أنظمة المعالجة المتدفقة
- 11 دقائق
صُمِمَت الأطر التي ألقينا نظرة عليها (MapReduce, Spark, GraphLab) لإجراء حساب الدفعات. وعادة ما تكون مدخلاتها مجموعات بيانات كبيرة موزعة، تتم معالجتها لعدة ساعات لإنتاج مخرجات كبيرة ومفيدة. كان استخدام هذه الأطر في الأصل مقتصرًا على علماء البيانات والمبرمجين، الذين استخدموها لاستفسارات محددة وكبيرة حيث كان زمن الانتقال العالي هذا مقبولاً. ومع ذلك، ونظرًا إلى اكتساب استخدام البيانات الضخمة انتشارًا داخل المؤسسات، كان هناك تحرك نحو الاستعلام المخصص للبيانات، مع فترات انتقال متوقعة بالدقائق وليس بالساعات. سمحت أدوات مثل Pig وHive وShark وSpark SQL للعديد من الشركات بطرح أسئلة معقدة عن بياناتها، دون الاعتماد على مجموعة كبيرة من المبرمجين المدربين تدريبًا عاليًا. وقادت مجموعة هذا الاعتماد إلى ما هو أبعد من ذلك، حيث وفرت إمدادًا مرنًا لموارد الحساب طوال مدة الاستعلام المخصص.
وسرعان ما أصبحت توقعات زمن الانتقال أقل. وبدأ تلقي البيانات الضخمة في الوقت الحقيقي، وكانت في كثير من الأحيان ذات قيمة فقط لفترة قصيرة. على سبيل المثال، تطلبت محركات البحث تقديم أفضل مجموعة من الإعلانات في غضون مللي ثانية لكل استعلام، واكتشفت مواقع التواصل الاجتماعي الاتجاهات والمواضيع المتداولة والكلمات الرئيسية، واكتشفت أدوات مراقبة النظام أنماطًا معقدة عبر العديد من مكونات البنية الأساسية الكبيرة. ولاكتساب القدرة على توفير أزمنة الانتقال المنخفضة هذه، بدأت فئة جديدة من أطر المعالجة المتدفقة في التكون. وكانت لها متطلبات وقيود مختلفة اختلافًا جوهريًا عن أنظمة المعالجة الدفعية والتفاعلية للسابق.
وأدى ذلك إلى ظهور أنظمة المعالجة المتدفقة.
المعالجة المتدفقة
يطبق نموذج المعالجة المتدفقة سلسلة من العمليات على كل عنصر من عناصر البيانات المُرسلة من مصدر بيانات إدخال طويل بلا حدود. يتم تنظيم سلسلة العمليات بشكل عام والذي يضيف تبعيات بين العمليات. وداخل تطبيق المعالجة، غالبًا ما تتم قراءة وكتابة معلومات الحالة إلى مصدر بيانات صغير وسريع. يعد إخراج البنية الأساسية لبرنامج ربط العمليات التجارية لعمليات التدفق هو أيضًا تدفق بيانات. ويمكن استخدام هذا لتشغيل تطبيقات أخرى، أو يمكن تخزينها مؤقتًا وتخزينها في المخزن المستقر. يرد أدناه البنية المفاهيمية لهذا النظام.
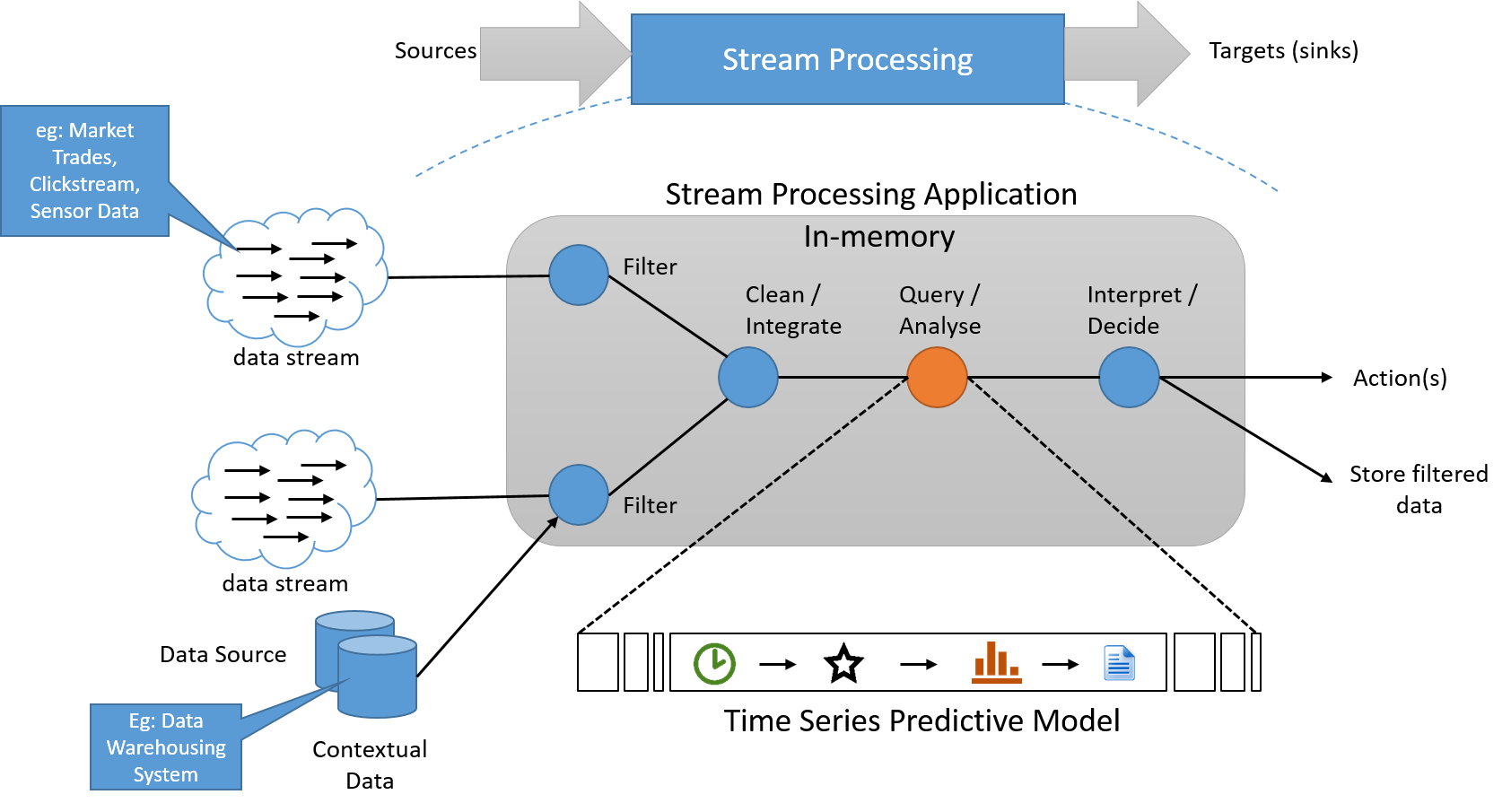
الشكل 6: يجب أن يقوم نظام معالجة دفق البيانات بمعالجة البيانات في أثناء التدفق، مع وجود بنية أساسية منفصلة للتخزين، إذا لزم الأمر، والذي لا يقع على "المسار الحرج"
القواعد الثماني للمعالجة المتدفقة
ستونبراكر وآخرون. وصف ثماني قواعد أساسية لأنظمة المعالجة المتدفقة.
القاعدة 1: الحفاظ على نقل البيانات
يجب أن يكون إطار عمل المعالجة المتدفقة في الوقت الحقيقي قادرًا على معالجة الرسائل "في التدفق" دون الحاجة إلى تخزينها على القرص، ما يضيف زمن وصول غير مقبول على المسار الحرج. وبالإضافة إلى ذلك، يجب أن تكون هذه الأنظمة نشطة (مدفوعة بالأحداث) وليست سلبية (حيث تحتاج التطبيقات إلى استقصاء النتائج للكشف عن حالات الاهتمام).
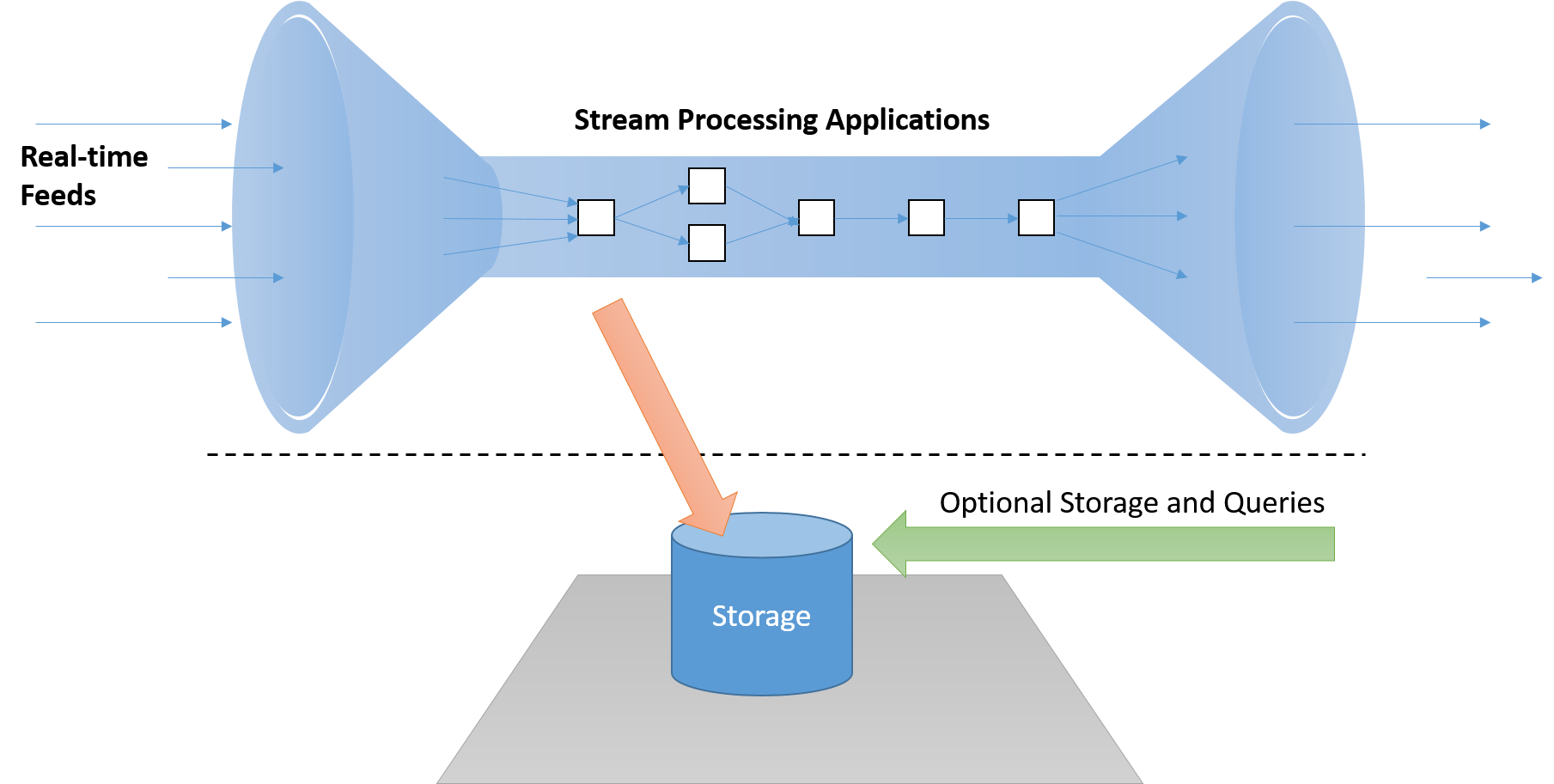
الشكل 7: يجب أن يقوم نظام معالجة دفق البيانات بمعالجة البيانات في أثناء التدفق، مع وجود بنية أساسية منفصلة للتخزين، إذا لزم الأمر، والذي لا يقع على "المسار الحرج"
القاعدة 2: ينبغي أن تدعم التدفقات الاستعلام باستخدام SQL
ظهر SQL كمعيار مألوف ومستخدم على نطاق واسع للاستعلام عن البيانات. ومع ذلك، يعمل SQL التقليدي على كمية محددة من البيانات، حيث يؤدي الوصول إلى نهاية الجدول إلى إخبار الاستعلام بأنه مكتمل. وفي سيناريوهات التدفق، تزداد البيانات بشكل مستمر. ستونبراكر وآخرون. أدركوا الحاجة إلى لغة StreamSQL، مع نوافذ منزلقة متغيرة الطول قائمة على الوقت تحدد نطاق الاستعلام. يمكن تعريف النوافذ باستخدام الوقت أو عدد الرسائل أو أي معلمات عشوائية. وقد تكون هناك حاجة إلى عوامل تشغيل إضافية لدمج الرسائل من عدة تدفقات.
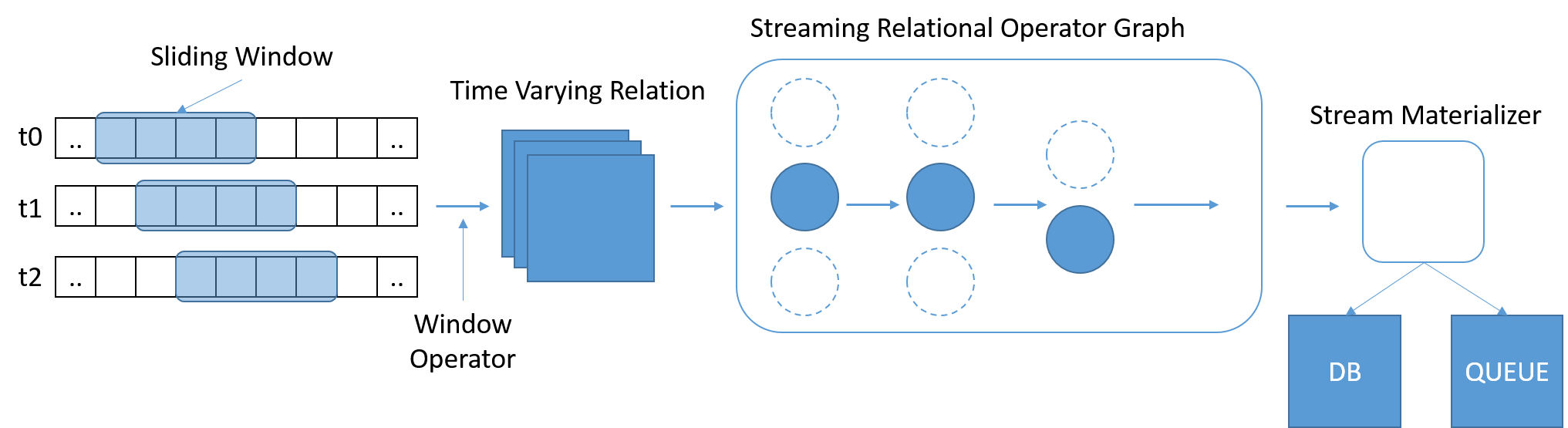
الشكل 8: ينبغي أن يعالج StreamSQL مجموعات فرعية من البيانات، ويسمح بالتعبير عن العلاقات عبر النوافذ
القاعدة 3: معالجة عيوب التدفق
في أنظمة الوقت الحقيقي، يمكن أن تُفقَد البيانات أو تصل في وقت متأخر أو تصل خارج النظام. ولا يمكن لنظام المعالجة المتدفقة الانتظار إلى ما لا نهاية للحصول على البيانات، ولكن أيضًا قد لا يتمتع بالمرونة لتجاهل أي بيانات أو فقدانها. ويجب أن تكون هذه الأنظمة مرنة في مقابل عيوب التدفق، مع آليات مثل المهلة القابلة للتكوين و"فترات السماح"، والتي يمكن خلالها قبول الوصول المتأخر.
القاعدة 4: توليد نتائج يمكن التنبؤ بها
يجب أن تكون نتيجة أي نظام معالجة تدفق محددة وقابلة للتكرار من خلال إعادة تشغيل التدفق. يكون هذا صعبًا بشكل خاص عندما يعمل النظام على عدة تدفقات متزامنة، أو عندما تصل الرسائل خارج الترتيب. ويجب أن يتم إنتاج الرسائل بترتيب زمني تصاعدي، بغض النظر عن وقت وصولها. وتُمَكّن هذه الخاصية أيضًا التسامح مع الخطأ بجعله معقولاً لإعادة تشغيل التدفقات التي فشلت المعالجة بناءً عليها.
القاعدة 5: دمج الحالة المخزنة
يجب أن تجمع تطبيقات المعالجة المتدفقة الحاضر مع الماضي. على سبيل المثال، عند التوصية بإعلان لأحد المستخدمين، يجب أن يجمع محرك البحث المعلومات الحالية حول مصطلح البحث والحالة الحالية لسوق الإعلان، مع المعلومات السابقة حول عادات نقر المستخدم. يتيح دمج الحالة المخزنة والبيانات المتدفقة أيضًا التبديل السلس، حيث يمكن اختبار الخوارزمية على البيانات التاريخية، ثم تحويلها إلى البث المباشر عندما تعمل بشكل مرضٍ. وينبغي تخزين البيانات في نفس مساحة عنوان النظام التي يخزن بها التطبيق، وربما باستخدام قاعدة بيانات مدمجة، للسماح باستخدام لغة موحدة تتعامل مع البيانات المخزنة والمتدفقة.
القاعدة 6: توفر قابلية الوصول العالية
تعمل أنظمة المعالجة المتدفقة في الوقت الحقيقي، وغالبًا لا يمكن أن تتسامح مع عمليات الاسترداد من جديد. يجب أن تسمح هذه الأنظمة بالتبديل السريع إلى نسخة احتياطية أو ظل، والتي يجب أن تكون متزامنة بانتظام مع الأساس. ويجب ضمان سلامة البيانات، وفقًا للقاعدة 4.
القاعدة 7: دعم التقسيم والتحجيم التلقائي
المعالجة الموزعة هي النموذج القياسي للتشغيل لجميع الأنظمة الكبيرة. يجب أن تكون البنية الجيدة للمعالجة المتدفقة غير محظورة واستغلال الهياكل الأساسية الحديثة متعددة مؤشرات الترابط. وعلاوة على ذلك، يجب أن يكون قادرًا على التعامل مع التوسع خارج أو في النظام بمفرده، عن طريق إضافة أو إزالة أجهزة، إما بناءً على أحجام البيانات المتزايدة أو المنخفضة أو بناءً على التأخيرات أو التعقيدات في المعالجة. وبالإضافة إلى ذلك، فإنه يجب أن يُنفِّذ بشكل تلقائي وبشفافية موازنة التحميل عبر الأجهزة المتوفرة. يجب ألا يضطر المستخدم النهائي للتعامل مع أي تعقيد من هذا القبيل.
القاعدة 8: التأكد من قدرتها على الاستمرار
ينبغي أن تكون جميع مكونات النظام مصممة للأداء العالي، مع حد أدنى من عدد العمليات يحدث خارج الذاكرة الأساسية. يجب اختبار النظام وقياسه استنادًا إلى حمل العمل المستهدف، ويجب التحقق من صحة أهداف معدل النقل وزمن الانتقال.
تطور محركات المعالجة المتدفقة
كان Aurora (2002) واحدًا من أقدم أنظمة المعالجة المتدفقة، والذي قام بتطويره أيضًا بواسطة ستونبراكر وآخرون في معهد ماساتشوستس للتقنية وجامعة براون. تَعامَل نظام Aurora مع مشكلة المعالجة المتدفقة على أنها رسم بياني دوري موجه (DAG).
مدخلات التدفق هي سلسلة من مجموعات غير محدودة (a1, a2, ..., an) بمرور الوقت تتدفق من المصدر (البداية) إلى انتقال البيانات من الخادم (المخرج). يمكن بناء تطبيق كامل من خلال إضافة مجموعات مختلفة من مربعات المعالجة وإنشاء الروابط بينها. كان Aurora نظامًا أحادي العقدة، والذي يفتقر إلى العديد من متطلبات قابلية التوسع لمحرك المعالجة المتدفقة. تم إنشاء نسخة جديدة من Aurora تسمى Aurora (2003)* للجمع بين العديد من عقد Aurora عبر شبكة. وهكذا، تم تحقيق قابلية التوسع من خلال تقسيم المراحل المختلفة من مهمة المعالجة المتدفقة على العقد المادية المختلفة. وأخيرًا، أضاف مشروع Medusa (2003) دعم الاتحاد إلى Aurora، ما سمح بالتعاون والمشاركة من جانب العديد من المستخدمين.
وكانت Borealis (2005) هي الامتداد التالي لمشروع Aurora، والتي أضافت دعمًا لقابلية الوصول العالية باستخدام النسخ المتماثل النشط. تمت مزامنة النسخ المتماثل بعناية لتوفير تناسق البيانات.
Apache Storm (2011) كان محرك معالجة دفق تم تطويره بواسطة X. هنا، يمكن لعقد المعالجة (Bolts) الاشتراك في التدفقات من مصادر مختلفة (Spouts)، وبالتالي تمكين نموذج مشترك بسيط للحساب. ويُوفِّر Storm معالجة مضمونة للرسائل، بغض النظر عن حالات فشل العقدة، ويُمكن الدلالات لمرة واحدة لضمان عدم احتساب البيانات بأقل أو أكثر من قيمتها. Apache S4 (2011) كان نظام اشتراك مماثلاً تم تطويره في Yahoo! وهو متماثل، بمعنى أن جميع العقد متساوية وليس هناك تحكم مركزي، على أمل جعلها قابلة للتوسع. لم يدعم S4 بشكل حيوي إضافة أو إزالة العقد من وإلى مجموعة قيد التشغيل. Apache Samza (2013) هو نظام آخر متعدد المشتركين في هذا القالب الذي سوف نستكشفه بمزيد من التفصيل.
تتبع Storm وSamza وS4 نموذج التدفق التقليدي، المعروف باسم معالجة السجل في كافة الأوقات. وفي هذا النموذج، تعالج المشغلات ذات الحالة الخاصة وصول السجلات، باستخدام البيانات الجديدة لتعديل الحالة الداخلية ثم إرسال سجلات جديدة. ويُنفَّذ التسامح مع الخطأ والاسترداد من خلال النسخ المتماثل إما عن طريق إجراء نسخ متعددة من عناصر المعالجة وإما من خلال التخزين المؤقت وتخزين النسخ الاحتياطية لمصدر الرسائل ثم إعادة إرسالها لانتقال البيانات من الخادم في حالة الفشل. وأيضًا، نظرًا لأن تخطيط DAG يزداد تعقيدًا، من الصعب ضمان الاتساق عبر مسارات مختلفة. وأخيرًا، فإن الجمع بين هذه الأطر وأنظمة الدفعات غير مهم، وغالبًا ما يتم ذلك باستخدام بنية Lambda (الذي تمت مناقشته لاحقًا).
توفر Spark Streaming (2012) نهجاً لتصميم أنظمة معالجة الدفق، الذي يوفر "التجزئة الدقيقة". تعمل التجزئة الدقيقة على تحويل حسابات الدفق إلى مجموعة من الحسابات السريعة للغاية، زمن وصول يتراوح من مئات من الملي ثانية إلى بضع ثوانٍ. وعلى حساب الانتقال المتزايد، يجعل ذلك من السهل توفير التسامح مع الخطأ والدلالات لمرة واحدة على نتيجة كل دفعة صغيرة.
يعد اختيار إطار العمل الصحيح لاستخدام مهمة عاملاً لزمن الانتقال المتوقع والتسامح مع الخطأ وضمانات توصيل الرسالة، فضلاً عن مجموعة مهارات المستخدمين وتكاليف التطوير المطلوب. في الوحدة التالية، سوف نستكشف الأجزاء الداخلية لهذه الأطر بمزيد من التفصيل، من خلال دراسة Apache Samza.
اختبر معلوماتك
الملاحظات
هل كانت هذه الصفحة مفيدة؟
لا
هل تحتاج إلى مساعدة مع هذا الموضوع؟
هل تريد محاولة استخدام Ask Learn لتوضيح هذا الموضوع أو إرشادك خلاله؟