البرنامج التعليمي: إنشاء تعريف وظيفة Apache Spark في Synapse Studio
يوضح هذا البرنامج التعليمي كيفية استخدام Synapse Studio لإنشاء تعريفات وظائف Apache Spark، ثم إرسالها إلى تجمع Apache Spark بلا خادم.
يشمل البرنامج التعليمي المهام التالية:
- إنشاء تعريف وظيفة Apache Spark لـ PySpark (Python)
- إنشاء تعريف وظيفة Apache Spark لـ Spark (Scala)
- إنشاء تعريف مهمة Apache Spark لـ .NET Spark (C#/F#)
- إنشاء تعريف الوظيفة عن طريق استيراد ملف JSON
- تصدير ملف تعريف وظيفة Apache Spark إلى ملف محلي
- إرسال تعريف وظيفة Apache Spark كوظيفة دفعة
- إضافة تعريف وظيفة Apache Spark إلى تدفق
المتطلبات الأساسية
قبل البدء مع هذا البرنامج التعليمي، تأكد من تلبية المتطلبات التالية:
- مساحة عمل Azure Synapse Analytics. للحصول على إرشادات، راجع إنشاء مساحة عمل Azure Synapse Analytics.
- تجمع Apache Spark بلا خادم.
- حساب تخزين ADLS Gen2. يجب أن يكون مساهم بيانات للبيانات الثنائية الكبيرة للتخزين لنظام ملف Data Lake Storage Gen2 الذي ترغب في العمل معه. إذا لم تكن كذلك، تحتاج إلى إضافة الإذن يدويًّا.
- إذا كنت لا تريد استخدام مساحة التخزين الافتراضية لمساحة العمل، فقم بربط حساب تخزين ADLS Gen2 المطلوب في Synapse Studio.
إنشاء تعريف وظيفة Apache Spark لـ PySpark (Python)
في هذا القسم، تقوم بإنشاء تعريف وظيفة Apache Spark لـ PySpark (Python).
قم بفتح Synapse Studio.
يمكنك الانتقال إلى ملفات عينة لإنشاء تعريفات وظائف Apache Spark لتنزيل ملفات عينة python.zip، ثم فك ضغط الحزمة المضغوطة، واستخراج ملفات wordcount.py وshakespeare.txt.
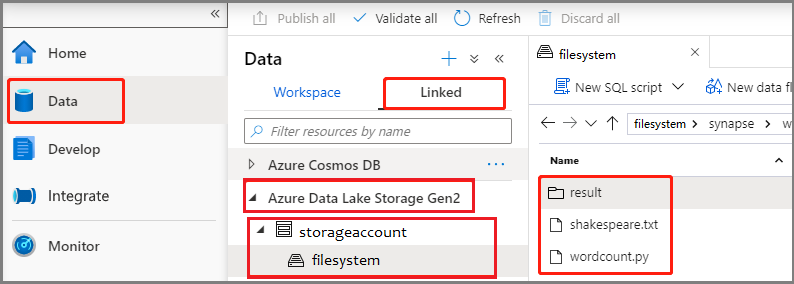
حدد Data ->Linked ->Azure Data Lake Storage Gen2، وقم بتحميل wordcount.py وshakespeare.txt في نظام الملفات ADLS Gen2 الخاص بك.
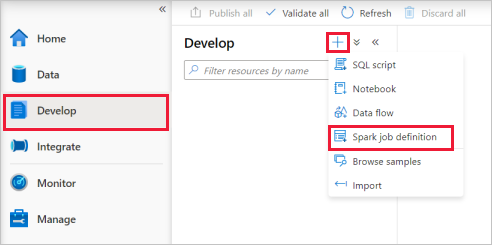
حدد مركز تطوير، وحدد الرمز '+' وحدد تعريف وظيفة Spark لإنشاء تعريف جديد لوظيفة Spark.
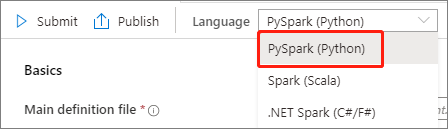
حدد PySpark (Python) من القائمة المنسدلة للغة في النافذة الرئيسية لتعريف وظيفة Apache Spark.
املأ المعلومات لتعريف وظيفة Apache Spark.
الخاصية الوصف اسم تعريف الوظيفة أدخل اسمًا لتعريف وظيفة Apache Spark. يمكن تحديث هذا الاسم في أي وقت حتى يتم نشره.
العينة:job definition sampleملف التعريف الرئيسي الملف الرئيسي المستخدم للوظيفة. حدد ملف PY من التخزين. يمكنك تحديد ملف التحميل لتحميل الملف إلى حساب تخزين.
العينة:abfss://…/path/to/wordcount.pyوسيطات سطر الأوامر الوسيطات الاختيارية للوظيفة.
العينة:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
ملاحظة: يتم فصل وسيطتين لتعريف المهمة عينة بمساحة.الملفات المرجعية ملفات إضافية تستخدم كمرجع في ملف التعريف الرئيسي. يمكنك تحديد ملف التحميل لتحميل الملف إلى حساب تخزين. تجمع Spark سيتم إرسال المهمة إلى تجمع Apache Spark المحدد. إصدار Spark نسخة من Apache Spark التي يتم تشغيل تجمع Apache Spark. المنفذون عدد المنفذين الذين سيتم إعطاؤهم في تجمع Apache Spark المحدد للوظيفة. حجم المنفذ عدد المعالجات والذاكرة التي سيتم استخدامها للمنفذين في تجمع Apache Spark المحدد للوظيفة. حجم برنامج التشغيل عدد النوى والذاكرة التي سيتم استخدامها لبرنامج التشغيل في تجمع Apache Spark المحدد لهذه المهمة. تكوين Apache Spark تخصيص التكوينات عن طريق إضافة الخصائص أدناه. إذا لم تقم بإضافة خاصية، فسيستخدم Azure Synapse القيمة الافتراضية عند الاقتضاء. 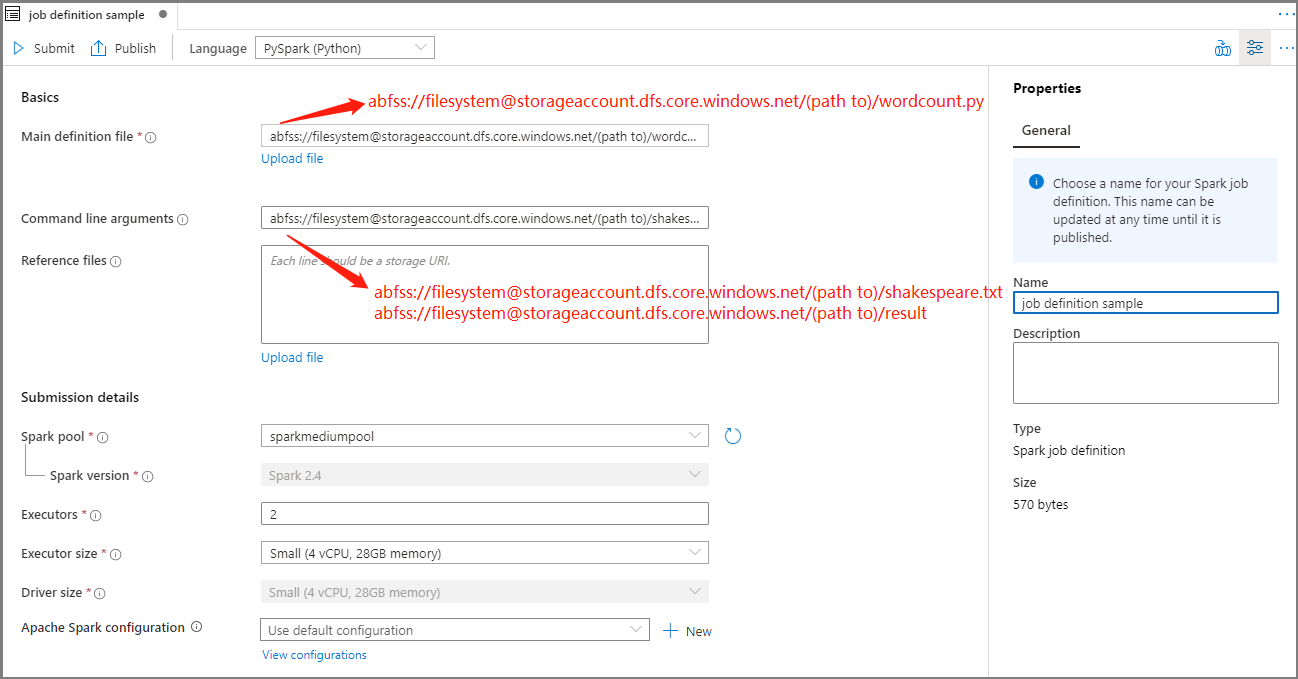
حدد نشر لحفظ تعريف وظيفة Apache Spark.

إنشاء تعريف وظيفة Apache Spark لـ Apache Spark(Scala)
في هذا القسم، يمكنك إنشاء تعريف وظيفة Apache Spark لـ Apache Spark(Scala).
افتح Azure Synapse Studio.
يمكنك الانتقال إلى ملفات عينة لإنشاء تعريفات وظائف Apache Spark لتنزيل ملفات عينة scala.zip، ثم فك ضغط الحزمة المضغوطة، واستخراج ملفات wordcount.jar وshakespeare.txt.
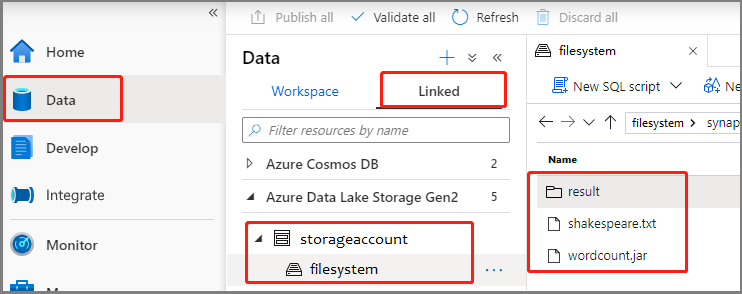
حدد Data ->Linked ->Azure Data Lake Storage Gen2، وقم بتحميل wordcount.jar وshakespeare.txt في نظام الملفات ADLS Gen2 الخاص بك.
حدد مركز تطوير، وحدد الرمز '+' وحدد تعريف وظيفة Spark لإنشاء تعريف جديد لوظيفة Spark. (صورة العينة هي نفس الخطوة 4 من إنشاء تعريف وظيفة Apache Spark (Python) لـ PySpark.)
حدد Spark(Scala) من القائمة المنسدلة للغة في النافذة الرئيسية لتعريف وظيفة Apache Spark.
املأ المعلومات لتعريف وظيفة Apache Spark. يمكنك نسخ معلومات العينة.
الخاصية الوصف اسم تعريف الوظيفة أدخل اسمًا لتعريف وظيفة Apache Spark. يمكن تحديث هذا الاسم في أي وقت حتى يتم نشره.
العينة:scalaملف التعريف الرئيسي الملف الرئيسي المستخدم للوظيفة. حدد ملف JAR من التخزين. يمكنك تحديد ملف التحميل لتحميل الملف إلى حساب تخزين.
العينة:abfss://…/path/to/wordcount.jarاسم الفئة الرئيسية المعرف المؤهل بالكامل أو الفئة الرئيسية الموجودة في ملف التعريف الرئيسي.
العينة:WordCountوسيطات سطر الأوامر الوسيطات الاختيارية للوظيفة.
العينة:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
ملاحظة: يتم فصل وسيطتين لتعريف المهمة عينة بمساحة.الملفات المرجعية ملفات إضافية تستخدم كمرجع في ملف التعريف الرئيسي. يمكنك تحديد ملف التحميل لتحميل الملف إلى حساب تخزين. تجمع Spark سيتم إرسال المهمة إلى تجمع Apache Spark المحدد. إصدار Spark نسخة من Apache Spark التي يتم تشغيل تجمع Apache Spark. المنفذون عدد المنفذين الذين سيتم إعطاؤهم في تجمع Apache Spark المحدد للوظيفة. حجم المنفذ عدد المعالجات والذاكرة التي سيتم استخدامها للمنفذين في تجمع Apache Spark المحدد للوظيفة. حجم برنامج التشغيل عدد النوى والذاكرة التي سيتم استخدامها لبرنامج التشغيل في تجمع Apache Spark المحدد لهذه المهمة. تكوين Apache Spark تخصيص التكوينات عن طريق إضافة الخصائص أدناه. إذا لم تقم بإضافة خاصية، فسيستخدم Azure Synapse القيمة الافتراضية عند الاقتضاء. 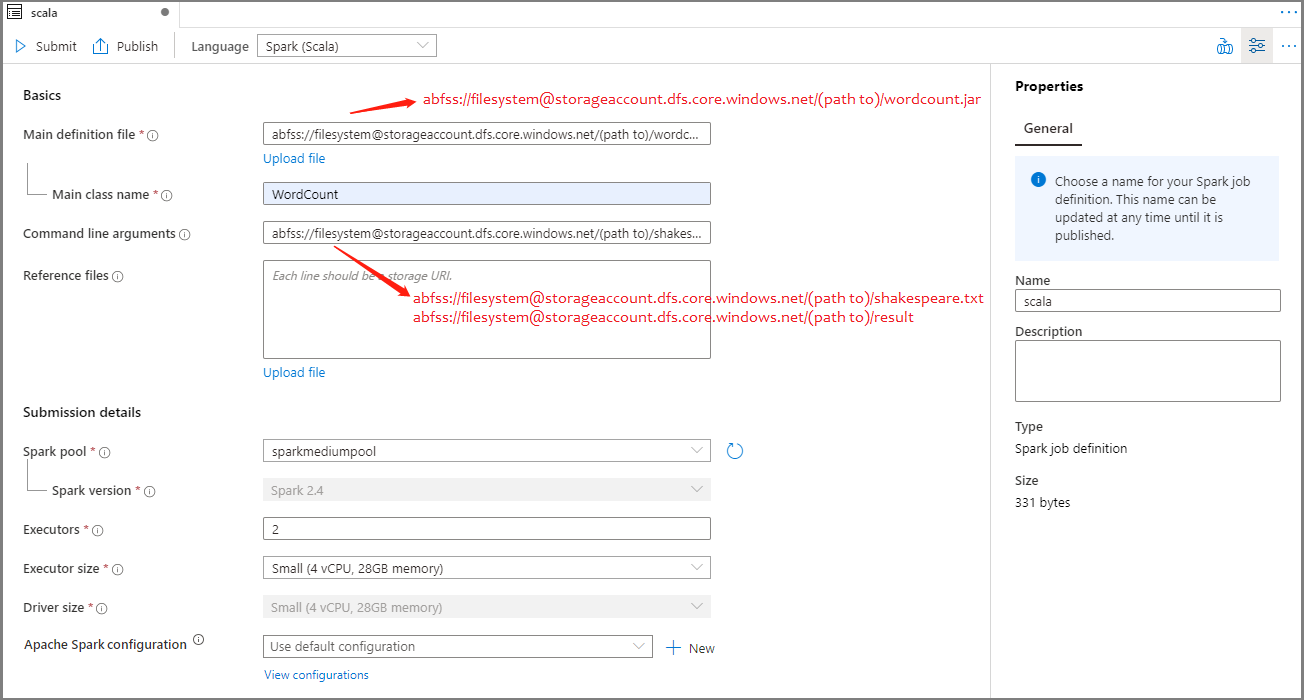
حدد نشر لحفظ تعريف وظيفة Apache Spark.

إنشاء تعريف وظيفة Apache Spark لـ .NET Spark (C#/F#)
في هذا القسم، يمكنك إنشاء تعريف مهمة أباتشي سبارك لـ .NET Spark(C#/F#).
افتح Azure Synapse Studio.
يمكنك الانتقال إلى ملفات عينة لإنشاء تعريفات وظائف Apache Spark لتنزيل ملفات عينة dotnet.zip، ثم فك ضغط الحزمة المضغوطة، واستخراج ملفات wordcount.zip وshakespeare.txt.
حدد Data ->Linked ->Azure Data Lake Storage Gen2، وقم بتحميل wordcount.zip وshakespeare.txt في نظام الملفات ADLS Gen2 الخاص بك.
حدد مركز تطوير، وحدد الرمز '+' وحدد تعريف وظيفة Spark لإنشاء تعريف جديد لوظيفة Spark. (صورة العينة هي نفس الخطوة 4 من إنشاء تعريف وظيفة Apache Spark (Python) لـ PySpark.)
حدد .NET Spark(C#/F#) من القائمة المنسدلة للغة في النافذة الرئيسية لتعريف وظيفة Apache Spark.
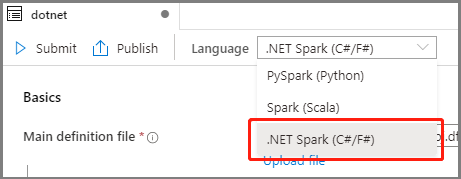
ملء المعلومات لتعريف وظيفة Apache Spark. يمكنك نسخ معلومات العينة.
الخاصية الوصف اسم تعريف الوظيفة أدخل اسمًا لتعريف وظيفة Apache Spark. يمكن تحديث هذا الاسم في أي وقت حتى يتم نشره.
العينة:dotnetملف التعريف الرئيسي الملف الرئيسي المستخدم للوظيفة. حدد ملف ZIP الذي يحتوي على تطبيق .NET لـ Apache Spark (أي الملف الرئيسي القابل للتنفيذ و DLLs الذي يحتوي على دالات معرفة من قبل المستخدم والملفات المطلوبة الأخرى) من التخزين. يمكنك تحديد ملف التحميل لتحميل الملف إلى حساب تخزين.
العينة:abfss://…/path/to/wordcount.zipالملف الرئيسي القابل للتنفيذ الملف الرئيسي القابل للتنفيذ في ملف ZIP التعريف الرئيسي.
العينة:WordCountوسيطات سطر الأوامر الوسيطات الاختيارية للوظيفة.
العينة:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
ملاحظة: يتم فصل وسيطتين لتعريف المهمة عينة بمساحة.الملفات المرجعية ملفات إضافية مطلوبة من قبل العقد العاملة لتنفيذ تطبيق .NET لـ Apache Spark غير المضمن في ملف ZIP التعريف الرئيسي (أي، امتدادات jars التابعة، DLLs دالة تعريف المستخدم إضافية، وملفات التكوين الأخرى). يمكنك تحديد ملف التحميل لتحميل الملف إلى حساب تخزين. تجمع Spark سيتم إرسال المهمة إلى تجمع Apache Spark المحدد. إصدار Spark نسخة من Apache Spark التي يتم تشغيل تجمع Apache Spark. المنفذون عدد المنفذين الذين سيتم إعطاؤهم في تجمع Apache Spark المحدد للوظيفة. حجم المنفذ عدد المعالجات والذاكرة التي سيتم استخدامها للمنفذين في تجمع Apache Spark المحدد للوظيفة. حجم برنامج التشغيل عدد النوى والذاكرة التي سيتم استخدامها لبرنامج التشغيل في تجمع Apache Spark المحدد لهذه المهمة. تكوين Apache Spark تخصيص التكوينات عن طريق إضافة الخصائص أدناه. إذا لم تقم بإضافة خاصية، فسيستخدم Azure Synapse القيمة الافتراضية عند الاقتضاء. 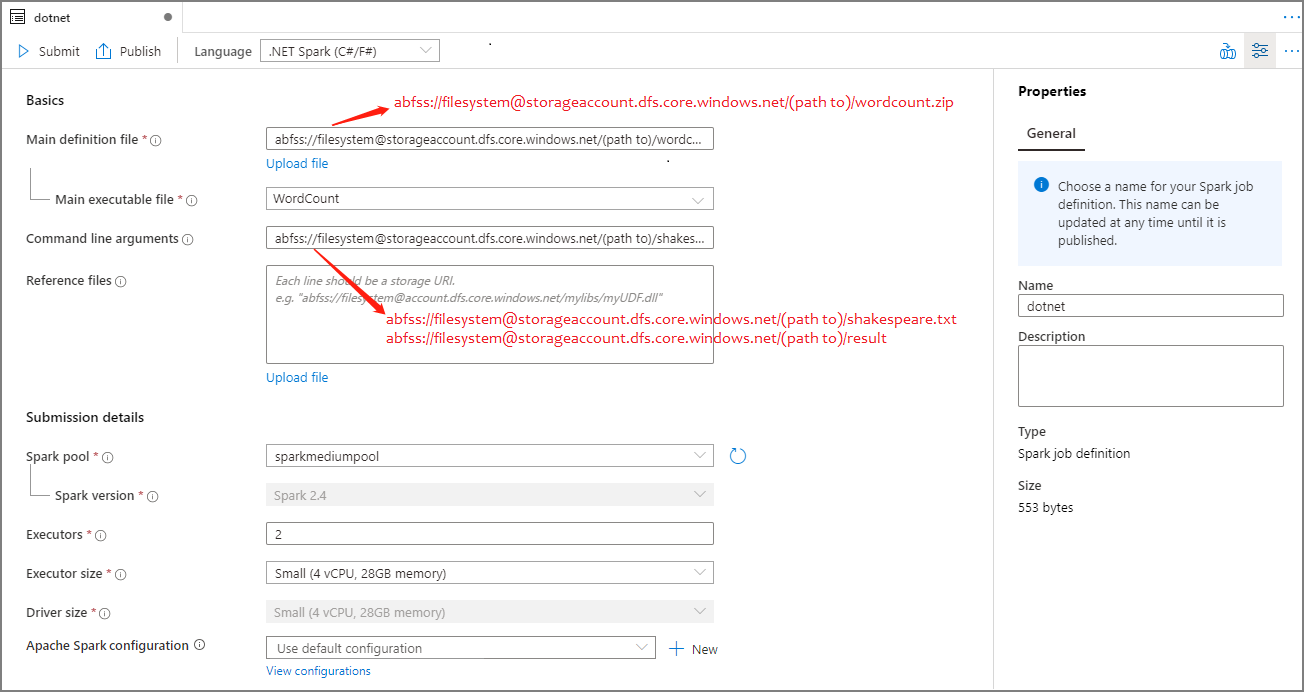
حدد نشر لحفظ تعريف وظيفة Apache Spark.

إشعار
بالنسبة لتكوين Apache Spark، إذا لم يَقم تعريف المهمة Apache Spark لتكوين Apache Spark بأي شيء خاص، فسيُستخدم التكوين الافتراضي عند تشغيل الوظيفة.
إنشاء تعريف وظيفة Apache Spark عن طريق استيراد ملف JSON
يمكنك استيراد ملف JSON محلي موجود في مساحة عمل Azure Synapse من قائمة الإجراءات (...) من مستكشف تعريف مهمة Apache Spark لإنشاء تعريف مهمة Apache Spark جديد.
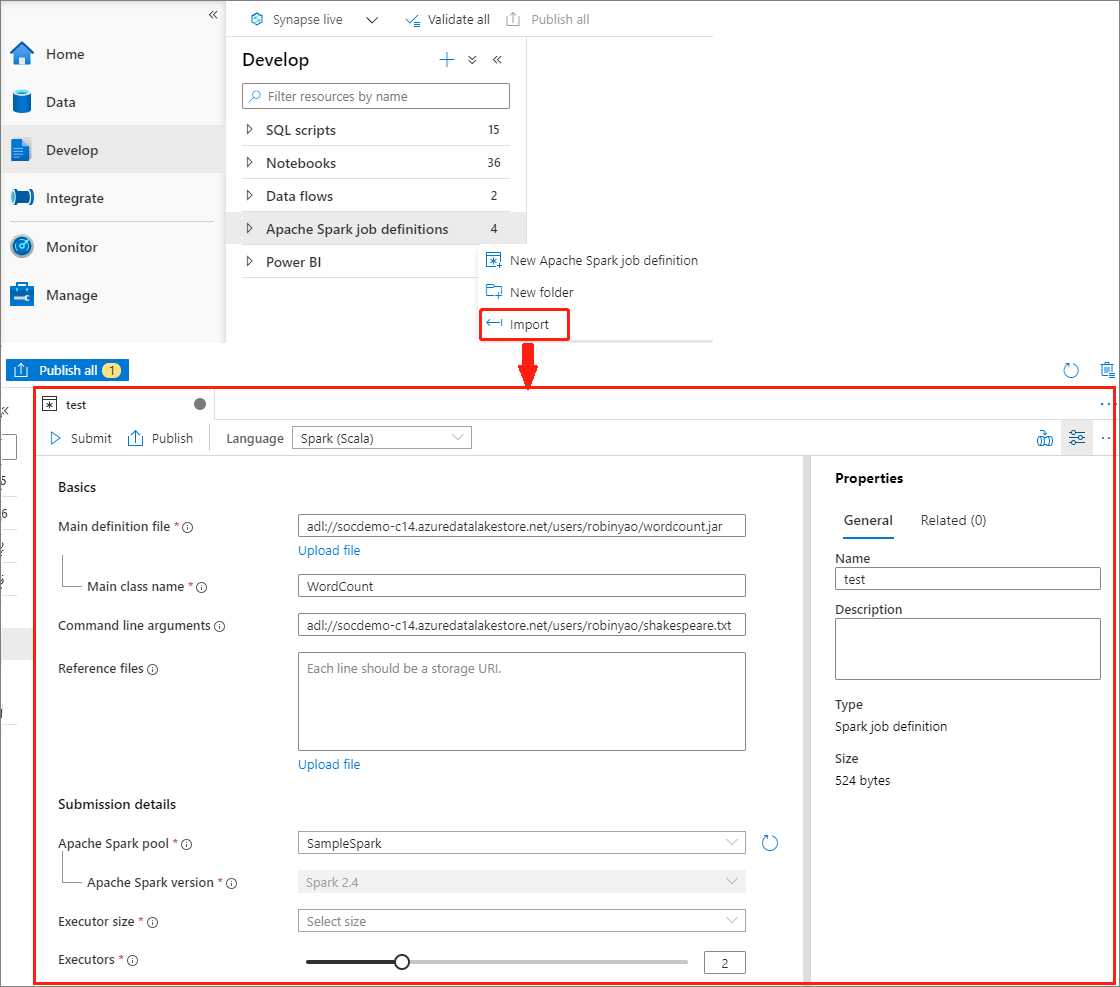
تعريف وظيفة Spark متوافق تمامًا مع واجهة برمجة تطبيقات Livy. يمكنك إضافة معلمات إضافية لخصائص Livy الأخرى (مستندات ليفي - REST API (apache.org) في ملف JSON المحلي. كما يمكنك تحديد معلمات تكوين Spark ذات الصلة في خاصية التكوين كما هو موضح أدناه. ثم يمكنك استيراد ملف JSON مرة أخرى لإنشاء تعريف مهمة Apache Spark جديد لمهمة الدفعة. مثال JSON لاستيراد تعريف spark:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
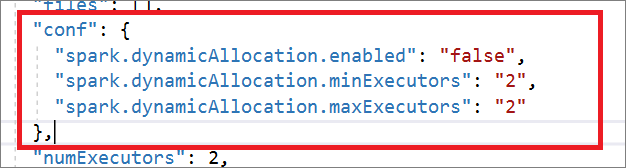
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
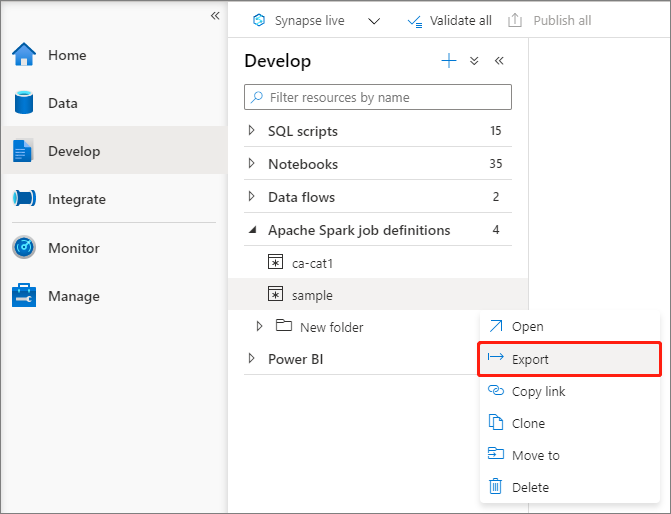
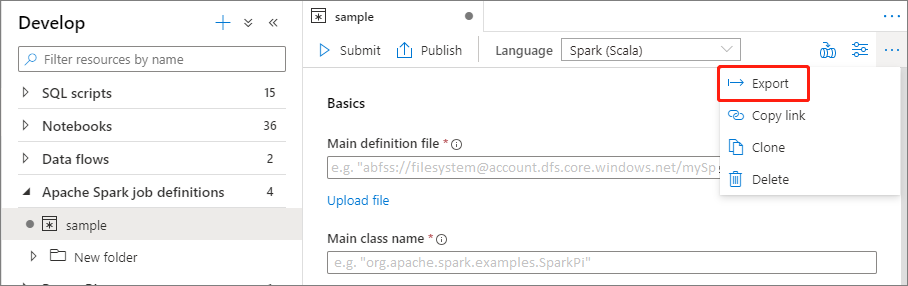
تصدير ملف تعريف وظيفة Apache Spark موجود
يمكنك تصدير ملفات تعريف مهمة Apache Spark الموجودة إلى محلي من الإجراءات (...) قائمة مستكشف الملفات. يمكنك تحديث ملف JSON لخصائص Livy إضافية ثم استيراده مرة أخرى لإنشاء تعريف مهمة جديدة إذا لزم الأمر.
إرسال تعريف وظيفة Apache Spark كوظيفة دفعة
بعد إنشاء تعريف وظيفة Apache Spark، يمكنك إرساله إلى تجمع Apache Spark. تأكد من أنك مساهم بيانات للبيانات الثنائية الكبيرة للتخزين لنظام ملف Data Lake Storage Gen2 الذي ترغب في العمل معها. إذا لم تكن كذلك، تحتاج إلى إضافة الإذن يدويًّا.
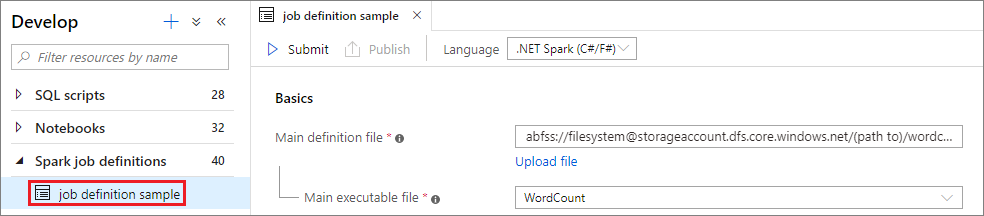
السيناريو 1: إرسال تعريف وظيفة Apache Spark
افتح نافذة تعريف وظيفة Apache عن طريق تحديدها.
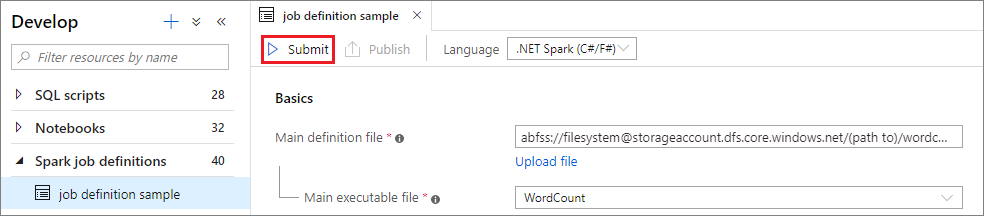
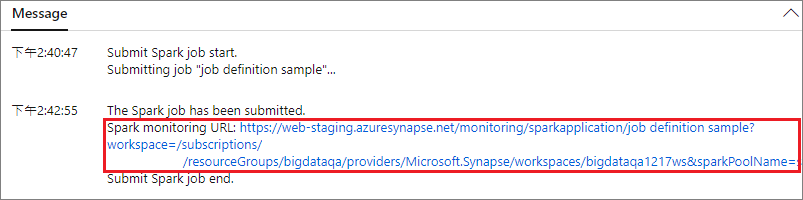
حدد إرسال زر لإرسال المشروع إلى تجمع Apache Spark المحدد. يمكنك تحديد علامة التبويب عنوان URL لمراقبة Spark لرؤية LogQuery لتطبيق Apache Spark.
السيناريو 2: عرض وظيفة Apache Spark للتشغيل المتقدم
حدد مراقبة، ثم حدد الخيار تطبيقات Apache Spark. يمكنك العثور على تطبيق Apache Spark المقدم.
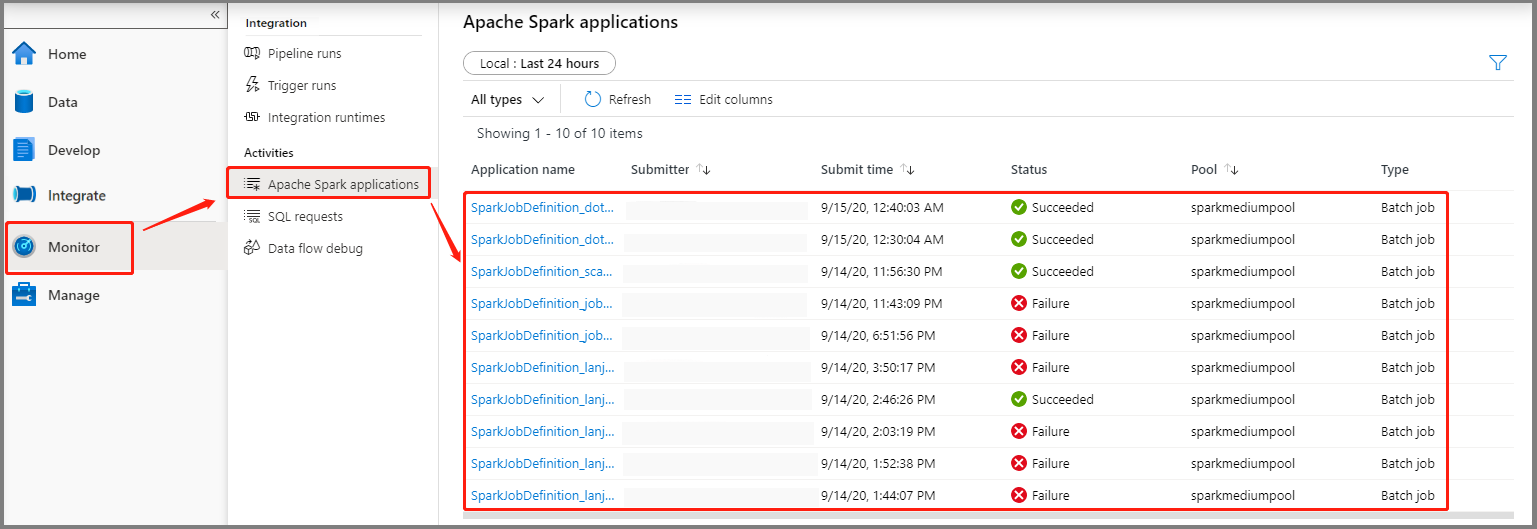
ثم حدد تطبيق Apache Spark، يعرض إطار مهمة SparkJobDefinition. يمكنك عرض تقدم تنفيذ المهمة من هنا.
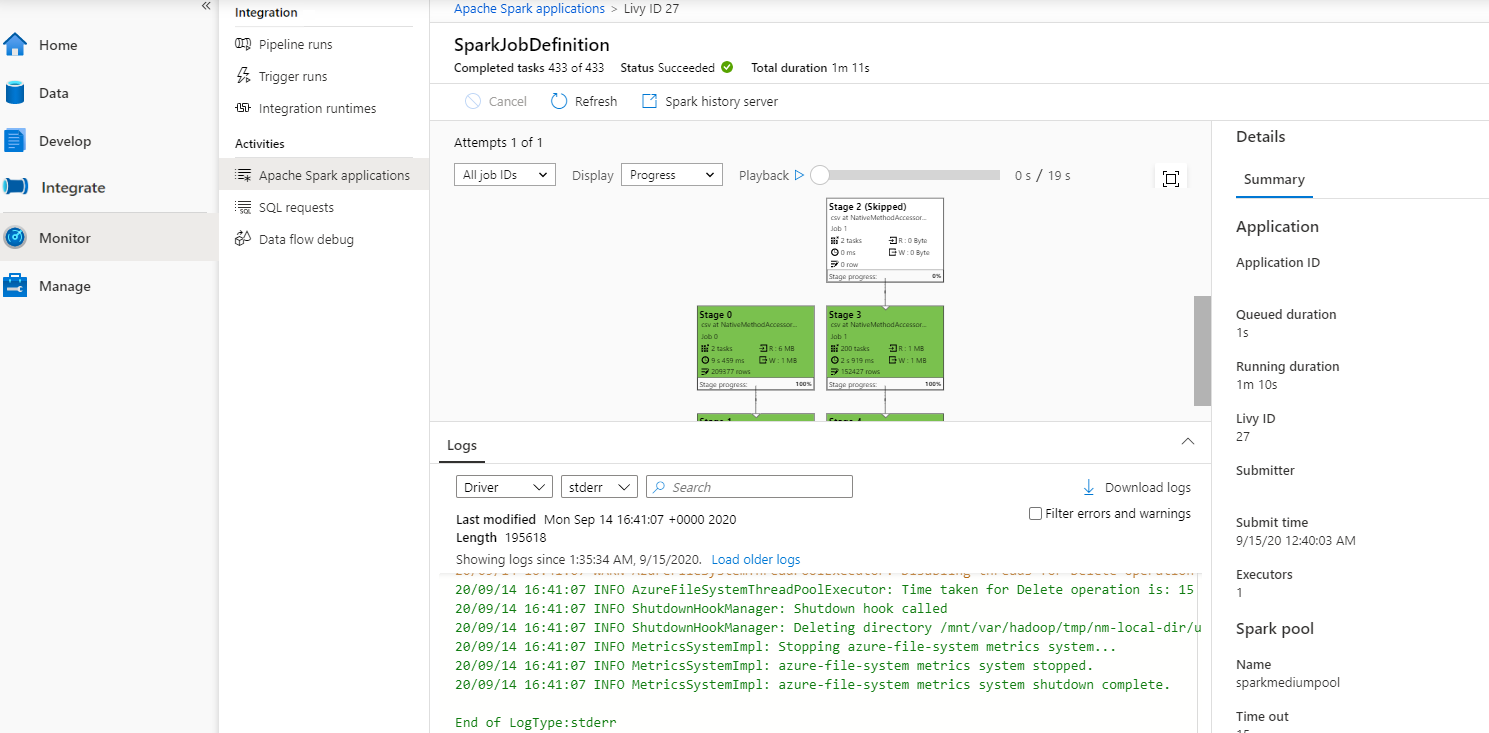
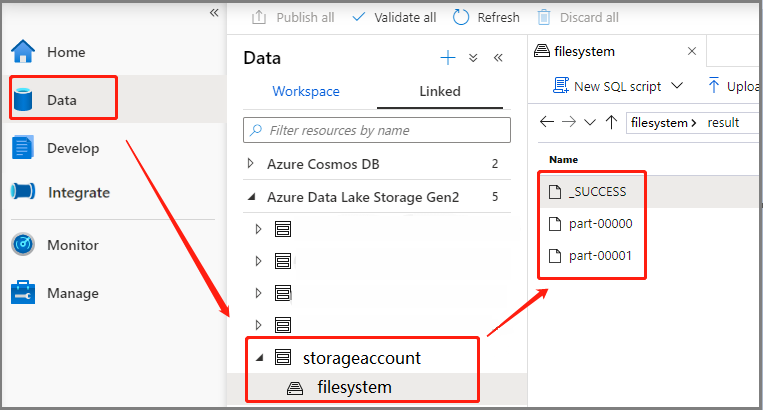
السيناريو 3: التحقق من ملف الإخراج
حدد Data ->Linked ->Azure Data Lake Storage Gen2 (hozhaobdbj)، افتح مجلد النتائج الذي تم إنشاؤه في وقت سابق، يمكنك الانتقال إلى مجلد النتائج والتحقق من إنشاء الإخراج.
إضافة تعريف وظيفة Apache Spark إلى تدفق
في هذا القسم، يمكنك إضافة تعريف مهمة Apache Spark إلى خط أنابيب.
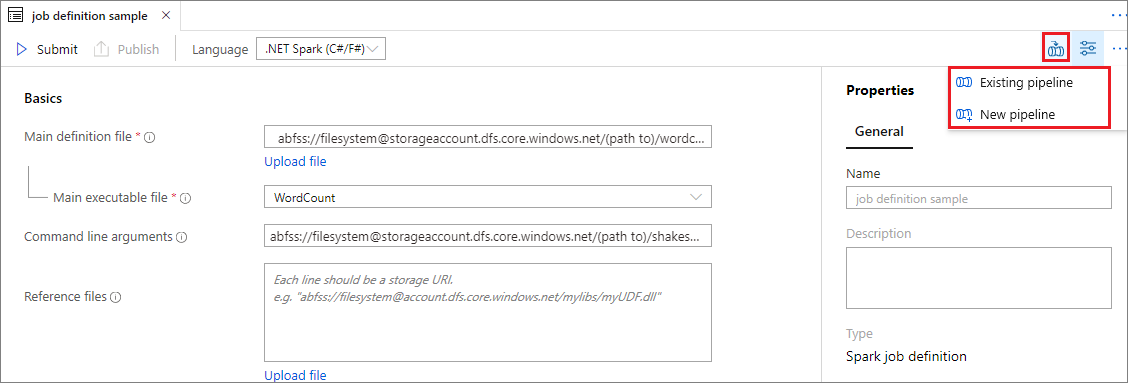
افتح تعريف وظيفة Apache Spark الحالي.
حدد الرمز الموجود أعلى يمين تعريف وظيفة Apache Spark، واختر خط الأنابيب الحالي،أو تدفق جديد. يمكنك الرجوع إلى صفحة تدفق للحصول على مزيد من المعلومات.
الخطوات التالية
بعد ذلك يمكنك استخدام Azure Synapse Studio لإنشاء مجموعات بيانات Power BI وإدارة بيانات Power BI. تقدم إلى مقالة مساحة عمل ربط Power BI بمساحة عمل Synapse لمعرفة المزيد.