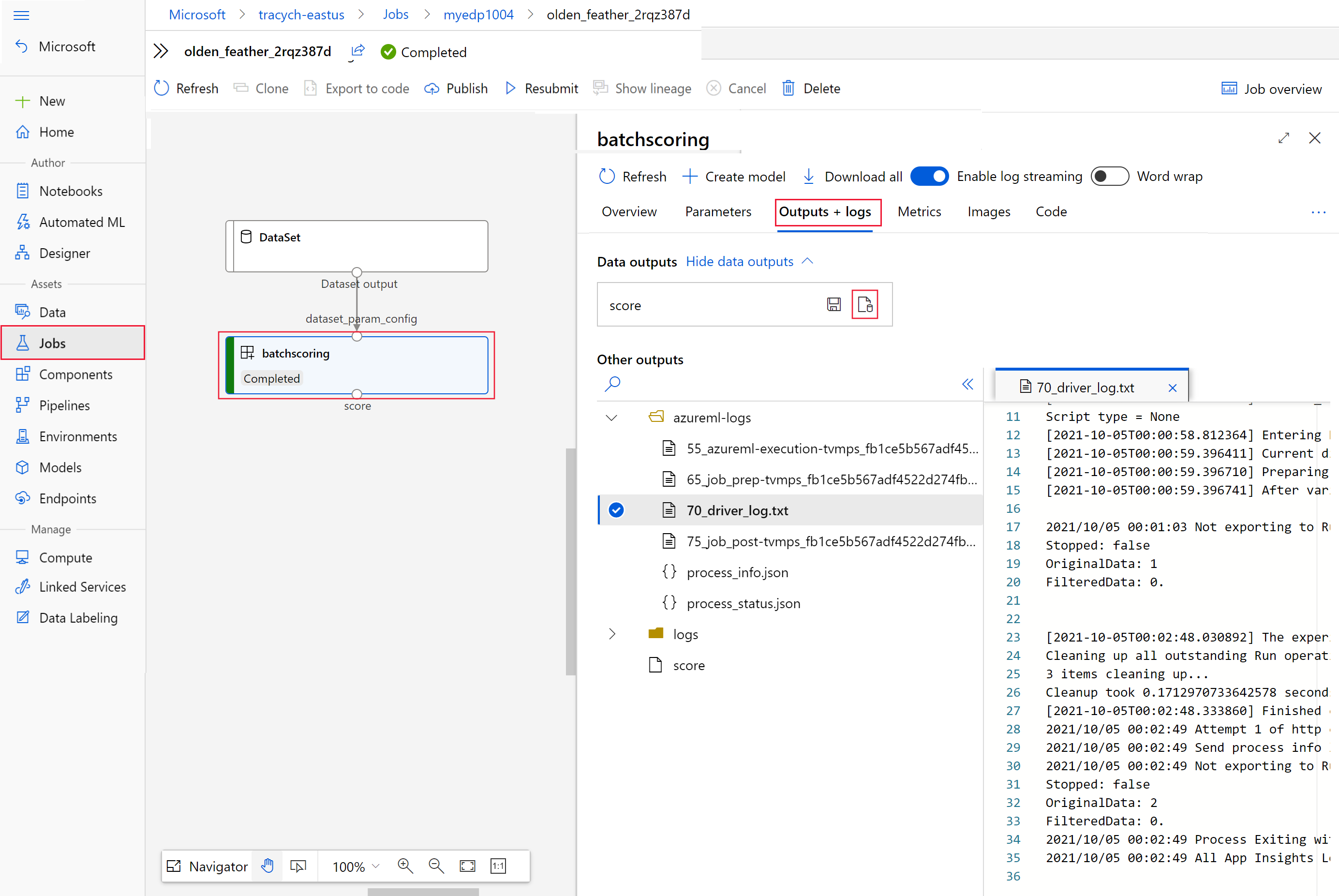
قم بتشغيل التعليمات البرمجية التالية لفتح مهمة تسجيل الدفعات في Azure التعلم الآلي studio. يتم تضمين ارتباط استوديو المهمة أيضا في استجابة
invoke، كقيمة لinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webفي الرسم البياني للوظيفة، حدد الخطوة
batchscoring.حدد علامة التبويب «Outputs + logs»، ثم حدد عرض مخرجات البيانات.
من مخرجات البيانات، حدد الأيقونة لفتح Storage Explorer.
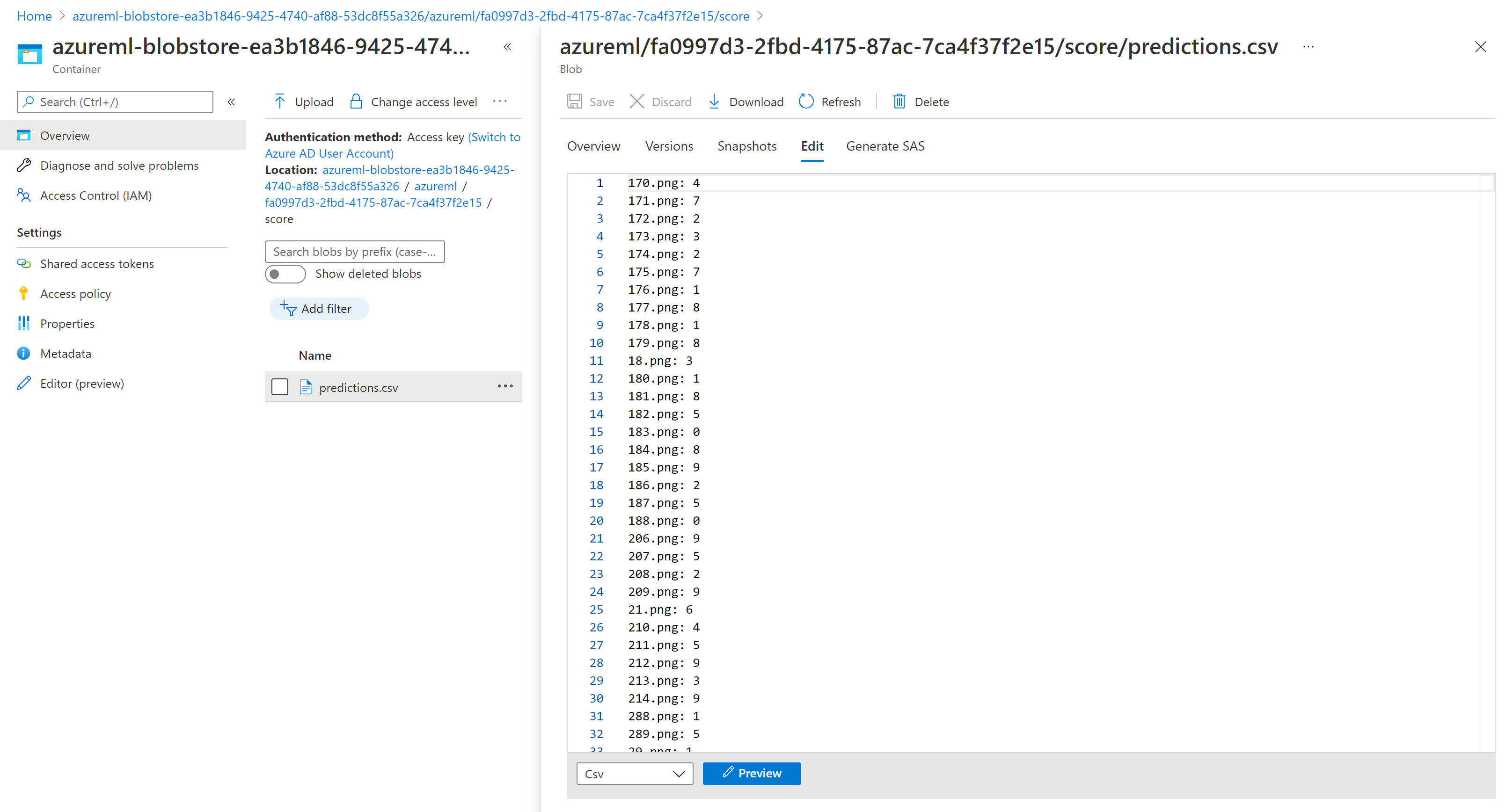
نتائج التسجيل في Storage Explorer مشابهة لصفحة العينة التالية:


تكوين موقع الإخراج
بشكل افتراضي، يتم تخزين نتائج تسجيل الدفعات في مخزن الكائن الثنائي كبير الحجم الافتراضي لمساحة العمل في مجلد يسمى باسم الوظيفة (GUID الذي تم إنشاؤه بواسطة النظام). قم بتكوين موقع الإخراج عند استدعاء نقطة نهاية الدفعة.
قم باستخدام output-path لتكوين أي مجلد في مخزن البيانات المسجل التعلم الآلي من Microsoft Azure. الصيغة الخاصة بـ --output-pathهو نفسه عند --input تحديد مجلداً أي azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. استخدم --set output_file_name=<your-file-name> لتكوين اسم ملف إخراج جديد.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $SAMPLE_INPUT_URI --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

تحذير
لابد من استخدام موقع إخراج فريد. في حالة وجود ملف الإخراج، تفشل مهمة تسجيل النقاط الدفعية.
هام
على عكس المدخلات، يمكن تخزين المخرجات فقط في Azure التعلم الآلي مخازن البيانات التي تعمل على حسابات تخزين الكائنات الثنائية كبيرة الحجم.
الكتابة فوق تكوين النشر لكل مهمة
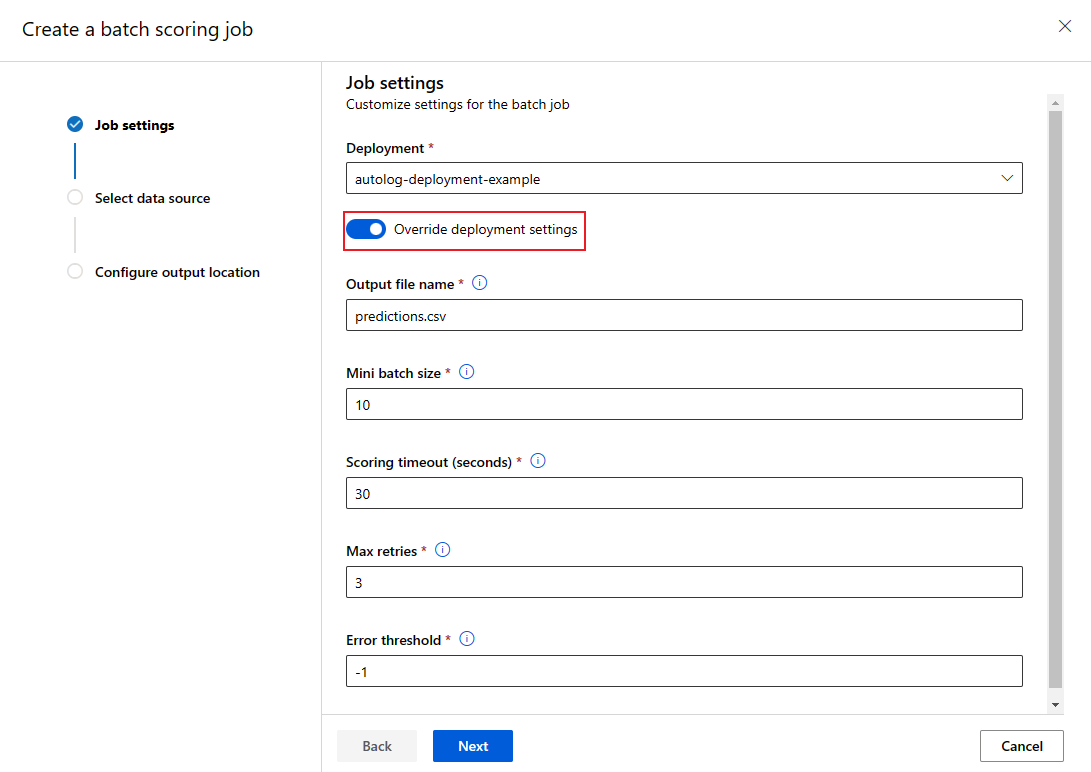
عند استدعاء نقطة نهاية دفعية، يمكنك الكتابة فوق بعض الإعدادات لتحقيق أقصى استفادة من موارد الحوسبة وتحسين الأداء. تكون هذه الميزة مفيدة عندما تحتاج إلى إعدادات مختلفة لمهام مختلفة دون تعديل النشر بشكل دائم.
ما هي الإعدادات التي يمكن تجاوزها؟
يمكنك تكوين الإعدادات التالية على أساس كل وظيفة:
| الإعداد | متى تستخدم | سيناريو مثال |
|---|---|---|
| عدد المثيلات | عندما يكون لديك أحجام بيانات متفاوتة | استخدم المزيد من المثيلات لمجموعات البيانات الأكبر (10 مثيلات ل 1 مليون ملف مقابل مثيلتين ل 100,000 ملف). |
| حجم الدفعة المصغرة | عندما تحتاج إلى تحقيق التوازن بين الإنتاجية واستخدام الذاكرة | استخدم دفعات أصغر (10-50 ملفا) للصور الكبيرة والدفعات الأكبر (100-500 ملف) للملفات النصية الصغيرة. |
| الحد الأقصى لإعادة المحاولة | عندما تختلف جودة البيانات | إعادة محاولة أعلى (5-10) للبيانات الصاخبة ؛ عمليات إعادة المحاولة الأقل (1-3) للبيانات النظيفة |
| مهله | متى يختلف وقت المعالجة حسب نوع البيانات | مهلة أطول (300 ثانية) للنماذج المعقدة ؛ مهلة أقصر (30 ثانية) للموديلات البسيطة |
| عتبة الخطأ | عندما تحتاج إلى مستويات مختلفة من التسامح مع الفشل | عتبة صارمة (-1) للوظائف الحرجة؛ عتبة متساهلة (10%) للوظائف التجريبية |
كيفية تجاوز الإعدادات
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
إضافة عمليات نشر إلى نقطة نهاية
بمجرد أن يكون لديك نقطة نهاية دفعية مع توزيع، يمكنك الاستمرار في تحسين النموذج الخاص بك وإضافة عمليات نشر جديدة. ستستمر نقاط النهاية الدفعية في خدمة النشر الافتراضي أثناء تطوير نماذج جديدة ونشرها تحت نفس نقطة النهاية. لا تؤثر عمليات التوزيع على بعضها البعض.
في هذا المثال، يمكنك إضافة نشر ثان يستخدم نموذجا تم إنشاؤه باستخدام Keras وTensorFlow لحل نفس مشكلة MNIST.
إضافة نشر ثان
قم بإنشاء بيئة لنشر الدفعات. قم بتضمين أي تبعيات تحتاج التعليمات البرمجية الخاصة بك لتشغيلها. أضف المكتبة
azureml-core، كما هو مطلوب لعمليات التوزيع الدفعية. يتضمن تعريف البيئة التالي المكتبات المطلوبة لتشغيل نموذج باستخدام TensorFlow.انسخ محتوى الملف deployment-keras/environment/conda.yaml من مستودع GitHub إلى المدخل.
حدد التالي حتى تصل إلى "صفحة المراجعة".
حدد Create وانتظر حتى تصبح البيئة جاهزة للاستخدام.
يبدو ملف conda المستخدم كما يلي:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]إنشاء برنامج نصي لتسجيل النقاط للنموذج:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)إنشاء تعريف نشر
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvحدد التالي للمتابعة إلى صفحة "التعليمات البرمجية + البيئة".
لتحديد برنامج نصي لتسجيل النقاط للاستدلال، استعرض لتحديد ملف تسجيل البرنامج النصي deployment-keras/code/batch_driver.py.
بالنسبة إلى تحديد البيئة، حدد البيئة التي أنشأتها في خطوة سابقة.
حدد التالي.
في صفحة Compute ، حدد مجموعة الحوسبة التي أنشأتها في خطوة سابقة.
بالنسبة إلى عدد المثيلات، أدخل عدد مثيلات الحوسبة التي تريدها للنشر. في هذه الحالة، استخدم 2.
حدد التالي.
إنشاء النشر:
قم بتشغيل التعليمات البرمجية التالية لإنشاء نشر دفعة ضمن نقطة نهاية الدفعة وتعيينها كنشر افتراضي.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMEتلميح
المعلمة
--set-defaultمفقودة في هذه الحالة. كأفضل ممارسة لسيناريوهات الإنتاج، قم بإنشاء نشر جديد دون تعيينه كافتراضي. ثم تحقق من ذلك، وقم بتحديث النشر الافتراضي لاحقا.
اختبر توزيع دفعة غير افتراضي
لاختبار التوزيع الجديد غير الافتراضي، تحتاج إلى معرفة اسم النشر الذي تريد تشغيله.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input $SAMPLE_INPUT_URI --input-type uri_folder --query name -o tsv)
يتم استخدام الإشعار --deployment-name لتحديد النشر المراد تنفيذه. تسمح لك invoke هذه المعلمة بنشر غير افتراضي دون تحديث النشر الافتراضي لنقطة نهاية الدفعة.
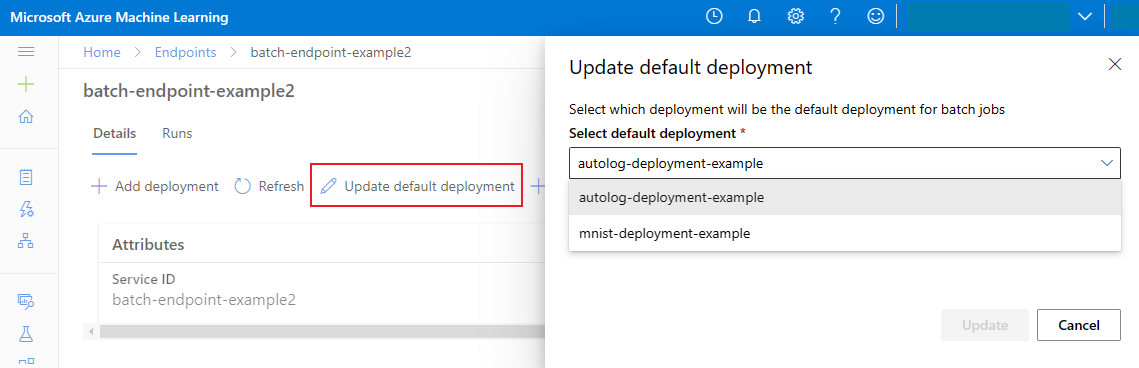
تحديث توزيع الدفعة الافتراضي
على الرغم من أنه يمكنك استدعاء نشر معين داخل نقطة نهاية، إلا أنك ستحتاج عادة إلى استدعاء نقطة النهاية نفسها والسماح لنقطة النهاية بتحديد التوزيع الذي يجب استخدامه - التوزيع الافتراضي. يمكنك تغيير النشر الافتراضي (وبالتالي تغيير النموذج الذي يخدم النشر) دون تغيير العقد مع المستخدم الذي يستدعي نقطة النهاية. استخدم التعليمات البرمجية التالية لتحديث النشر الافتراضي:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
حذف نقطة نهاية الدفعة والتوزيع
إذا لم تكن بحاجة إلى نشر الدفعة القديمة، فاحذفه عن طريق تشغيل التعليمات البرمجية التالية. يؤكد العلم --yes الحذف.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
قم بتشغيل التعليمات البرمجية التالية لحذف نقطة نهاية الدفعة وعمليات التوزيع الأساسية الخاصة بها. لا يتم حذف مهام تسجيل الدفعات
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes