تعزيز سرعة نقطة التحقق وتقليل التكلفة مع السديم
تعرف على كيفية زيادة سرعة نقطة التحقق وتقليل تكلفة نقاط التفتيش لنماذج تدريب Azure التعلم الآلي الكبيرة باستخدام Nebula.
نظرة عامة
Nebula هي أداة نقطة تحقق سريعة وبسيطة وأقل قرصا ومدركة للنموذج في حاوية Azure ل PyTorch (ACPT). تقدم Nebula حلا بسيطا وعالي السرعة لنقاط التفتيش لوظائف تدريب النموذج الموزعة على نطاق واسع باستخدام PyTorch. من خلال استخدام أحدث تقنيات الحوسبة الموزعة، يمكن أن يقلل Nebula من أوقات نقاط التفتيش من ساعات إلى ثوان - مما قد يوفر 95٪ إلى 99.9٪ من الوقت. يمكن أن تستفيد وظائف التدريب واسعة النطاق بشكل كبير من أداء Nebula.
لجعل Nebula متاحا لوظائف التدريب الخاصة بك، قم باستيراد حزمة nebulaml python في البرنامج النصي الخاص بك. يتمتع Nebula بالتوافق الكامل مع استراتيجيات التدريب PyTorch الموزعة المختلفة، بما في ذلك PyTorch Lightning و DeepSpeed والمزيد. توفر واجهة برمجة تطبيقات Nebula طريقة بسيطة لمراقبة دورات حياة نقاط التفتيش وعرضها. تدعم واجهات برمجة التطبيقات أنواعا مختلفة من النماذج، وتضمن تناسق نقاط التحقق وموثوقيتها.
هام
nebulaml الحزمة غير متوفرة على فهرس حزمة PyPI python العام. وهو متوفر فقط في حاوية Azure لبيئة PyTorch (ACPT) المنسقة على Azure التعلم الآلي. لتجنب المشكلات، لا تحاول التثبيت nebulaml من PyPI أو استخدام pip الأمر .
في هذا المستند، ستتعلم كيفية استخدام Nebula مع ACPT على Azure التعلم الآلي للتحقق بسرعة من مهام تدريب النموذج. بالإضافة إلى ذلك، ستتعلم كيفية عرض بيانات نقطة التحقق Nebula وإدارتها. ستتعلم أيضا كيفية استئناف مهام تدريب النموذج من آخر نقطة تحقق متاحة إذا كان هناك انقطاع أو فشل أو إنهاء Azure التعلم الآلي.
لماذا تحسين نقطة التفتيش لتدريب النموذج الكبير مهم
مع نمو وحدات تخزين البيانات وتصبح تنسيقات البيانات أكثر تعقيدا، أصبحت نماذج التعلم الآلي أيضا أكثر تعقيدا. يمكن أن يكون تدريب هذه النماذج المعقدة صعبا بسبب حدود سعة ذاكرة وحدة معالجة الرسومات وأوقات التدريب الطويلة. ونتيجة لذلك، غالبا ما يتم استخدام التدريب الموزع عند العمل مع مجموعات البيانات الكبيرة والنماذج المعقدة. ومع ذلك، يمكن أن تواجه البنيات الموزعة أخطاء غير متوقعة وفشل عقدة، والتي يمكن أن تصبح مشكلة متزايدة مع زيادة عدد العقد في نموذج التعلم الآلي.
يمكن أن تساعد نقاط التحقق في التخفيف من هذه المشكلات عن طريق حفظ لقطة من حالة النموذج الكاملة بشكل دوري في وقت معين. في حالة الفشل، يمكن استخدام هذه اللقطة لإعادة بناء النموذج إلى حالته في وقت اللقطة بحيث يمكن استئناف التدريب من تلك النقطة.
عندما تواجه عمليات التدريب النموذجية الكبيرة حالات فشل أو إنهاء، يمكن لعلماء البيانات والباحثين استعادة عملية التدريب من نقطة تحقق محفوظة مسبقا. ومع ذلك، يتم فقدان أي تقدم يتم إحرازه بين نقطة التحقق والإنهاء حيث يجب إعادة تنفيذ الحسابات لاسترداد النتائج الوسيطة غير المحفدسة. يمكن أن تساعد فترات التحقق الأقصر في تقليل هذه الخسارة. يوضح الرسم التخطيطي الوقت الضائع بين عملية التدريب من نقاط التحقق والإنهاء:

ومع ذلك، يمكن لعملية حفظ نقاط التحقق نفسها أن تولد حملا كبيرا. غالبا ما يصبح حفظ نقطة تفتيش بحجم ТБ ازدحاما في عملية التدريب، مع حظر عملية نقطة التحقق المتزامنة التدريب لساعات. في المتوسط، يمكن أن تمثل النفقات العامة المتعلقة بنقاط التفتيش 12٪ من إجمالي وقت التدريب ويمكن أن ترتفع إلى ما يصل إلى 43٪ (Maeng et al.، 2021).
للتلخيص، تتضمن إدارة نقاط التفتيش النموذجية الكبيرة تخزينا ثقيلا، ونفقاتا إضافية لوقت استرداد الوظيفة. عمليات حفظ نقاط التفتيش المتكررة، جنبا إلى جنب مع استئناف مهمة التدريب من أحدث نقاط التفتيش المتاحة، تصبح تحديا كبيرا.
سديم إلى الإنقاذ
لتدريب النماذج الموزعة الكبيرة بشكل فعال، من المهم أن يكون لديك طريقة موثوقة وفعالة لحفظ واستئناف تقدم التدريب الذي يقلل من فقدان البيانات وهدر الموارد. يساعد Nebula على تقليل أوقات توفير نقاط التحقق ومتطلبات ساعة GPU لنموذج كبير Azure التعلم الآلي مهام التدريب من خلال توفير إدارة أسرع وأسهل لنقاط التفتيش.
مع السديم يمكنك:
عزز سرعات نقاط التفتيش بما يصل إلى 1000 مرة باستخدام واجهة برمجة تطبيقات بسيطة تعمل بشكل غير متزامن مع عملية التدريب الخاصة بك. يمكن أن يقلل السديم من أوقات نقاط التفتيش من ساعات إلى ثوان - انخفاض محتمل بنسبة 95٪ إلى 99٪.
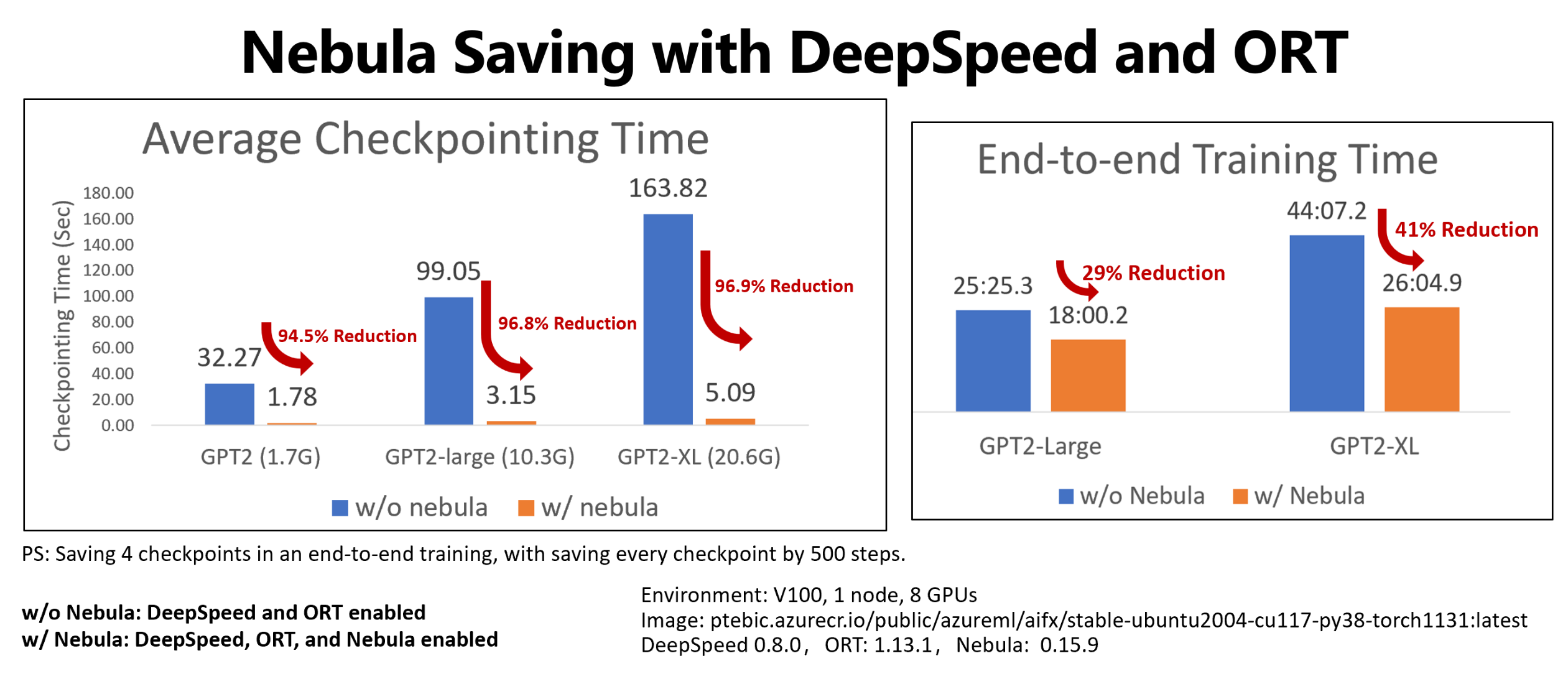
يوضح هذا المثال نقطة التحقق وتقليل وقت التدريب من طرف إلى طرف لأربع نقاط تحقق حفظ وظائف التدريب عناق Face GPT2 وGPT2-Large وGPT-XL. بالنسبة لنقطة التفتيش متوسطة الحجم التي يحفظها Face Hugging Face GPT2-XL (20.6 غيغابايت)، حققت Nebula تقليلا بنسبة 96.9٪ من الوقت لنقطة تفتيش واحدة.
لا يزال من الممكن زيادة زيادة سرعة نقطة التحقق مع حجم النموذج وأرقام وحدة معالجة الرسومات. على سبيل المثال، يمكن أن يتقلص اختبار نقطة اختبار نقطة تدريب بسعة 97 غيغابايت على 128 A100 Nvidia GPUs من 20 دقيقة إلى ثانية واحدة.
تقليل وقت التدريب الشامل وتكاليف الحساب للنماذج الكبيرة عن طريق تقليل النفقات العامة لنقاط التفتيش وتقليل عدد ساعات GPU المهدرة في استرداد الوظيفة. يحفظ Nebula نقاط التفتيش بشكل غير متزامن، ويلغى حظر عملية التدريب، لتقليص وقت التدريب الشامل. كما أنه يسمح بحفظ نقاط التحقق بشكل متكرر. بهذه الطريقة، يمكنك استئناف تدريبك من أحدث نقطة تفتيش بعد أي انقطاع، وتوفير الوقت والمال المهدر في ساعات استرداد الوظيفة وساعات تدريب GPU.
توفير التوافق الكامل مع PyTorch. يوفر Nebula التوافق الكامل مع PyTorch، ويوفر تكاملا كاملا مع أطر التدريب الموزعة، بما في ذلك DeepSpeed (>=0.7.3)، وPyTorch Lightning (>=1.5.0). يمكنك أيضا استخدامه مع أهداف حساب Azure التعلم الآلي مختلفة، مثل Azure التعلم الآلي الحوسبة أو AKS.
يمكنك بسهولة إدارة نقاط التحقق الخاصة بك باستخدام حزمة Python التي تساعد في سرد نقاط التحقق الخاصة بك والحصول عليها وحفظها وتحميلها. لإظهار دورة حياة نقطة التحقق، يوفر Nebula أيضا سجلات شاملة على Azure التعلم الآلي studio. يمكنك اختيار حفظ نقاط التحقق في موقع تخزين محلي أو بعيد
- Azure Blob Storage
- Azure Data Lake Storage Gen2
- NFS
والوصول إليها في أي وقت مع بضعة أسطر من التعليمات البرمجية.

المتطلبات الأساسية
- اشتراك Azure ومساحة عمل Azure التعلم الآلي. راجع إنشاء موارد مساحة العمل للحصول على مزيد من المعلومات حول إنشاء موارد مساحة العمل
- هدف حساب Azure التعلم الآلي. راجع إدارة التدريب ونشر الحسابات لمعرفة المزيد حول إنشاء هدف الحساب
- برنامج نصي للتدريب يستخدم PyTorch.
- بيئة ACPT المنسقة (حاوية Azure ل PyTorch). راجع البيئات المنسقة للحصول على صورة ACPT. تعرف على كيفية استخدام البيئة المنسقة
كيفية استخدام السديم
يوفر Nebula تجربة نقطة تحقق سريعة وسهلة، مباشرة في البرنامج النصي للتدريب الحالي. تتضمن خطوات البدء السريع Nebula ما يلي:
استخدام بيئة ACPT
تتضمن حاوية Azure ل PyTorch (ACPT)، وهي بيئة منسقة لتدريب نموذج PyTorch، Nebula كحزمة Python مثبتة مسبقا ومعتمدة. راجع حاوية Azure ل PyTorch (ACPT) لعرض البيئة المنسقة، وتمكين التعلم العميق باستخدام حاوية Azure ل PyTorch في Azure التعلم الآلي لمعرفة المزيد حول صورة ACPT.
تهيئة السديم
لتمكين Nebula مع بيئة ACPT، تحتاج فقط إلى تعديل البرنامج النصي للتدريب الخاص بك لاستيراد الحزمة nebulaml ، ثم استدعاء واجهات برمجة التطبيقات Nebula في الأماكن المناسبة. يمكنك تجنب تعديل Azure التعلم الآلي SDK أو CLI. يمكنك أيضا تجنب تعديل الخطوات الأخرى لتدريب نموذجك الكبير على Azure التعلم الآلي Platform.
يحتاج Nebula إلى التهيئة للتشغيل في البرنامج النصي للتدريب الخاص بك. في مرحلة التهيئة، حدد المتغيرات التي تحدد موقع حفظ نقطة التحقق وتكرارها، كما هو موضح في قصاصة التعليمات البرمجية هذه:
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
تم دمج Nebula في DeepSpeed وPyTorch Lightning. ونتيجة لذلك، تصبح التهيئة بسيطة وسهلة. توضح هذه الأمثلة كيفية دمج Nebula في البرامج النصية للتدريب.
هام
يتطلب حفظ نقاط التحقق باستخدام Nebula بعض الذاكرة لتخزين نقاط التحقق. الرجاء التأكد من أن الذاكرة أكبر من ثلاث نسخ على الأقل من نقاط التحقق.
إذا لم تكن الذاكرة كافية للاحتفاظ بنقاط التحقق، يقترح عليك إعداد متغير NEBULA_MEMORY_BUFFER_SIZE بيئة في الأمر للحد من استخدام الذاكرة لكل عقدة عند حفظ نقاط التحقق. عند تعيين هذا المتغير، سيستخدم Nebula هذه الذاكرة كمخزن مؤقت لحفظ نقاط التحقق. إذا لم يكن استخدام الذاكرة محدودا، فسيستخدم Nebula الذاكرة قدر الإمكان لتخزين نقاط التحقق.
إذا كانت عمليات متعددة تعمل على نفس العقدة، فإن الحد الأقصى للذاكرة لحفظ نقاط التحقق سيكون نصف الحد مقسوما على عدد العمليات. سيستخدم السديم النصف الآخر للتنسيق متعدد العمليات. على سبيل المثال، إذا كنت تريد تحديد استخدام الذاكرة لكل عقدة إلى 200 ميغابايت، يمكنك تعيين متغير البيئة على أنه export NEBULA_MEMORY_BUFFER_SIZE=200000000 (بالبايت، حوالي 200 ميغابايت) في الأمر. في هذه الحالة، سيستخدم Nebula ذاكرة 200 ميغابايت فقط لتخزين نقاط التحقق في كل عقدة. إذا كانت هناك 4 عمليات تعمل على نفس العقدة، فسيستخدم Nebula ذاكرة 25 ميغابايت لكل عملية لتخزين نقاط التحقق.
استدعاء واجهات برمجة التطبيقات لحفظ نقاط التحقق وتحميلها
يوفر Nebula واجهات برمجة التطبيقات للتعامل مع عمليات حفظ نقاط التحقق. يمكنك استخدام واجهات برمجة التطبيقات هذه في البرامج النصية للتدريب، على غرار واجهة برمجة تطبيقات PyTorch torch.save() . توضح هذه الأمثلة كيفية استخدام Nebula في البرامج النصية للتدريب.
عرض مخازن نقاط التفتيش
عند انتهاء مهمة التدريب، انتقل إلى جزء Job Name> Outputs + logs . في اللوحة اليسرى، قم بتوسيع مجلد Nebula ، وحدد checkpointHistories.csv لمشاهدة معلومات مفصلة حول حفظ نقطة تفتيش Nebula - المدة ومعدل النقل وحجم نقطة التحقق.

الأمثلة
توضح هذه الأمثلة كيفية استخدام Nebula مع أنواع إطار عمل مختلفة. يمكنك اختيار المثال الذي يناسب البرنامج النصي للتدريب الخاص بك.
لتمكين التوافق الكامل مع Nebula مع البرامج النصية للتدريب المستندة إلى PyTorch، قم بتعديل البرنامج النصي للتدريب الخاص بك حسب الحاجة.
أولا، استيراد الحزمة المطلوبة
nebulaml:# Import the Nebula package for fast-checkpointing import nebulaml as nmلتهيئة Nebula، قم باستدعاء الدالة
nm.init()فيmain()، كما هو موضح هنا:# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)لحفظ نقاط التحقق، استبدل العبارة الأصلية
torch.save()لحفظ نقطة التحقق الخاصة بك ب Nebula. يرجى التأكد من أن مثيل نقطة التحقق يبدأ ب "global_step"، مثل "global_step500" أو "global_step1000":checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)إشعار
<'CKPT_TAG_NAME'>هو المعرف الفريد لنقطة التحقق. العلامة عادة ما تكون عدد الخطوات أو رقم الفترة أو أي اسم معرف من قبل المستخدم. تحدد المعلمة الاختيارية رقم<'NUM_OF_FILES'>الحالة الذي ستحفظه لهذه العلامة.قم بتحميل أحدث نقطة تحقق صالحة، كما هو موضح هنا:
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)نظرا لأن نقطة التحقق أو اللقطة قد تحتوي على العديد من الملفات، يمكنك تحميل واحد أو أكثر منها بالاسم. باستخدام نقطة التحقق الأخيرة، يمكن استعادة حالة التدريب إلى الحالة المحفوظة بواسطة نقطة التحقق الأخيرة.
يمكن لواجهات برمجة التطبيقات الأخرى التعامل مع إدارة نقاط التحقق
- سرد جميع نقاط التحقق
- الحصول على أحدث نقاط التحقق
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ