البحث عن النص الكامل في Azure الذكاء الاصطناعي Search
البحث عن النص الكامل هو نهج في استرداد المعلومات يتطابق مع النص العادي المخزن في فهرس. على سبيل المثال، بالنظر إلى سلسلة استعلام "الفنادق في سان دييغو على الشاطئ"، يبحث محرك البحث عن سلاسل مميزة استنادا إلى هذه المصطلحات. لجعل عمليات الفحص أكثر كفاءة، تخضع سلاسل الاستعلام للتحليل المعجمي: تصغير جميع المصطلحات، وإزالة كلمات التوقف مثل "ال"، وتقليل المصطلحات إلى أشكال جذر بدائية. عند العثور على مصطلحات مطابقة، يقوم محرك البحث باسترداد المستندات وترتيبها حسب الصلة وإرجاع أفضل النتائج.
يمكن أن يكون تنفيذ الاستعلام معقدا. هذه المقالة مخصصة للمطورين الذين يحتاجون إلى فهم أعمق لكيفية عمل البحث الكامل في النص في Azure الذكاء الاصطناعي Search. بالنسبة للاستعلامات النصية، يقدم Azure الذكاء الاصطناعي Search النتائج المتوقعة بسلاسة في معظم السيناريوهات، ولكن في بعض الأحيان قد تحصل على نتيجة تبدو "متوقفة عن التشغيل" بطريقة ما. في هذه الحالات، يمكن أن يساعدك وجود خلفية في المراحل الأربع من تنفيذ استعلام Lucene (تحليل الاستعلام، والتحليل المعجمي، ومطابقة المستندات، وتسجيل النقاط) في تحديد تغييرات محددة لمعلمات الاستعلام أو تكوين الفهرس الذي ينتج عنه النتيجة المرجوة.
إشعار
يستخدم Azure الذكاء الاصطناعي Search Apache Lucene للبحث عن النص الكامل، ولكن تكامل Lucene ليس شاملا. نحن نكشف وظائف Lucene ونوسعها بشكل انتقائي لتمكين السيناريوهات المهمة ل Azure الذكاء الاصطناعي Search.
نظرة عامة على البنية والرسم التخطيطي
تنفيذ الاستعلام له أربع مراحل:
- تحليل الاستعلام
- تحليل معجمي
- استرجاع المستندات
- سجل
يبدأ استعلام بحث النص الكامل بتحليل نص الاستعلام لاستخراج مصطلحات البحث وعوامل التشغيل. هناك محللان بحيث يمكنك الاختيار بين السرعة والتعقيد. مرحلة التحليل هي التالية، حيث يتم أحيانا تقسيم مصطلحات الاستعلام الفردية وإعادة تشكيلها إلى أشكال جديدة. تساعد هذه الخطوة على تحويل شبكة أوسع على ما يمكن اعتباره تطابقا محتملا. ثم يقوم محرك البحث بفحص الفهرس للعثور على مستندات ذات مصطلحات ودرجات مطابقة لكل تطابق. ثم يتم فرز مجموعة النتائج حسب درجة الصلة المعينة لكل مستند مُطابق فردي. تُرجع تلك الموجودة في أعلى القائمة المصنفة إلى تطبيق الاستدعاء.
يوضح الرسم التخطيطي أدناه المكونات المُستخدمة لمعالجة طلب بحث.
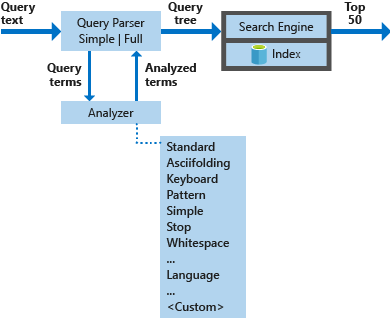
| المكونات الرئيسية | وصف وظيفي |
|---|---|
| محللو الاستعلام | فصل مصطلحات الاستعلام عن عوامل تشغيل الاستعلام وإنشاء بنية الاستعلام (شجرة استعلام) لإرسالها إلى محرك البحث. |
| تحليل | إجراء تحليل معجمي على شروط الاستعلام. يمكن أن تتضمن هذه العملية تحويل شروط الاستعلام أو إزالتها أو توسيعها. |
| الفهرس | بنية بيانات فعالة تستخدم لتخزين وتنظيم المُصطلحات القابلة للبحث المستخرجة من المستندات المفهرسة. |
| مُحرك البحث | استرداد المُستندات المتطابقة ودرجاتها استنادا إلى محتويات الفهرس المقلوب. |
تشريح طلب بحث
طلب البحث هو مواصفات كاملة لما يتعين إرجاعه في مجموعة النتائج. في أبسط شكل، إنه استعلام فارغ بدون معايير من أي نوع. يتضمن المثال الأكثر واقعية المعلمات، والعديد من مُصطلحات الاستعلام، وربما تم تحديد نطاقها لحقول معينة، مع احتمال وجود تعبير عامل تصفية وقواعد ترتيب.
المثال التالي هو طلب بحث قد ترسله إلى Azure الذكاء الاصطناعي Search باستخدام واجهة برمجة تطبيقات REST.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
لهذا الطلب، يقوم محرك البحث بالعملية التالية:
البحث عن مستندات حيث يكون السعر 60 دولارا على الأقل وأقل من 300 دولار.
تنفيذ الاستِعلام. في هذا المثال، يتكون استعلام البحث من عبارات ومصطلحات:
"Spacious, air-condition* +\"Ocean view\""(عادة ما لا يدخل المستخدمون علامات الترقيم، ولكن تضمينها في المثال يسمح لنا بشرح كيفية تعامل المحللين معها).بالنسبة لهذا الاستعلام، يفحص محرك البحث حقلي الوصف والعنوان المحددين في "searchFields" للمستندات التي تحتوي على
"Ocean view"، بالإضافة إلى ذلك على المصطلح"spacious"، أو على المصطلحات التي تبدأ بالبادئة"air-condition". يتم استخدام المعلمة "searchMode" للمطابقة على أي مصطلح (افتراضي) أو كل منها، للحالات التي لا يكون فيها المصطلح مطلوبا بشكل صريح (+).طلب مجموعة الفنادق الناتجة عن طريق القرب من موقع جغرافي معين، ثم إرجاع النتائج إلى تطبيق الاتصال.
تتناول معظم هذه المقالة معالجة استعلام البحث: "Spacious, air-condition* +\"Ocean view\"". التصفية والترتيب خارج النِطاق. للمزيد من المعلومات، راجع وثائق مرجع واجهة برمجة التطبيقات للبحث.
المرحلة الأولى: تحليل الاستعلام
كما هو موضح، سلسلة الاستعلام هي السطر الأول من الطلب:
"search": "Spacious, air-condition* +\"Ocean view\"",
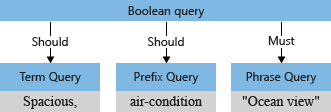
يفصل محلل الاستعلام عوامل التشغيل (مثل * و + في المثال) عن مصطلحات البحث، ويفك تكوين استعلام البحث إلى استعلامات فرعية من نوع معتمد:
- مصطلح الاستعلام عن مصطلحات مستقلة (مثل spacious)
- استعلام العبارة للمصطلحات المقتبسة (مثل ocean view)
- استعلام البادئة للمصطلحات متبوعا بعامل تشغيل بادئة
*(مثل حالة الهواء)
للحصول على قائمة كاملة من أنواع الاستعلامات المدعومة، راجع بناء جملة استعلام Lucene
تحدد عوامل التشغيل المقترنة بالاستعلام الفرعي ما إذا كان الاستعلام "إلزاميًا أن يكون" أو "يفضل أن يكون" راضيا لكي يعتبر المستند مطابقا. على سبيل المثال، +"Ocean view" هو "لازم" بسبب + عامل التشغيل.
يعيد محلل الاستعلام هيكلة الاستعلامات الفرعية في شجرة استعلام (بنية داخلية تمثل الاستعلام) يمررها إلى مُحرك البحث. في المرحلة الأولى من تحليل الاستعلام، تبدو شجرة الاستعلام كالتالي.
محللات معتمدة: Lucene بسيطة وكاملة
يعرض Azure الذكاء الاصطناعي Search لغتين مختلفتين للاستعلام، simple (افتراضي) و full. من خلال تعيين المعلمة queryType مع طلب البحث الخاص بك، يُمكنك إخبار محلل الاستعلام عن لغة الاستعلام التي تختارها بحيث تعرف كيفية تفسير عوامل التشغيل وبناء الجملة.
لغة الاستعلام بسيطة بديهية وقوية، وغالبا ما تكون مناسبة لتفسير مدخلات المستخدم كما هو دون معالجة من جانب العميل. وهو يدعم مشغلي الاستعلام مألوفة من محركات البحث على شبكة الإنترنت.
لغة الاستعلام Lucene الكامل، التي تحصل عليها عن طريق إعداد
queryType=full، توسيع لغة الاستعلام البسيطة الافتراضية عن طريق إضافة دعم للمزيد من المشغلين وأنواع الاستعلام مثل البدل، غامض، regex، والاستعلامات ذات النطاق الميداني. على سبيل المثال، سوف يتم تفسير regex المرسل في بناء جملة استعلام بسيط كسلسلة استعلام وليس تعبيرا. يستخدم طلب المثال في هذه المقالة لغة الاستعلام Lucene الكاملة.
تأثير searchMode على المُحلل
معلمة طلب بحث أخرى تؤثر على التحليل هي المعلمة "searchMode". يتحكم في عامل التشغيل الافتراضي للاستعلامات المَنطقية: أي (افتراضي) أو الكل.
عند "searchMode=any"، وهو الافتراضي، يكون محدد المسافة بين الفسيحة وحالة الهواء هو OR (||)، ما يجعل نص الاستعلام النموذجي مكافئا لما يلي:
Spacious,||air-condition*+"Ocean view"
عوامل التشغيل الصريحة، كما في ++"Ocean view"، لا لبس فيها في بناء الاستعلام المَنطقي ( يجب أن يتطابق المصطلح). أقل وضوحا هو كيفية تفسير المُصطلحات المتبقية: spacious وair-condition. هل يجب على محرك البحث العثور على تطابقات على عرض المحيط وspaciousو air-condition؟ أم ينبغي أن تجد ocean view بالإضافة إلى أي من المصطلحات المتبقية؟
بشكل افتراضي ("searchMode=any")، يفترض محرك البحث التفسير الأوسع. يجب أن يكون أي حقل متطابقا، يعكس "أو" دلالات. تظهر شجرة الاستعلام الأولية الموضحة سابقا، مع عمليتي "يفضل" الإعداد الافتراضي.
لنفترض أننا قمنا الآن بتعيين "searchMode=all". في هذه الحالة، يتم تفسير المساحة على أنها "و" عملية. يجب أن يكون كل من المصطلحات المتبقية موجودا في المستند ليتم تأهيله كمطابقة. سوف يتم تفسير نموذج الاستعلام الناتج على النحو التالي:
+Spacious,+air-condition*+"Ocean view"
سوف تكون شجرة استعلام معدلة لهذا الاستعلام كما يلي، حيث يكون المستند المطابق هو تقاطع جميع الاستعلامات الفرعية الثلاثة:

إشعار
اختيار "searchMode=any" على "searchMode=all" هو أفضل قرار تم الوصول إليه عن طريق تشغيل الاستعلامات التمثيلية. قد يجد المستخدمون الذين من المحتمل أن يتضمنوا عوامل التشغيل (شائعة عند البحث في مخازن المستندات) نتائج أكثر سهولة إذا كان "searchMode=all" يعلم بنيات الاستعلام المنطقية. لمزيد من التفاصيل حول التفاعل بين "searchMode" وعوامل التشغيل، راجع بناء جملة استعلام بسيط.
المَرحلة الثانية: التحليل المعجمي
تقوم أدوات التحليل المعجمية بمعالجة استعلامات المصطلحواستعلامات العبارة بعد هيكلة شجرة الاستعلام. يقبل المحلل إدخالات النص المقدمة إليه من قبل المحلل، ويعالج النص، ثم يرسل المصطلحات المُميزة مرة أخرى لتضمينها في شجرة الاستعلام.
النموذج الأكثر شيوعا للتحليل المعجمي هو *التحليل اللغوي الذي يحول مصطلحات الاستعلام استنادا إلى قواعد خاصة بلغة معينة:
- تقليل مُصطلح استعلام إلى نموذج جذر الكلمة
- إزالة الكلمات غير الأساسية (كلمات التوقف، مثل "ال" أو "و" باللغة الإنجليزية)
- تقسيم كلمة مُركبة إلى أجزاء مكونة
- غلاف سُفلي لكلمة أحرف كبيرة
تميل جميع هذه العمليات إلى مَسح الاختلافات بين إدخال النص الذي يوفره المستخدم والمصطلحات المخزنة في الفهرس. وتتجاوز هذه العمليات مُعالجة النصوص وتتطلب معرفة متعمقة باللغة نفسها. لإضافة هذه الطبقة من الوعي اللغوي، يدعم Azure الذكاء الاصطناعي Search قائمة طويلة من محللات اللغة من كل من Lucene وMicrosoft.
إشعار
يمكن أن تتراوح متطلبات التحليل من الحد الأدنى إلى التفاصيل وفقا للسيناريو الخاص بك. يمكنك التحكم في تعقيد التحليل المعجمي عن طريق تحديد أحد المحللات المعرفة مُسبقا أو عن طريق إنشاء محلل مخصص خاص بك. يتم تحديد نطاق أدوات التحليل لحقول قابلة للبَحث ويتم تحديدها كجزء من تعريف الحقل. يَسمح لك هذا باختلاف التحليل المعجمي على أساس كل حقل. غير مُحدد، يتم استخدام محلل Lucene القياسي.
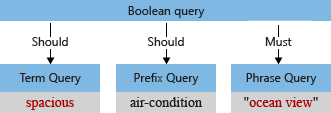
في مثالنا، قبل التحليل، تحتوي شجرة الاستعلام الأولية على مصطلح "واسع"، مع حرف "S" كبير وفاسمة يفسرها محلل الاستعلام كجزء من مصطلح الاستعلام (لا تعتبر الفاصلة عامل تشغيل لغة استعلام).
عندما يقوم المحلل الافتراضي بمعالجة المصطلح، فإنه سينخفض "ocean view" و"spacious"، ويزيل حرف الفاصلة. تبدو شجرة الاستعلام المعدلة كما يلي:
اختبار سلوكيات المُحلل
يمكنك اختبار سلوك المحلل باستخدام واجهة برمجة تطبيقات التحليل. قم بتوفير النص الذي تريد تحليله لمعرفة المصطلحات التي ينشئها المحلل. على سبيل المثال، لمعرفة كيفية معالجة المحلل القياسي للنص "air-condition"، يمكنك إصدار الطلب التالي:
{
"text": "air-condition",
"analyzer": "standard"
}
يقوم المحلل القياسي بتقسيم نص الإدخال إلى الرمزين المميزين التاليين، مع إضافة تعليقات توضيحية إليهما باستخدام سمات مثل إزاحات البدء والنهاية (المستخدمة لتمييز الضغط) بالإضافة إلى موضعهما (يُستخدم لمطابقة العبارة):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
الاستثناءات للتحليل المعجمي
ينطبق التحليل المعجمي فقط على أنواع الاستعلامات التي تتطلب مصطلحات كاملة - إما استعلام مُصطلح أو استعلام عبارة. لا ينطبق على أنواع الاستعلامات ذات المُصطلحات غير المكتملة - استعلام البادئة، استعلام حرف البدل، استعلام regex - أو استعلام غامض. تتم إضافة أنواع الاستعلام هذه، بما في ذلك استعلام البادئة مع المُصطلح air-condition* في مثالنا، مباشرة إلى شجرة الاستعلام، متجاوزة مرحلة التحليل. التحويل الوحيد الذي يتم تنفيذه على شروط الاستعلام من هذه الأنواع هو الأقل أحرفا.
المرحلة الثالثة: استرجاع المستند
يُشير استرداد المستند إلى البحث عن مستندات ذات مصطلحات مطابقة في الفهرس. هذه المرحلة مفهومة بشكل أفضل من خِلال مثال. لنبدأ بمؤشر الفنادق الذي يحتوي على المُخطط البسيط التالي:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
افترض أيضا أن هذا الفهرس يحتوي على المُستندات الأربعة التالية:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
كيفية فهرسة المُصطلحات
فهم الاسترداد، يساعد على معرفة بعض الأساسيات حول الفهرسة. وحدة التخزين هي فِهرس مقلوب، واحد لكل حقل قابل للبحث. ضمن الفهرس المقلوب توجد قائمة تم فرزها من جميع المُصطلحات من جميع المستندات. يتم تعيين كل مُصطلح إلى قائمة المستندات التي يحدث فيها، كما هو واضح في المثال أدناه.
لإنتاج المُصطلحات في فهرس معكوس، يقوم محرك البحث بإجراء تحليل معجمي على محتوى المستندات، على غرار ما يحدث أثناء معالجة الاستعلام:
- يتم تمرير إدخالات النص إلى مُحلل، ذي أحرف صغيرة، ويتم تجريدها من علامات الترقيم، وما إلى ذلك، اعتمادا على تكوين المحلل.
- الرموز المميزة هي ناتج التحليل المعجمي.
- تتم إضافة المصطلحات إلى الفهرس.
من الشائع، ولكن ليس مطلوبا، استخدام نفس المحللات لعمليات البحث والفهرسة بحيث تبدو مُصطلحات الاستعلام أشبه بالمصطلحات داخل الفهرس.
إشعار
يتيح لك Azure الذكاء الاصطناعي Search تحديد محللات مختلفة للفهرسة والبحث عبر معلمات إضافية indexAnalyzer وحقل searchAnalyzer . إذا لم يتم تحديده، يتم استخدام مجموعة المحلل مع الخاصية analyzer لكل من الفهرَسة والبحث.
الفهرس المقلوب لنماذج المستندات
بالعودة إلى مثالنا، لحقل العنوان، يبدو الفهرس المقلوب كما يلي:
| الشرط | قائمة المُستندات |
|---|---|
| عَتمان | 1 |
| beach | 2 |
| فندق | 1, 3 |
| محيط | 4 |
| بِلايا | 3 |
| مُنتجع | 3 |
| تَراجع | 4 |
في حقل العنوان، يظهر الفندق فقط في مُستندين: 1، 3.
بالنسبة لحقل الوصف، يكون الفهرس كما يلي:
| الشرط | قائمة المُستندات |
|---|---|
| air | 3 |
| و | 4 |
| beach | 1 |
| مشروط | 3 |
| مُريح | 3 |
| مسافة | 1 |
| جزيرة | 2 |
| كاوايي | 2 |
| يقع | 2 |
| الشمال | 2 |
| محيط | 1, 2, 3 |
| من | 2 |
| تشغيل | 2 |
| هادئ | 4 |
| غرف | 1, 3 |
| مُنعزل | 4 |
| شاطئ | 2 |
| spacious | 1 |
| الـ | 1، 2 |
| to | 1 |
| العرض | 1, 2, 3 |
| مشي | 1 |
| مع | 3 |
مطابقة مصطلحات الاستعلام مقابل المصطلحات المفهرسة
بالنظر إلى الفهارس المقلوبة أعلاه، دعنا نعود إلى نموذج الاستعلام ونرى كيف يتم العثور على مستندات مطابقة لاستعلام المثال الخاص بنا. استرجع أن شجرة الاستعلام النهائية تبدو كالتالي:
أثناء تنفيذ الاستعلام، يتم تنفيذ الاستعلامات الفردية مقابل الحقول القابلة للبحث بشكل مُستقل.
يتطابق TermQuery، "spacious"، مع المستند 1 (فندق عتمان).
لا يتطابق PrefixQuery، "air-condition*"، مع أي مُستندات.
يخلط هذا السلوك أحيانا بين المطورين. على الرغم من وجود مصطلح مكيف الهواء في المستند، فإنه يتم تقسيمه إلى مصطلحين بواسطة المحلل الافتراضي. تذكر أنه لا يتم تحليل استعلامات البادئة، التي تحتوي على مصطلحات جزئية. لذلك يتم البحث عن المصطلحات ذات البادئة "air-conditioned" في الفهرس المقلوب ولم يتم العثور عليها.
يبحث PhraseQuery، "ocean view"، عن مصطلحي "ocean" و"view" ويتحقق من تقارب المصطلحات في الوثيقة الأصلية. تطابق المستندات 1 و 2 و 3 هذا الاستعلام في حقل الوصف. لاحظ أن المستند 4 يحتوي على مصطلح ocean في العنوان ولكنه لا يعتبر مطابقا، لأننا نبحث عن عبارة "ocean view" بدلا من الكلمات الفردية.
إشعار
يتم تنفيذ استعلام بحث بشكل مستقل مقابل جميع الحقول القابلة للبحث في فهرس البحث في Azure الذكاء الاصطناعي إلا إذا قمت بتحديد الحقول التي تم تعيينها باستخدام المعلمة searchFields ، كما هو موضح في طلب البحث المثال. يتم إرجاع المستندات المتطابقة في أي من الحقول المُحددة.
بشكل عام، بالنسبة للاستعلام المعني، تكون المُستندات المتطابقة هي 1، 2، 3.
المَرحلة الرابعة: التسجيل
يتم تعيين درجة صلة لكل مُستند في مجموعة نتائج البحث. وظيفة درجة الصلة هي ترتيب أعلى لتلك المُستندات التي تجيب على سؤال المستخدم على النحو المعبر عنه في استعلام البحث. يتم حساب النتيجة استنادا إلى الخصائص الإحصائية للمُصطلحات المتطابقة. في جوهر صيغة التسجيل يوجد TF/IDF (مصطلح التردد العكسي للمستندات). في الاستعلامات التي تحتوي على مصطلحات نادرة وشائعة، يعزز TF/IDF النتائج التي تحتوي على المُصطلح النادر. على سبيل المثال، في فهرس افتراضي مع جميع مقالات ويكيبيديا، من المستندات التي تطابق الاستعلام الرئيس، تعتبر المستندات المطابقة على الرئيس أكثر صلة من المستندات المطابقة على.
مثال على تسجيل النِقاط
تذكر المُستندات الثلاثة التي تطابقت مع استعلام المثال:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
يتطابق المستند الأول مع الاستعلام على أفضل نحو لأن كلا من المصطلح spacious وocean view المطلوب يحدثان في حقل الوصف. تتطابق الوثيقتان التاليتان فقط مع عبارة ocean view. قد يكون من المستغرب أن تكون درجة الصلة للمستند الثاني والثالث مختلفة على الرغم من أنها تطابقت مع الاستعلام بنفس الطريقة. وذلك لأن صيغة التسجيل تحتوي على مُكونات أكثر من TF/IDF فقط. في هذه الحالة، تم تعيين درجة أعلى قليلا للمستند الثالث لأن وصفه أقصر. تعرف على صيغة التسجيل العملية لـ Lucene لفهم كيفية تأثير طول الحقل والعوامل الأخرى على درجة الصلة.
تساهم بعض أنواع الاستعلامات (حرف البدل، البادئة، regex) دائما بنقاط ثابتة في درجة المُستند الإجمالية. يَسمح هذا بتضمين التطابقات التي تم العثور عليها من خلال توسيع الاستعلام في النتائج، ولكن دون التأثير على الترتيب.
مثال يوضح السبب لأهمية ذلك. عمليات البحث عن أحرف البدل، بما في ذلك عمليات البحث عن البادئة، غامضة بحكم التعريف لأن الإدخال عبارة عن سلسلة جزئية ذات تطابقات محتملة على عدد كبير جدا من المصطلحات المتباينة (ضع في اعتبارك إدخال "tour*"، مع وجود تطابقات في "tours"، و"tourettes"، و"tourmaline"). نظرا لطبيعة هذه النتائج، لا توجد طريقة للاستدلال بشكل معقول على المصطلحات الأكثر قيمة من غيرها. لهذا السبب، نتجاهل تكرارات المُصطلح عند تسجيل النتائج في استعلامات أنواع حرف البدل والبادئة و regex. في طلب بحث متعدد الأجزاء يتضمن مصطلحات جزئية وكاملة، يتم دمج النتائج من الإدخال الجزئي بدرجة ثابتة لتجنب التحيز نحو التطابقات غير المتوقعة المُحتملة.
ضبط الصلة
هناك طريقتان لضبط درجات الصلة في Azure الذكاء الاصطناعي Search:
ترقيملفات تعريف النقاط للمستندات في قائمة النتائج المصنفة استنادا إلى مجموعة من القواعد. في مثالنا، يمكننا اعتبار المستندات المتطابقة في حقل العنوان أكثر صلة من المُستندات المتطابقة في حقل الوصف. بالإضافة إلى ذلك، إذا كان فهرسنا حقل سعر لكل فندق، يمكننا الترويج للمُستندات بسعر أقل. تعرف على المزيد حول إضافة ملفات تعريف تسجيل النقاط إلى فهرس بحث.
يوفر تعزيز المُصطلح (متوفر فقط في بناء جملة استعلام Lucene الكامل) عامل تشغيل
^تعزيز يمكن تطبيقه على أي جزء من شجرة الاستعلام. في مثالنا، بدلا من البحث عن air-condition البادئة*، يمكن للمرء أن يبحث عن المصطلح الدقيق air-condition أو البادئة، ولكن يتم ترتيب المستندات التي تتطابق مع المصطلح الدقيق أعلى من خلال تطبيق تعزيز على استعلام المصطلح: air-condition^2||air-condition*. تعرف على المزيد حول تعزيز المصطلح في استعلام.
تسجيل النقاط في فهرس موزع
يتم تقسيم جميع الفهارس في Azure الذكاء الاصطناعي Search تلقائيا إلى أجزاء متعددة، ما يسمح لنا بتوزيع الفهرس بسرعة بين عقد متعددة أثناء توسيع الخدمة أو تقليصها. عند إصدار طلب بحث، يتم إصداره مقابل كل جزء بشكل مُستقل. بعدها يتم دمج النتائج من كل جزء وترتيبها حسب النتيجة (إذا لم يتم تعريف أي ترتيب آخر). من المهم معرفة أن دالة التسجيل ترجح تكرار مصطلح الاستعلام مقابل تكرار المستند العكسي في جميع المستندات داخل الجزء، وليس عبر جميع الأجزاء!
وهذا يعني أن نقاط الصلة يمكن أن تكون مختلفة للمستندات المتطابقة إذا كانت موجودة على أجزاء مختلفة. لحسن الحظ، تميل هذه الاختلافات إلى الاختفاء مع نمو عدد المستندات في الفهرس بسبب توزيع أكثر التساوي للمُصطلحات. لا يمكن افتراض الجزء الذي سوف يتم وضع أي مستند معين عليه. ومع ذلك، بافتراض عدم تغيير مفتاح المستند، سوف يتم تعيينه دائما إلى نفس الجزء.
بشكل عام، درجة المستند ليست أفضل سمة لطلب المستندات إذا كان استقرار الطلب مهما. على سبيل المثال، بالنظر إلى مستندين مع درجة متطابقة، لا يوجد ضمان بأن يظهر أحدهما أولا في عمليات التشغيل اللاحقة لنفس الاستعلام. يجب أن تعطي درجة المستند فقط إحساسًا عامًا بأهمية المستند بالنسبة إلى المستندات الأخرى في مجموعة النتائج.
الخاتمة
وقد أدى نجاح محركات البحث التجارية إلى رفع التوقعات للبحث الكامل عن النص على البيانات الخاصة. لأي نوع تقريبا من تجربة البحث، نتوقع الآن أن يفهم المُحرك هدفنا، حتى عندما تكون المصطلحات بها أخطاء إملائية أو غير مكتملة. قد نتوقع حتى تطابقات استنادا إلى مصطلحات أو مرادفات شبه مكافئة لم نحددها أبدا.
من الناحية التقنية، يعد البحث عن النص الكامل معقدا للغاية، ويتطلب تحليلا لغويا متطورا ونهجا منهجيا للمعالجة بطرق تقوم بتقطير مُصطلحات الاستعلام وتوسيعها وتحويلها لتقديم نتيجة ذات صلة. نظرا للتعقيدات المتأصلة، هناك العديد من العوامل التي يمكن أن تؤثر على نتيجة الاستعلام. لهذا السبب، يوفر استثمار الوقت لفهم آليات البحث عن النص الكامل فوائد ملموسة عند محاولة العمل من خلال نتائج غير مُتوقعة.
استكشفت هذه المقالة البحث عن النص الكامل في سياق Azure الذكاء الاصطناعي Search. نأمل أن يمنحك خلفية كافية للتعرف على الأسباب المُحتملة والحلول لمعالجة مشاكل الاستعلام الشائعة.
الخطوات التالية
إنشاء نموذج الفهرس وتجربة استعلامات مُختلفة ومراجعة النتائج. للحصول على الإرشادات، راجع إنشاء فِهرس والاستعلام عنه في المدخل.
جرب بناء جملة استعلام آخر من قسم مثال البحث في المستندات أو من بناء جملة استعلام بسيط في مستكشف البحث في المدخل.
راجع ملفات تعريف تسجيل النقاط إذا كنت تريد ضَبط الترتيب في تطبيق البحث الخاص بك.
تعرف على كيفية تطبيق محللات معجمية متعلقة باللغة.
تكوين أدوات التحليل المخصصة إما للمعالجة الدنيا أو المعالجة المتخصصة في حقول معينة.
(راجع أيضًا )
البحث عن مستندات واجهة برمجة تطبيقات REST
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ