استكشاف معالجة البيانات التحليلية
تستخدم معالجة البيانات التحليلية عادة أنظمة للقراءة فقط (أو للقراءة-في الغالب) تُخزن كميات مهولة من البيانات التاريخية أو مقاييس الأعمال. يمكن أن تستند التحليلات إلى لقطة للبيانات في نقطة زمنية معينة، أو على مجموعة من اللقطات.
يمكن أن تختلف التفاصيل المحددة لنظام المعالجة التحليلية بين الحلول، ولكن البنية المشتركة للتحليلات على نطاق المؤسسة تبدو كما يلي:
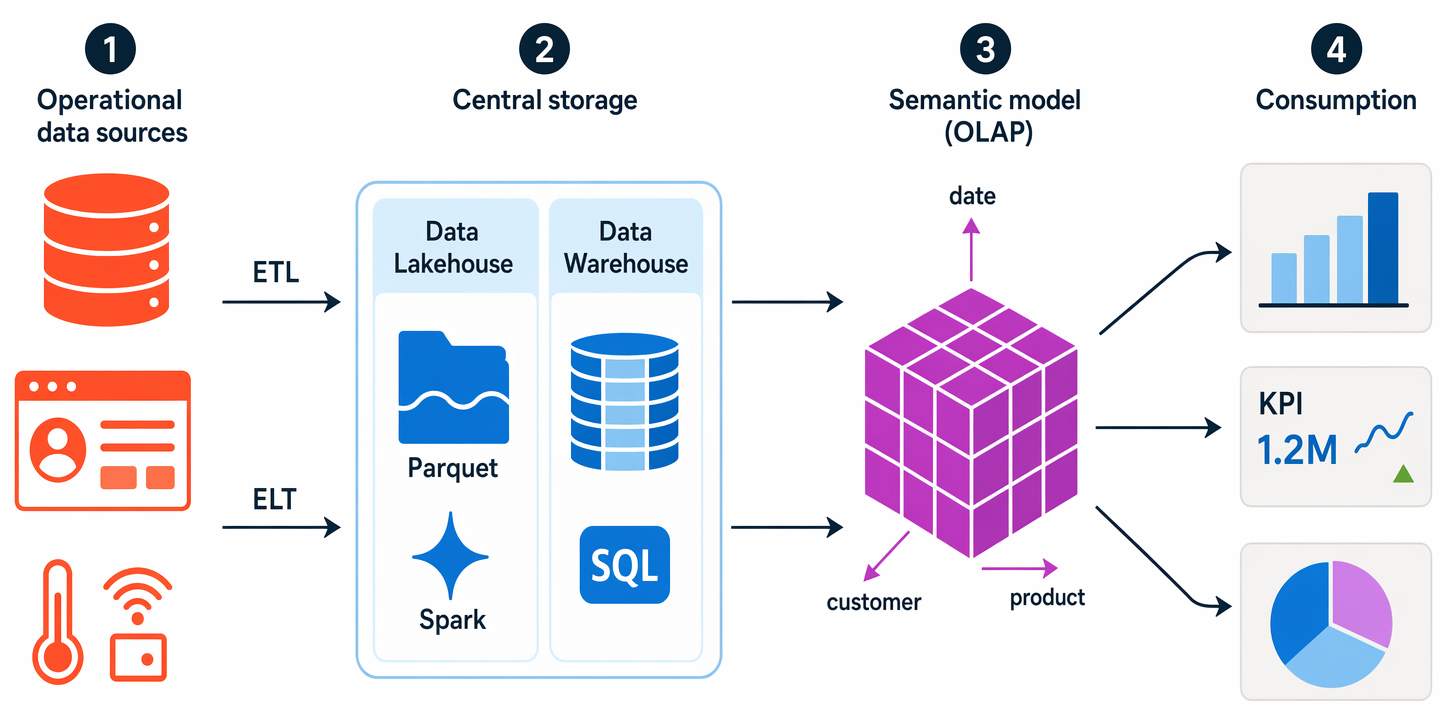
يتم استخراج البيانات التشغيلية وتحويلها وتحميلها (ETL) إلى بحيرة بيانات للتحليل—أو يتم استخراجها وتحميلها أولا مع تطبيق التحويلات لاحقا، وهو نمط يسمى ELT وهو نمط شائع في بيوت البحيرات الحديثة.
يتم تحميل البيانات في مخطط جداول - عادة في مستودع بيانات يستند إلى Spark مع تجريدات جدولية عبر الملفات في مستودع البيانات، أو مستودع بيانات بمحرك SQL علائقي بالكامل.
يمكن تجميع البيانات في مستودع البيانات وتحميلها في نموذج معالجة تحليلية عبر الإنترنت (OLAP) — والذي يسمى اليوم نموذجا دلاليا (وتاريخيا هو مكعب). تُحسب القيم الرقمية المجمعة (المقاييس) من جداول الحقائق لتقاطعات الأبعاد من جداول الأبعاد. على سبيل المثال، قد يُحسب إجمالي إيرادات المبيعات حسب التاريخ والعميل والمنتج. نماذج Power BI الدلالية هي المثال الأكثر شيوعا الذي ستواجهه.
يمكن الاستعلام عن البيانات الموجودة في مستودع البيانات (data lake) ومستودع البيانات (data warehouse) والنموذج التحليلي لإنتاج التقارير والتصورات ولوحات المعلومات.
تعدمستودعات البيانات شائعة في سيناريوهات المعالجة التحليلية للبيانات واسعة النطاق، حيث يجب جمع كمية كبيرة من البيانات المستندة إلى الملفات وتحليلها.
مستودعات البيانات هي طريقة معروفة لتخزين البيانات في مخطط علائقي محسن لعمليات القراءة – وبشكل أساسي الاستعلامات لدعم التقارير وتصور البيانات.
تعد Data Lakehouses ابتكارا أحدث يجمع بين التخزين المرن والقابل للتوسع لبحيرة البيانات مع دلالات الاستعلام العلائقي في مستودع البيانات. قد يتطلب مخطط الجدول بعض إلغاء تكرار البيانات في مصدر بيانات OLTP (إدخال بعض التكرار لجعل الاستعلامات تعمل بشكل أسرع).
نموذج OLAP (أو النموذج الدلالي) هو نوع مجمع من تخزين البيانات يتم تحسينه لأحمال العمل التحليلية. تجميعات البيانات تتم عبر أبعاد ومستويات مختلفة، مما يتيح لك التنقيب للأعلى/الأسفل لعرض التجميعات على مستويات هرمية متعددة؛ على سبيل المثال، لإيجاد إجمالي المبيعات حسب المنطقة، أو المدينة، أو لعنوان فردي. نظرا لأن البيانات مجمعة مسبقا، يمكن تشغيل الاستعلامات لإعادة الملخصات التي تحتويها بسرعة.
قد تقوم أنواع مختلفة من المستخدمين بعمل تحليل البيانات في مراحل مختلفة من البنية العامة. على سبيل المثال:
- قد يعمل علماء البيانات مباشرة مع ملفات البيانات في مستودع البيانات لاستكشاف البيانات ونمذجتها.
- قد يستعلم محللو البيانات عن الجداول مباشرة في مستودع البيانات لإنتاج تقارير ومرئيات معقدة.
- قد يستهلك مستخدمو الأعمال بيانات مجمعة مسبقا في نموذج تحليلي على شكل تقارير أو لوحات بيانات.
منصات التحليلات الحديثة
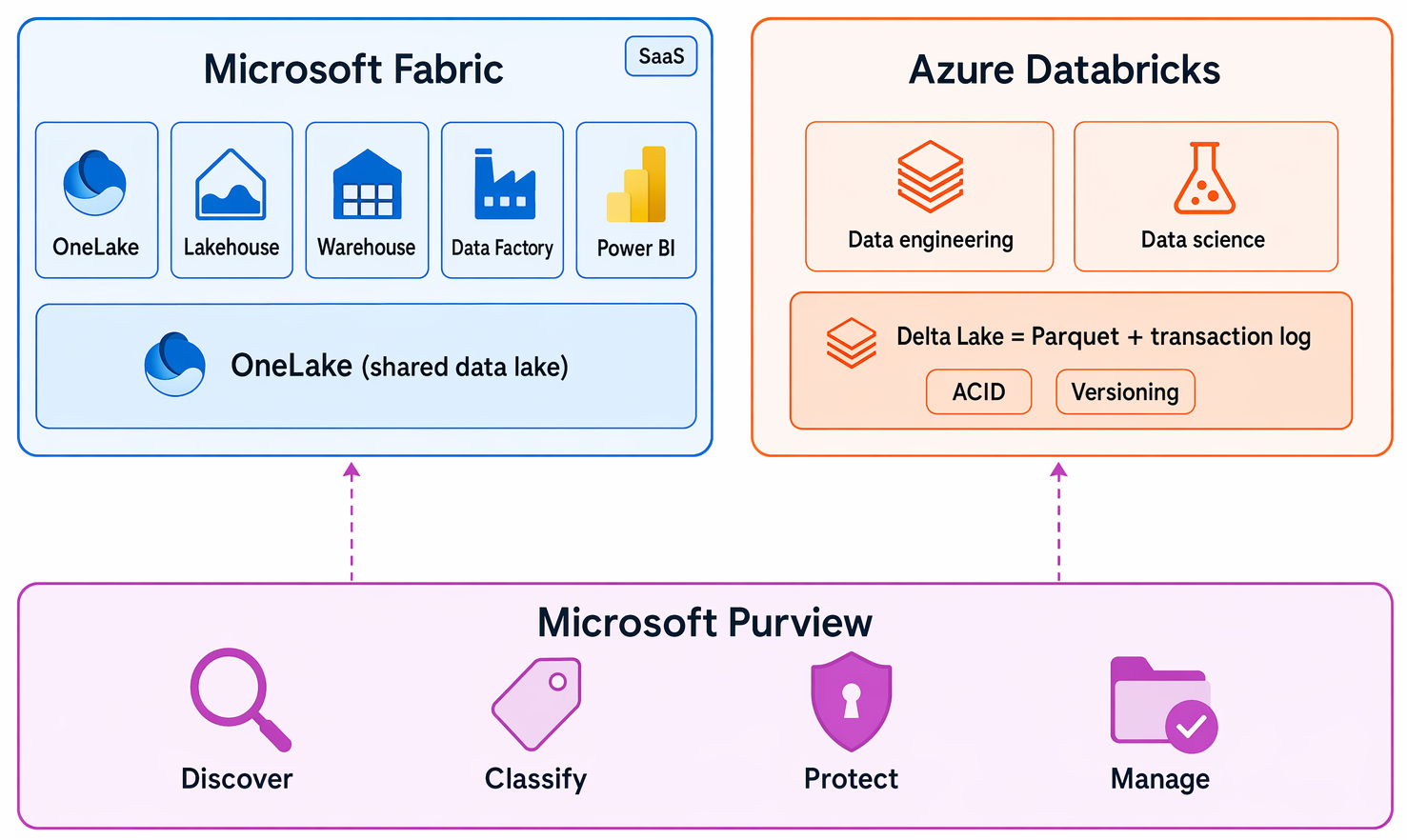
تهيمن منصتان تحليليتان "شاملتان" على Azure. Microsoft Fabric يجمع بين OneLake (بحيرة بيانات مشتركة واحدة)، Fabric Lakehouse، Fabric Warehouse، Fabric Data Factory، و Power BI في مساحة عمل SaaS موحدة. Azure Databricks هي منصة تحليلات سحابية مصممة لهندسة البيانات وعلوم البيانات واسعة النطاق، باستخدام **Delta Lake—Parquet بالإضافة إلى سجل معاملات يتيح الإصدارات ومعاملات ACID—كصيغة تخزين قياسية. يوفر Microsoft Purview أمن البيانات الموحد، والحوكمة، والامتثال، مما يساعدك على اكتشاف وتصنيف وحمايتها وإدارتها عبر جميع مصادر بياناتك.
تنظيم البيانات باستخدام هندسة الميداليون
نمط شائع لتنظيم البيانات في بيت البحيرة هو هندسة الميداليون، التي تستخدم ثلاث طبقات:
- برونز: البيانات الخام التي تم استدعاؤها as-is من الأنظمة المصدرية، دون تطبيق أي تحويلات، مما يحافظ على السجلات الأصلية لإعادة المعالجة.
- الفضة: بيانات منقية ومتوافقة، مع إزالة التكرارات وتوحيد أنواع البيانات.
- ذهب: بيانات مجمعة وجاهزة للأعمال مصممة لحالات استخدام محددة للتقارير والتحليلات.
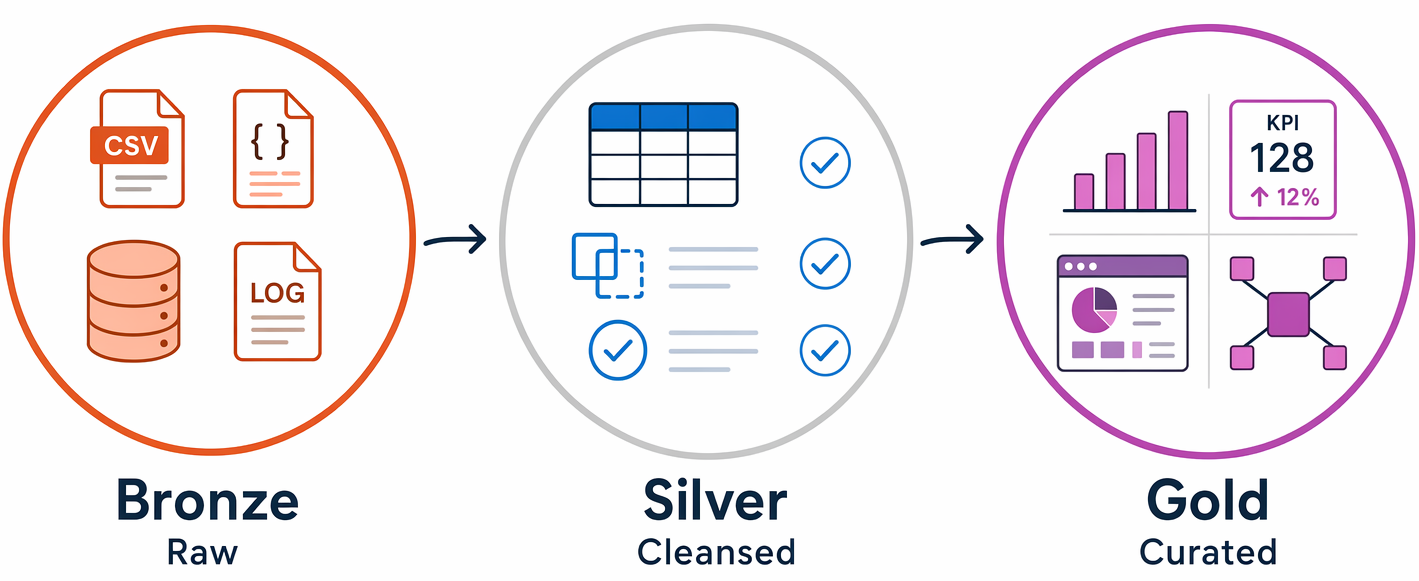
تستخدم الفرق هذا النمط لأنه يخلق حدود جودة واضحة في كل طبقة، ويمكنك دائما إعادة معالجة البيانات من سجلات برونز الأصلية إذا تغيرت المتطلبات.
كل من Fabric و Databricks يشملان تجارب Copilot تتيح لك استكشاف البيانات باستخدام اللغة الطبيعية.