حدث
٢ شوال، ١١ م - ٤ شوال، ١١ م
أكبر حدث تعلم Fabric وPower BI وSQL. 31 مارس – 2 أبريل. استخدم التعليمات البرمجية FABINSIDER لتوفير 400 دولار.
تسجيل اليوملم يعد هذا المتصفح مدعومًا.
بادر بالترقية إلى Microsoft Edge للاستفادة من أحدث الميزات والتحديثات الأمنية والدعم الفني.
In this tutorial, you ingest more dimensional and fact tables from the Wide World Importers (WWI) into the lakehouse.
In this section, you use the Copy data activity of the Data Factory pipeline to ingest sample data from an Azure storage account to the Files section of the lakehouse you created earlier.
Select Workspaces in the left navigation pane, and then select your new workspace from the Workspaces menu. The items view of your workspace appears.
From the New item option in the workspace ribbon, select Data pipeline.
In the New pipeline dialog box, specify the name as IngestDataFromSourceToLakehouse and select Create. A new data factory pipeline is created and opened.
Next, set up an HTTP connection to import the sample World Wide Importers data into the Lakehouse. From the list of New sources, select View more, search for Http and select it.

In the Connect to data source window, enter the details from the table below and select Next.
| Property | Value |
|---|---|
| URL | https://assetsprod.microsoft.com/en-us/wwi-sample-dataset.zip |
| Connection | Create a new connection |
| Connection name | wwisampledata |
| Data gateway | None |
| Authentication kind | Anonymous |

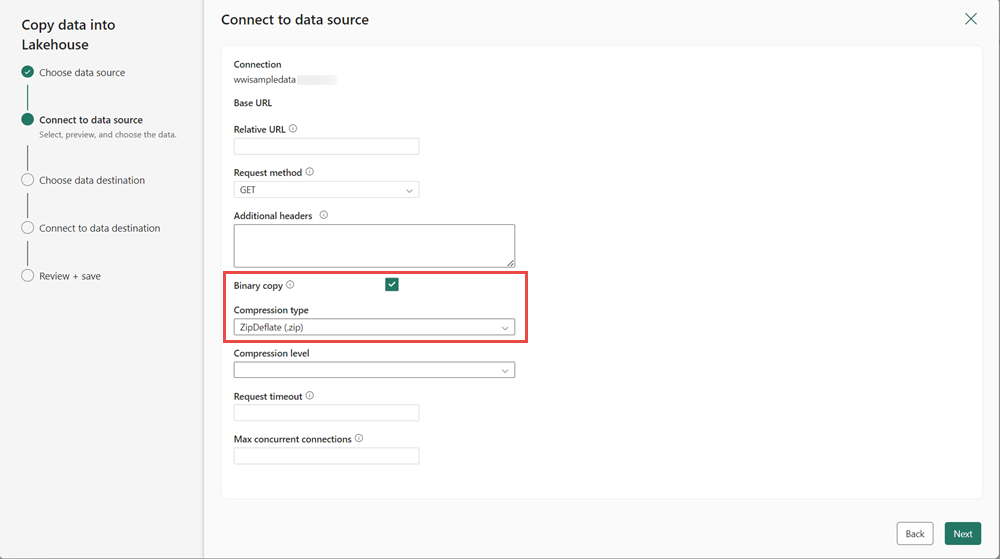
In the next step, enable the Binary copy and choose ZipDeflate (.zip) as the Compression type since the source is a .zip file. Keep the other fields at their default values and click Next.
In the Connect to data destination window, specify the Root folder as Files and click Next. This will write the data to the Files section of the lakehouse.

Choose the File format as Binary for the destination. Click Next and then Save+Run. You can schedule pipelines to refresh data periodically. In this tutorial, we only run the pipeline once. The data copy process takes approximately 10-15 minutes to complete.

You can monitor the pipeline execution and activity in the Output tab. You can also view detailed data transfer information by selecting the glasses icon next to the pipeline name, which appears when you hover over the name.

After the successful execution of the pipeline, go to your lakehouse (wwilakehouse) and open the explorer to see the imported data.

Verify that the folder WideWorldImportersDW is present in the Explorer view and contains data for all tables.

The data is created under the Files section of the lakehouse explorer. A new folder with GUID contains all the needed data. Rename the GUID to wwi-raw-data
To load incremental data into a lakehouse, see Incrementally load data from a data warehouse to a lakehouse.
حدث
٢ شوال، ١١ م - ٤ شوال، ١١ م
أكبر حدث تعلم Fabric وPower BI وSQL. 31 مارس – 2 أبريل. استخدم التعليمات البرمجية FABINSIDER لتوفير 400 دولار.
تسجيل اليومالتدريب
الوحدة النمطية
تحميل البيانات في مستودع بيانات علائقية - Training
تعرف على كيفية تحميل الجداول في مستودع بيانات ارتباطي مستضاف في تجمع SQL مخصص في Azure Synapse Analytics.
الشهادة
Microsoft Certified: Fabric Data Engineer Associate - Certifications
بصفتك مهندس بيانات النسيج، يجب أن يكون لديك خبرة في الموضوع مع أنماط تحميل البيانات وبنى البيانات وعمليات التزامن.
الوثائق
Lakehouse tutorial - Build a report - Microsoft Fabric
After ingesting data, and using notebooks to transform and prepare the data, you create a Power BI data model and create a report.
Lakehouse tutorial - clean up resources - Microsoft Fabric
As a final step in the tutorial, clean up your resources. Learn how to delete individual reports, pipelines, warehouses, or remove the entire workspace.
Lakehouse tutorial - Create your first lakehouse - Microsoft Fabric
Learn how to create a lakehouse, ingest data into a table, transform it, and use the data to create reports.