البنية في الوقت الحقيقي قيد الممارسة
- 9 دقائق
بدأت العديد من المؤسسات على نطاق شبكة الإنترنت الآن في استخدام قوائم انتظار الرسائل وأطر والنقل باستمرار داخل تطبيقاتها. ويرجع ذلك في المقام الأول إلى أن هذه الشركات قد بدأت تكتسب قيمة كبيرة من استخدام البيانات الجديدة. الآن بعد أن قمنا بتغطية المفاهيم الأساسية لقوائم انتظار الرسائل والنقل باستمرار وبنية Lambda، قد يكون من المثير للاهتمام أن ننظر إلى مثال واقعي عن كيفية توفير بنية كثيفة البيانات ذات زمن انتقال منخفض بتوفير قيمة لشركة كبيرة. على وجه التحديد، سنوضح كيف أن دمج Kafka وSamza سمح لموقع LinkedIn بتغذية العديد من الأنظمة المختلفة في الوقت الحقيقي.
دمج Kafka وSamza في LinkedIn
بصفتها شركة تكنولوجية حديثة العهد، غالبًا ما وجدت LinkedIn نفسها تُنشئ وتعتمد عددًا كبيرًا من التقنيات الأكثر تطورًا، كل منها لحل متطلبات معينة. وعَمِلت خدماتها على خلفية مخصصة استخدمت مخزن قيمة رئيسية موزعًا له زمن انتقال منخفض على LinkedIn (Voldemort) ومخزن مستندات موزعًا (Espresso)، وOracle RDBMS. كانت خدمات ويب الواجهة الأمامية والتحليلات ورسائل البريد الإلكتروني والإخطارات مدفوعة بمهام ذات تعقيد مختلف. وشَمِلَ ذلك الوظائف الدفعية باستخدام Hadoop، والاستعلامات على مستودع بيانات كبير، وبنية أساسية منفصلة لعمليات البحث، وكلها مدعومة بطبقة من التسجيل والمراقبة وتتبع المستخدم والقياس.
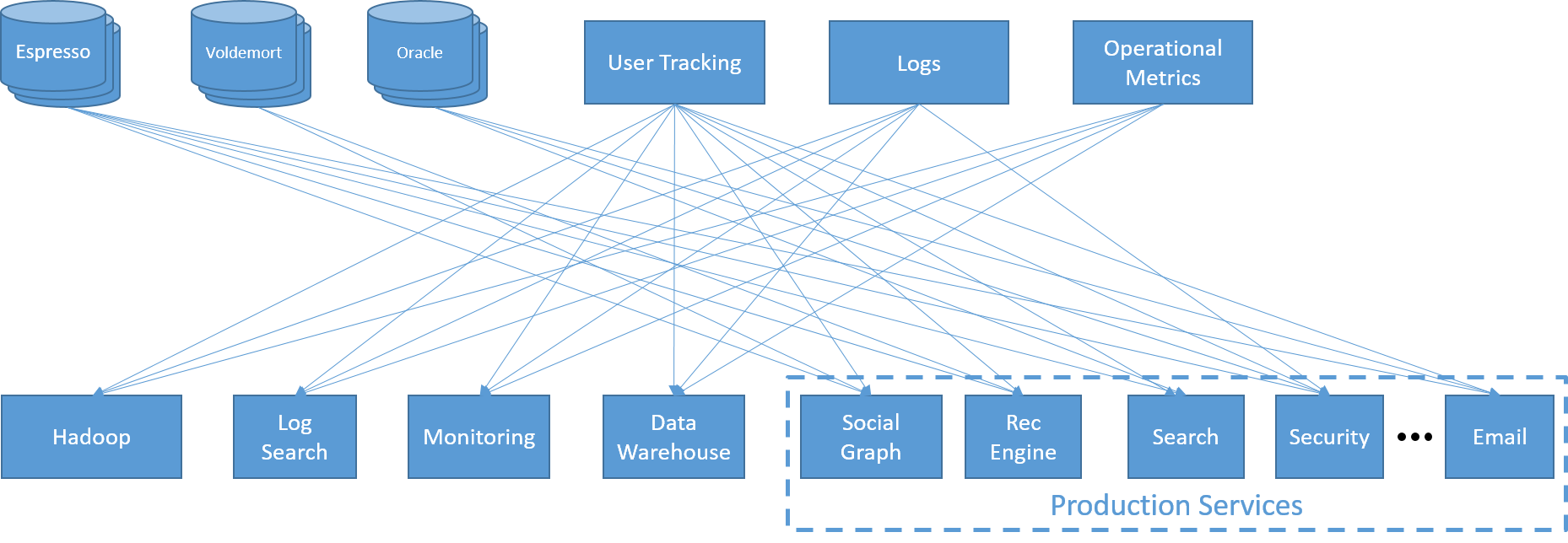
الشكل 19: كارثة تكامل البيانات في LinkedIn
قبل بضع سنوات، أدرك المهندسون في LinkedIn أن نظامهم قد أصبح معقدًا للغاية. كانت الاتصالات بين الخدمات والواجهات الأمامية والخلفية شاملة للجميع، حيث كان لكل مكون متطلبات زمن الانتقال والإنتاجية الخاصة به. وقد تطلبت إضافة خدمة واحدة اتصالات بعدد كبير من المكونات، ما أدى بدوره إلى نقاط نهاية هشة للغاية. وأدى ذلك أيضًا إلى الحاجة لمستودعات، حيث كان أصحاب الخدمات الفردية أقل عرضة لمشاركة بياناتهم.
كان التغيير الأول في LinkedIn هو التحرك نحو استخدام بنية أساسية مركزية للبيانات تحركه Kafka. وقد سمح ذلك لكل خدمة بإنتاج البيانات وإرسالها باستخدام موضوع محدد. أصبح الوصول إلى البيانات من خدمة أخرى الآن بسيطًا مثل الاشتراك في هذا الموضوع المحدد. ونظرًا إلى أنه تم تشغيل بنية أساسية داخليًا على نظام مجموعة موزعة، كان من المتوقع أن يكون قابلاً للتوسع بطبيعته.
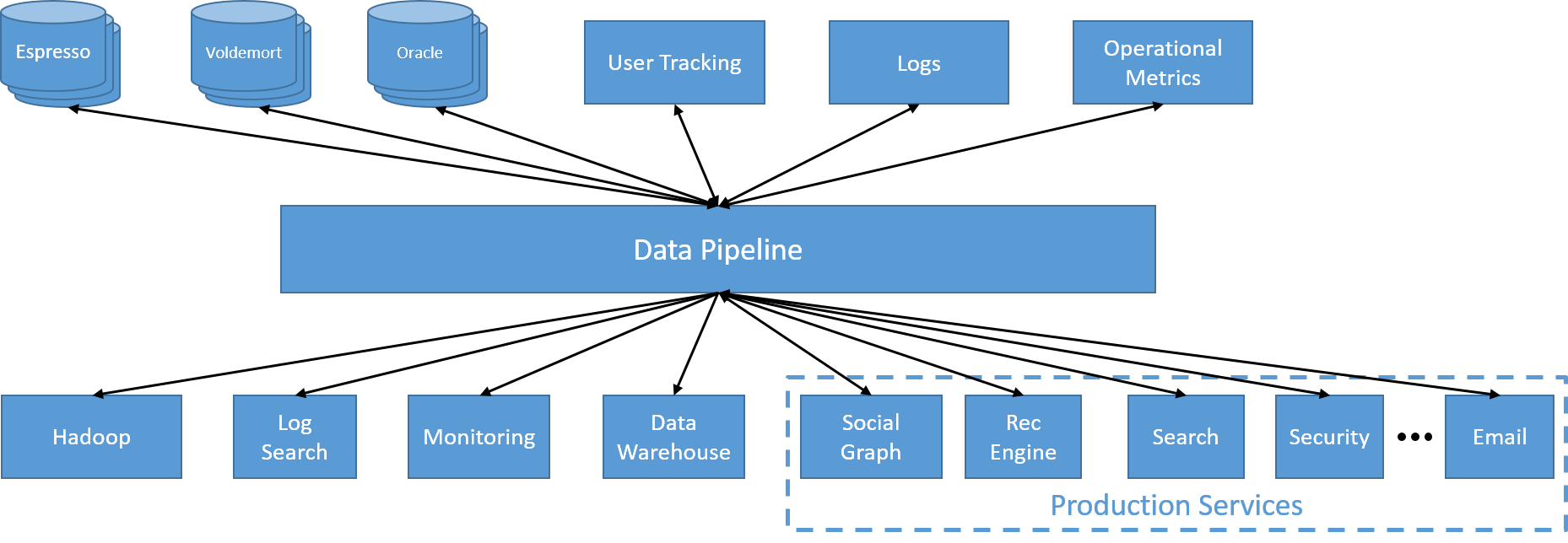
الشكل 20: بنية أساسية للبيانات واحدة موزعة غير متزامنة
هناك حاجة الآن إلى خدمة أخرى لإدارة عضوية العُقد داخل مركز بيانات. نظرًا إلى أن توسيع الحجم وتصغيره أصبح الآن مجرد مسألة إضافة وإزالة العقد من النظام، فقد تم استخدام خدمة جديدة تسمى ZooKeeper لإدارة العضوية داخل المجموعة، وتوزيع مسؤولية الأقسام والموضوعات داخل طبقة الوسيط، والتعامل بشكل صحيح مع إزاحات طبقة المستهلك.
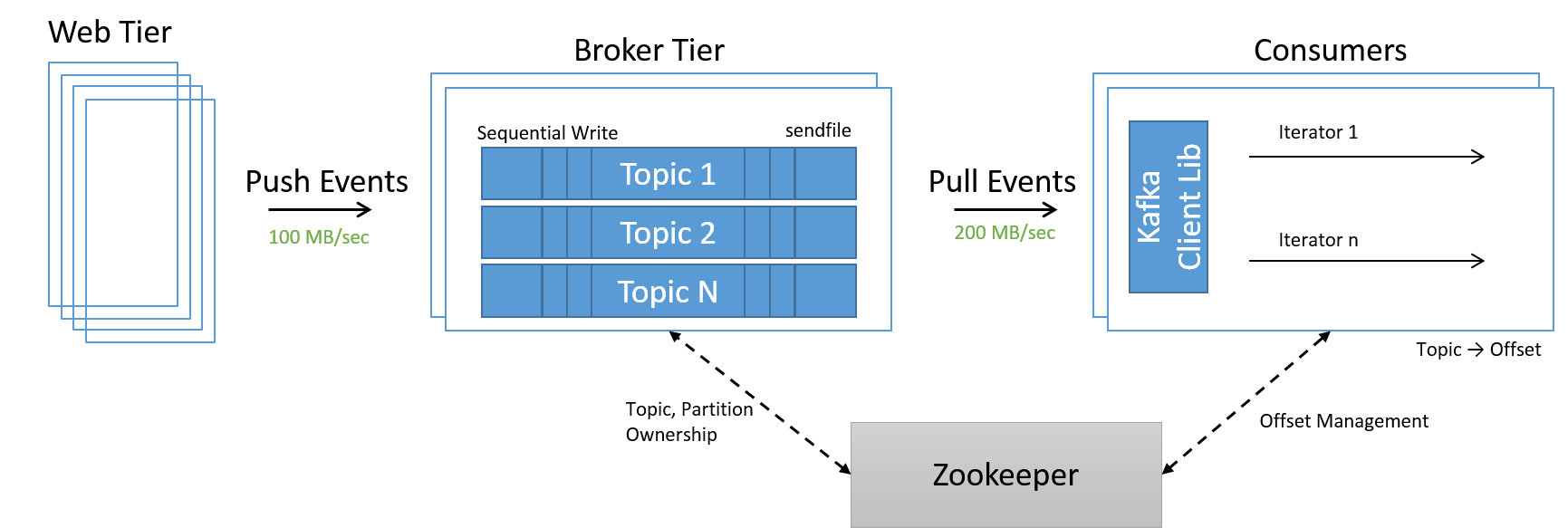
الشكل 21: معالجة البيانات عالية السرعة باستخدام مواضيع Kafka
كما كانت التغييرات في بنية LinkedIn مدفوعة بالتحرك نحو أنظمة أكثر تفاعلية. في بنيته الأصلية (حوالي عام 2010)، تم مسح جميع سجلات نشاط المستخدم من خلال عملية دفعية كل بضع ساعات، ويُستخدم هذا لإنشاء رسومات بيانية ولوحات معلومات جديدة في الواجهة الأمامية. وقد أتاحت هذه البنية لـ LinkedIn الحصول على تحديثات كل ساعة أو تحديثات يومية لعدد مرات العرض وتوصيات المستخدم والمواضيع المتداولة.
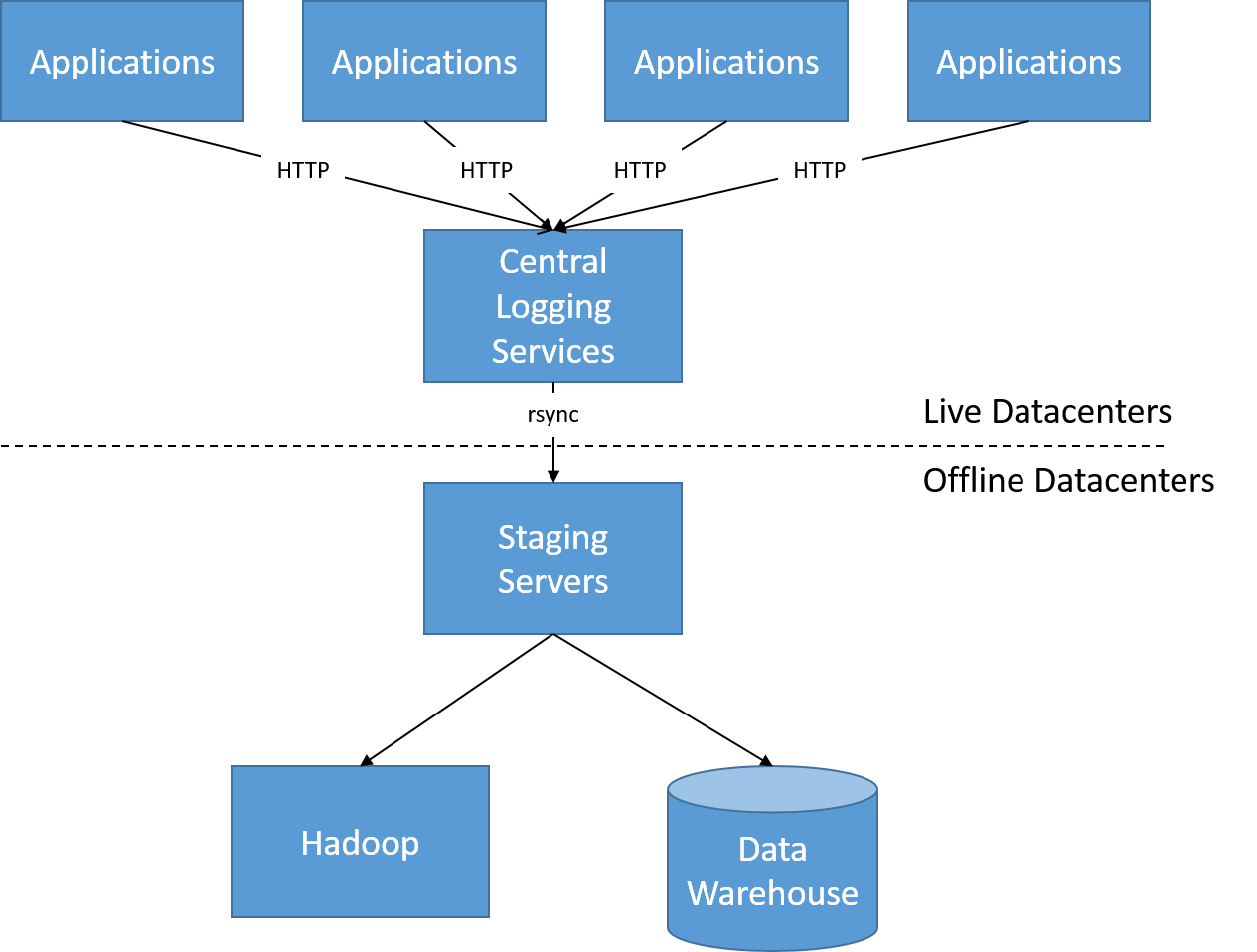
الشكل 22: قبل معالجة سجلات نشاط المستخدم دون اتصال
ومع ذلك، لم يعد الكمون لبضع ساعات مقبولاً؛ لا للمستخدمين النهائيين الذين يريدون معرفة إحصاءات عرض الصفحة والاتجاهات من آخر خمس دقائق، ولا لجهات الدعاية وكذلك تحليلات البيانات للأشخاص الذين يحتاجون إلى عرض المعلومات الأكثر صلة في الوقت الحقيقي. لم تعد الإعلانات مدفوعة فقط من خلال تحليل مسارات النقر في مستودعات البيانات في حالة عدم الاتصال، ولكن في الحقيقة، تتأثر بشكل متزايد بنماذج الوقت الحقيقي التي يتم تحديثها عبر الإنترنت.
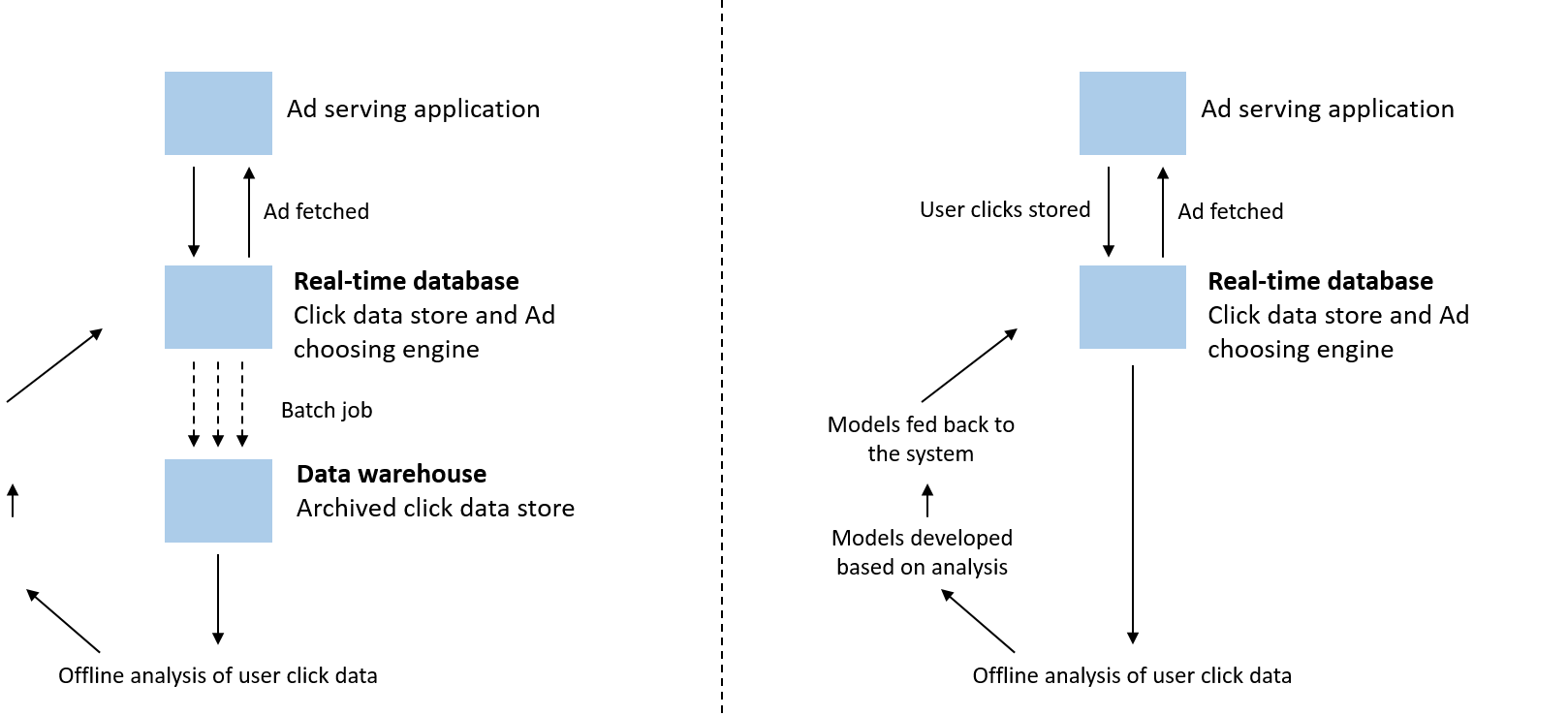
الشكل 23: اليسار: تقديم خدمات إعلانية تقليدية. اليمين: تقديم خدمات إعلانية نموذجية.
هذا هو ما يُمّكنه التدفق ذو الحالة الخاصة باستخدام Samza. من الناحية التقليدية، فإن مصدر تقصى الحقائق يأتي دائمًا من أصل واحد من مخازن البيانات المركزية. ومع ذلك، لا يمكن أن تخدم قواعد البيانات هذا العدد الكبير من الطلبات المتزامنة لمطابقة الاستفسارات المعقدة في الوقت الحقيقي للتوصيات ونظم التحليلات المعقدة. وقد فرض ذلك طلبًا كبيرًا على النطاق الترددي التقابلي من مركز البيانات. بدلاً من ذلك، كان نهج LinkedIn يتمثل في استخدام نفس تدفق البيانات لتحديث العديد من النهايات الخلفية. ومن ثم، ونظرًا إلى أن كل عقدة للمستهلك تضم قاعدة بيانات مضمنة محلية، سيؤدى حدث تحديث واحد ببساطة إلى تشغيل جميع التحديثات ذات الصلة في الوقت الحقيقي على قاعدة البيانات المحلية هذه.
ويُعرض أدناه مثال بسيط على حدث تحديث لملف تعريف المستخدم. عند تحديث ملف التعريف، فإنه يكتب إلى موضوع UserProfileUpdate محدد، والذي يستهلكه ملف الأخبار (ليُظهر في الوقت الحقيقي أن المستخدم قد انتقل إلى شركة جديدة) ومخزن بيانات البحث (بحيث لا يتم إرجاع البيانات التالفة)، ويستهلك أيضًا لاستخدامه في المعالجة دون الاتصال بالإنترنت (على سبيل المثال، لاستخلاص الاتجاهات بشأن عدد مهندسي البرمجيات الذين ينضمون إلى شركة معينة يوميًا).
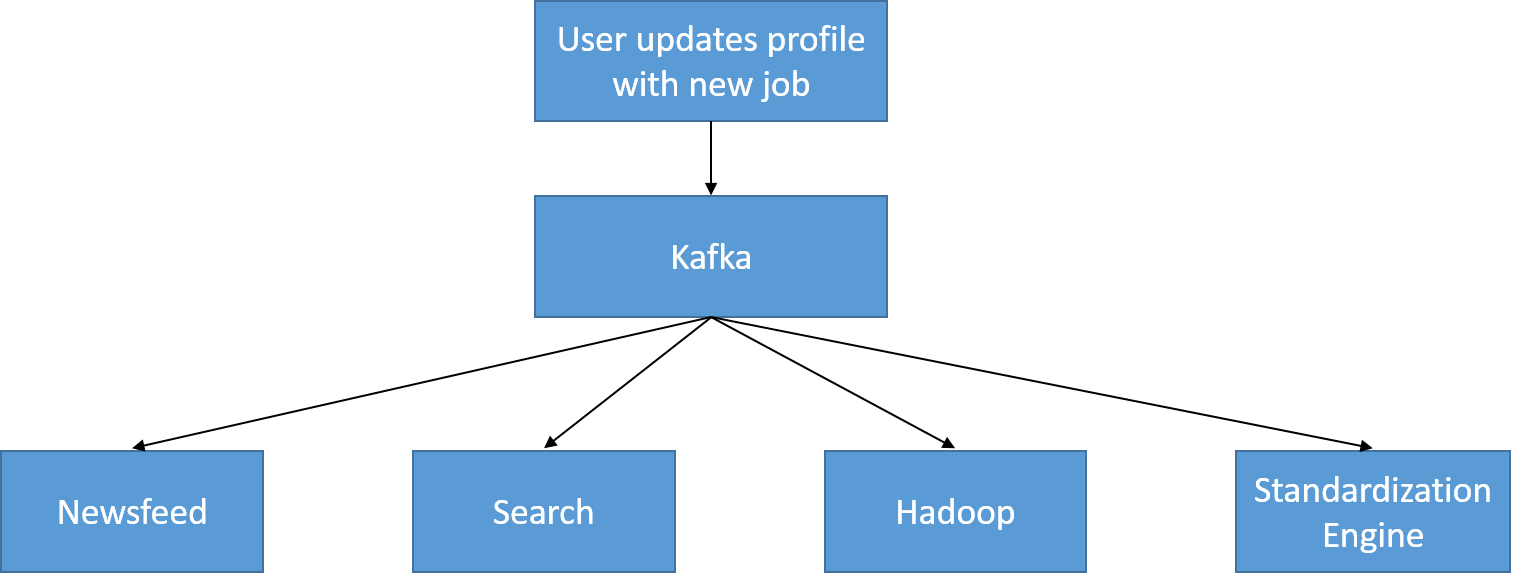
الشكل 24: يتم استهلاك موضوع UserProfileUpdate في LinkedIn
عندما تقوم بتشغيل الأنظمة الموزعة الكبيرة على نطاق الويب مثل العديد من الشركات التقنية الكبيرة، هناك تفاوت ظاهري في خيارات التصميم. أنشأت الشركات التقنية عددًا كبيرًا من الأنظمة المتخصصة، مثل مخازن البيانات، والوصلات البينية للشبكات، والدفعات وأطر المعالجة التفاعلية والنقل باستمرار، وغيرها. وذلك لأن الحلول التي تناسب الجميع لم تعد تلبي المتطلبات الصعبة المحددة لمستخدمي اليوم. ومع ذلك، يتمثل الجانب السلبي لهذا النهج في قدر كبير من مبدأ "إعادة اختراع العجلة"، وبناء حلول مخصصة لمشاكل مثل الكشف عن الفشل والاسترداد وإدارة نظام المجموعة. يعد التحرك نحو هذه الأنظمة مدفوعًا بشكل أساسي باحتياجات السرعة وسهولة الإدارة وقابلية التوسع.
بإيجاز، نرى هنا الفوائد التي يجنيها موقع LinkedIn في حالة الانتقال إلى نظام موجه نحو السجل. وهذا ما جعل من السهل أن تصبح عديمة المخططات، ما يسمح بتكامل البيانات بشكل أسهل. ومن خلال جعل رسالة السجل القابلة للتحجيم تمر على مواطن من الفئة الأولى داخل مركز البيانات الخاص به، قامت إدارة موقع LinkedIn بإعداد نظام نمطي ومرن للغاية.
اختبر معلوماتك
الملاحظات
هل كانت هذه الصفحة مفيدة؟
لا
هل تحتاج إلى مساعدة مع هذا الموضوع؟
هل تريد محاولة استخدام Ask Learn لتوضيح هذا الموضوع أو إرشادك خلاله؟