تقييم الذكاء الاصطناعي التوليدية
التقييمات هي تقييمات منهجية لأداء وموثوقية وسلامة تطبيقات الذكاء الاصطناعي التوليدي. تساعدك على التحقق مما إذا كان التطبيق ينتج ردودا مفيدة وواقعية ومتوافقة مع السياسات عبر السيناريوهات التي تهم مستخدميك أكثر.
التقييمات حاسمة لعدة أسباب:
- ضمان الجودة: تساعد في ضمان أن أنظمة الذكاء الاصطناعي تلبي المعايير المتوقعة للفائدة والوضوح والموثوقية.
- التحقق من السلامة: يكشف عن سلوك ضار أو يخالف السياسات قبل أن يصل إلى المستخدمين النهائيين.
- مقارنة التغييرات: تساعدك على مقارنة تغييرات الطلب، والاسترجاع، والنموذج، والأدوات مع الأدلة بدلا من القصص القصصية.
- ثقة المستخدم: التطبيقات التي يتم تقييمها باستمرار أسهل في التحسين وأسهل على أصحاب المصلحة في الثقة.
التقييمات المدعومة بالذكاء الاصطناعي في مايكروسوفت فاوندري
عادة ما تحتاج تطبيقات الذكاء الاصطناعي التوليدي إلى أكثر من مقياس واحد. في بوابة Foundry، يتم تنظيم المقيمين المدمجين في ثلاث مجموعات رفيعة المستوى: الوكيل، الجودة، والسلامة. في الكتالوج الكامل، تتوسع هذه المجموعات لتشمل عائلات المقيمين مثل جودة الاستخدامات العامة، التشابه النصي، RAG، المخاطر والسلامة، ومقيمو الوكلاء. يساعدك هذا الهيكل على اختبار أنماط الفشل المختلفة بدلا من اعتبار التقييم درجة دقة واحدة.
يحتاج المقيمون المدعومون بالذكاء الاصطناعي عبر كتالوج الجودة، بالإضافة إلى العديد من مقيمي الوكلاء، إلى اتصال Azure OpenAI مع نموذج GPT منشور يدعم إكمال المحادثة. ويستخدمون Groundedness Pro مقيمو السلامة خدمات التقييم المستضافة من مايكروسوفت بدلا من ذلك، لذا لا يعتمدون على نشر نموذج الحكم. هذا التمييز يؤثر على المتطلبات المسبقة، وتخطيط التكاليف، وأي المقيمين يمكنك تشغيلهم في منطقة معينة.
التقييم مع مايكروسوفت فاوندري
استخدم بوابة Foundry عندما ترغب في سير عمل موجه. يتيح لك تدفق البوابة الحالي اختيار هدف تقييم (وكيل، نموذج، أو مجموعة بيانات)، رفع أو إنشاء مجموعة بيانات، اختيار مقيمين مدمجين أو مخصصين، تأكيد رسم بيانات، وفحص النتائج في البوابة.
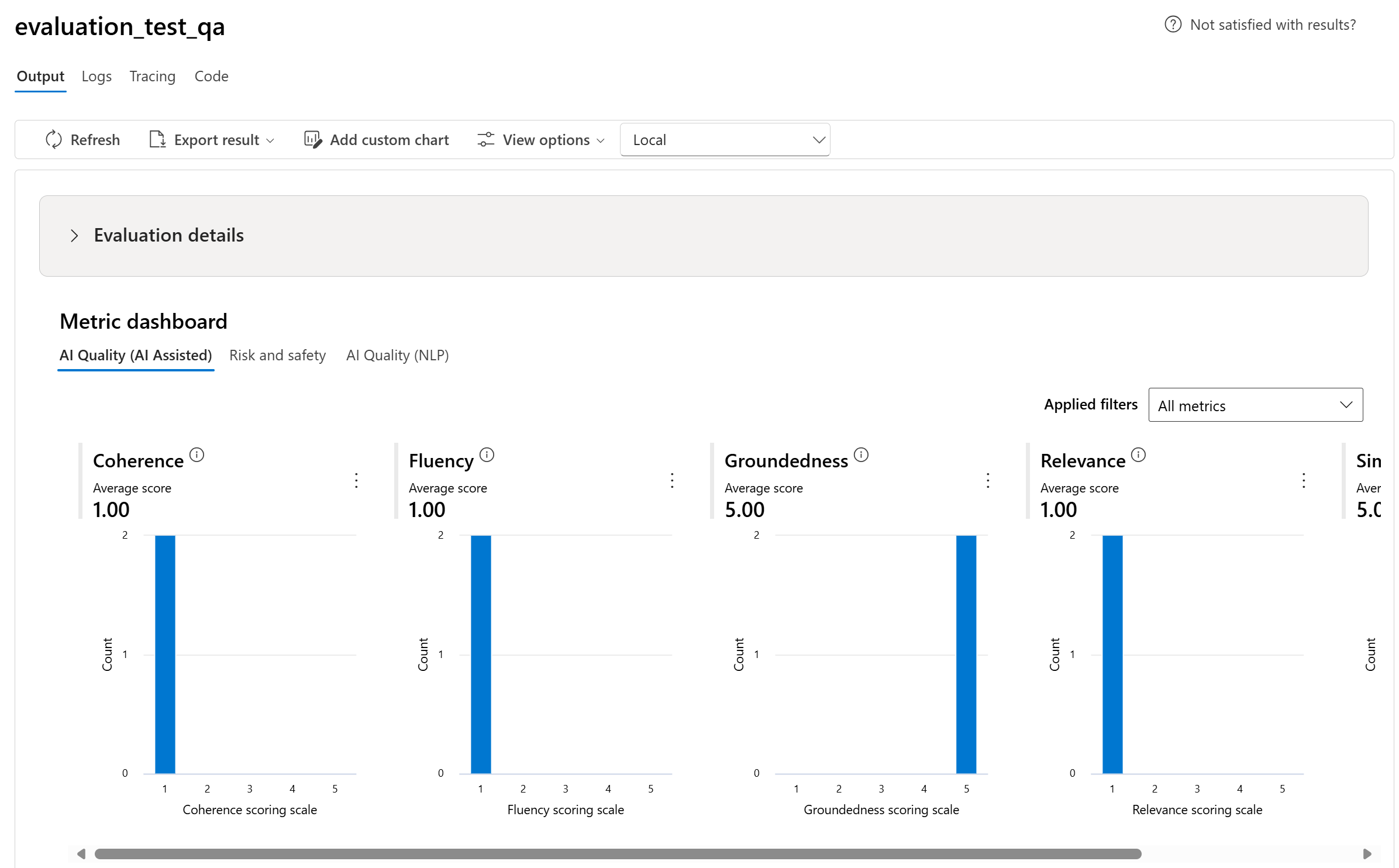
تظهر الصورة لوحة تحكم تقييم مع تفاصيل الجولة وملخص مقياسي. تتضمن لوحة التحكم مخططات لعدة مقيمين، وتتيح لك تصفية المقاييس، وتوفر مشاهدات للجودة والمخاطر والسلامة. هذا النوع من صفحات النتائج يساعدك على رؤية الاتجاه العام للجولة قبل أن تفحص أزواج الأسئلة والرد الفردية.
بعد إكمال التشغيل، راجع كل من المقاييس الإجمالية ونتائج مستوى الصف. تظهر المقاييس المجمعة الحركة العامة، بينما تظهر نتائج مستوى الصف أي المحفزات فشلت، والدرجات والتسميات التي تلقتها، ولماذا قام المقيم بوضع علامة عليها بهذه الطريقة.
استخدم سير عمل SDK للأتمتة
استخدم سير عمل SDK عندما تحتاج إلى أتمتة قابلة للتكرار، أو اختبار ما قبل النشر على نطاق أوسع، أو تكامل CI/CD. تدعم إرشادات تقييم السحابة الحالية تقييمات مجموعات بيانات JSONL أو CSV، وتقييمات النموذج-الهدف، وتقييمات الوكيل-الهدف، وتقييمات الوكيل-الاستجابة (حسب معرف الاستجابة)، وتقييمات البيانات التركيبية (المعاينة)، وتقييمات الفريق الأحمر. يتم تخزين تلك الجولات في مشروع Foundry الخاص بك حتى تتمكن من مراجعتها في البوابة إلى جانب تقييمات أخرى، ويمكنك أيضا جدولتها أو إعداد تقييم مستمر على ردود وكلاء الإنتاج المأخوذة من عينات.
نظرا لأن تقييم السحابة هو حاليا معاينة، ولأن بعض ميزات التقييم تدعم منطقة محددة، تأكد من شروط المعاينة الحالية، والمناطق المدعومة، والحدود التشغيلية قبل استخدامها كبوابة إصدار للإنتاج.
بغض النظر عن الأداة التي تختارها، اجمع بين التقييم الآلي والمراجعة البشرية المستهدفة. عينة صغيرة ونموذجية من قبل مراجعة بشرية غالبا ما تظهر مشاكل في النغمة، أو إجابات ناقصة، أو مخرجات مضللة لكنها معقولة يمكن أن تخفي الدرجات المجمعة.