تحسين وظائف Apache Spark في Azure Synapse Analytics
تعرف على كيفية تحسين تكوين نظام مجموعة Apache Spark لعبء العمل الخاص بك. التحدي الأكثر شيوعًا هو الضغط على الذاكرة، بسبب تكوينات غير صحيحة (المنفذين ذوي الحجم الخطأ بشكل خاص)، والعمليات طويلة الأمد، والمهام التي تؤدي إلى عمليات ديكارتية. يمكنك تسريع المهام باستخدام التخزين المؤقت المناسب، والسماح بـ انحراف البيانات. للحصول على أفضل أداء، قم بمراقبة ومراجعة عمليات تنفيذ وظائف Spark طويلة الأمد والمستهلكة للموارد.
تصف المقاطع التالية تحسينات وتوصيات وظائف Spark الشائعة.
اختيار تجريد البيانات
تستخدم إصدارات Spark السابقة RDDs لتلخيص البيانات، وSpark 1.3، و1.6 المقدمة DataFrames وDataSets، على التوالي. ضع في اعتبارك المزايا النسبية التالية:
- إطارات البيانات
- أفضل خيار في معظم الحالات.
- يوفر تحسين الاستعلام من خلال Catalyst.
- توليد التعليمات البرمجية للمرحلة الكاملة.
- الوصول المباشر إلى الذاكرة.
- حمل منخفض لمجموعة البيانات المهملة (GC).
- ليس سهلاً على المطور مثل مجموعات البيانات، كما لا توجد أي عمليات تحقق من وقت التحويل البرمجي أو برمجة كائن المجال.
- مجموعات البيانات
- جيد في تدفقات ETL المعقدة حيث يكون تأثير الأداء مقبولاً.
- ليس جيداً في التجميعات حيث يمكن أن يكون تأثير الأداء كبيراً.
- يوفر تحسين الاستعلام من خلال Catalyst.
- سهل للمطور عن طريق توفير برمجة كائن المجال وعمليات التحقق من وقت التجميع.
- إضافة الحمل التسلسلي/ إلغاء التسلسل.
- ارتفاع حمل مجموعة البيانات المهملة.
- فواصل توليد التعليمات البرمجية للمرحلة الكاملة.
- مجموعات البيانات الموزعة المرنة
- لا تحتاج إلى استخدام مجموعات البيانات الموزعة المرنة، إلا إذا كنت بحاجة إلى إنشاء مجموعة البيانات الموزعة المرنة مخصص جديد.
- لا يوجد تحسين للاستعلام من خلال Catalyst.
- لا يوجد توليد للتعليمات البرمجية للمرحلة الكاملة.
- ارتفاع حمل مجموعة البيانات المهملة.
- يجب استخدام واجهات برمجة التطبيقات القديمة من Spark 1.x.
استخدم تنسيق البيانات الأمثل
يدعم Spark العديد من التنسيقات، مثل csv وjson وxml وparquet وorc وavro. يمكن توسيع Spark لدعم العديد من التنسيقات مع مصادر البيانات الخارجية - لمزيد من المعلومات، راجع حزم Apache Spark.
أفضل تنسيق للأداء هو Parquet مع ضغط snappy، وهو الافتراضي في Spark 2.x. يخزن Parquet البيانات بتنسيق عمودي، ويتم تحسينه بشكل كبير في Spark. بالإضافة إلى ذلك، بينما ضغط snappy قد يؤدي إلى ملفات أكبر من ضغط gzip على سبيل المثال. نظرًا إلى الطبيعة القابلة للتقسيم لتلك الملفات، فإنها تفك الضغط بشكل أسرع.
استخدام ذاكرة التخزين المؤقت
يوفر Spark آليات التخزين المؤقت الأصلية الخاصة بها، والتي يمكن استخدامها بطرق مختلفة مثل .persist() و.cache() وCACHE TABLE. ذاكرة التخزين المؤقت الأصلية هذه فعالة مع مجموعات البيانات الصغيرة وكذلك في تدفقات ETL حيث تحتاج إلى تخزين النتائج المتوسطة في ذاكرة التخزين المؤقت. ومع ذلك، لا يعمل التخزين المؤقت الأصلي لـ Spark حاليًا بشكل جيد مع التقسيم، نظرًا إلى أن الجدول المخزن بذاكرة التخزين المؤقت لا يحتفظ ببيانات التقسيم.
استخدام الذاكرة بكفاءة
يعمل Spark عن طريق وضع البيانات في الذاكرة، لذلك تعد إدارة موارد الذاكرة جانبًا رئيسيًا لتحسين تنفيذ وظائف Spark. توجد العديد من التقنيات التي يمكنك تطبيقها لاستخدام ذاكرة نظام المجموعة بكفاءة.
تُفضل أقسام البيانات الأصغر حجمًا والحساب لحجم البيانات وأنواعها وتوزيعها في استراتيجية التقسيم لديك.
في Synapse Spark (وقت التشغيل 3.1 أو أعلى)، يتم تمكين تسلسل بيانات Kryo بشكل افتراضي لتسلسل بيانات Kryo.
يمكنك تخصيص حجم المخزن المؤقت kryoserializer باستخدام تكوين Spark استنادا إلى متطلبات حمل العمل:
// Set the desired property spark.conf.set("spark.kryoserializer.buffer.max", "256m")مراقبة وضبط إعدادات تكوين Spark.
لاطلاعكم، يتم عرض بنية ذاكرة Spark وبعض معلمات الذاكرة المنفذ للمفاتيح في الصورة التالية.
اعتبارات ذاكرة Spark
Apache Spark في Azure Synapse يستخدم YARN Apache Hadoop YARN، يسيطر YARN على الحد الأقصى من الذاكرة المستخدمة من قبل جميع الحاويات على كل عقدة Spark. يوضح الرسم التخطيطي التالي الكائنات الرئيسية وعلاقاتها.
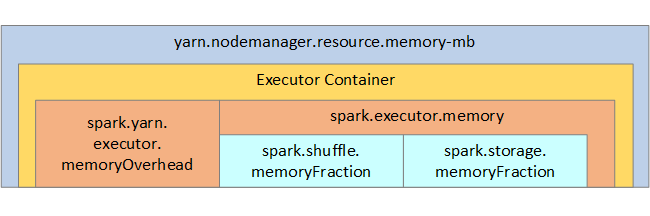
لمعالجة رسائل 'نفاد الذاكرة'، جرب ما يلي:
- راجع DAG Management Shuffles. تقليل بواسطة التقليل من جانب الخريطة، التقسيم المسبق (أو bucketize) لبيانات المصدر، وزيادة الخلط المفرد، وتقليل كمية البيانات المرسلة.
- يُفضل
ReduceByKeyبحد الذاكرة الثابتة الخاص بهGroupByKey، والذي يوفر التجميعات والنوافذ والوظائف الأخرى ولكن لديها حد ذاكرة غير محدود. - يُفضل
TreeReduceالذي يقوم بمزيد من العمل على المنفذين أو الأقسام، إلىReduceالذي يقوم بكل العمل على المشغل. - الاستفادة من DataFrames بدلاً من الكائنات RDD بالمستوى الأدنى.
- إنشاء ComplexTypes التي تغلف الإجراءات، مثل "Top N" أو التجميعات المختلفة أو عمليات النوافذ.
تحسين تسلسل البيانات
يتم توزيع وظائف Spark، لذا فإن تسلسل البيانات المناسب مهم لتحقيق أفضل أداء. هناك خياران للتسلسل لـ Spark:
- تسلسل Java هو الافتراضي.
- تسلسل Kryo هو تنسيق أحدث ويمكن أن يؤدي إلى تسلسل أسرع وأكثر إحكامًا من Java. يتطلب Kryo تسجيل الفئات في برنامجك، ولا يدعم حتى الآن كافة الأنواع القابلة للتسلسل.
استخدام المستودع
المستودع يشبه تقسيم البيانات، ولكن يمكن لكل مستودع أن يحتوي على مجموعة من قيم الأعمدة وليس قيمة واحدة فقط. يعمل المستودع بشكل جيد على تقسيم القيم ذات الأرقام الكبيرة (بالملايين أو أكثر)، مثل معرفات المنتج. يتم تعريف المستودع على أنه خوارزمية مفتاح المستودع بالصف. تقدم الجداول المخزنة بالمستودع تحسينات فريدة لأنها تخزن البيانات الوصفية حول كيفية وضعها في المستودع وفرزها.
فيما يلي بعض ميزات التجميع المتقدمة:
- تحسين الاستعلام استنادًا إلى معلومات التعريف للتجميع.
- تجميعات محسنة.
- صلات ربط محسنة.
يمكنك استخدام التقسيم والتجميع في الوقت نفسه.
تحسين الصلات والخلطات
إذا كانت لديك وظائف بطيئة على انضمام أو تبديل، والسبب هو على الأرجح انحراف البيانات، وهو عدم تماثل في بيانات وظيفتك. على سبيل المثال، قد تستغرق وظيفة الخريطة 20 ثانية، ولكن تشغيل وظيفة حيث يتم ربط البيانات أو تعديلها يستغرق ساعات. لإصلاح انحراف البيانات، يجب إضافة القيمة العشوائية المضافة لحماية المفتاح بأكمله، أو استخدام القيمة العشوائية المضافة للحماية المعزولة لبعض مفاتيح المجموعة الفرعية فقط. إذا كنت تستخدم قيمة عشوائية مضافة معزولة، يجب عليك إجراء تصفية إضافية لعزل المجموعة الفرعية من مفاتيح القيمة العشوائية المضافة للحماية في صلات الخريطة. هناك خيار آخر وهو تقديم عمود مستودع والتجميع المسبق في المستودعات أولاً.
عامل آخر يسبب الصلات البطيئة وهو قد يكون نوع الصلة. بصورة افتراضية، يستخدم Spark نوع الصلة SortMerge. هذا النوع من صلات الربط هو الأنسب لمجموعات البيانات الكبيرة ولكنه مكلف حسابيًا لأنه يجب أن يفرز أولاً الجانبين الأيمن والأيسر للبيانات قبل دمجهما.
Broadcastالصلة هي الأنسب لأصغر مجموعات البيانات، أو حيث يكون أحد جانبي الصلة أصغر بكثير من الجانب الآخر. هذا النوع من الصلة يبث جانباً واحداً إلى جميع المنفذين، وذلك يتطلب المزيد من الذاكرة للبث بشكل عام.
يمكنك تغيير نوع الصلة في التكوين الخاص بك عن طريق تعيين spark.sql.autoBroadcastJoinThreshold، أو يمكنك تعيين تلميح صلة باستخدام واجهات برمجة تطبيقات DataFrame (dataframe.join(broadcast(df2))).
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
إذا كنت تستخدم جداول المستودع، فحينئذٍ يكون لديك نوع صلة ثالثة، وهي الصلة Merge. ستتخطى مجموعة البيانات المقسمة مسبقا والمفرزة مسبقا مرحلة الفرز باهظة الثمن من SortMerge الصلة.
ترتيب الصلات مهم، ولا سيما في الاستفسارات الأكثر تعقيداً. ابدأ بالصلات الأكثر انتقائية. أيضاً، عندما يكون ذلك ممكناً، فانقل الصلات التي تزيد من عدد الصفوف بعد التجميعات.
لإدارة التوازي للصلات الديكارتية، يمكنك إضافة بنيات متداخلة، ووضع نوافذ، وربما تخطي خطوة واحدة أو أكثر في "وظيفة Spark".
تحديد حجم المنفذ الصحيح
عند تحديد تكوين المنفذ، ضع في اعتبارك الحمل العام لجمع البيانات المهملة Java (GC).
عوامل لتقليل حجم المنفذ:
- تقليل حجم الكومة إلى أقل من 32 غيغابايت للحفاظ على حمل GC < بنسبة 10%.
- تقليل عدد النوى للحفاظ على حمل GC < بنسبة 10%.
عوامل لزيادة حجم المنفذ:
- تقليل حمل الاتصال بين المنفذين.
- تقليل عدد الاتصالات المفتوحة بين المنفذين (N2) على مجموعات أكبر (>100 منفذ).
- زيادة حجم كومة الذاكرة المؤقتة لاستيعاب المهام التي تستهلك الذاكرة.
- اختياري: تقليل مقدار حمل الذاكرة لكل منفذ.
- اختياري: زيادة الاستخدام والتزامن من خلال الاشتراك الزائد في CPU.
كقاعدة عامة عند اختيار حجم المنفذ:
- ابدأ بـ 30 جيجابايت لكل منفذ، ثم وزع الذاكرات الأساسية المتوفرة للجهاز.
- زيادة عدد أنوية المنفذ لمجموعات أكبر (>100 منفذ).
- عدّل الحجم استنادًا إلى التشغيل التجريبي والعوامل السابقة مثل حمل تجميع البيانات المهملة (GC).
عند تشغيل الاستعلامات المتزامنة، ضع في اعتبارك ما يلي:
- ابدأ بـ 30 جيجابايت لكل منفذ وجميع الذاكرات الأساسية للجهاز.
- أنشئ تطبيقات متعددة ومتوازية في Spark من خلال الاستخدام الزائد لـ CPU (تحسين زمن الانتقال بحوالي 30%).
- وزع الاستعلامات عبر التطبيقات المتوازية.
- عدّل الحجم استنادًا إلى التشغيل التجريبي والعوامل السابقة مثل حمل تجميع البيانات المهملة (GC).
راقب أداء الاستعلام الخاص بك عن القيم الخارجية أو غيرها من مشاكل الأداء، من خلال النظر في طريقة عرض المخطط الزمني، الرسم البياني SQL، إحصاءات الوظائف، وهلم جرًّا. في بعض الأحيان، يكون منفذ واحد أو عدد قليل من المنفذين أبطأ من الآخرين، وتستغرق المهام وقتًا أطول بكثير لتنفيذها. يحدث هذا بشكل متكرر على المجموعات الكبيرة (> 30 عقدة). في هذه الحالة، قم بتقسيم العمل إلى عدد أكبر من المهام بحيث يمكن تعويض المجدوِل عن المهام البطيئة.
على سبيل المثال، لديك على الأقل ضعف عدد المهام مثل عدد أساسات المنفذ في التطبيق. كما يمكنك تمكين تنفيذ المهام باستخدام conf: spark.speculation = true.
تحسين تنفيذ الوظيفة
- التخزين في ذاكرة التخزين المؤقت حسب الضرورة، على سبيل المثال، إذا كنت تستخدم البيانات مرتين، فحينئذٍ قم بتخزينها في ذاكرة التخزين المؤقت.
- قم ببث المتغيرات إلى جميع المنفذين. لا يتم تسلسل المتغيرات إلا مرة واحدة، ما يؤدي إلى عمليات بحث أسرع.
- استخدم تجمع مؤشر الترابط على برنامج التشغيل، ما يؤدي إلى عملية أسرع للعديد من المهام.
مفتاح أداء الاستعلام Spark 2.x هو محرك Tungsten، الذي يعتمد على توليد مرحلة كاملة من التعليمات البرمجية. في بعض الحالات، قد يتم تعطيل إنشاء التعليمات البرمجية للمرحلة الكاملة.
على سبيل المثال، إذا كنت تستخدم نوعاً غير قابل للتغيير (string) في تعبير التجميع، يظهر SortAggregate بدلاً من HashAggregate. على سبيل المثال، للحصول على أداء أفضل، جرب ما يلي، ثم قم بإعادة تمكين إنشاء التعليمات البرمجية:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))
الخطوات التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ