إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
تلميح
Microsoft Fabric Data Warehouse هو مستودع علائقي على نطاق مؤسسي قائم على أساس بحيرة البيانات، مع بنية جاهزة للمستقبل، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في مستودع البيانات، ابدأ ب Fabric Data Warehouse. يمكن لأحمال عمل تجمع SQL المخصصة الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
تشرح هذه المقالة كيف يمكنك تقدير وإدارة تكاليف تجمع SQL بدون خادم في Azure Synapse Analytics:
- تقدير كمية البيانات المعالجة قبل إصدار استعلام
- استخدم ميزة التحكم في التكاليف لتحديد الميزانية
افهم أن تكاليف تجمع SQL بدون خادم في Azure Synapse Analytics هي جزء فقط من التكاليف الشهرية في فاتورة Azure الخاصة بك. إذا كنت تستخدم خدمات Azure أخرى، يتم احتساب رسوم جميع خدمات وموارد Azure المستخدمة في اشتراكك في Azure، بما في ذلك خدمات الطرف الثالث. تشرح هذه المقالة كيفية التخطيط وإدارة التكاليف لمجموعة SQL بدون خادم في Azure Synapse Analytics.
البيانات التي تمت معالجتها
البيانات المعالجة هي كمية البيانات التي يخزنها النظام مؤقتا أثناء تشغيل الاستعلام. تتكون البيانات المعالجة من الكميات التالية:
- كمية البيانات المقروءة من التخزين. يشمل هذا المبلغ:
- البيانات التي تقرأ أثناء قراءتها.
- البيانات المقروءة أثناء قراءة البيانات الوصفية (لصيغ الملفات التي تحتوي على بيانات وصفية، مثل Parquet).
- كمية البيانات في النتائج الوسيطة. يتم نقل هذه البيانات بين العقد أثناء تشغيل الاستعلام. يتضمن نقل البيانات إلى نقطة النهاية الخاصة بك، بصيغة غير مضغوطة.
- كمية البيانات المكتوبة للتخزين. إذا استخدمت CETAS لتصدير مجموعة النتائج إلى التخزين، فإن كمية البيانات المكتوبة تضاف إلى كمية البيانات المعالجة لجزء SELECT من CETAS.
قراءة الملفات من التخزين محسنة للغاية. تستخدم العملية ما يلي:
- الجلب المسبق، مما قد يضيف بعض العبء الزائد على كمية البيانات المقروءة. إذا قرأ الاستعلام ملفا كاملا، فلا يوجد عبء إضافي. إذا تمت قراءة ملف جزئيا، كما في TOP N استعلامات، فيتم قراءة المزيد من البيانات باستخدام الجلب المسبق.
- محلل قيم مفصولة بالفواصل (CSV) محسن. إذا استخدمت PARSER_VERSION='2.0' لقراءة ملفات CSV، فإن كمية البيانات المقروءة من التخزين تزداد قليلا. يقرأ محلل CSV المحسن الملفات بشكل متوازي، في أجزاء متساوية الحجم. القطع لا تحتوي بالضرورة على صفوف كاملة. لضمان تحليل جميع الصفوف، يقرأ محلل CSV المحسن أيضا أجزاء صغيرة من الأجزاء المجاورة. تضيف هذه العملية بعض التكاليف التشغيلية.
الإحصائيات
يعتمد محسن استعلامات SQL بدون خادم على الإحصائيات لتوليد خطط تنفيذ مثالية للاستعلام. يمكنك إنشاء الإحصائيات يدويا. وإلا، فإن مجموعة SQL بدون خادم تنشئ هذه المجموعات تلقائيا. في كلتا الحالتين، يتم إنشاء الإحصائيات عن طريق تشغيل استعلام منفصل يعيد عمودا محددا بمعدل عينة معين. هذا الاستعلام له كمية مرتبطة من البيانات المعالجة.
إذا قمت بتشغيل نفس الاستعلام أو أي استعلام آخر سيستفيد من الإحصائيات التي تم إنشاؤها، فسيتم إعادة استخدام الإحصائيات إذا أمكن. لا يتم معالجة بيانات إضافية لإنشاء الإحصائيات.
عند إنشاء إحصائيات لعمود باركيه، يقرأ فقط العمود المناسب من الملفات. عند إنشاء إحصائيات لعمود CSV، تقرأ الملفات بالكامل وتحللها.
التدوير
يتم تقريب كمية البيانات المعالجة إلى أقرب ميغابايت لكل استفسار. كل استعلام يحتوي على ما لا يقل عن 10 ميجابايت من البيانات تمت معالجتها.
ما لا يشمل البيانات المعالجة
- بيانات وصفية على مستوى الخادم (مثل تسجيل الدخول، الأدوار، وبيانات الاعتماد على مستوى الخادم).
- قواعد البيانات التي تنشئها في نقطة النهاية الخاصة بك. تحتوي هذه قواعد البيانات فقط على بيانات وصفية (مثل المستخدمين، الأدوار، المخططات، العروض، الوظائف ذات القيمة الجزئية الداخلية [TVFs]، الإجراءات المخزنة، بيانات الاعتماد الموجهة ضمن نطاق قاعدة البيانات، مصادر بيانات خارجية، تنسيقات ملفات خارجية، والجداول الخارجية).
- إذا استخدمت استدلال المخطط، فيتم قراءة أجزاء الملفات لاستنتاج أسماء الأعمدة وأنواع البيانات، وتضاف كمية البيانات المقروءة إلى كمية البيانات المعالجة.
- عبارات لغة تعريف البيانات (DDL)، باستثناء بيان إنشاء الإحصائيات لأنه يعالج البيانات من التخزين بناء على نسبة العينة المحددة.
- استعلامات بيانات وصفية فقط.
تقليل كمية البيانات المعالجة
يمكنك تحسين كمية البيانات المعالجة لكل استعلام وتحسين الأداء عن طريق تقسيم وتحويل بياناتك إلى تنسيق مضغوط قائم على الأعمدة مثل Parquet.
أمثلة
تخيل ثلاث طاولات.
- جدول population_csv مدعوم ب 5 تيرابايت من ملفات CSV. تنظم الملفات في خمسة أعمدة متساوية الحجم.
- جدول population_parquet يحتوي على نفس بيانات جدول population_csv. مدعوم ب 1 تيرابايت من ملفات باركيه. هذا الجدول أصغر من السابق لأن البيانات مضغوطة بصيغة باركيه.
- جدول very_small_csv مدعوم ب 100 كيلوبايت من ملفات CSV.
استعلام 1: اختر مجموع (عدد سكاني) من population_csv
يقرأ هذا الاستعلام ويحلل الملفات كاملة للحصول على قيم لعمود السكان. تعالج العقد أجزاء من هذا الجدول، ويتم نقل مجموع السكان لكل جزء بين العقد. يتم تحويل المبلغ النهائي إلى نقطة النهاية الخاصة بك.
يعالج هذا الاستعلام 5 تيرابايت من البيانات بالإضافة إلى كمية صغيرة من التكاليف التشغيلية لنقل مجموعات من الشظايا.
الاستعلام 2: اختر المجموع (السكان) من population_parquet
عندما تستشفي في تنسيقات مضغوطة وأعمدة مثل Parquet، تقرأ بيانات أقل مقارنة بالاستعلام 1. ترى هذه النتيجة لأن مجموعة SQL بدون خادم تقرأ عمودا مضغوطا واحدا بدلا من الملف بأكمله. في هذه الحالة، يتم قراءة 0.2 تيرابايت. (خمسة أعمدة متساوية الحجم بحجم 0.2 تيرابايت لكل منها.) تعالج العقد أجزاء من هذا الجدول، ويتم نقل مجموع السكان لكل جزء بين العقد. يتم تحويل المبلغ النهائي إلى نقطة النهاية الخاصة بك.
يعالج هذا الاستعلام 0.2 تيرابايت بالإضافة إلى كمية صغيرة من الحمل التشغيلي لنقل مجموعات الشظايا.
الاستعلام 3: اختر * من population_parquet
يقرأ هذا الاستعلام جميع الأعمدة وينقل جميع البيانات بصيغة غير مضغوطة. إذا كان تنسيق الضغط بنسبة 5:1، فإن الاستعلام يعالج 6 تيرابايت لأنه يقرأ 1 تيرابايت وينقل 5 تيرابايت من البيانات غير المضغوطة.
الاستعلام 4: اختر العد(*) من very_small_csv
هذا الاستعلام يقرأ ملفات كاملة. الحجم الإجمالي للملفات في التخزين لهذا الجدول هو 100 كيلوبايت. تعالج العقد أجزاء من هذا الجدول، ويتم نقل مجموع كل جزء بين العقد. يتم تحويل المبلغ النهائي إلى نقطة النهاية الخاصة بك.
يعالج هذا الاستعلام أكثر قليلا من 100 كيلوبايت من البيانات. يتم تقريب كمية البيانات المعالجة لهذا الاستعلام إلى 10 ميجابايت، كما هو محدد في قسم التقريب في هذا المقال.
مراقبة التكاليف
ميزة التحكم في التكاليف في مجموعة SQL بدون خوادم تتيح لك تحديد الميزانية لكمية البيانات المعالجة. يمكنك تحديد الميزانية بوحدة تيرايت من البيانات المعالجة ليوم أو أسبوع أو شهر. وفي نفس الوقت يمكنك تحديد ميزانية أو أكثر. لتكوين التحكم في التكاليف لمجموعة SQL بدون خادم، يمكنك استخدام Synapse Studio أو T-SQL.
تكوين التحكم في التكاليف لتجمع SQL بدون خادم في Synapse Studio
لتكوين التحكم في التكاليف لمجموعة SQL بدون خادم في Synapse Studio، انتقل إلى إدارة عنصر في القائمة على اليسار، ثم اختر عنصر تجمع SQL تحت مجموعات التحليلات. عندما تمر فوق مجموعة SQL بدون خادم، ستلاحظ أيقونة للتحكم في التكاليف - اضغط على هذه الأيقونة.
بمجرد النقر على أيقونة التحكم في التكاليف، سيظهر شريط جانبي:
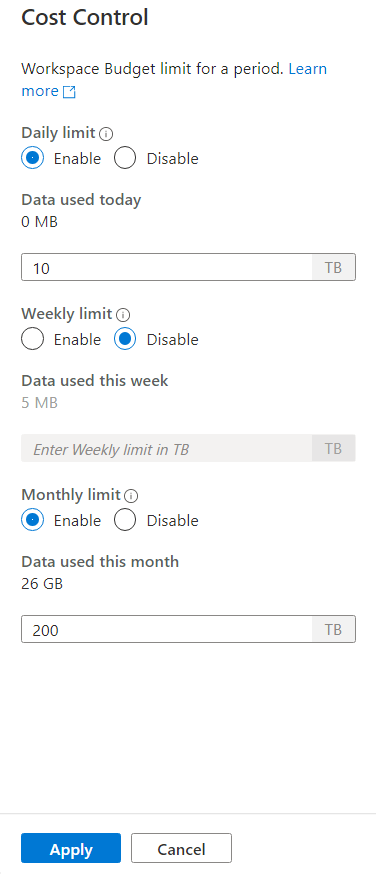
لتعيين ميزانية أو أكثر، انقر أولا على زر تمكين الراديو لميزانية تريد تحديدها، ثم أدخل القيمة الصحيحة في مربع النص. وحدة القيمة هي TBs. بمجرد أن تضبط الميزانيات التي تريدها، اضغط على زر التطبيق في أسفل الشريط الجانبي. هذا كل شيء، ميزانيتك الآن محددة.
تكوين التحكم في التكاليف لمجموعة SQL بدون خادم في T-SQL
لتكوين التحكم في التكاليف لتجمع SQL بدون خادم في T-SQL، تحتاج إلى تنفيذ واحد أو أكثر من الإجراءات المخزنة التالية.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
لرؤية التكوين الحالي، نفذ بيان T-SQL التالي:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
لرؤية كمية البيانات التي تمت معالجتها خلال اليوم أو الأسبوع أو الشهر الحالي، نفذ بيان T-SQL التالي:
SELECT * FROM sys.dm_external_data_processed
تجاوز الحدود المحددة في نظام التحكم في التكاليف
في حال تجاوز أي حد أثناء تنفيذ الاستعلام، فلن يتم إنهاء الاستعلام.
عند تجاوز الحد، سيتم رفض استعلام جديد مع رسالة الخطأ التي تحتوي على تفاصيل حول الفترة، والحد المحدد لتلك الفترة، والبيانات المعالجة لتلك الفترة. على سبيل المثال، في حال تم تنفيذ استعلام جديد، حيث تم تعيين الحد الأسبوعي إلى 1 تيرابايت وتم تجاوزه، ستكون رسالة الخطأ:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
الخطوات التالية
لتتعلم كيفية تحسين استعلاماتك من حيث الأداء، راجع أفضل الممارسات لتجمع SQL بدون خادم.