إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
تلميح
Microsoft Fabric Data Warehouse هو مستودع علائقي على نطاق مؤسسي قائم على أساس بحيرة البيانات، مع بنية جاهزة للمستقبل، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في مستودع البيانات، ابدأ ب Fabric Data Warehouse. يمكن لأحمال عمل تجمع SQL المخصصة الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
تتيح لك الدالة OPENROWSET(BULK...) الوصول إلى الملفات في تخزين Azure. تقرأ الدالة OPENROWSET محتوى مصدر بيانات عن بُعد (على سبيل المثال: ملف) وتُعيد المحتوى في شكل مجموعة من الصفوف. ضمن مورد تجمع SQL بدون خادم، يتم الوصول إلى موفر مجموعة الصفوف المجمعة OPENROWSET عن طريق استدعاء الدالة OPENROWSET وتحديد الخيار BULK.
يمكن الرجوع إلى الدالة OPENROWSET في جملة الاستعلام FROM كما لو كانت اسم جدول OPENROWSET. وهو يدعم العمليات المجمعة من خلال موفر BULK المضمن الذي يتيح قراءة البيانات من ملف وإعادتها كمجموعة صفوف.
إشعار
الدالة OPENROWSET غير مدعومة في تجمع SQL المخصص.
مصدر البيانات
تقرأ الدالة OPENROWSET في Synapse SQL محتوى الملفات من مصدر بيانات. مصدر البيانات هو حساب تخزين Azure ويمكن الإشارة إليه بشكل صريح في الدالة OPENROWSET أو يمكن استنتاجه ديناميكيًّا من عنوان URL للملفات التي تريد قراءتها.
يمكن أن تحتوي الدالة OPENROWSET اختياريًّا على المعلمة DATA_SOURCE لتحديد مصدر البيانات الذي يحتوي على ملفات.
يمكن استخدام
OPENROWSETبدونDATA_SOURCEلقراءة محتويات الملفات مباشرةً من موقع عنوان URL المحدد كخيارBULK:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
هذه طريقة سريعة وسهلة لقراءة محتوى الملفات دون تكوين مسبق. يمكنك هذا الخيار من استخدام خيار المصادقة الأساسي للوصول إلى التخزين (تمرير Microsoft Entra لتسجيلات دخول Microsoft Entra ورمز SAS المميز لتسجيلات دخول SQL).
يمكن استخدام
OPENROWSETمعDATA_SOURCEللوصول إلى الملفات على حساب التخزين المحدد:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]يتيح هذا الخيار تكوين موقع حساب التخزين في مصدر البيانات وتحديد طريقة المصادقة التي يجب استخدامها للوصول إلى التخزين.
هام
يوفر
OPENROWSETبدونDATA_SOURCEطريقة سريعة وسهلة للوصول إلى ملفات التخزين ولكنه يقدم خيارات مصادقة محدودة. على سبيل المثال، يمكن لمديري Microsoft Entra الوصول إلى الملفات فقط باستخدام هوية Microsoft Entra أو الملفات المتاحة للجمهور. إذا كنت بحاجة إلى المزيد من خيارات المصادقة القوية، فاستخدم خيارDATA_SOURCEوحدد بيانات الاعتماد التي تريد استخدامها للوصول إلى التخزين.
الأمان
يجب أن يكون لدى مستخدم قاعدة البيانات إذن ADMINISTER BULK OPERATIONS لاستخدام الدالة OPENROWSET.
يجب على مسؤول التخزين أيضا تمكين المستخدم من الوصول إلى الملفات عن طريق توفير رمز SAS مميز صالح أو تمكين Microsoft Entra الأساسي للوصول إلى ملفات التخزين. تعرف على المزيد حول التحكم في الوصول إلى التخزين في هذه المقالة.
OPENROWSET استخدم القواعد التالية لتحديد كيفية المصادقة على التخزين:
- في
OPENROWSETبدونDATA_SOURCEتعتمد آلية المصادقة على نوع المتصل.- ويمكن لأي مستخدم استخدام
OPENROWSETبدونDATA_SOURCEلقراءة الملفات المتوفرة بشكل عام على تخزين Azure. - يمكن لتسجيلات دخول Microsoft Entra الوصول إلى الملفات المحمية باستخدام هوية Microsoft Entra الخاصة بها إذا كان تخزين Azure يسمح لمستخدم Microsoft Entra بالوصول إلى الملفات الأساسية (على سبيل المثال، إذا كان لدى المتصل
Storage Readerإذن على تخزين Azure). - ويمكن أيضًا استخدام عمليات تسجيل الدخول إلى SQL
OPENROWSETبدونDATA_SOURCEللوصول إلى الملفات المتاحة بشكل عام أو الملفات المحمية باستخدام رمز SAS المميز أو مساحة عمل هوية Synapse المُدارة. ستحتاج إلى إنشاء بيانات اعتماد على نطاق خادم للسماح بالوصول إلى ملفات التخزين.
- ويمكن لأي مستخدم استخدام
- في
OPENROWSETمعDATA_SOURCEيتم تحديد آلية المصادقة في بيانات اعتماد على نطاق قاعدة البيانات المعينة لمصدر البيانات المُشار إليه. يمكنك هذا الخيار من الوصول إلى التخزين المتاح للجمهور أو الوصول إلى التخزين باستخدام رمز SAS المميز أو الهوية المدارة لمساحة العمل أو هوية Microsoft Entra للمتصل (إذا كان المتصل هو Microsoft Entra الأساسي). إذاDATA_SOURCEكانت مراجع تخزين Azure غير عامة، فستحتاج إلى إنشاء بيانات اعتماد على نطاق قاعدة البيانات والإشارة إليها فيDATA SOURCEللسماح بالوصول إلى ملفات التخزين.
يجب أن يكون لدى المتصل الإذن REFERENCES على بيانات الاعتماد لاستخدامه للمصادقة على التخزين.
بناء الجملة
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
الوسيطات
لديك ثلاثة خيارات لملفات الإدخال التي تحتوي على البيانات الهدف للاستعلام. القيم الصالحة هي:
'CSV' - يتضمن أي ملف نصي محدد بفواصل صفًا/عمودًا. يمكن استخدام أي حرف كفاصل حقل، مثل TSV: FIELDTERMINATOR = tab.
'PARQUET' - ملف ثنائي بتنسيق Parquet.
'DELTA' - مجموعة من ملفات Parquet منظمة بتنسيق Delta Lake (معاينة).
القيم ذات المسافات الفارغة غير صالحة. على سبيل المثال، 'CSV' ليست قيمة صالحة.
'unstructured_data_path'
يمكن أن يكون unstructured_data_path الذي ينشئ مسارا إلى البيانات مسارا مطلقا أو نسبيا:
- المسار المطلق في التنسيق
\<prefix>://\<storage_account_path>/\<storage_path>يتيح للمستخدم قراءة الملفات بشكل مباشر. - المسار النسبي بالتنسيق
<storage_path>الذي يجب استخدامه مع المعلمةDATA_SOURCEويصف نمط الملف داخل موقع <storage_account_path> المحدد فيEXTERNAL DATA SOURCE.
ستجد فيما يلي قيم <storage account path> التي ستقوم بالربط مع مصدر البيانات الخارجي الخاص لديك.
| مصدر البيانات الخارجية | البادئة | مسار حساب التخزين |
|---|---|---|
| مساحة تخزين Azure Blob | http[s] | <storage_account.blob.core.windows.net/path/file> |
| مساحة تخزين Azure Blob | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | <storage_account.azuredatalakestore.net/webhdfs/v1> |
| Azure Data Lake Store Gen2 | http[s] | < >storage_account.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name.dfs.core.windows.net/path/file> |
'<storage_path>'
تحديد مسار داخل التخزين يشير إلى المجلد أو الملف الذي تريد قراءته. إذا كان المسار يشير إلى حاوية أو مجلد، فستتم قراءة كافة الملفات من تلك الحاوية أو المجلد المعين. لن يتم تضمين الملفات في المجلدات الفرعية.
يمكنك استخدام أحرف البدل لاستهداف ملفات أو مجلدات متعددة. يُسمح باستخدام أحرف البدل غير المتتالية المتعددة.
وفيما يلي مثال يقرأ جميع ملفات csv التي تبدأ بـ population من جميع المجلدات التي تبدأ بـ /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
إذا قمت بتحديد مسار unstructured_data_path ليكون مجلدًا، فسيقوم استعلام تجمع SQL بدون خادم باسترداد الملفات من هذا المجلد.
يمكنك توجيه تجمع SQL بدون خادم لاجتياز المجلدات بتحديد /* في نهاية المسار كما في المثال: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
إشعار
على عكس Hadoop وPolyBase، لا يقوم تجمع SQL بدون خادم بإرجاع المجلدات الفرعية ما لم تحدد /** في نهاية المسار. وتمامًا مثل Hadoop وPolyBase، لا يقوم بإرجاع الملفات التي يبدأ اسمها بتسطير (_) أو نقطة (.).
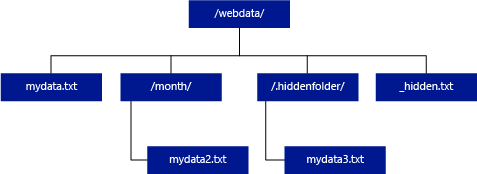
في المثال أدناه، إذا كان unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/، فسيُعيد استعلام تجمع SQL بدون خادم صفوفًا من mydata.txt. ولن يقوم بإرجاع mydata2.txt وmydata3.txt لأنهما موجودان في مجلد فرعي.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
تسمح جملة WITH بتحديد الأعمدة التي تريد قراءتها من الملفات.
بالنسبة لملفات بيانات CSV، ولقراءة كافة الأعمدة، قم بتوفير أسماء الأعمدة وأنواع بياناتها. إذا كنت تريد مجموعة فرعية من الأعمدة، فاستخدم الأرقام الترتيبية لاختيار الأعمدة من ملفات البيانات الأصلية حسب الترتيب. سيتم ربط الأعمدة بالتعيين الترتيبي. إذا كان HEADER_ROW = TRUE يتم ربط العمود بواسطة اسم العمود بدلاً من الموضع الترتيبي.
تلميح
يمكنك حذف جملة WITH لملفات CSV أيضًا. سيتم الاستدلال على أنواع البيانات تلقائيًّا من محتوى الملف. يمكنك استخدام وسيطة HEADER_ROW لتحديد وجود صف رأس في أي حالة ستتم قراءة أسماء الأعمدة من صف الرأس. للحصول على تفاصيل، تحقَّق من الاكتشاف التلقائي للمخطط.
بالنسبة لملفات Parquet أو Delta Lake، قم بتوفير أسماء أعمدة تتطابق مع أسماء الأعمدة في ملفات البيانات الأصلية. سيتم ربط الأعمدة بالاسم وتكون حساسة لحالة الأحرف. إذا تم حذف جملة WITH، فسيتم إرجاع كافة الأعمدة من ملفات Parquet.
هام
أسماء الأعمدة في ملفات Parquet وDelta Lake حساسة لحالة الأحرف. إذا حددت اسم عمود بغلاف مختلف عن غلاف اسم العمود في الملفات، فسيتم إرجاع قيم
NULLلهذا العمود.
column_name = اسم عمود الإخراج. إذا تم توفيره، يتجاوز هذا الاسم اسم العمود في الملف المصدر واسم العمود المتوفر في مسار JSON إذا كان هناك اسم. إذا لم يتم توفير json_path، فستتم إضافتها تلقائيا ك '$.column_name'. تحقق من الوسيطة json_path لمعرفة السلوك.
column_type = نوع البيانات لعمود الإخراج. سيتم تحويل نوع البيانات الضمني هنا.
column_ordinal = الرقم الترتيبي للعمود في الملف (الملفات) المصدر. يتم تجاهل هذه الوسيطة لملفات Parquet عندما يتم الربط بالاسم. قد يرجع المثال التالي عمودًا ثانيًا فقط من ملف CSV:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = تعبير مسار JSON للعمود أو الخاصية المتداخلة. ويكون وضع المسار الافتراضي هو المُسهَل.
إشعار
في الوضع المقيد، سيفشل الاستعلام مع ظهور خطأ إذا كان المسار المقدم غير موجود. في استعلام الوضع المُسهَل، سينجح وسيتم تقييم تعبير مسار JSON إلى NULL.
<bulk_options>
FIELDTERMINATOR = 'field_terminator'
حدد منهي الحقل المراد استخدامه. يكون منهي الحقل الافتراضي هو الفاصلة ("،")
ROWTERMINATOR ='row_terminator''
حدد منهي الصف الذي سيتم استخدامه. إذا لم يتم تحديد فاصل الصف، استخدام أحد الإنهاءات الافتراضية. المُنهيات الافتراضية لـ PARSER_VERSION = '1.0' هي \r\n، و\n و\r. المنهيات الافتراضية لـ PARSER_VERSION = '2.0' هي \r\n و\n.
إشعار
عند استخدام PARSER_VERSION='1.0' وتحديد \n (سطر جديد) كمنهي الصف، سيتم بادئته تلقائيًّا بالحرف \r (إرجاع حرف)، مما يؤدي إلى منهي صف من النوع \r\n.
ESCAPE_CHAR = 'char'
تحدد الحرف في الملف الذي يتم استخدامه لإلغاء نفسه وجميع قيم المحدد في الملف. إذا كان الإلغاء متبوعًا بقيمة أخرى غير نفسها، أو أي من قيم المحدد، فسيتم إسقاط حرف الإلغاء عند قراءة القيمة.
سيتم تطبيق المعلمة ESCAPECHAR بغض النظر عما إذا كان قد تم تمكين FIELDQUOTE أو لا. لن تُستخدَم لإلغاء حرف الاقتباس. يجب أن يكون حرف الاقتباس تم إلغاؤه بحرف اقتباس آخر. يمكن أن يظهر حرف اقتباس داخل قيمة العمود فقط إذا كانت القيمة مغلفة بأحرف اقتباس.
الصف الأول = 'first_row'
تحدد عدد الصف الأول الذي سيتم تحميله. القيمة الافتراضية هي 1 وتُشير إلى الصف الأول في ملف البيانات المحدد. يتم تحديد أرقام الصفوف عن طريق حساب مُنهيات الصفوف. يستند FIRSTROW إلى 1.
FIELDQUOTE = 'field_quote'
تحدد الحرف سيتم استخدامه كحرف اقتباس في ملف CSV. إذا لم يتم التحديد، فسيتم استخدام حرف الاقتباس (").
DATA_COMPRESSION = 'data_compression_method'
تحدد أسلوب الضغط. مدعوم في PARSER_VERSION ='1.0' فقط. يتم اعتماد أسلوب الضغط التالي:
- GZIP
PARSER_VERSION = 'parser_version'
تحدد إصدار محلل لاستخدامه عند قراءة الملفات. إصدارات محلل CSV المدعومة حاليًّا هي 1.0 و2.0:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
ويكون الإصدار 1.0 من محلل CSV افتراضيًّا وثريًّا بالميزات. تم تصميم الإصدار 2.0 للأداء ولا يدعم جميع الخيارات والترميزات.
مواصفات الإصدار 1.0 من محلل CSV:
- الخيارات التالية غير مدعومة: HEADER_ROW.
- المنهيات الافتراضية هي \r\n، و\n و\r.
- إذا حددت \n (سطر جديد) كمُنهي صف، فسيتم بادئته تلقائيًّا بحرف \r (إرجاع حرف)، مما يؤدي إلى مُنهي صف \r\n.
مواصفات الإصدار 2.0 من محلل CSV:
- لا يدعم كافة أنواع البيانات.
- الحد الأقصى لطول عمود الحرف هو 8000.
- الحد الأقصى لحجم الصف هو 8 ميغابايت.
- الخيارات التالية غير مدعومة: DATA_COMPRESSION.
- يتم تفسير السلسلة الفارغة المقتبسة ("") على أنها سلسلة فارغة.
- خيار DATEFORMAT SET غير محترم.
- التنسيق المدعوم لنوع بيانات التاريخ هو: السنة-الشهر-اليوم
- التنسيق المدعوم لنوع بيانات الوقت هو: ساعة:دقيقة:ثانية [اللحظات.]
- التنسيق المدعوم لنوع بيانات DATETIME2: السنة-الشهر-اليوم ساعة:دقيقة:ثانية [.اللحظات]
- وتكون المنهيات الافتراضية هي \r\n و\n.
HEADER_ROW = { صحيح | خطأ }
تحديد إذا ما كان ملف CSV يحتوي على سجل عنوان. الافتراضي FALSE.مدعوم في PARSER_VERSION = '2.0'. في حال كانت TRUE، فستتم قراءة أسماء الأعمدة من الصف الأول وفقًا لوسيطة FIRSTROW. إذا تم تحديد TRUE والمخطط باستخدام WITH، فسيتم ربط أسماء الأعمدة بواسطة اسم العمود، وليس المواضع الترتيبية.
DATAFILETYPE = { 'char' | 'وايدشار' }
يحدد الترميز:charيستخدم لملفات UTF8، ويستخدم widecharلملفات UTF16.
CODEPAGE = { 'ACP' | 'OEM الأصلي' | 'RAW' | 'code_page' }
يحدد صفحة التعليمات البرمجية للبيانات في ملف البيانات. وتكون القيمة الافتراضية هي 65001 (UTF-8 ترميز). راجع المزيد من التفاصيل حول هذا الخيار هنا.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
هذا الخيار سيعطل التحقق من تعديل الملف أثناء تنفيذ الاستعلام، وقراءة الملفات التي يتم تحديثها في أثناء تشغيل الاستعلام. يُعد هذا خيارًا مفيدًا عندما تحتاج إلى قراءة ملفات الإلحاق فقط التي يتم إلحاقها في أثناء تشغيل الاستعلام. في الملفات القابلة للإلحاق، لا يتم تحديث المحتوى الموجود، وتتم إضافة صفوف جديدة فقط. لذلك، يتم تقليل احتمالية حدوث نتائج خاطئة إلى الحد الأدنى مقارنة بالملفات القابلة للتحديث. قد يمكّنك هذا الخيار من قراءة الملفات الملحقة بشكل متكرر دون معالجة الأخطاء. اطلع على مزيد من المعلومات في قسم الاستعلام عن ملفات CSV القابلة للإلحاق.
رفض الخيارات
إشعار
توجد ميزة الصفوف المرفوضة في المعاينة العامة. يُرجى ملاحظة أن ميزة الصفوف المرفوضة تعمل مع الملفات النصية المحددة و PARSER_VERSION 1.0.
يمكنك تحديد معلمات الرفض التي تحدد كيفية تعامل الخدمة مع السجلات المُهملة التي تستردها من مصدر البيانات الخارجي. يُعتبر سجل البيانات "مُهملًا" إذا كانت أنواع البيانات الفعلية لا تتطابق مع تعريفات العمود للجدول الخارجي.
عندما لا تحدد خيارات الرفض أو تغيرها، تستخدم الخدمة قيمًا افتراضية. سوف تستخدم الخدمة خيارات الرفض لتحديد عدد الصفوف التي يمكن رفضها قبل فشل الاستعلام الفعلي. سيعرض الاستعلام نتائج (جزئية) حتى يتم تجاوز حد الرفض. ثم يفشل مع ظهور رسالة الخطأ المناسبة.
MAXERRORS = reject_value
تحديد عدد الصفوف التي يمكن رفضها قبل فشل الاستعلام. ينبغي أن يكون MAXERRORS عددًا صحيحًا بين 0 و2 و147 و483 و647.
ERRORFILE_DATA_SOURCE = مصدر البيانات
تحديد مصدر البيانات حيث ينبغي كتابة الصفوف المرفوضة وملف الخطأ المطابق.
ERRORFILE_LOCATION = موقع الدليل
يحدد الدليل داخل DATA_SOURCE، أو ERROR_FILE_DATASOURCE في حال تم تحديده، ينبغي كتابة الصفوف المرفوضة وملف الخطأ المقابل. في حال لم يكن المسار المحدد موجودًا، فستنشئ الخدمة مسارًا نيابةً عنك. يتم إنشاء دليل فرعي باسم "الصفوف المرفوضة". يضمن الحرف "" تجاوز الدليل لمعالجة البيانات الأخرى ما لم يُذكر صراحةً في معلمة الموقع. داخل هذا الدليل، يوجد مجلد تم إنشاؤه بناءً على وقت إرسال التحميل بالتنسيق YearMonthDay_HourMinuteSecond_StatementID (على سبيل المثال 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). يمكنك استخدام معرف العبارة لربط المجلد بالاستعلام الذي أنشأه. في هذا المجلد، تتم كتابة ملفين: ملف error.json وملف البيانات.
يحتوي ملف error.json على مصفوفة json مع وجود أخطاء متعلقة بالصفوف المرفوضة. يحتوي كل عنصر يمثل خطأ على السمات التالية:
| السمة | الوصف |
|---|---|
| خطأ | سبب رفض الصف. |
| الصف | رقم ترتيب الصف المرفوض في الملف. |
| Column | رقم ترتيب العمود المرفوض. |
| القيمة | قيمة العمود المرفوضة. في حال كانت القيمة أكبر من 100 حرف، فسيتم عرض أول 100 حرف فقط. |
| الملف | مسار الملف الذي ينتمي إليه هذا الصف. |
تحليل النص المحدد بسرعة
هناك إصداران محددان من محلل النص المحدد يمكنك استخدامهما. يكون الإصدار 1.0 من محلل CSV هو الوضع الافتراضي وثري بالميزات بينما تم تصميم الإصدار 2.0 من المحلل لتحسين الأداء. يأتي تحسين الأداء في الإصدار 2.0 من المحلل من تقنيات التحليل المتقدمة ومؤشرات الترابط. وسيكون الفرق في السرعة أكبر كلما كبر حجم الملف.
الاكتشاف التلقائي للمخطط
يمكنك الاستعلام بسهولة عن كل من ملفات CSV وParquet دون معرفة أو تحديد المخطط عن طريق حذف جملة WITH. وسيتم الاستدلال على أسماء الأعمدة وأنواع البيانات من الملفات.
تحتوي ملفات Parquet على بيانات التعريف للعمود الذي ستتم قراءته، ويمكن العثور على تعيينات النوع في type mappings for Parquet. تحقق من قراءة ملفات Parquet دون تحديد مخطط للعينات.
بالنسبة لملفات CSV، يمكن قراءة أسماء الأعمدة من صف العنوان. ويمكنك تحديد إذا ما كان صف الرأس موجودًا باستخدام الوسيطة HEADER_ROW. إذا كان HEADER_ROW = FALSE، فسيتم استخدام أسماء الأعمدة العامة: C1، C2، ... Cn حيث n هو عدد الأعمدة في الملف. سيتم الاستدلال على أنواع البيانات من صفوف البيانات المائة الأولى. تحقق من قراءة ملفات CSV دون تحديد مخطط للعينات.
ضع في اعتبارك أنه إذا كنت تقرأ عدد الملفات في وقت واحد، استنتاج المخطط من خدمة الملفات الأولى التي تحصل عليها من التخزين. قد يعني هذا أنه تم حذف بعض الأعمدة المتوقعة، كل ذلك لأن الملف المستخدم من قبل الخدمة لتعريف المخطط لم يحتوي على هذه الأعمدة. في هذه الحالة، استخدم عبارة OPENROWSET WITH.
هام
هناك حالات لا يمكن فيها الاستدلال على نوع البيانات المناسب؛ بسبب نقص المعلومات وسيتم استخدام نوع البيانات الأكبر بدلاً من ذلك. ويؤدي ذلك إلى زيادة الأداء وهو مهم بشكل خاص لأعمدة الأحرف التي سيتم استنتاجها كـ varchar(8000). للحصول على الأداء الأمثل، تحقق من أنواع البيانات المستنتجة واستخدم أنواع البيانات المناسبة.
تعيين النوع لـ Parquet
تحتوي ملفات Parquet وDelta Lake على أوصاف نوع لكل عمود. يصف الجدول التالي كيفية تعيين أنواع Parquet إلى أنواع SQL الأصلية.
| نوع Parquet | نوع منطقي من Parquet (تعليق توضيحي) | نوع بيانات SQL |
|---|---|---|
| BOOLEAN | بت | |
| ثنائي / BYTE_ARRAY | varbinary | |
| مزدوج | عائم | |
| حُر | real | |
| INT32 | العدد الصحيح | |
| INT64 | عدد صحيح كبير | |
| INT96 | التاريخ والوقت2 | |
| FIXED_LEN_BYTE_ARRAY | binary | |
| ثنائي | UTF8 | varchar *(ترتيب UTF8) |
| ثنائي | سلسلة | varchar *(ترتيب UTF8) |
| ثنائي | قائمة تعداد | varchar *(ترتيب UTF8) |
| FIXED_LEN_BYTE_ARRAY | Uuid | uniqueidentifier |
| ثنائي | عشري | عشري |
| ثنائي | JSON | varchar(8000) *(تجميع UTF8) |
| ثنائي | BSON | غير مدعوم |
| FIXED_LEN_BYTE_ARRAY | عشري | عشري |
| BYTE_ARRAY | الفاصل | غير مدعوم |
| INT32 | INT(8، صحيح) | Smallint |
| INT32 | INT(16، صحيح) | Smallint |
| INT32 | INT(32، صحيح) | العدد الصحيح |
| INT32 | INT (8، خطأ) | Tinyint |
| INT32 | INT (16، خطأ) | العدد الصحيح |
| INT32 | INT (32، خطأ) | عدد صحيح كبير |
| INT32 | التاريخ | date |
| INT32 | عشري | عشري |
| INT32 | الوقت (مللي ثانية) | time |
| INT64 | INT(64، صحيح) | عدد صحيح كبير |
| INT64 | INT(64, خطأ) | عشري(20، 0) |
| INT64 | عشري | عشري |
| INT64 | الوقت (ميكرو ثانية) | time |
| INT64 | الزمن (النانو) | غير مدعوم |
| INT64 | الطابع الزمني (تم تطبيعه إلى UTC) (MILLIS / MICROS) | التاريخ والوقت2 |
| INT64 | الطابع الزمني (غير محدد إلى UTC) (ميليس / ميكروس) | bigint - تأكد من ضبط القيمة bigint بوضوح مع إزاحة المنطقة الزمنية قبل تحويلها إلى قيمة التاريخ والوقت. |
| INT64 | الطابع الزمني (النانو) | غير مدعوم |
| نوع معقد | قائمة | varchar(8000)، متسلسل إلى JSON |
| نوع معقد | تعيين | varchar(8000)، متسلسل إلى JSON |
الأمثلة
قراءة ملفات CSV دون تحديد المخطط
يقرأ المثال التالي ملف CSV الذي يحتوي على صف رأس دون تحديد أسماء الأعمدة وأنواع البيانات:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
يقرأ المثال التالي ملف CSV الذي لا يحتوي على صف رأس دون تحديد أسماء الأعمدة وأنواع البيانات:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
قراءة ملفات Parquet دون تحديد مخطط
يُرجع المثال التالي كافة أعمدة الصف الأول من مجموعة بيانات التعداد، بتنسيق Parquet، ودون تحديد أسماء الأعمدة وأنواع البيانات:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
قراءة ملفات Delta Lake دون تحديد المخطط
يُرجع المثال التالي كافة أعمدة الصف الأول من مجموعة بيانات التعداد، بتنسيق Delta Lake، ودون تحديد أسماء الأعمدة وأنواع البيانات:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
قراءة أعمدة معينة من ملف CSV
يُرجع المثال التالي عمودين فقط مع أرقام ترتيبية 1 و4 من ملفات population*.csv. نظرًا لوجود صف رأس في الملفات، فإنه يبدأ القراءة من السطر الأول:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
قراءة أعمدة معينة من ملف Parquet
يُرجع المثال التالي عمودين فقط من الصف الأول من مجموعة بيانات التعداد، في تنسيق Parquet:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
تحديد أعمدة باستخدام مسارات JSON
يوضح المثال التالي كيفية استخدام تعبيرات مسار JSON في جملة WITH ويوضح الفرق بين أوضاع المسار المقيد والمُسهَل:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
تحديد ملفات/ مجلدات متعددة في مسار BULK
يوضح المثال التالي كيفية استخدام عدة مسارات الملفات/ المجلدات في المعلمة BULK:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
الخطوات التالية
لمزيد من العينات، راجع التشغيل السريع لتخزين بيانات الاستعلام لمعرفة كيفية استخدام OPENROWSET لقراءة CSV، وPARQUET، وDELTA LAKE، وتنسيقات ملف JSON. تحقق من أفضل الممارسات لتحقيق الأداء الأمثل. يمكنك أيضًا معرفة كيفية حفظ نتائج الاستعلام إلى تخزين Azure باستخدام CETAS.