ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
يمكن ل Azure الذكاء الاصطناعي Search استخراج وفهرسة كل من النصوص والصور من مستندات PDF المخزنة في Azure Blob Storage. يوضح لك هذا البرنامج التعليمي كيفية إنشاء مسار فهرسة متعدد الوسائط من خلال وصف المحتوى المرئي باللغة الطبيعية وتضمينه جنبا إلى جنب مع نص المستند.
من المستند المصدر، يتم تمرير كل صورة إلى مهارة GenAI Prompt (معاينة) لإنشاء وصف نصي موجز. ثم يتم تضمين هذه الأوصاف، جنبا إلى جنب مع نص المستند الأصلي، في تمثيلات المتجهات باستخدام نموذج Azure OpenAI لتضمين النص-3-كبير. والنتيجة هي فهرس واحد يحتوي على محتوى قابل للبحث الدلالي من كلا الأسلوبين: النص والصور اللفظية.
في هذا البرنامج التعليمي، يمكنك استخدام:
مستند PDF من 36 صفحة يجمع بين محتوى مرئي غني، مثل المخططات البيانية والرسوم البيانية للمعلومات والصفحات الممسوحة ضوئيا، مع النص التقليدي.
مهارة استخراج المستند لاستخراج الصور والنصوص التي تمت تسويتها.
مهارة GenAI Prompt (معاينة) لإنشاء تسميات توضيحية للصور، وهي أوصاف مستندة إلى النص للمحتوى المرئي، للبحث والترسيخ.
فهرس بحث تم تكوينه لتخزين تضمينات النص والصور ودعم البحث عن التشابه المستند إلى المتجهات.
يوضح هذا البرنامج التعليمي نهجا أقل تكلفة لفهرسة المحتوى متعدد الوسائط باستخدام مهارة استخراج المستندات والتسمية التوضيحية للصور. وهو يتيح الاستخراج والبحث عبر كل من النص والصور من المستندات في Azure Blob Storage. ومع ذلك، لا يتضمن بيانات التعريف الموقعية للنص، مثل أرقام الصفحات أو المناطق الحدودية.
للحصول على حل أكثر شمولا يتضمن تخطيط نص منظم وبيانات تعريف مكانية، راجع فهرسة الكائنات الثنائية كبيرة الحجم مع النصوص والصور لسيناريوهات RAG متعددة الوسائط باستخدام شفه الصور ومهارة تخطيط المستند.
إشعار
الإعداد imageAction إلى generateNormalizedImages مطلوب لهذا البرنامج التعليمي ويتحمل رسوما إضافية لاستخراج الصور وفقا لتسعير Azure الذكاء الاصطناعي Search.
باستخدام عميل REST وواجهات برمجة تطبيقات REST للبحث ، سوف:
- إعداد نموذج البيانات وتكوين
azureblobمصدر بيانات - إنشاء فهرس مع دعم لتضمين النص والصور
- تحديد مجموعة مهارات مع خطوات الاستخراج والتسمية التوضيحية والتضمين
- إنشاء مفهرس وتشغيله لمعالجة المحتوى وفهرسته
- البحث في الفهرس الذي أنشأته للتو
المتطلبات المسبقه
حساب Azure مع اشتراك نشط. أنشئ حساباً مجاناً.
Azure الذكاء الاصطناعي Search أو مستوى التسعير الأساسي أو أعلى، بهوية مدارة. إنشاء خدمة أو العثور على خدمة موجودة في اشتراكك الحالي.
Visual Studio Code مع عميل REST.
تنزيل الملفات
قم بتنزيل نموذج PDF التالي:
تحميل نموذج البيانات إلى Azure Storage
في Azure Storage، قم بإنشاء حاوية جديدة تسمى doc-extraction-image-اللفظية-container.
إنشاء تعيين دور في Azure Storage وتحديد هوية مدارة في سلسلة اتصال
للاتصالات التي تم إجراؤها باستخدام هوية مدارة يعينها النظام. قم بتوفير سلسلة اتصال تحتوي على ResourceId، بدون مفتاح حساب أو كلمة مرور. يجب أن يتضمن ResourceId معرف الاشتراك لحساب التخزين ومجموعة الموارد لحساب التخزين واسم حساب التخزين. يشبه سلسلة الاتصال المثال التالي:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }للاتصالات التي تم إجراؤها باستخدام هوية مدارة يعينها المستخدم. قم بتوفير سلسلة اتصال تحتوي على ResourceId، بدون مفتاح حساب أو كلمة مرور. يجب أن يتضمن ResourceId معرف الاشتراك لحساب التخزين ومجموعة الموارد لحساب التخزين واسم حساب التخزين. توفير هوية باستخدام بناء الجملة الموضح في المثال التالي. تعيين userAssignedIdentity إلى الهوية المدارة المعينة من قبل المستخدم سلسلة الاتصال مشابهة للمثال التالي:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }, "identity" : { "@odata.type": "#Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity" : "/subscriptions/00000000-0000-0000-0000-00000000/resourcegroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.ManagedIdentity/userAssignedIdentities/MY-DEMO-USER-MANAGED-IDENTITY" }
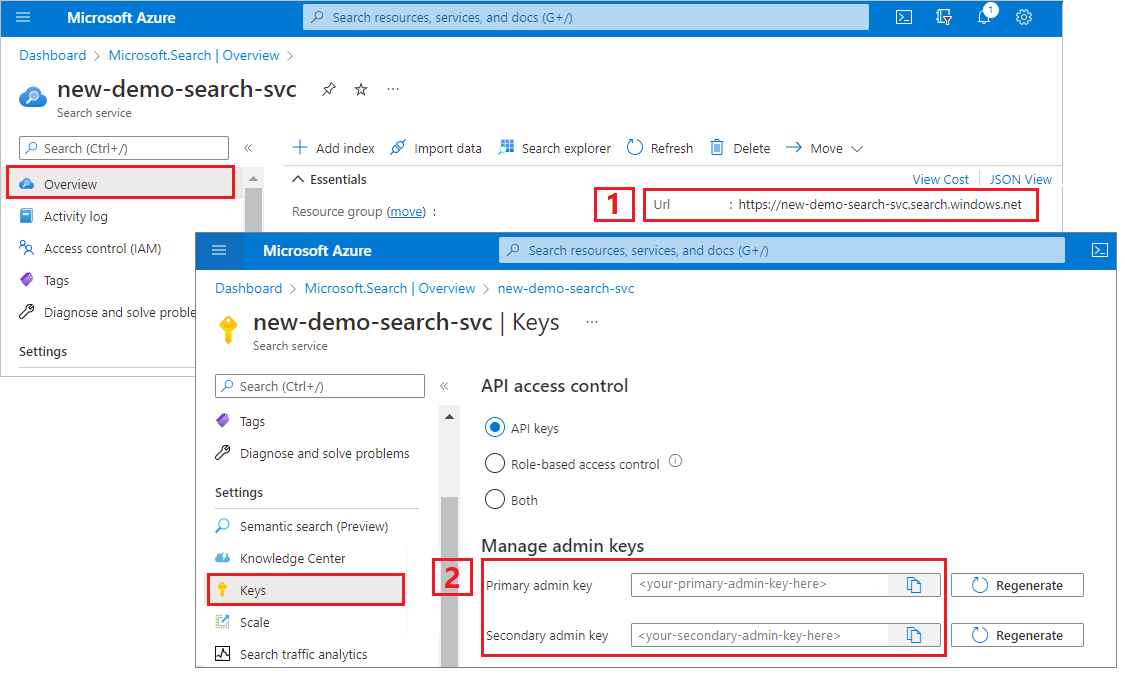
نسخ عنوان URL لخدمة البحث ومفتاح API
بالنسبة لهذا البرنامج التعليمي، تتطلب الاتصالات ب Azure الذكاء الاصطناعي Search نقطة نهاية ومفتاح API. يمكنك الحصول على هذه القيم من مدخل Microsoft Azure. للحصول على أساليب اتصال بديلة، راجع الهويات المدارة.
سجل الدخول إلى مدخل Microsoft Azure، وانتقل إلى صفحة نظرة عامة على خدمة البحث، وانسخ عنوان URL. قد يبدو مثال نقطة النهاية بالشكل
https://mydemo.search.windows.net.ضمن مفاتيح الإعدادات>، انسخ مفتاح مسؤول. يتم استخدام مفاتيح المسؤول لإضافة الكائنات وتعديلها وحذفها. هناك مفتاحان للمسؤول قابلان للتبديل. انسخ أي منهما.
إعداد ملف REST
ابدأ تشغيل Visual Studio Code وأنشئ ملفا جديدا.
توفير قيم للمتغيرات المستخدمة في الطلب.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @openAIResourceUri = PUT-YOUR-OPENAI-URI-HERE @openAIKey = PUT-YOUR-OPENAI-KEY-HERE @chatCompletionResourceUri = PUT-YOUR-CHAT-COMPLETION-URI-HERE @chatCompletionKey = PUT-YOUR-CHAT-COMPLETION-KEY-HERE @imageProjectionContainer=PUT-YOUR-IMAGE-PROJECTION-CONTAINER-HEREاحفظ الملف باستخدام
.restملحق ملف أو.http.
للحصول على تعليمات حول عميل REST، راجع التشغيل السريع: البحث عن الكلمات الأساسية باستخدام REST.
إنشاء مصدر بيانات
إنشاء مصدر بيانات (REST) ينشئ اتصال مصدر بيانات يحدد البيانات التي يجب فهرستها.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnection}}"
},
"container": {
"name": "doc-extraction-image-verbalization-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
أرسل الطلب. يجب أن تبدو الاستجابة كما يلي:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows-int.net:443/datasources('doc-extraction-image-verbalization-ds')?api-version=2025-05-01-preview -Preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 4eb8bcc3-27b5-44af-834e-295ed078e8ed
elapsed-time: 346
Date: Sat, 26 Apr 2025 21:25:24 GMT
Connection: close
{
"name": "doc-extraction-image-verbalization-ds",
"description": "A test datasource",
"type": "azureblob",
"subtype": null,
"indexerPermissionOptions": [],
"credentials": {
"connectionString": null
},
"container": {
"name": "doc-extraction-multimodality-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
إنشاء فهرس
إنشاء فهرس (REST) ينشئ فهرس بحث على خدمة البحث. يحدد الفهرس جميع المعلمات وسماتها.
بالنسبة إلى JSON المتداخلة، يجب أن تكون حقول الفهرس متطابقة مع الحقول المصدر. حاليا، لا يدعم Azure الذكاء الاصطناعي Search تعيينات الحقول إلى JSON المتداخلة، لذلك يجب أن تتطابق أسماء الحقول وأنواع البيانات تماما. يتوافق الفهرس التالي مع عناصر JSON في المحتوى الأولي.
### Create an index
POST {{baseUrl}}/indexes?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-index",
"fields": [
{
"name": "content_id",
"type": "Edm.String",
"retrievable": true,
"key": true,
"analyzer": "keyword"
},
{
"name": "text_document_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false
},
{
"name": "document_title",
"type": "Edm.String",
"searchable": true
},
{
"name": "image_document_id",
"type": "Edm.String",
"filterable": true,
"retrievable": true
},
{
"name": "content_text",
"type": "Edm.String",
"searchable": true,
"retrievable": true
},
{
"name": "content_embedding",
"type": "Collection(Edm.Single)",
"dimensions": 3072,
"searchable": true,
"retrievable": true,
"vectorSearchProfile": "hnsw"
},
{
"name": "content_path",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "offset",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "location_metadata",
"type": "Edm.ComplexType",
"fields": [
{
"name": "page_number",
"type": "Edm.Int32",
"searchable": false,
"retrievable": true
},
{
"name": "bounding_polygons",
"type": "Edm.String",
"searchable": false,
"retrievable": true,
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
],
"vectorSearch": {
"profiles": [
{
"name": "hnsw",
"algorithm": "defaulthnsw",
"vectorizer": "{{vectorizer}}"
}
],
"algorithms": [
{
"name": "defaulthnsw",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"metric": "cosine"
}
}
],
"vectorizers": [
{
"name": "{{vectorizer}}",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"modelName": "text-embedding-3-large"
}
}
]
},
"semantic": {
"defaultConfiguration": "semanticconfig",
"configurations": [
{
"name": "semanticconfig",
"prioritizedFields": {
"titleField": {
"fieldName": "document_title"
},
"prioritizedContentFields": [
],
"prioritizedKeywordsFields": []
}
}
]
}
}
النقاط الرئيسية:
يتم تخزين تضمينات النص والصور في
content_embeddingالحقل ويجب تكوينها بأبعاد مناسبة (على سبيل المثال، 3072) وملف تعريف بحث متجه.location_metadataيلتقط المضلع المحيط وبيانات تعريف رقم الصفحة لكل صورة تمت تسويتها، ما يتيح البحث المكاني الدقيق أو تراكبات واجهة المستخدم.location_metadataموجود فقط للصور في هذا السيناريو. إذا كنت ترغب في التقاط بيانات التعريف الموقعية للنص أيضا، ففكر في استخدام مهارة تخطيط المستند. يتم ربط برنامج تعليمي متعمق في أسفل الصفحة.لمزيد من المعلومات حول البحث عن المتجهات، راجع المتجهات في Azure الذكاء الاصطناعي Search.
لمزيد من المعلومات حول الترتيب الدلالي، راجع الترتيب الدلالي في Azure الذكاء الاصطناعي Search
إنشاء مجموعة مهارات
ينشئ Create Skillset (REST) فهرس بحث على خدمة البحث. يحدد الفهرس جميع المعلمات وسماتها.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "doc-extraction-image-verbalization-skillset",
"description": "A test skillset",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentExtractionSkill",
"name": "document-extraction-skill",
"description": "Document extraction skill to exract text and images from documents",
"parsingMode": "default",
"dataToExtract": "contentAndMetadata",
"configuration": {
"imageAction": "generateNormalizedImages",
"normalizedImageMaxWidth": 2000,
"normalizedImageMaxHeight": 2000
},
"context": "/document",
"inputs": [
{
"name": "file_data",
"source": "/document/file_data"
}
],
"outputs": [
{
"name": "content",
"targetName": "extracted_content"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "split-skill",
"description": "Split skill to chunk documents",
"context": "/document",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 200,
"unit": "characters",
"inputs": [
{
"name": "text",
"source": "/document/extracted_content",
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "text-embedding-skill",
"description": "Embedding skill for text",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Custom.ChatCompletionSkill",
"name": "genAI-prompt-skill",
"description": "GenAI Prompt skill for image verbalization",
"uri": "{{chatCompletionResourceUri}}",
"timeout": "PT1M",
"apiKey": "{{chatCompletionKey}}",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "systemMessage",
"source": "='You are tasked with generating concise, accurate descriptions of images, figures, diagrams, or charts in documents. The goal is to capture the key information and meaning conveyed by the image without including extraneous details like style, colors, visual aesthetics, or size.\n\nInstructions:\nContent Focus: Describe the core content and relationships depicted in the image.\n\nFor diagrams, specify the main elements and how they are connected or interact.\nFor charts, highlight key data points, trends, comparisons, or conclusions.\nFor figures or technical illustrations, identify the components and their significance.\nClarity & Precision: Use concise language to ensure clarity and technical accuracy. Avoid subjective or interpretive statements.\n\nAvoid Visual Descriptors: Exclude details about:\n\nColors, shading, and visual styles.\nImage size, layout, or decorative elements.\nFonts, borders, and stylistic embellishments.\nContext: If relevant, relate the image to the broader content of the technical document or the topic it supports.\n\nExample Descriptions:\nDiagram: \"A flowchart showing the four stages of a machine learning pipeline: data collection, preprocessing, model training, and evaluation, with arrows indicating the sequential flow of tasks.\"\n\nChart: \"A bar chart comparing the performance of four algorithms on three datasets, showing that Algorithm A consistently outperforms the others on Dataset 1.\"\n\nFigure: \"A labeled diagram illustrating the components of a transformer model, including the encoder, decoder, self-attention mechanism, and feedforward layers.\"'"
},
{
"name": "userMessage",
"source": "='Please describe this image.'"
},
{
"name": "image",
"source": "/document/normalized_images/*/data"
}
],
"outputs": [
{
"name": "response",
"targetName": "verbalizedImage"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "verblized-image-embedding-skill",
"description": "Embedding skill for verbalized images",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "text",
"source": "/document/normalized_images/*/verbalizedImage",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "verbalizedImage_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "shaper-skill",
"description": "Shaper skill to reshape the data to fit the index schema"
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='{{imageProjectionContainer}}/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
},
{
"name": "location_metadata",
"sourceContext": "/document/normalized_images/*",
"inputs": [
{
"name": "page_number",
"source": "/document/normalized_images/*/pageNumber"
},
{
"name": "bounding_polygons",
"source": "/document/normalized_images/*/boundingPolygon"
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "{{index}}",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/pages/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/pages/*/text_vector"
},
{
"name": "content_text",
"source": "/document/pages/*"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
},
{
"targetIndexName": "{{index}}",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_text",
"source": "/document/normalized_images/*/verbalizedImage"
},
{
"name": "content_embedding",
"source": "/document/normalized_images/*/verbalizedImage_vector"
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath"
},
{
"name": "document_title",
"source": "/document/document_title"
},
{
"name": "locationMetadata",
"source": "/document/normalized_images/*/new_normalized_images/location_metadata"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
},
"knowledgeStore": {
"storageConnectionString": "{{storageConnection}}",
"projections": [
{
"files": [
{
"storageContainer": "{{imageProjectionContainer}}",
"source": "/document/normalized_images/*"
}
]
}
]
}
}
تستخرج مجموعة المهارات هذه النص والصور، وتتجه إلى كل من، وأشكال بيانات تعريف الصورة للإسقاط في الفهرس.
النقاط الرئيسية:
content_textيتم ملء الحقل بطريقتين:من نص المستند المستخرج باستخدام مهارة استخراج المستند ومقسم باستخدام مهارة تقسيم النص
من محتوى الصورة باستخدام مهارة GenAI Prompt، التي تنشئ تسميات توضيحية وصفية لكل صورة تمت تسويتها
content_embeddingيحتوي الحقل على تضمينات ثلاثية الأبعاد لكل من نص الصفحة ووصف الصورة اللفظية. يتم إنشاء هذه باستخدام نموذج تضمين النص-3-كبير من Azure OpenAI.content_pathيحتوي على المسار النسبي لملف الصورة داخل حاوية إسقاط الصورة المعينة. يتم إنشاء هذا الحقل فقط للصور المستخرجة من ملفات PDF عندimageActionتعيينها إلىgenerateNormalizedImages، ويمكن تعيينه من المستند الذي تم إثرائه من الحقل/document/normalized_images/*/imagePathالمصدر .
إنشاء مفهرس وتشغيله
إنشاء مفهرس ينشئ مفهرس على خدمة البحث. يتصل المفهرس بمصدر البيانات، ويحمل البيانات، ويشغل مجموعة مهارات، وفهرسة البيانات التي تم إثراؤها.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"dataSourceName": "doc-extraction-image-verbalization-ds",
"targetIndexName": "doc-extraction-image-verbalization-index",
"skillsetName": "doc-extraction-image-verbalization-skillset",
"parameters": {
"maxFailedItems": -1,
"maxFailedItemsPerBatch": 0,
"batchSize": 1,
"configuration": {
"allowSkillsetToReadFileData": true
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "document_title"
}
],
"outputFieldMappings": []
}
تفعيل الاستعلامات
يمكنك بدء البحث بمجرد تحميل المستند الأول.
### Query the index
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
أرسل الطلب. هذا استعلام بحث نص كامل غير محدد يقوم بإرجاع كافة الحقول التي تم وضع علامة عليها على أنها قابلة للاسترداد في الفهرس، إلى جانب عدد المستندات. يجب أن تبدو الاستجابة كما يلي:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 712ca003-9493-40f8-a15e-cf719734a805
elapsed-time: 198
Date: Wed, 30 Apr 2025 23:20:53 GMT
Connection: close
{
"@odata.count": 100,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview "
}
يتم إرجاع 100 مستند في الاستجابة.
بالنسبة إلى عوامل التصفية، يمكنك أيضا استخدام عوامل التشغيل المنطقية (و، أو لا) وعوامل المقارنة (eq، ne، gt، lt، ge، le). مقارنات السلسلة حساسة لحالة الأحرف. لمزيد من المعلومات والأمثلة، راجع أمثلة استعلامات البحث البسيطة.
إشعار
تعمل المعلمة $filter فقط على الحقول التي تم وضع علامة عليها قابلة للتصفية أثناء إنشاء الفهرس.
فيما يلي بعض الأمثلة على الاستعلامات الأخرى:
### Query for only images
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true,
"filter": "image_document_id ne null"
}
### Query for text or images with content related to energy, returning the id, parent document, and text (extracted text for text chunks and verbalized image text for images), and the content path where the image is saved in the knowledge store (only populated for images)
POST {{baseUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-05-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "energy",
"count": true,
"select": "content_id, document_title, content_text, content_path"
}
إعادة تعيين وإعادة تشغيل
يمكن إعادة تعيين المفهرسات لمسح علامة المياه العالية، والتي تسمح بإعادة التشغيل الكامل. طلبات POST التالية لإعادة التعيين، متبوعة بإعادة التشغيل.
### Reset the indexer
POST {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/reset?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/run?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/doc-extraction-image-verbalization-indexer/status?api-version=2025-05-01-preview HTTP/1.1
api-key: {{apiKey}}
تنظيف الموارد
عندما تعمل في اشتراكك الخاص، في نهاية المشروع، من المستحسن إزالة الموارد التي لم تعد بحاجة إليها. الموارد المتبقية قيد التشغيل يمكن أن تكلفك المال. يمكنك حذف الموارد بشكل فردي أو حذف مجموعة الموارد لحذف تشكيلة الموارد بأكملها.
يمكنك استخدام مدخل Microsoft Azure لحذف الفهارس والمفهرسات ومصادر البيانات.
راجع أيضًا
الآن بعد أن أصبحت على دراية بتنفيذ نموذج لسيناريو فهرسة متعدد الوسائط، تحقق مما يلي: