حدث
٢ شوال، ١١ م - ٤ شوال، ١١ م
أكبر حدث تعلم Fabric وPower BI وSQL. 31 مارس – 2 أبريل. استخدم التعليمات البرمجية FABINSIDER لتوفير 400 دولار.
تسجيل اليوملم يعد هذا المتصفح مدعومًا.
بادر بالترقية إلى Microsoft Edge للاستفادة من أحدث الميزات والتحديثات الأمنية والدعم الفني.
In this tutorial, learn how to read/write data into your Fabric lakehouse with a notebook. Fabric supports Spark API and Pandas API are to achieve this goal.
In the code cell of the notebook, use the following code example to read data from the source and load it into Files, Tables, or both sections of your lakehouse.
To specify the location to read from, you can use the relative path if the data is from the default lakehouse of your current notebook. Or, if the data is from a different lakehouse, you can use the absolute Azure Blob File System (ABFS) path. Copy this path from the context menu of the data.
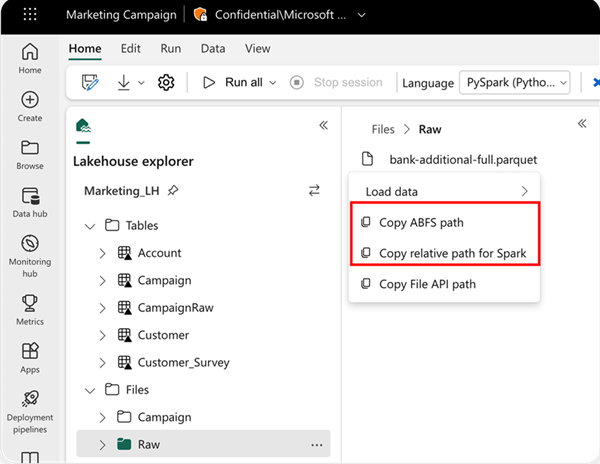
Copy ABFS path: This option returns the absolute path of the file.
Copy relative path for Spark: This option returns the relative path of the file in your default lakehouse.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
To support Pandas API, the default lakehouse is automatically mounted to the notebook. The mount point is '/lakehouse/default/'. You can use this mount point to read/write data from/to the default lakehouse. The "Copy File API Path" option from the context menu returns the File API path from that mount point. The path returned from the option Copy ABFS path also works for Pandas API.
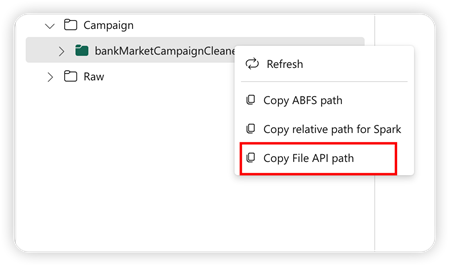
Copy File API Path: This option returns the path under the mount point of the default lakehouse.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
تلميح
For Spark API, please use the option of Copy ABFS path or Copy relative path for Spark to get the path of the file. For Pandas API, please use the option of Copy ABFS path or Copy File API path to get the path of the file.
The quickest way to have the code to work with Spark API or Pandas API is to use the option of Load data and select the API you want to use. The code is automatically generated in a new code cell of the notebook.

حدث
٢ شوال، ١١ م - ٤ شوال، ١١ م
أكبر حدث تعلم Fabric وPower BI وSQL. 31 مارس – 2 أبريل. استخدم التعليمات البرمجية FABINSIDER لتوفير 400 دولار.
تسجيل اليومالتدريب
الوحدة النمطية
استخدام Apache Spark في Microsoft Fabric - Training
Apache Spark هي تقنية أساسية لتحليلات البيانات واسعة النطاق. يوفر Microsoft Fabric الدعم لمجموعات Spark، ما يتيح لك تحليل البيانات ومعالجتها على نطاق واسع.
الشهادة
Microsoft Certified: Fabric Data Engineer Associate - Certifications
بصفتك مهندس بيانات النسيج، يجب أن يكون لديك خبرة في الموضوع مع أنماط تحميل البيانات وبنى البيانات وعمليات التزامن.
الوثائق
Develop, execute, and manage notebooks - Microsoft Fabric
Learn how to author, execute, and manage Microsoft Fabric notebook jobs with rich built-in features.
Author and run T-SQL notebooks in Microsoft Fabric - Microsoft Fabric
Learn how to author and run T-SQL code in a notebook within the data engineering workload. Also learn how to run cross warehouse queries.
Read and write data with Pandas - Microsoft Fabric
Learn how to read and write lakehouse data in a notebook using Pandas, a popular Python library for data exploration and processing.