البرنامج التعليمي: التقاط بيانات مراكز الأحداث بتنسيق parquet وتحليلها باستخدام Azure Synapse Analytics
يوضح لك هذا البرنامج التعليمي كيفية استخدام Stream Analytics بدون محرر تعليمات برمجية لإنشاء وظيفة تلتقط بيانات مراكز الأحداث في Azure Data Lake Storage Gen2 بتنسيق parquet.
في هذا البرنامج التعليمي، تتعلم كيفية:
- توزيع منشئ حدث يرسل أحداثا نموذجية إلى مركز أحداث
- قم بإنشاء وظيفة Stream Analytics باستخدام محرر من دون تعليمة برمجية
- مراجعة بيانات الإدخال والمخطط
- قم بتكوين Azure Data Lake Storage Gen2 الذي سيتم تسجيل بيانات مركز الحدث إليه
- تشغيل وظيفة Stream Analytics
- استخدم Azure Synapse Analytics للاستعلام عن ملفات Parquet
المتطلبات الأساسية
قبل أن تبدأ، تأكد من إكمال الخطوات التالية:
- إذا لم يكن لديك اشتراك في Azure، فأنشئ حساباً مجانياً.
- انشر تطبيق منشئ أحداث TollApp إلى Azure. قم بتعيين المعلمة "الفاصل الزمني" إلى 1، واستخدم مجموعة موارد جديدة لهذه الخطوة.
- أنشئ مساحة عمل Azure Synapse Analytics باستخدام حساب Data Lake Storage Gen2.
لا تستخدم أي محرر من دون تعليمة برمجية لإنشاء وظيفة Stream Analytics
حدد موقع مجموعة الموارد التي تم فيها توزيع منشئ أحداث TollApp.
حدد namespace في مراكز الأحداث.
في صفحة Event Hubs Namespace، حدد Event Hubs ضمن Entities في القائمة اليسرى.
حدد
entrystreaminstance.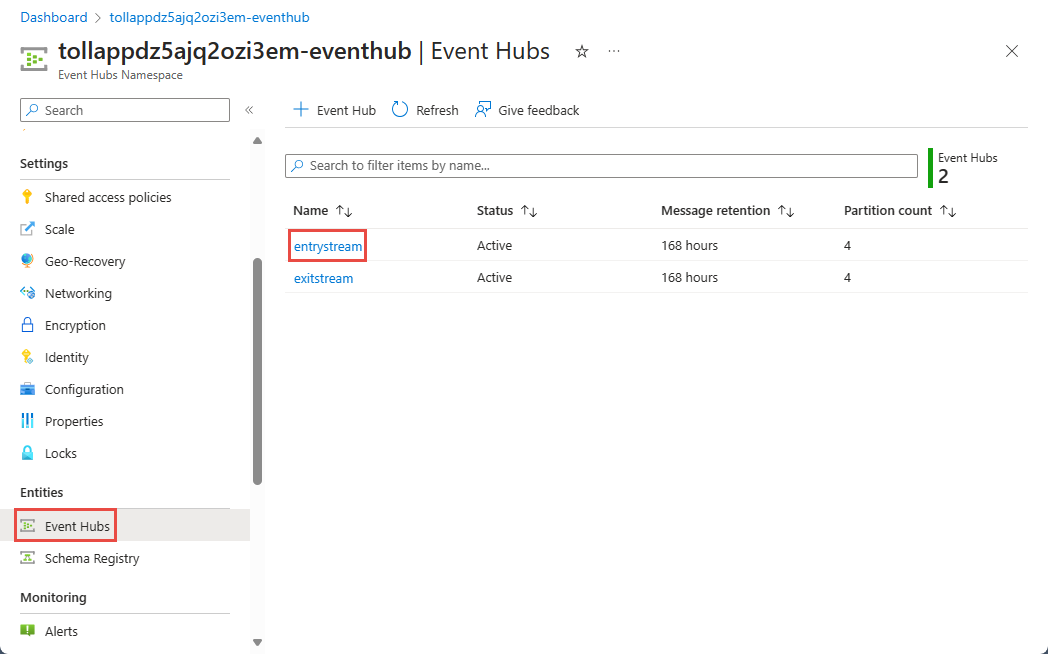
في صفحة Event Hubs instance، حدد Process data في قسم Features في القائمة اليسرى.
حدد Start في مربع تسجيل البيانات إلى ADLS Gen2 بتنسيق Parquet.
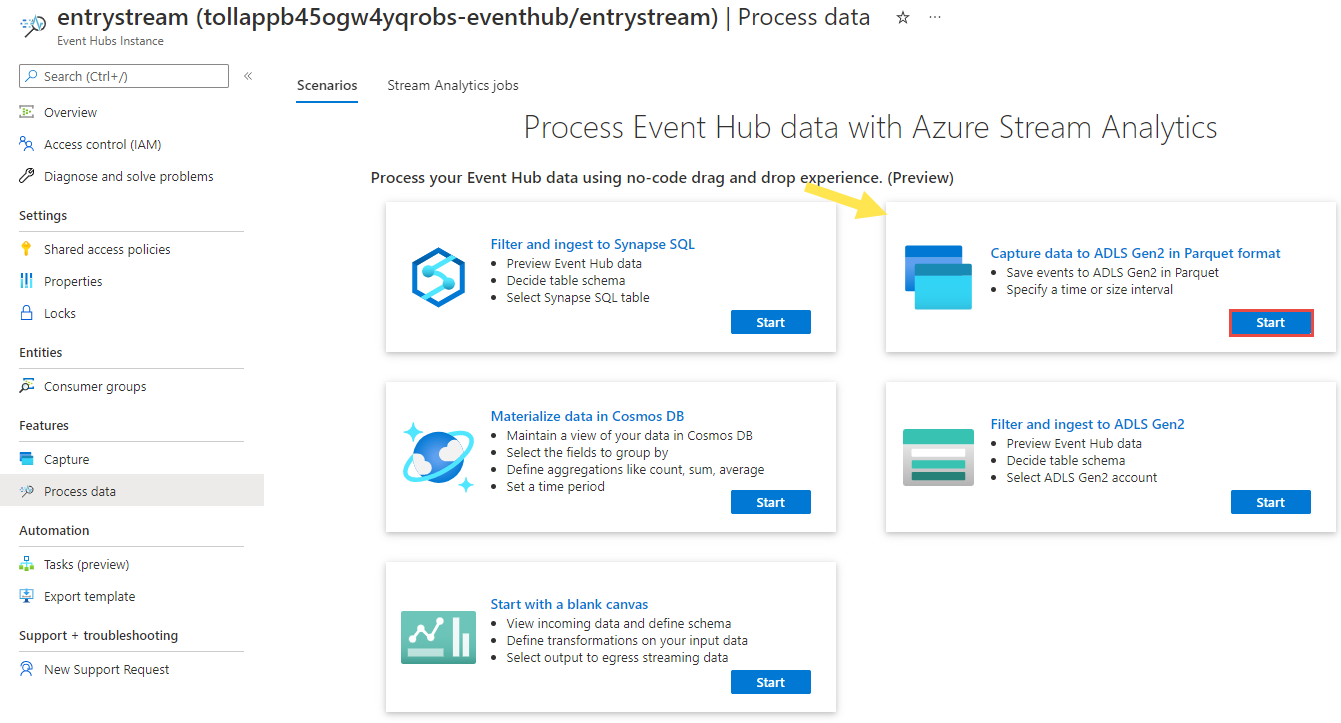
قم بتسمية وظيفتك
parquetcaptureوحدد إنشاء.
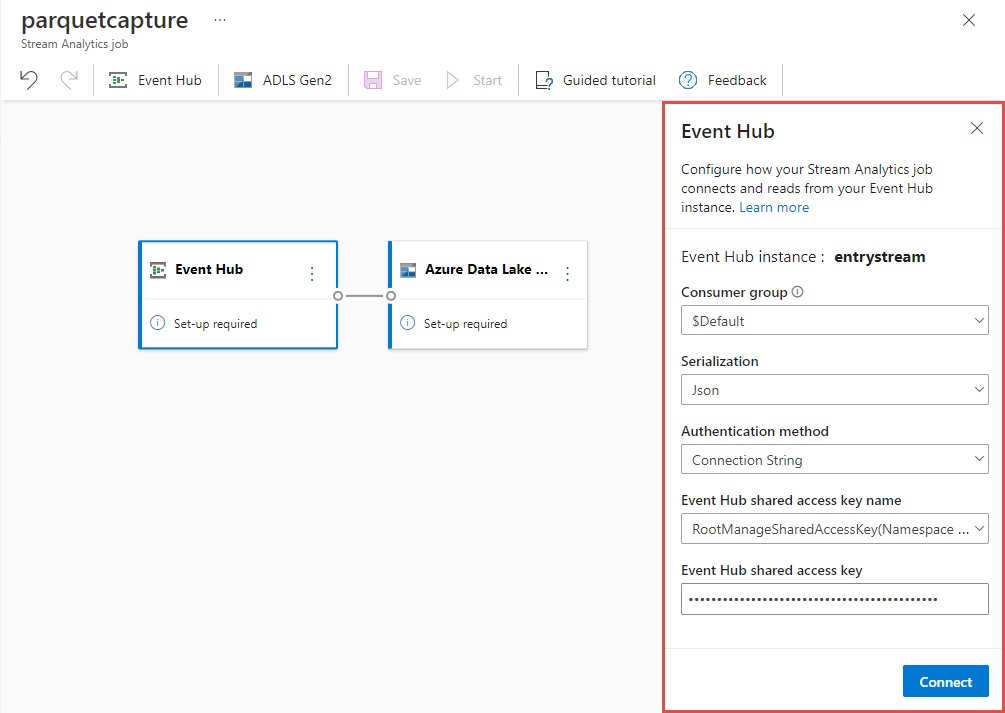
في صفحة تكوين event hub، قم بتأكيد الإعدادات التالية، ثم حدد Connect.
مجموعة المستهلكين: افتراضي
نوع التسلسل لبيانات الإدخال: JSON
وضع المصادقة الذي ستستخدمه المهمة للاتصال بمركز الأحداث: سلسلة الاتصال.
في غضون ثوانٍ قليلة، سترى عينة من بيانات الإدخال والمخطط. يمكنك اختيار إسقاط الحقول أو إعادة تسمية الحقول أو تغيير نوع البيانات.
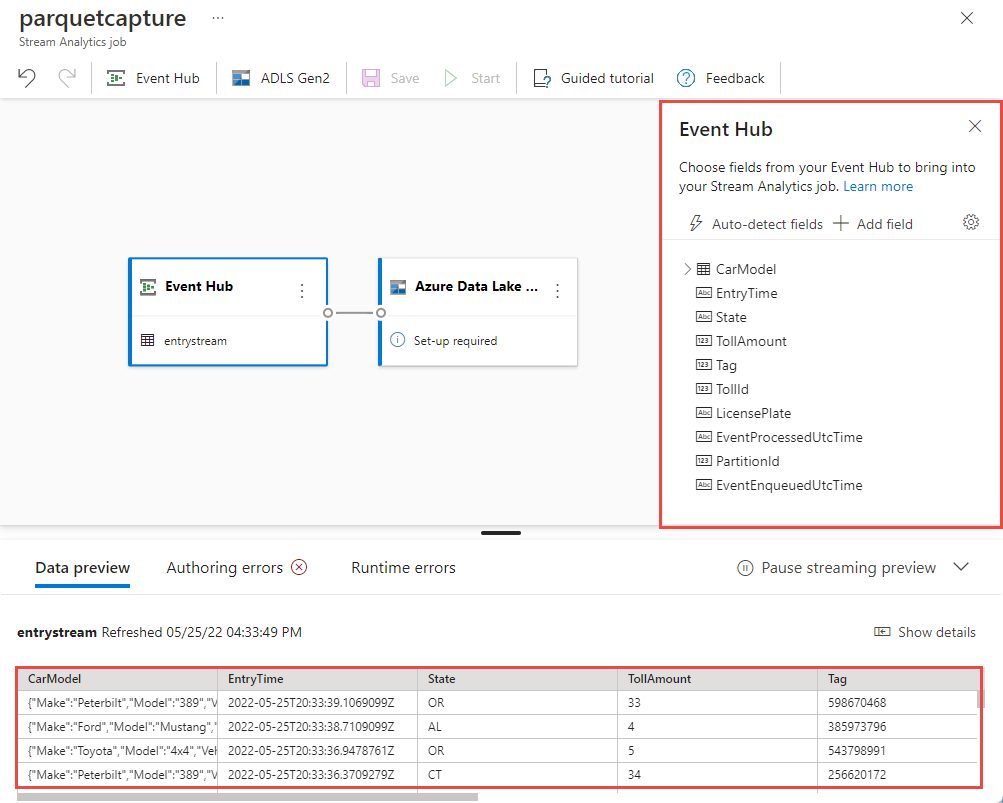
حدد لوحة Azure Data Lake Storage Gen2 على لوحتك وقم بتكوينها عن طريق التحديد
- الاشتراك حيث يوجد حساب Azure Data Lake Gen2 الخاص بك
- اسم حساب التخزين، والذي يجب أن يكون نفس حساب ADLS Gen2 المستخدم مع مساحة عمل Azure Synapse Analytics التي تم إجراؤها في قسم المتطلبات الأساسية.
- الحاوية التي سيتم إنشاء ملفات Parquet بداخلها.
- تم تعيين نمط المسار على {date}/{time}
- نمط التاريخ والوقت كنمط افتراضي yyyy-mm-dd وHH.
- اختر اتصال
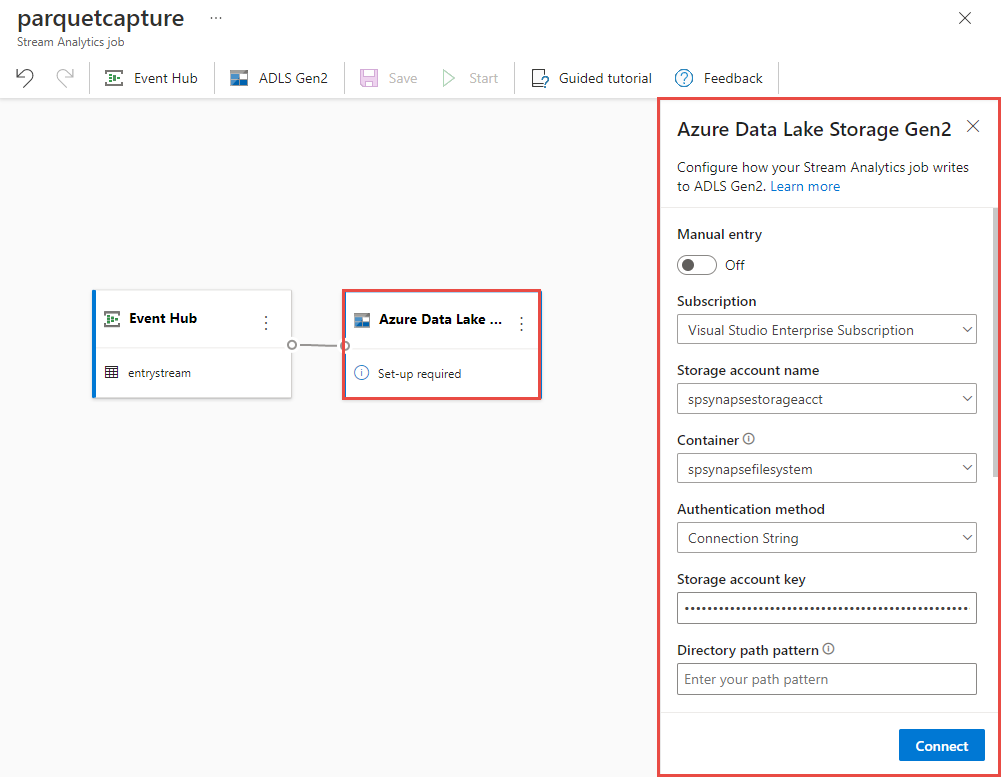
حدد حفظ في الشريط العلوي لحفظ وظيفتك، ثم حدد البدء لتشغيل وظيفتك. بمجرد بدء المهمة، حدد X في الزاوية اليمنى لإغلاق صفحة وظيفة Stream Analytics .
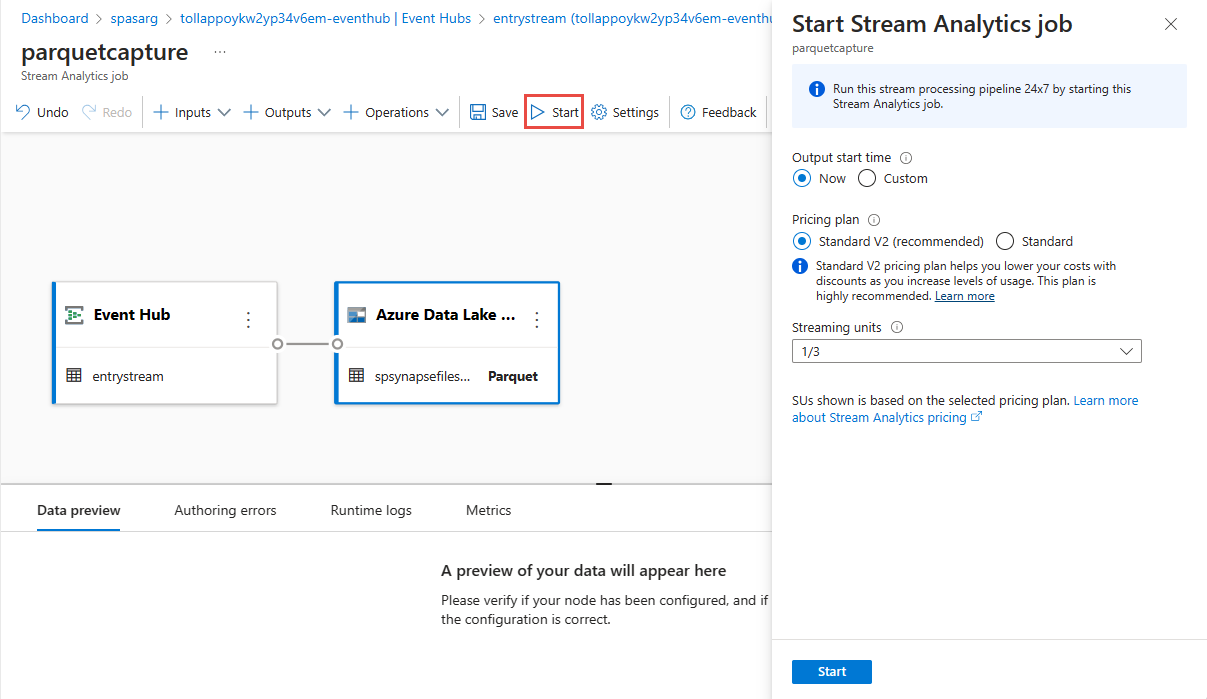
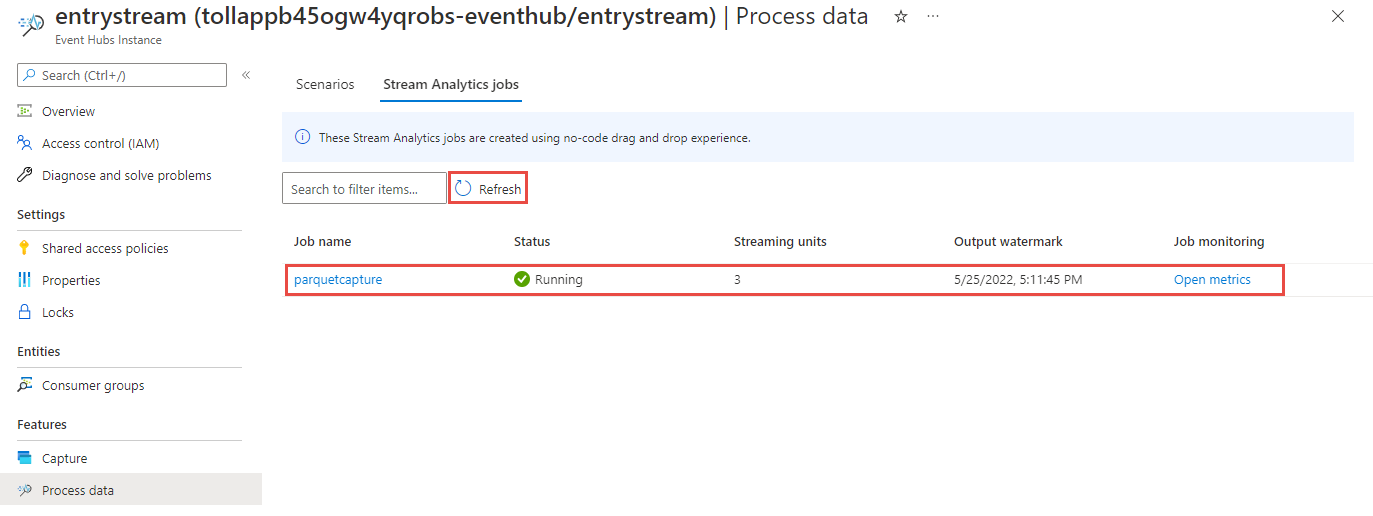
سترى بعد ذلك قائمة بجميع وظائف Stream Analytics التي تم إنشاؤها باستخدام محرر من دون تعليمة برمجية. وفي غضون دقيقتين، ستنتقل وظيفتك إلى الحالة Running. حدد الزر Refresh على الصفحة لمشاهدة الحالة المتغيرة من تم الإنشاء -> البدء -> قيد التشغيل.








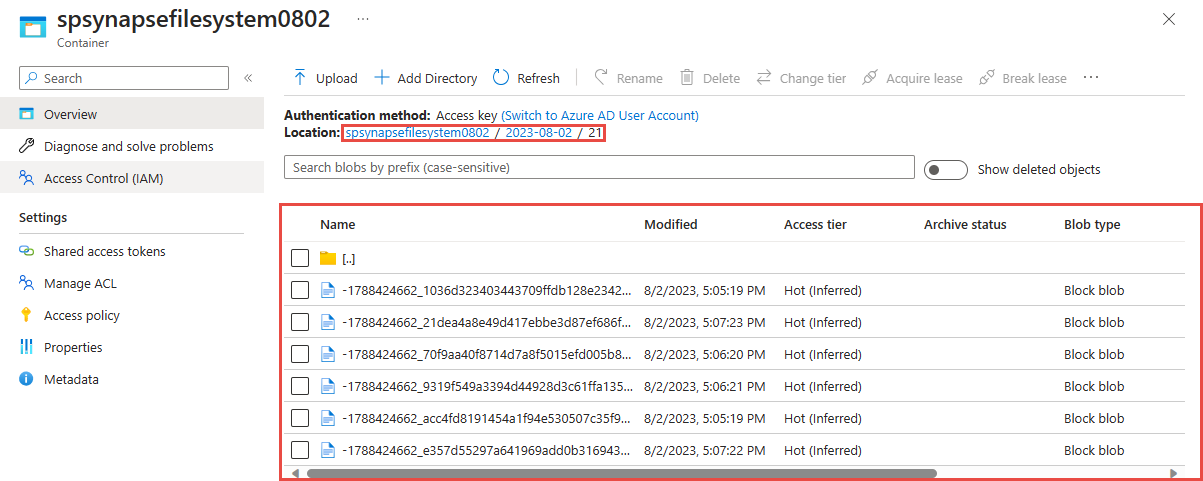
عرض الإخراج في حساب Azure Data Lake Storage Gen 2 الخاص بك
حدد موقع حساب Azure Data Lake Storage Gen2 الذي استخدمته في الخطوة السابقة.
حدد الحاوية التي استخدمتها في الخطوة السابقة. سترى ملفات Parquet تم إنشاؤها بناءً على نمط المسار {date}/{time} المستخدم في الخطوة السابقة.
تم تسجيل الاستعلام عن البيانات بتنسيق Parquet باستخدام Azure Synapse Analytics
الاستعلام باستخدام Azure Synapse Spark
حدد موقع مساحة عمل Azure Synapse Analytics وافتح إستوديو Synapse.
أنشئ تجمع Apache Spark من دون خادم في مساحة عملك إذا لم يكن موجوداً بالفعل.
في Synapse Studio، انتقل إلى مركز Develop وأنشئ Notebookجديداً.
قم بإنشاء خلية تعليمات برمجية جديدة والصق التعليمة البرمجية التالية في تلك الخلية. استبدل الحاوية وadlsname باسم الحاوية وحساب ADLS Gen2 المستخدم في الخطوة السابقة.
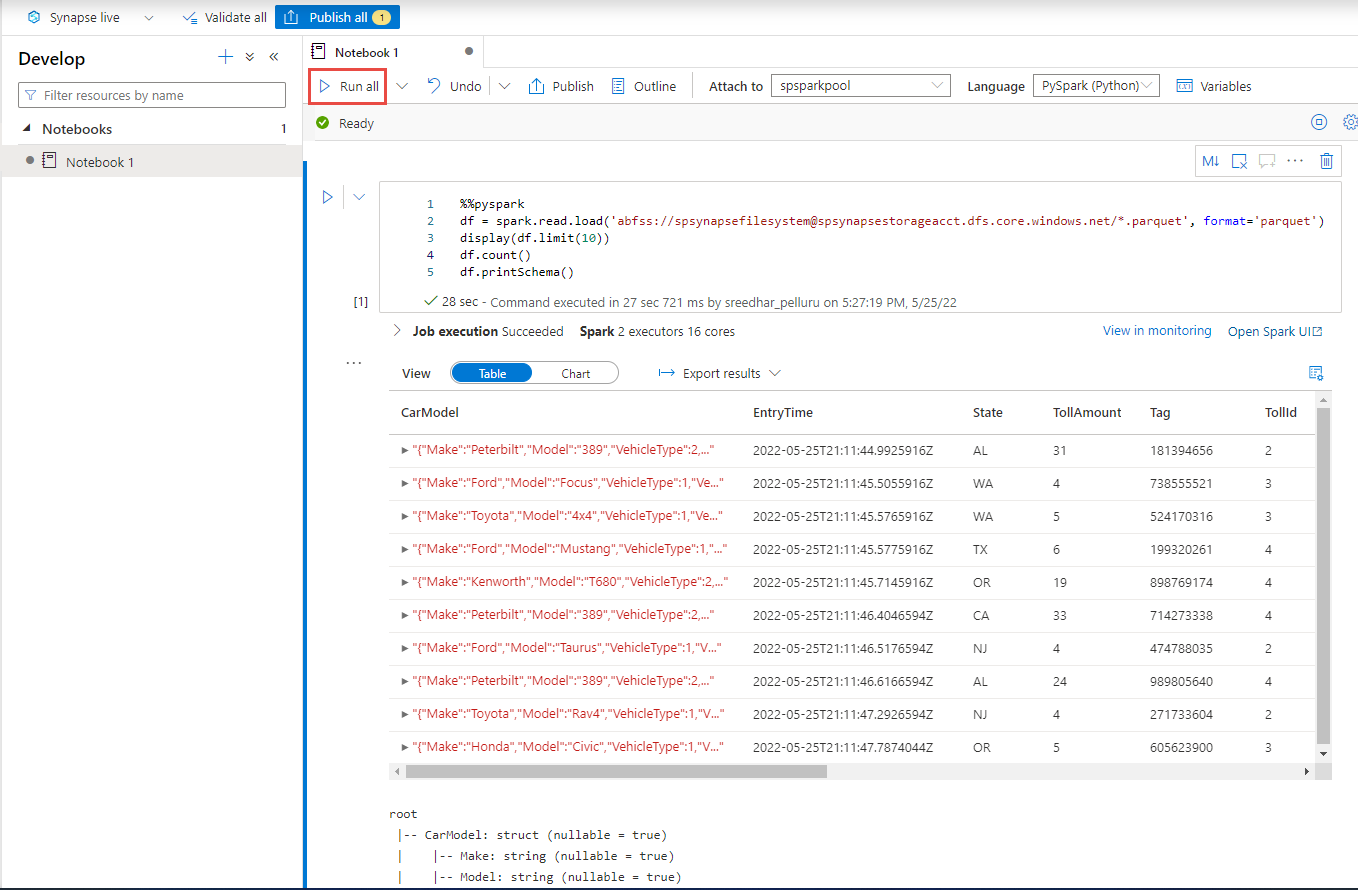
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()للإرفاق على شريط الأدوات، حدد تجمع Spark من القائمة المنسدلة.
حدد Run All لمشاهدة النتائج

الاستعلام باستخدام Azure Synapse من دون خادم SQL
في مركز Develop، قم بإنشاء برنامج نصي SQLجديد.
الصق النص البرمجي التالي وشغّله باستخدام نقطة نهاية SQL المضمنة من دون خادم. استبدل الحاوية وadlsname باسم الحاوية وحساب ADLS Gen2 المستخدم في الخطوة السابقة.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]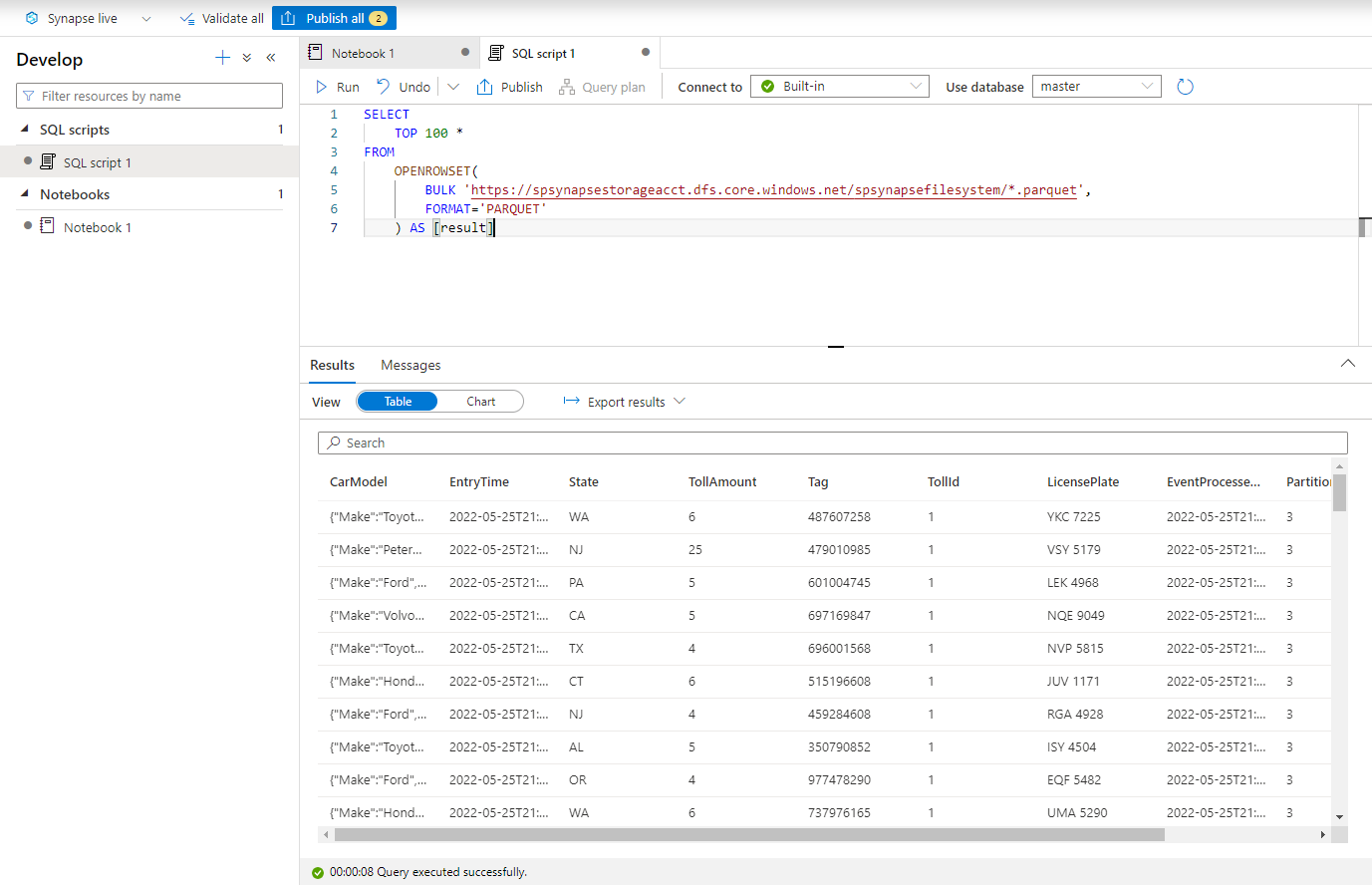

تنظيف الموارد
- حدد موقع مثيل مراكز الأحداث الخاص بك واطلع على قائمة وظائف Stream Analytics ضمن قسم Process Data. أوقف أي وظائف قيد التشغيل.
- انتقل إلى مجموعة الموارد التي استخدمتها أثناء توزيع منشئ أحداث TollApp.
- حدد Delete resource group. اكتب اسم مجموعة الموارد لتأكيد الحذف.
الخطوات التالية
في هذا البرنامج التعليمي، تعلمت كيفية إنشاء وظيفة Stream Analytics باستخدام محرر من دون تعليمة برمجية لتسجيل تدفقات بيانات مراكز الأحداث بتنسيق Parquet. ثم استخدمت Azure Synapse Analytics للاستعلام عن ملفات Parquet باستخدام كل من Synapse Spark وSynapse SQL.