بنية البيانات وتدفق الرسم البياني
- 17 دقائق
تم تطوير GraphLab من قبل Carnegie Mellon University ويقدم مثالاً على محركات التحليلات الموزَّعة الموازية للرسوم البيانية للسحابة. كما هو الحال مع أي محرك موازٍ للرسم البياني، يفترض GraphLab مشاكل الإدخال على غرار الرسوم البيانية، والتي تمثل فيها الذروات الحسابات وتعمل الحواف على ترميز تبعيات البيانات أو التواصل.
تطور GraphLab وإصداراته
تم تطوير GraphLab في البداية كإطار عمل معالجة الرسم البياني والذي يستهدف أنظمة الذاكرة المشتركة (الأجهزة ذات الذاكرة الأساسية المتعددة)1. تضمن بعدها GraphLab محرك تنفيذ موزَّعًا للسماح بحساب رسوم بيانية كبيرة للغاية عبر نظام مجموعة أجهزة.2PowerGraph3 (يعرف أيضًا باسم GraphLab 2.0) ظهر مستخدمًا تقنيات سمحت بمعالجة موزَّعة أسرع للرسوم البيانية التي اتبعت توزيع قانون القوة (مثل الرسوم البيانية الاجتماعية). وقد تم تحويل GraphLab منذ ذلك الحين إلى بدء التشغيل التجاري المعروف باسم Dato Inc.، والتي توفر حزمة GraphLab لإنشاء البرامج. ستغطي مناقشتنا حول GraphLab في هذه الوحدة النمطية أحدث نسخة مفتوحة المصدر، PowerGraph (GraphLab 2.0).
في GraphLab، يتم تخزين الرسومات البيانية في البداية كملفات في طبقة تخزين موزَّعة أساسية، مثل HDFS، كما هو موضح في الشكل 5. يتكون GraphLab من طورين: التهيئة والتنفيذ. في أثناء التهيئة، يقرأ محرك GraphLab ملفات رسم الإدخال البياني من التخزين الأساسي ويقسمها إلى أقسام متعددة يمكن توزيعها بين أجهزة متعددة في نظام المجموعة. في أثناء طور التنفيذ، يعمل كل جهاز على تشغيل الحساب المعرف من قبل المستخدم على ذروات الرسم البياني، ما يرسل التحديثات ويعمل على التكرار حتى يتم استيفاء بعض شروط التقارب.
طور التهيئة
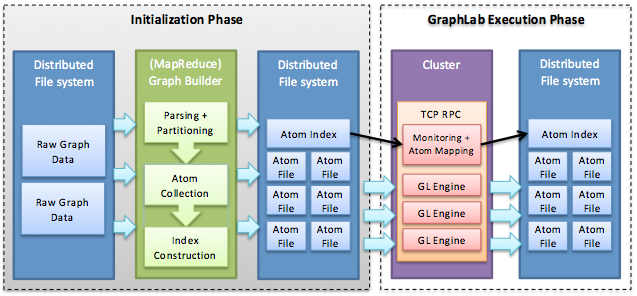
الشكل 5: نظام GraphLab. في طور التهيئة، يتم إنشاء الذرات باستخدام MapReduce (على سبيل المثال). في طور تنفيذ GraphLab، يتم تعيين الذرات إلى أجهزة نظام مجموعة وتحميلها بواسطة أجهزة من نظام الملفات الموزَّعة (على سبيل المثال، HDFS).
في الطور الأول، ينقسم رسم الإدخال البياني إلى أقسام k تسمى ذرات، حيث k أكبر بكثير من عدد من أجهزة نظام مجموعة. وكما هو موضح في الشكل 5، يمكن بناء الذرات إما بالتتابع أو باستخدام تقنيات التحميل الموازية، بما في ذلك MapReduce. لا يعمل GraphLab على تخزين الذروات والحافات الفعلية في الذرات بل يخزن الأوامر لإنشائها، في شكل دفتر يومية. وهذا يسمح لـ GraphLab بإعادة بناء أجزاء من الرسم البياني في حالة فشل العقدة. بالإضافة إلى ذلك، يحافظ GraphLab على معلومات حول الذروات والحواف المجاورة في كل ذرة. هذه المعلومات، المشار إليها في GraphLab كـ نسخ ذروات توفر التخزين المؤقت لإمكانية الوصول إلى البيانات المجاورة بكفاءة.
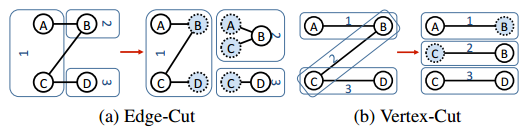
الشكل 6: إستراتيجيات تقسيم Microsoft Azure Active Directory Graph. (أ) يوضح أسلوب التقسيم المقتطع من الحافة، بينما (ب) يوضح تقنية المقتطع من الذروة.
يمكن تقسيم الرسم البياني عبر أجهزة نظام مجموعة بعدد من الطرق (الشكل 6). تقنية بسيطة هي المقتطع من الحافة، حيث يتم تقسيم الرسم البياني على طول كل ذروة (الشكل 6 (أ)). يتم تعيين كل ذروة بشكل عشوائي إلى جهاز مع كل الحواف المرتبطة به. ونتيجة لذلك، يتم إنشاء نسخ ذروات بحيث يمكن أن تكون الحواف مرتبطة بذروة غير موجودة في جهاز معين. ومع ذلك، بالنسبة إلى الرسوم البيانية مع توزيع قانون القوة من الحواف، هذا يعني أن تقسيم المقتطع من الحافة سيكون غير متوازن وستكون بعض الأجهزة أكثر تحميلاً من غيرها (نظرًا إلى الرسوم التعبيرية مثل النجوم من عدد قليل من الذروات). للتعامل مع مثل هذه الرسوم البيانية، يستخدم GraphLab تقنية جديدة (تعرف باسم مقتطعات الذروة المكثفة)لتقسيم الذروات عالية الدرجة عبر الأجهزة من أجل توزيع الحساب بشكل أكثر فعالية. يتم نسخ الذروات عالية الدرجة نسخة متماثلة عبر الأجهزة، حيث يتلقى كل جهاز مجموعة فرعية من حواف تلك الذروة (الشكل 6 (ب)). يتم تحديد الجهاز الذي يحمل حافة معينة لذروة باستخدام الخوارزمية التالية:
الخوارزمية 1
مقتطعات الحافة المكثفة لوضع حافة $e = \lbrace v_{i}, v_{j} \rbrace$ للذروة $v_{i}$:
إذا كان هناك جهاز تم تعيين كل من $v_{i}$ و$v_{j}$ له، فقم
- بتعيين $v_{j}$ إلى هذا الجهاز
وغير ذلك إذا تم تعيين $v_{i}$ و$v_{j}$ إلى أجهزة مختلفة، فقم
- بتعيين $e$ إلى الجهاز الذي يحتوي على أقل عدد من الحواف المعينة له
وغير ذلك
- قم بتعيين $e$ إلى الجهاز الأقل تحميلاً
قم بتمييز الحافة $e$ كما تم تعيينها
يمكن القيام بتحميل هذه الأقسام بطريقة موزَّعة ومنسقة، ما يضمن أن تعيين الذروات والحافات عبر نظام المجموعة هو الأمثل، ولكن الوقت المُتَّخَذ للتحميل هو أعلى بكثير من وضع عشوائي. من ناحية أخرى، سيؤدي الوضع العشوائي إلى تحميل غير متوازن وفقدان المنطقة. تسوية بين هذين النهجين، حيث كل جهاز يقدر تعيينات الحواف والذروات في نظام المجموعة، هي المقايضة المقترحة في "PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs."3
ومع ذلك، يحتاج المستخدمون إلى تخزين الرسوم البيانية بتنسيقات يمكن استهلاكها وتحليلها بواسطة GraphLab في أثناء مرحلة التهيئة. ومن الواضح أن هذا يعتمد على طبقة التخزين الأساسية ومحرك التحليل الذي يستخدمه GraphLab. على سبيل المثال، إذا تم استخدام MapReduce لقراءة ملفات رسم الإدخال البياني من HDFS وتحليلها، يجب تنسيق ملفات رسم الإدخال البياني باستخدام بنية بيانات قيم المفاتيح لدى MapReduce.
يعمل إنشاء ذرات لرسم إدخال بياني معين على إكمال الطور الأول من استراتيجية تقسيم GraphLab. فيما بعد، يخزن المحرك بنية الاتصال ومواقع الذرة في ملف فهرسة مشار إليه أيضًا كـ رسم بياني تعريفي (شكل 5). ملف فهرس الذرة يشمل ذروات k، كل ذروة مقابلة لذرة، وحافات تعمل على ترميز الاتصال فيما بينها. في الطور الثاني، يتم تقسيم ملف فهرس ذرة بالتساوي عبر أجهزة نظام المجموعة. ثم يتم تحميل الذرات بواسطة أجهزة نظام المجموعة، ويعمل كل جهاز على إنشاء أقسامها للرسم البياني المعين عن طريق تنفيذ دفتر اليومية في كل ذرة من الذرات المخصصة له. عن طريق إنشاء أقسام من دفاتر الذرات اليومية (وليس مباشرة تخطيط الأقسام إلى أجهزة نظام المجموعة)، يسمح GraphLab بتغييرات الرسم البياني في المستقبل على أن يتم إلحاقها ببساطة كأوامر دفتر اليومية، دون الحاجة إلى إعادة تقسيم الرسوم البيانية بأكملها. وعلاوة على ذلك، يمكن إعادة استخدام ذرات الرسم البياني ذاته لأحجام نظام المجموعة المختلفة ببساطة من خلال إعادة تقسيم ملف فهرس الذرة المقابلة وإعادة تنفيذ دفاتر الذرة اليومية، ومن ثم تكرار فقط طور التقسيم الثاني.
بناء أقسام الرسم البياني في أجهزة نظام المجموعة يختتم طور تهيئة GraphLab، ويبدأ طور التنفيذ.
طور التنفيذ
كما هو موضح في الشكل 5، يعمل كل جهاز نظام مجموعة على تشغيل مثيل من محرك GraphLab، الذي يتضمن جزأين رئيسيين: الرسم البياني للبيانات، والدالات المعرفة من قبل المستخدم التي تعمل على الرسم البياني للبيانات. يمثل الرسم البياني للبيانات حالة برنامج المستخدم في جهاز نظام المجموعة ويتضمن رسمًا بيانيًا موجهًا $G = (V, E, D)$، حيث $V$ هو مجموعة الذروات، و$E$ هي مجموعة الحواف، و$D$ هي البيانات المعرفة من قبل المستخدم (على سبيل المثال، المعلمات وبيانات إدخال المستخدم وحتى البيانات الإحصائية). في GraphLab، ترتبط البيانات بكل من الذروات والحافات.
ثم يتم تمثيل الحساب على أنه برنامج عديم الحالة يتم تنفيذه على كل ذروة من الرسم البياني بالتوازي. يتكون هذا البرنامج من ثلاث أطوار متميزة: الجمع والتطبيق والمبعثر (GAS).
طور الجمع:في طور الجمع، تجمع كل ذروة (يشار إليها من الآن فصاعدًا بالذروة المركزية) معلومات من الذروات والحافات المجاورة. بإمكان GraphLab بعد ذلك تطبيق عملية تجميع أو مجموع معرفة من قبل المستخدم:
$$\Sigma \leftarrow \bigoplus_{\substack{v \in Nbr[u]}} g(D_{u}, D_{u, v}, D_{v})$$
في المعادلة أعلاه، تشير $D_{u}$ و$D_{v}$ و$D_{u, v}$ إلى القيم والبيانات التعريفية للذروات $u$ و$v$ وحافة $(u, v)$، على التوالي. يجب أن تكون عملية المجموع المعرفة من قبل المستخدم ($\bigoplus$) تبادلية وإقرانية، ويمكن أن تتراوح بين المجموع العددي وتوحيد البيانات على كل الذروات والحافات المجاورة.
طور التطبيق: في طور التطبيق، يتم استخدام القيمة الناتجة $\Sigma$ لتحديث قيمة الذروة المركزية:
$$D_u^{new} \leftarrow a(D_{u}, \Sigma)$$
طور المبعثر: أخيرًا، في طور المبعثر، يتم إرسال القيمة الجديدة للذروة المركزية إلى كل الذروات المجاورة:
$$\forall v \in Nbr[u]:(D_{(u, v)}) \leftarrow s(D_u^{new}, D_{u, v}, D_{v})$$
مع نهاية عملية المبعثر، يتم إكمال تكرار واحد لحساب الذروة.
يتم تنفيذ دالات GAS على مجموعة من الذروات النشطة على كل تكرار. في أثناء التكرار الأولي، يتم وضع كل الذروات في مجموعة الذروات النشطة. استنادًا إلى منطق دالات GAS، يمكن أن تعمل ذروة على تمييز أحد الجيران على أنه نشط، بحيث يمكن حسابه في التكرار التالي.
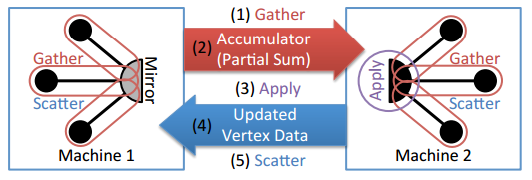
الشكل 7: تنفيذ دالات التجميع والتطبيق والمبعثر على جهازين التي هي مجموعة فرعية من حواف الذروة ذاتها.
يوضح الشكل نمط الاتصال الناتج عن استخدام دالات GAS على رسم بياني مقسم باستخدام خوارزمية المقتطع من الحافة المكثف الموصوف سابقًا. تعمل دالات الجمع محليًا على كل جهاز يحتوي على نسخة ذروة. في أثناء التراكم، يتم إرسال هذه القيم المجمعة إلى الجهاز الذي يحتوي على النسخة الرئيسية من الذروة، حيث يمكن حساب الدالة المعرفة في مرحلة التطبيق. وأخيرًا، يتم نسخ بيانات الذروة المحدثة إلى كل الأجهزة التي تحتوي على نسخ خفية من الذروة، ويتم تنفيذ دالة المبعثر لنشر القيم إلى الذروات المجاورة.
تخزين delta المؤقت: هناك حالات حيث سيتم تشغيل برنامج ذروة (جعله نشطًا) بسبب تغيير في عدد قليل فقط من الجيران. عندما يتم تشغيل الذروة، فإنه سيتم تنفيذ عملية جمع من كل الجيران، وكثير منها لم يتم تنفيذه ومن ثم سترجع القيم التي لم تتغير منذ آخر مرة تم تشغيل هذه الذروة المعينة. يقدم GraphLab تحسينًا خفيًا يسمى تخزين delta المؤقت، حيث يتم تخزين نتيجة عمليات الجمع من كل جيران الذروة في ذاكرة التخزين المؤقت في تلك الذروة. في أثناء عملية المبعثر التي يتم تشغيلها في الذروات المجاورة، يمكن إرسال معلمة اختيارية، $\Delta a$، لتلخيص التغيير في قيمة المتغيّر $a$ بين التكرارات. يمكن استخدام هذه القيمة لتجاوز طور الجمع وإضافتها إلى القيمة المخزنة مؤقتًا $a$ لتسريع التنفيذ.
المراجع
- ي. لو، ج. غونزاليس، أ. كيرولا، د. بيكسون، سي غيدرين، وجي.M هيلرشتاين (2010). GraphLab: إطار عمل موازٍ جديد للتعلم الآلي مؤتمر بشأن عدم اليقين في الذكاء الاصطناعي (UAI)
- ي. لو، ج. غونزاليس، أ. كيرولا، د. بيكسون، سي غيدرين، وجي.M هيلرشتاين (2012). نظام GraphLab الموزع: إطار عمل للتعلم الآلي والبيانات المخزنة في السحابة PVLDB
- ي. غونزاليس ، واي لو ، إتش جو ، دي بيكسون ، وسي جوسترين (أكتوبر 2012). PowerGraph: حساب الرسوم البيانية الموازية الموزعة على الرسوم البيانية الطبيعية في وقائع مؤتمر USENIX العاشر بشأن تصميم أنظمة التشغيل وتطبيقها
اختبر معلوماتك
الملاحظات
هل كانت هذه الصفحة مفيدة؟
لا
هل تحتاج إلى مساعدة مع هذا الموضوع؟
هل تريد محاولة استخدام Ask Learn لتوضيح هذا الموضوع أو إرشادك خلاله؟