ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
هذه المقالة هي الجزء الثاني من سلسلة الأجزاء السبعة التي توفر إرشادات حول كيفية الترحيل من Oracle إلى Azure Synapse Analytics. توفر هذه المقالة أفضل الممارسات لـ ETL وترحيل التحميل.
اعتبارات ترحيل البيانات
هناك العديد من العوامل التي يجب مراعاتها عند ترحيل البيانات وETL والأحمال من مستودع بيانات Oracle القديم ومخازن البيانات إلى Azure Synapse.
القرارات الأولية حول ترحيل البيانات من Oracle
عند التخطيط للترحيل من بيئة Oracle موجودة، ضع في اعتبارك الأسئلة التالية المتعلقة بالبيانات:
هل يجب ترحيل بنيات الجدول غير المُستخدَمة؟
ما هو أفضل نهج ترحيل لتقليل المخاطر والتأثير للمستخدمين؟
عند ترحيل متجر البيانات: هل تريد البقاء فعليًا أو الانتقال إلى الإصدار الظاهري؟
تناقش الأقسام التالية هذه النقاط في سياق الترحيل من Oracle.
هل تريد ترحيل الجداول غير المُستخدَمة؟
من المنطقي ترحيل الجداول المُستخدَمة. يمكن أرشفة الجداول غير النشطة بدلاً من ترحيلها، بحيث تتوفر البيانات إذا استلزم الأمر في المستقبل. من الأفضل استخدام بيانات تعريف النظام وملفات السجل بدلاً من الوثائق لتحديد الجداول المُستخدَمة، لأن الوثائق يمكن أن تكون قديمة.
كتالوج نظام Oracle تحتوي على معلومات يمكن استخدامها لتحديد وقت آخر وصول إلى جدول معين - والتي يمكن استخدامها بدورها لتحديد ما إذا كان الجدول مرشحاً للترحيل من عدمه.
إذا قمت بترخيص Oracle Diagnostic Pack، فسيكون لديك حق الوصول إلى محفوظات جلسة العمل النشطة، والتي يمكنك استخدامها لتحديد وقت آخر وصول إلى جدول.
تلميح
في الأنظمة القديمة، ليس من غير المعتاد أن تصبح الجداول زائدة عن الحاجة بمرور الوقت - لا تحتاج إلى ترحيلها في معظم الحالات.
فيما يلي مثال استعلام يبحث عن استخدام جدول معين ضمن فترة زمنية معينة:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
قد يستغرق تشغيل هذا الاستعلام بعض الوقت إذا كنت تقوم بتشغيل العديد من الاستعلامات.
ما هو أفضل نهج ترحيل لتقليل المخاطر وتأثير المستخدم؟
يظهر هذا السؤال في كثير من الأحيان لأن الشركات قد ترغب في تقليل تأثير التغييرات على نموذج بيانات مستودع البيانات لتحسين السرعة. غالبا ما ترى الشركات فرصة لزيادة تحديث بياناتها أو تحويلها أثناء ترحيل ETL. ويحمل هذا النهج مخاطرة أكبر لأنه يغير عوامل متعددة في وقت واحد، مما يجعل من الصعب مقارنة نتائج النظام القديم مقابل الجديد. قد يؤثر إجراء تغييرات في نموذج البيانات هنا أيضا على وظائف ETL المصدر أو انتقال البيانات من الخادم إلى أنظمة أخرى. وبسبب هذا الخطر، من الأفضل عادة إعادة التصميم على هذا المقياس بعد ترحيل مستودع البيانات.
حتى إذا تم تغيير نموذج البيانات عن قصد كجزء من الترحيل الكلي، فمن الممارسات الجيدة ترحيل النموذج الحالي كما هو إلى Azure Synapse، بدلا من إجراء أي إعادة هندسة على النظام الأساسي الجديد. يقلل هذا النهج من التأثير على أنظمة الإنتاج الحالية، مع الاستفادة من الأداء وقابلية التوسع المرنة لنظام Azure الأساسي لمهام إعادة الهندسة لمرة واحدة.
تلميح
يمكنك ترحيل النموذج الحالي كما هو في البداية، حتى إذا كان من المخطط إجراء تغيير على نموذج البيانات في المستقبل.
ترحيل مخزن البيانات: البقاء ماديًا أو الانتقال إلى الظاهرية؟
في بيئات مستودع بيانات Oracle القديمة، من الشائع إنشاء العديد من متاجر البيانات المنظمة لتوفير أداء جيد لاستعلامات وتقارير الخدمة الذاتية المخصصة لقسم معين أو وظيفة عمل داخل مؤسسة. يتكون متجر البيانات عادةً من مجموعة فرعية من مستودع البيانات ويحتوي على إصدارات مجمّعة من البيانات في نموذج يمكّن المستخدمين من الاستعلام بسهولة عن تلك البيانات بأوقات استجابة سريعة. يمكن للمستخدمين استخدام أدوات استعلام سهلة الاستخدام مثل Microsoft Power BI، والتي تدعم تفاعلات مستخدم الأعمال مع قوالب البيانات. شكل البيانات في مخزن البيانات هو بشكل عام نموذج بيانات الأبعاد. أحد استخدامات متاجر البيانات هو كشف البيانات في شكل قابل للاستخدام، حتى لو كان نموذج بيانات المستودع الأساسي مختلفاً، مثل مخزن البيانات.
يمكنك استخدام مارت بيانات منفصلة لوحدات الأعمال الفردية داخل المؤسسة لتنفيذ أنظمة أمان البيانات القوية. تقييد الوصول إلى الأسواق الخاصة بالبيانات ذات الصلة للمستخدمين، وإزالة البيانات الحساسة أو تعتيمها أو تحجبها.
إذا تم تنفيذ متاجر البيانات هذه كجداول فعلية، فستتطلب موارد تخزين إضافية ومعالجة لإنشائها وتحديثها بانتظام. أيضًا، ستكون البيانات في المتجر محدثة فقط مثل عملية التحديث الأخيرة، وبالتالي قد تكون غير مناسبة للوحات معلومات البيانات المتقلبة للغاية.
تلميح
يمكن أن يوفر إضفاء الطابع الظاهري على متاجر البيانات موارد التخزين والمعالجة.
مع ظهور بنيات MPP القابلة للتطوير ومنخفضة التكلفة، مثل Azure Synapse، وخصائص الأداء المتأصلة، بإمكانك توفير وظائف متجر البيانات دون الحاجة إلى إنشاء مثيل للمتجر كمجموعة من الجداول الفعلية. إحدى الطرق هي المحاكاة الظاهرية لمخازن البيانات بشكل فعال عبر طرق عرض SQL في مستودع البيانات الرئيسي. طريقة أخرى هي المحاكاة الظاهرية لمارت البيانات عبر طبقة ظاهرية باستخدام ميزات مثل طرق العرض في منتجات المحاكاة الظاهرية لـ Azure أو الجهات الخارجية. يبسط هذا النهج الحاجة إلى التخزين الإضافي ومعالجة التجميع أو يلغيه ويقلل من العدد الإجمالي لكائنات قاعدة البيانات التي سيتم ترحيلها.
وهناك فائدة محتملة أخرى لهذا النهج. من خلال تنفيذ منطق التجميع والربط داخل طبقة ظاهرية، وتقديم أدوات إعداد التقارير الخارجية عبر طريقة عرض ظاهرية، يتم دفع المعالجة المطلوبة لإنشاء طرق العرض هذه إلى مستودع البيانات. مستودع البيانات هو عموما أفضل مكان لتشغيل الصلات والتجميعات والعمليات الأخرى ذات الصلة على وحدات تخزين البيانات الكبيرة.
برامج تشغيل الأجهزة الأساسية لتنفيذ متجر بيانات ظاهري عبر متجر بيانات فعلي هي:
مزيد من السرعة: من الأسهل تغيير متجر البيانات الظاهرية من الجداول الفعلية وعمليات استخراج وتحويل وتحميل مقترنة.
التكلفة الإجمالية المنخفضة للتملك: يتطلب التنفيذ الظاهري عدداً أقل من مخازن البيانات ونسخ البيانات.
إلغاء وظائف استخراج وتحويل وتحميل لترحيل وتبسيط بنية مستودع البيانات في بيئة ظاهرية.
الأداء: على الرغم من أن متاجر البيانات الفعلية كانت أفضل أداء تاريخياً، فإن منتجات الظاهرية تنفذ الآن تقنيات التخزين المؤقت الذكية للتخفيف من حدة هذا الاختلاف.
تلميح
يتيح أداء Azure Synapse وقابليته للتوسع الظاهرية دون التأثير على الأداء.
ترحيل البيانات من Oracle
فهم بياناتك
كجزء من التخطيط للترحيل، عليك فهم حجم البيانات التي يجب ترحيلها بالتفصيل لأن ذلك يمكن أن يؤثر على القرارات المتعلقة بنهج الترحيل. استخدم بيانات تعريف النظام لتحديد المساحة الفعلية التي تأخذها "البيانات الأولية" داخل الجداول المُراد ترحيلها. في هذا السياق، تعني البيانات الأولية مقدار المساحة المُستخدَمة من قبل صفوف البيانات داخل جدول، باستثناء الأحمال الإضافية مثل الفهارس والملفات المضغوطة. أكبر جداول الحقائق ستتضمن عادة أكثر من 95% من البيانات.
سيعطيك هذا الاستعلام إجمالي حجم قاعدة البيانات في Oracle:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
حجم قاعدة البيانات يساوي حجم (data files + temp files + online/offline redo log files + control files). يتضمن الحجم الإجمالي لقاعدة البيانات المساحة المستخدمة والمساحة الحرة.
يعطي استعلام المثال التالي تصنيفًا لمساحة القرص المستخدمة بواسطة بيانات الجدول والفهارس:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
بالإضافة إلى ذلك، يوفر فريق ترحيل قاعدة بيانات Microsoft العديد من الموارد، بما في ذلك Oracle Inventory Script Artifacts. تتضمن أداة Oracle Inventory Script Artifacts استعلام PL / SQL الذي يصل إلى جداول نظام Oracle، ويوفر عددًا من الكائنات حسب نوع المخطط ونوع الكائن والحالة. كما توفر الأداة تقديرًا تقريبيًا للبيانات الأولية في كل مخطط، وحجم الجداول في كل مخطط، مع تخزين النتائج في تنسيق CSV. يأخذ جدول بيانات الحاسبة المضمن CSV كإدخال ويوفر بيانات تغيير الحجم.
بالنسبة لأي جدول، يمكنك تقدير حجم البيانات التي تحتاج إلى ترحيل بدقة عن طريق استخراج عينة تمثيلية من البيانات، مثل مليون صف، إلى ملف بيانات ASCII ثابت غير مضغوط. ثم استخدم حجم هذا الملف للحصول على متوسط حجم البيانات الأولية لكل صف. وأخيرًا، اضرب هذا الحجم المتوسط في العدد الإجمالي للصفوف في الجدول الكامل لإعطاء حجم بيانات أولي للجدول. استخدم حجم البيانات الأولية هذا في تخطيطك.
استخدام استعلامات SQL للبحث عن أنواع البيانات
من خلال الاستعلام عن طريقة عرض قاموس البيانات الثابتة DBA_TAB_COLUMNS لـ Oracle، يمكنك تحديد أنواع البيانات المستخدمة في المخطط وما إذا كان أي من أنواع البيانات هذه بحاجة إلى تغيير. استخدم استعلامات SQL للعثور على الأعمدة في أي مخطط Oracle مع أنواع البيانات التي لا تعين مباشرة إلى أنواع البيانات في Azure Synapse. وبالمثل، يمكنك استخدام الاستعلامات لحساب عدد مرات حدوث كل نوع بيانات Oracle لا يتم تعيينه مباشرة إلى Azure Synapse. باستخدام النتائج من هذه الاستعلامات بالاقتران مع جدول مقارنة نوع البيانات، يمكنك تحديد أنواع البيانات التي يجب تغييرها في بيئة Azure Synapse.
للعثور على الأعمدة التي تحتوي على أنواع بيانات لا يتم تعيينها إلى أنواع البيانات في Azure Synapse، قم بتشغيل الاستعلام التالي بعد استبدال <owner_name> بمالك المخطط ذي الصلة:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
لحساب عدد أنواع البيانات غير القابلة للتطبيق، استخدم الاستعلام التالي:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
تقدم Microsoft SQL Server Migration Assistant (SSMA) لـ Oracle لأتمتة ترحيل مستودعات البيانات من بيئات Oracle القديمة، بما في ذلك تعيين أنواع البيانات. يمكنك أيضًا استخدام Azure Database Migration Services للمساعدة في تخطيط وتنفيذ الترحيل من بيئات مثل Oracle. كما يقدم موردو الجهات الخارجية أدوات وخدمات لأتمتة الترحيل. إذا كانت أداة ETL تابعة لجهة خارجية قيد الاستخدام بالفعل في بيئة Oracle، يمكنك استخدام هذه الأداة لتنفيذ أي تحويلات بيانات مطلوبة. يستكشف القسم التالي ترحيل عمليات ETL الحالية.
اعتبارات ترحيل استخراج وتحويل وتحميل
القرارات الأولية حول ترحيل Oracle ETL
لمعالجة ETL/ELT، غالبا ما تستخدم مستودعات بيانات Oracle القديمة برامج نصية مخصصة، أو أدوات ETL تابعة لجهة خارجية، أو مجموعة من الأساليب التي تطورت بمرور الوقت. عند التخطيط للترحيل إلى Azure Synapse، يجب تحديد أفضل طريقة لتنفيذ معالجة ETL/ELT المطلوبة في البيئة الجديدة مع تقليل التكلفة والمخاطر.
تلميح
خطط نهج ترحيل ETL مسبقًا واستفد من مرافق Azure عند الاقتضاء.
يلخص المخطط الانسيابي التالي نهجاً واحداً:
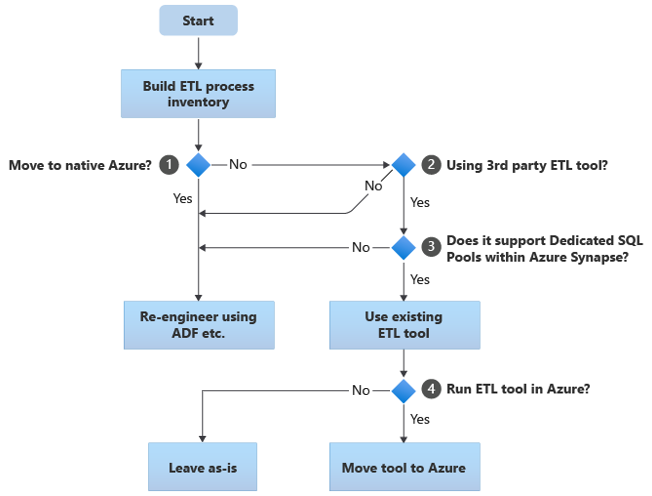
كما هو موضح في المخطط الانسيابي، فإن الخطوة الأولية هي دائما إنشاء مخزون من عمليات ETL/ELT التي تحتاج إلى ترحيل. مع ميزات Azure المضمنة القياسية، قد لا تحتاج بعض العمليات الموجودة إلى النقل. لأغراض التخطيط، من المهم فهم حجم الترحيل. بعد ذلك، ضع في اعتبارك الأسئلة في شجرة قرارات المخطط الانسيابي:
الانتقال إلى Azure الأصلي؟ تعتمد إجابتك على ما إذا كنت تقوم بالترحيل إلى بيئة أصلية تماما في Azure. إن كان الأمر كذلك، نوصي بإعادة هندسة معالجة ETL باستخدام البنية الأساسية والأنشطة في Azure Data Factory أو البنية الأساسية لـ Azure Synapse.
استخدام أداة ETL تابعة لجهة خارجية؟ إذا كنت لا تنتقل إلى بيئة أصلية تمامًا في Azure، فإن الفحص هو ما إذا كانت أداة ETL موجودة تابعة لجهة خارجية قيد الاستخدام بالفعل. في بيئة Oracle، قد تجد أن بعض أو كل معالجة ETL يتم تنفيذها بواسطة برامج نصية مخصصة باستخدام أدوات مساعدة خاصة بـ Oracle مثل Oracle SQL Developer أو Oracle SQL*Loader أو Oracle Data Pump. النهج في هذه الحالة هو إعادة الهندسة باستخدام Azure Data Factory.
هل تدعم الجهات الخارجية تجمعات SQL المخصصة داخل Azure Synapse؟ ضع في اعتبارك ما إذا كان هناك استثمار كبير في المهارات في أداة ETL التابعة لجهة خارجية، أو إذا كانت مهام سير العمل والجدول الزمني الحالية تستخدم هذه الأداة. إذا كان الأمر كذلك، فحدد ما إذا كانت الأداة يمكنها دعم Azure Synapse بكفاءة كبيئة مستهدفة. من الناحية المثالية، ستتضمن الأداة موصلات "أصلية" يمكنها استخدام مرافق Azure مثل PolyBase أو COPY INTO، لتحميل البيانات الأكثر كفاءة. ولكن حتى بدون الموصلات الأصلية، هناك بشكل عام طريقة يمكنك من خلالها استدعاء العمليات الخارجية، مثل PolyBase أو
COPY INTO، وتمرير المعلمات القابلة للتطبيق. في هذه الحالة، استخدم المهارات الحالية وسير العمل، باستخدام Azure Synapse كبيئة مستهدفة جديدة.إذا كنت تستخدم Oracle Data Integrator (ODI) لمعالجة ELT، فأنت بحاجة إلى وحدات معرفات ODI لـ Azure Synapse. إذا لم تكن هذه الوحدات النمطية متوفرة لك في مؤسستك، ولكن لديك ODI، فيمكنك استخدام ODI لإنشاء ملفات مسطحة. يمكن بعد ذلك نقل هذه الملفات المسطحة إلى Azure واستيعابها في Azure Data Lake Storage للتحميل في Azure Synapse.
تشغيل أدوات ETL في Azure؟ إذا قررت الاحتفاظ بأداة ETL الحالية التابعة لجهة خارجية، يمكنك تشغيل هذه الأداة داخل بيئة Azure (بدلاً من الاحتفاظ بخادم ETL محلي حالي) وامتلاك Data Factory يعالج التنسيق العام لسير العمل الحالية. لذلك، عليك التقرير ما إذا كنت تريد ترك الأداة الحالية تعمل كما هي أو نقلها إلى بيئة Azure لتحقيق مزايا التكلفة والأداء وقابلية التوسع.
تلميح
ضع في اعتبارك تشغيل أدوات ETL في Azure للاستفادة من الأداء وقابلية التوسع وفوائد التكلفة.
إعادة هندسة البرامج النصية الحالية الخاصة بـ Oracle
إذا تمت معالجة بعض أو كل معالجة مستودع Oracle ETL/ELT الحالية بواسطة برامج نصية مخصصة تستخدم أدوات مساعدة خاصة بـ Oracle، مثل Oracle SQL*Plus أو Oracle SQL Developer أو Oracle SQL*Loader أو Oracle Data Pump، فأنت بحاجة إلى إعادة ترميز هذه البرامج النصية لبيئة Azure Synapse. وبالمثل، إذا تم تنفيذ عمليات ETL باستخدام الإجراءات المخزنة في Oracle، فأنت بحاجة إلى إعادة ترميز هذه العمليات.
من السهل ترحيل بعض عناصر عملية ETL، على سبيل المثال عن طريق تحميل البيانات المجمّعة البسيطة إلى جدول مرحلي من ملف خارجي. قد يكون من الممكن حتى أتمتة هذه الأجزاء من العملية، على سبيل المثال، باستخدام Azure Synapse COPY INTO أو PolyBase بدلاً من SQL*Loader. ستستغرق الأجزاء الأخرى من العملية التي تحتوي على SQL المعقدة العشوائية و/أو الإجراءات المخزّنة مزيداً من الوقت لإعادة التصميم.
تلميح
يجب أن يتضمن مخزون مهام استخراج وتحويل وتحميل التي سيتم ترحيلها البرامج النصية والإجراءات المخزّنة.
إحدى طرق اختبار Oracle SQL للتوافق مع Azure Synapse هي التقاط بعض عبارات SQL التمثيلية من صلة Oracle v$active_session_history وv$sql للحصول على sql_text، ثم بادئة هذه الاستعلامات مع EXPLAIN. بافتراض نموذج بيانات تم ترحيله في Azure Synapse، قم بتشغيل عبارات EXPLAIN في Azure Synapse. ستعطي أي لغة الاستعلامات المركبة غير متوافقة خطأ. يمكنك استخدام هذه المعلومات لتحديد تغيير حجم مهمة إعادة الترميز.
تلميح
استخدم EXPLAIN للعثور على عدم توافق SQL.
في أسوأ الحالات، قد يكون من الضروري إعادة الترميز اليدوي. ومع ذلك، هناك منتجات وخدمات متاحة من شركاء Microsoft للمساعدة في إعادة هندسة التعليمات البرمجية الخاصة بـ Oracle.
تلميح
يقدم الشركاء منتجات ومهارات للمساعدة في إعادة هندسة التعليمات البرمجية الخاصة بـ Oracle.
استخدام أدوات ETL التابعة لجهة خارجية موجودة
سيتم بالفعل ملء نظام مستودع البيانات القديمة الحالي وصيانته من قبل منتج ETL التابع لجهة خارجية. راجع شركاء تكامل بيانات Azure Synapse Analytics للحصول على قائمة بشركاء تكامل بيانات Microsoft الحاليين لـ Azure Synapse.
يستخدم مجتمع Oracle في كثير من الأحيان العديد من منتجات ETL الشائعة. تناقش الفقرات التالية أدوات ETL الأكثر شيوعًا لمستودعات Oracle. يمكنك تشغيل جميع هذه المنتجات داخل جهاز ظاهري في Azure واستخدامها لقراءة قواعد بيانات Azure وملفاتها وكتابتها.
تلميح
يمكنك الاستفادة من الاستثمار في أدوات الجهات الخارجية الحالية لتقليل التكلفة والمخاطر.
تحميل البيانات من Oracle
الخيارات المتوفرة عند تحميل البيانات من Oracle
عندما تحضر لنقل بيانات مستودع البيانات Oracle، عليك تحديد كيفية نقل البيانات فعلياً من البيئة المحلية الحالية إلى Azure Synapse في السحابة، والأدوات التي سيتم استخدامها لإجراء عمليتي النقل والتحميل. ضع في اعتبارك الأسئلة التالية، التي تمت مناقشتها في الأقسام التالية.
هل ستقوم باستخراج البيانات إلى الملفات، أو نقلها مباشرة عبر اتصال شبكة؟
هل ستنسق العملية من النظام المصدر، أو من بيئة هدف Azure؟
ما هي الأدوات التي ستستخدمها لأتمتة عملية النقل وإدارتها؟
هل تريد نقل البيانات عبر الملفات أو اتصال الشبكة؟
بعد إنشاء جداول قاعدة البيانات المُراد ترحيلها في Azure Synapse، يمكنك نقل البيانات لتعبئة هذه الجداول خارج نظام Oracle القديم وإلى البيئة الجديدة. هناك نهجان أساسيان للذكاء الاصطناعي:
استخراج الملفات: استخراج البيانات من جداول Oracle إلى ملفات محددة مسطحة، عادة بتنسيق CSV. يمكنك استخراج بيانات الجدول بعدة طرق:
- استخدم أدوات Oracle القياسية مثل SQL*Plus وSQL Developer وSQLcl.
- استخدم Oracle Data Integrator (ODI) لإنشاء ملفات مسطحة.
- استخدم موصل Oracle في Data Factory لتفريغ جداول Oracle بالتوازي لتمكين تحميل البيانات حسب الأقسام.
- استخدام أدوات ETL التابعة لجهة خارجية.
للحصول على أمثلة حول كيفية استخراج بيانات جدول Oracle، راجع ملحق المقالة.
يتطلب هذا الأسلوب مساحة للوصول إلى ملفات البيانات المستخرجة. يمكن أن تكون المساحة محلية في قاعدة بيانات مصدر Oracle إذا كان التخزين الكافي متوفراً، أو عن بُعد في Azure Blob Storage. يتم تحقيق أفضل أداء عند كتابة ملف محلياً، لأن ذلك يتجنب زيادة الحمل على الشبكة.
لتقليل متطلبات التخزين ونقل الشبكة، عليك ضغط ملفات البيانات المستخرجة باستخدام أداة مساعدة مثل gzip.
بعد الاستخراج، انقل الملفات المسطحة إلى Azure Blob Storage. توفر Microsoft خيارات مختلفة لنقل كميات كبيرة من البيانات، بما في ذلك:
- AzCopy لنقل الملفات عبر الشبكة إلى Azure Storage.
- Azure ExpressRoute لنقل البيانات المجمعة عبر اتصال شبكة خاصة.
- Azure Data Box لنقل الملفات إلى جهاز تخزين فعلي تقوم بشحنه إلى مركز بيانات Azure لتحميله.
لمزيد من المعلومات، راجع نقل البيانات من وإلى تطبيق Azure.
الاستخراج والتحميل المباشر عبر الشبكة: ترسل بيئة Azure الهدف طلب استخراج البيانات، عادةً عبر أمر SQL، إلى نظام Oracle القديم لاستخراج البيانات. يتم إرسال النتائج عبر الشبكة وتحميلها مباشرة في Azure Synapse، دون الحاجة إلى نقل البيانات إلى ملفات وسيطة. العامل المحدد في هذا السيناريو هو عادة النطاق الترددي لاتصال الشبكة بين قاعدة بيانات Oracle وبيئة Azure. بالنسبة لأحجام البيانات الكبيرة بشكل استثنائي، قد لا يكون هذا النهج عملياً.
تلميح
يمكنك فهم وحدات تخزين البيانات التي سيتم ترحيلها وعرض النطاق الترددي للشبكة المتاح لأن هذه العوامل تؤثر على قرار نهج الترحيل.
هناك أيضًا نهج مختلط يستخدم كلا الأسلوبين. على سبيل المثال، يمكنك استخدام نهج استخراج الشبكة المباشرة لجداول الأبعاد الأصغر وعينات جداول الحقائق الأكبر لتوفير بيئة اختبار بسرعة في Azure Synapse. بالنسبة إلى جداول الحقائق التاريخية الكبيرة الحجم، يمكنك استخدام نهج استخراج الملفات ونقلها باستخدام Azure Data Box.
هل تنسق من Oracle أو Azure؟
النهج الموصى به عند الانتقال إلى Azure Synapse هو تنسيق استخراج البيانات وتحميلها من بيئة Azure باستخدام SSMA أو Data Factory. استخدم الأدوات المساعدة المقترنة، مثل PolyBase أو COPY INTO، لتحميل البيانات الأكثر كفاءة. يستفيد هذا النهج من قدرات Azure المضمنة ويقلل من الجهد المبذول لإنشاء مسارات تحميل بيانات قابلة لإعادة الاستخدام. يمكنك استخدام مسارات تحميل البيانات المستندة إلى بيانات التعريف لأتمتة عملية الترحيل.
يقلل النهج الموصى به أيضا من الأداء على بيئة Oracle الحالية أثناء عملية تحميل البيانات، لأن عملية الإدارة والتحميل تعمل في Azure.
أدوات ترحيل البيانات الموجودة
تحويل البيانات وحركتها هي الوظيفة الأساسية لجميع منتجات ETL. إذا كانت أداة ترحيل البيانات قيد الاستخدام بالفعل في بيئة Oracle الحالية وتدعم Azure Synapse كبيئة مستهدفة، ففكر في استخدام هذه الأداة لتبسيط ترحيل البيانات.
حتى إذا لم تكن أداة ETL موجودة، فإن شركاء تكامل بيانات Azure Synapse Analytics يقدمون أدوات ETL لتبسيط مهمة ترحيل البيانات.
وأخيرًا، إذا كنت تخطط لاستخدام أداة ETL، ففكر في تشغيل هذه الأداة داخل بيئة Azure للاستفادة من أداء سحابة Azure وقابلية التوسع والتكلفة. يحرر هذا النهج أيضًا الموارد في مركز بيانات Oracle.
الملخص
للتلخيص، فإن توصياتنا لترحيل البيانات وعمليات ETL المرتبطة بها من Oracle إلى Azure Synapse هي:
التخطيط مسبقًا لضمان نجاح عملية الترحيل.
إنشاء مخزون مفصل للبيانات والعمليات التي سيتم ترحيلها في أقرب وقت ممكن.
استخدام بيانات تعريف النظام وملفات السجل للحصول على فهم دقيق للبيانات واستخدام العمليات. عدم الاعتماد على الوثائق لأنها قد تكون قديمة.
فهم وحدات تخزين البيانات التي سيتم ترحيلها، وعرض النطاق الترددي للشبكة بين مركز البيانات المحلي وبيئات سحابة Azure.
الوضع في الاعتبار استخدام مثيل Oracle في جهاز Azure الظاهري كخطوة انطلاق لإلغاء تحميل الترحيل من بيئة Oracle القديمة.
استخدم ميزات Azure القياسية المضمنة لتقليل حمل عمل الترحيل.
تحديد وفهم الأدوات الأكثر كفاءة لاستخراج البيانات وتحميلها في كل من بيئات Oracle وAzure. استخدام الأدوات المناسبة في كل مرحلة من مراحل العملية.
استخدام مرافق Azure، مثل Azure Data Factory، لتنسيق عملية الترحيل وأتمتتها مع تقليل التأثير على نظام Oracle.
الملحق: أمثلة على تقنيات استخراج بيانات Oracle
يمكنك استخدام العديد من التقنيات لاستخراج بيانات Oracle عند الترحيل من Oracle إلى Azure Synapse. توضح الأقسام التالية كيفية استخراج بيانات Oracle باستخدام Oracle SQL Developer وموصل Oracle في Data Factory.
استخدام Oracle SQL Developer لاستخراج البيانات
يمكنك استخدام واجهة مستخدم مطور Oracle SQL لتصدير بيانات الجدول إلى العديد من التنسيقات، بما في ذلك CSV، كما هو موضح في لقطة الشاشة التالية:

تتضمن خيارات التصدير الأخرى JSON وXML. يمكنك استخدام واجهة المستخدم لإضافة مجموعة من أسماء الجداول إلى "عربة"، ثم تطبيق التصدير على المجموعة بأكملها في السلة:

يمكنك أيضًا استخدام سطر أوامر مطور Oracle SQL (SQLcl) لتصدير بيانات Oracle. يدعم هذا الخيار الأتمتة باستخدام برنامج نصي shell.
بالنسبة للجداول الصغيرة نسبيا، قد تجد هذه التقنية مفيدة إذا واجهت مشاكل في استخراج البيانات من خلال اتصال مباشر.
استخدام موصل Oracle في Azure Data Factory للنسخ المتوازي
يمكنك استخدام موصل Oracle في Data Factory لتفريغ جداول Oracle الكبيرة بالتوازي. يوفر موصل Oracle تقسيم البيانات المضمنة لنسخ البيانات من Oracle بالتوازي. يمكنك العثور على خيارات تقسيم البيانات في علامة التبويب Source لنشاط النسخ.

للحصول على معلومات حول كيفية تكوين موصل Oracle للنسخ المتوازي، راجع النسخ المتوازي من Oracle.
لمزيد من المعلومات حول أداء نشاط نسخ Data Factory وقابلية التوسع، راجع دليل أداء نشاط النسخ وقابلية التوسع.
الخطوات التالية
لمعرفة المزيد حول عمليات الوصول إلى الأمان، راجع المقالة التالية في هذه السلسلة: الأمان والوصول وإتمام العمليات لعمليات ترحيل Oracle.