أحجام الأجهزة الظاهرية من سلسلة HBv2
ينطبق على: ✔️ أجهزة ظاهرية بنظام التشغيل Linux ✔️ أجهزة ظاهرية بنظام التشغيل Windows ✔️ مجموعات التوسعة المرنة ✔️ مجموعات التوسعة الموحدة
تم تشغيل العديد من اختبارات الأداء على حجم الأجهزة الظاهرية من سلسلةHBv2. فيما يلي بعض نتائج اختبار الأداء هذا.
| حمل العمل | HBv2 |
|---|---|
| ثلاثية STREAM | 350 جيجابايت/ثانية (21-23 جيجابايت/ثانية لكل CCX) |
| Linpack (HPL) عالي الأداء | 4 TeraFLOPS (Rpeak, FP64), 8 TeraFLOPS (Rmax, FP32) |
| زمن انتقال RDMA وعرض النطاق الترددي | 1.2 ميكروثانية، 190 جيجابت/ثانية |
| FIO على NVMe SSD المحلي | 2.7 غيغابايت / ثانية يقرأ، 1.1 غيغابايت / ثانية يكتب؛ 102k IOPS يقرأ، 115 IOPS يكتب |
| IOR على 8 * Azure Premium SSD (P40 الأقراص المدارة، RAID0)** | 1.3 غيغابايت / ثانية يقرأ، 2.5 غيغابايت / يكتب؛ 101k IOPS يقرأ، 105k IOPS يكتب |
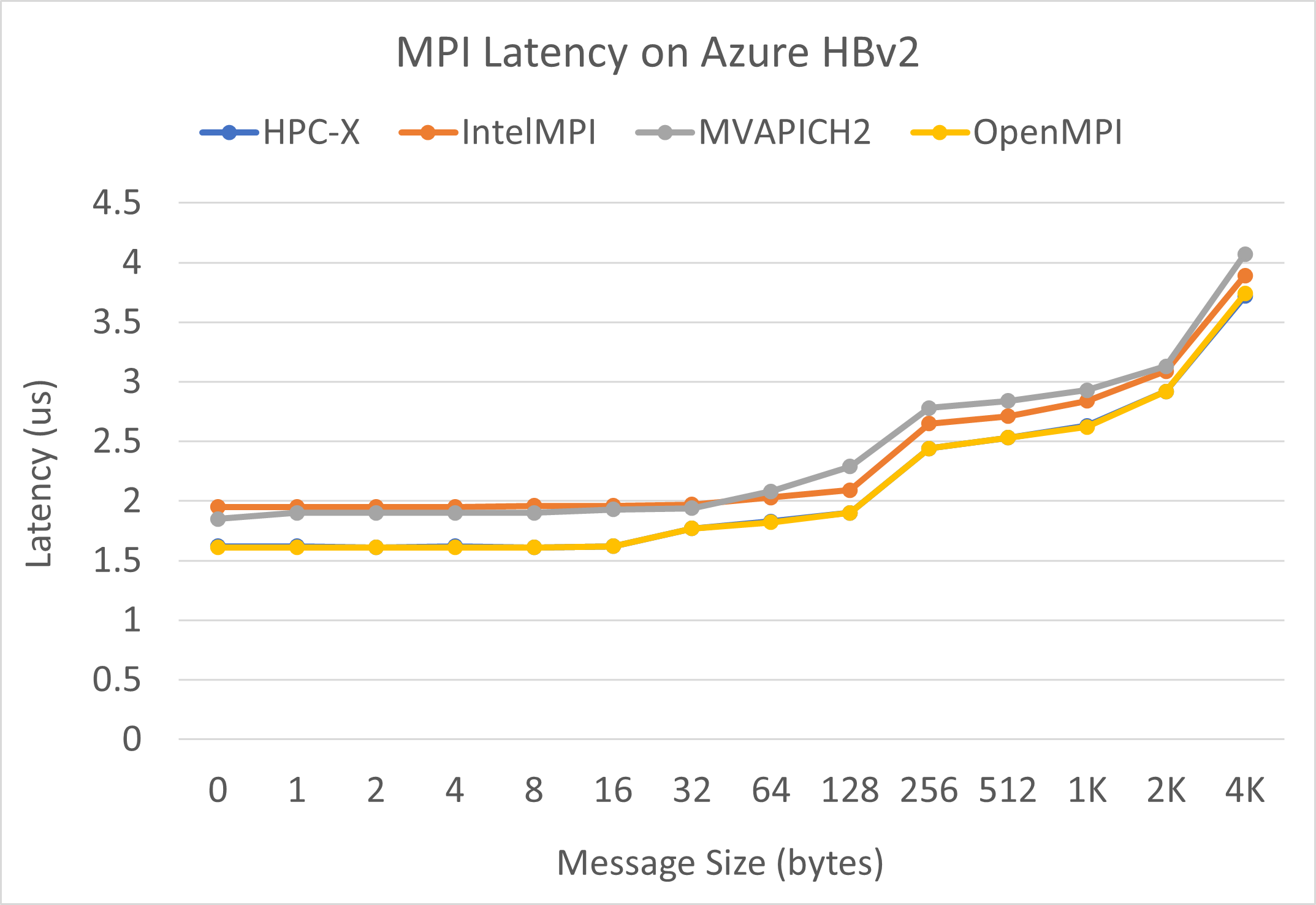
زمن انتقال MPI
يتم تشغيل اختبار زمن انتقال MPI من مجموعة المعايير الدقيقة OSU. نماذج البرامج النصية موجودة على GitHub.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
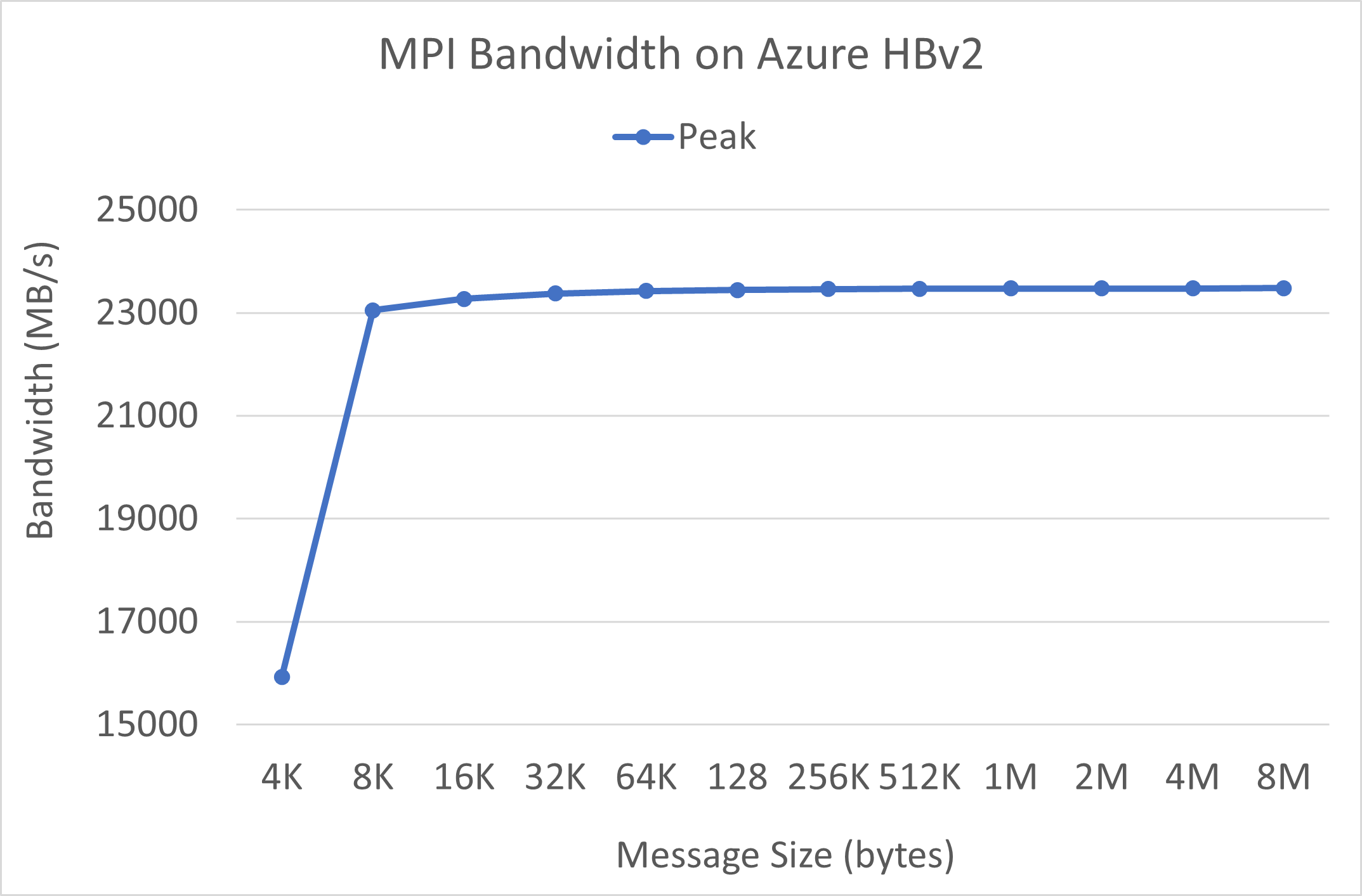
عرض النطاق الترددي MPI
يتم تشغيل اختبار النطاق الترددي MPI من مجموعة المعايير الدقيقة OSU. نماذج البرامج النصية موجودة على GitHub.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
تحتوي حزمة Mellanox Perftest على العديد من اختبارات InfiniBand مثل زمن انتقال (ib_send_lat) والنطاق الترددي (ib_send_bw). يوجد مثال على الأمر أدناه.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
الخطوات التالية
- اقرأ بشأن أحدث الإعلانات، والأمثلة حول حمل عمل الحوسبة عالية الأداء (HPC)، ونتائج الأداء في مدوّنات المجتمع التقني حول الحساب في Azure.
- من أجل عرض هندسي ذي مستوى أعلى لتشغيل أحمال عمل HPC، راجع الحوسبة عالية الأداء (HPC) على Azure.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ