التراجع
يتم تدريب نماذج الانحدار على التنبؤ بقيم التسميات الرقمية استنادا إلى بيانات التدريب التي تتضمن كل من الميزات والتسميات المعروفة. تتضمن عملية تدريب نموذج الانحدار (أو أي نموذج تعلم آلي خاضع للإشراف) تكرارات متعددة تستخدم فيها خوارزمية مناسبة (عادة مع بعض الإعدادات ذات المعلمات) لتدريب نموذج وتقييم الأداء التنبؤي للنموذج وتحسين النموذج من خلال تكرار عملية التدريب باستخدام خوارزميات ومعلمات مختلفة حتى تحقق مستوى مقبولا من الدقة التنبؤية.
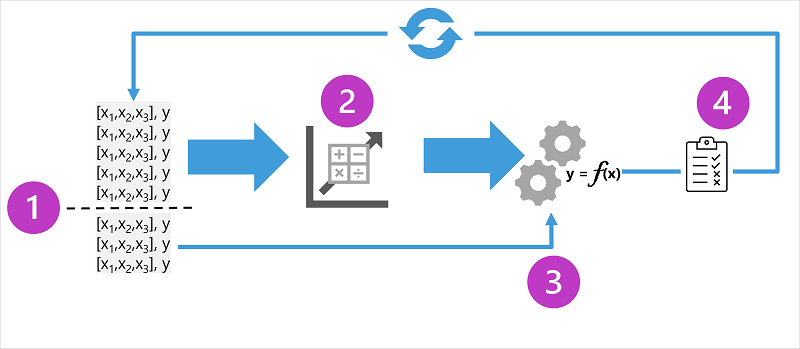
يوضح الرسم التخطيطي أربعة عناصر رئيسية لعملية التدريب لنماذج التعلم الآلي الخاضعة للإشراف:
- تقسيم بيانات التدريب (عشوائيا) لإنشاء مجموعة بيانات لتدريب النموذج مع الاحتفاظ بمجموعة فرعية من البيانات التي ستستخدمها للتحقق من صحة النموذج المدرب.
- استخدم خوارزمية لاحتواء بيانات التدريب مع نموذج. في حالة نموذج الانحدار، استخدم خوارزمية انحدار مثل الانحدار الخطي.
- استخدم بيانات التحقق التي قمت بالاحتفاظ بها مرة أخرى لاختبار النموذج عن طريق التنبؤ بتسميات الميزات.
- قارن التسميات الفعلية المعروفة في مجموعة بيانات التحقق من الصحة بالتسميات التي توقعها النموذج. ثم قم بتجميع الاختلافات بين قيم التسمية المتوقعة والفعلية لحساب مقياس يشير إلى مدى دقة النموذج المتوقع لبيانات التحقق من الصحة.
بعد كل تدريب، والتحقق من الصحة، وتقييم التكرار، يمكنك تكرار العملية مع خوارزميات ومعلمات مختلفة حتى يتم تحقيق مقياس تقييم مقبول.
مثال - الانحدار
دعونا نستكشف الانحدار باستخدام مثال مبسط سنقوم فيه بتدريب نموذج للتنبؤ بتسمية رقمية (y) استنادا إلى قيمة ميزة واحدة (x). تتضمن معظم السيناريوهات الحقيقية قيم ميزات متعددة، مما يضيف بعض التعقيد؛ ولكن المبدأ هو نفسه.
على سبيل المثال، لنلتزم بسيناريو مبيعات الآيس كريم الذي ناقشناه سابقا. بالنسبة لمميزتنا، سننظر في درجة الحرارة (لنفترض أن القيمة هي الحد الأقصى لدرجة الحرارة في يوم معين)، والتسمية التي نريد تدريب نموذج للتنبؤ بها هي عدد الآيس كريمات المباعة في ذلك اليوم. سنبدأ ببعض البيانات التاريخية التي تتضمن سجلات درجات الحرارة اليومية (x) ومبيعات الآيس كريم (y):
 |
 |
|---|---|
| درجة الحرارة (x) | مبيعات الآيس كريم (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| 78 | 26 |
| 83 | 36 |
تدريب نموذج انحدار
سنبدأ بتقسيم البيانات واستخدام مجموعة فرعية منها لتدريب نموذج. فيما يلي مجموعة بيانات التدريب:
| درجة الحرارة (x) | مبيعات الآيس كريم (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
للحصول على نظرة ثاقبة حول كيفية ارتباط قيم x وy هذه ببعضها البعض، يمكننا رسمها كإحداثيات على طول محورين، مثل هذا:
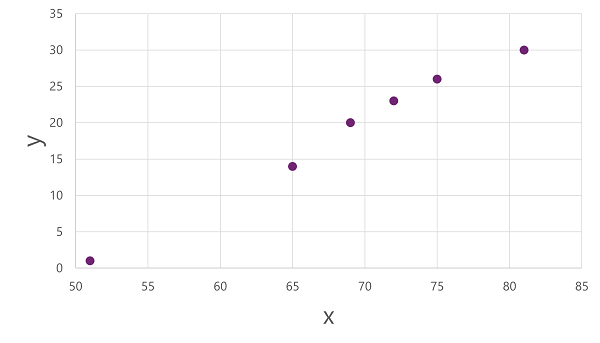
الآن نحن مستعدون لتطبيق خوارزمية على بيانات التدريب الخاصة بنا وملاءمتها مع دالة تطبق عملية على x لحساب y. إحدى هذه الخوارزميات هي الانحدار الخطي، والذي يعمل عن طريق اشتقاق دالة تنتج خطا مستقيما من خلال تقاطعات قيم x وyمع تقليل متوسط المسافة بين الخط والنقاط المرسومة، مثل هذا:
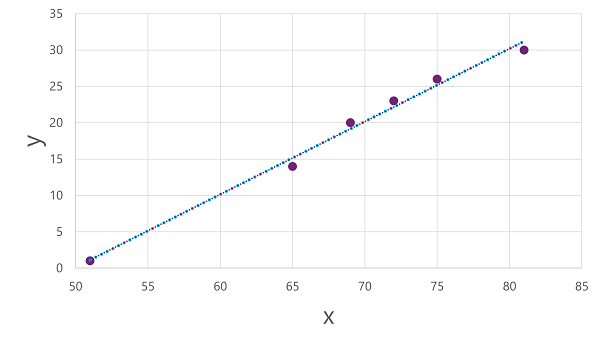
السطر هو تمثيل مرئي للدالة التي يصف فيها ميل الخط كيفية حساب قيمة y لقيمة معينة من x. يعترض الخط المحور س عند 50، لذلك عندما تكون x 50، تكون y هي 0. كما ترى من علامات المحور في الرسم، فإن منحدرات الخط بحيث تؤدي كل زيادة تبلغ 5 على طول المحور س إلى زيادة 5 لأعلى في المحور ص؛ لذلك عندما تكون x 55، y هي 5؛ عندما تكون x 60، y هي 10، وهكذا. لحساب قيمة y لقيمة معينة من x، تطرح الدالة ببساطة 50؛ وبعبارة أخرى، يمكن التعبير عن الدالة كما يلي:
f(x) = x-50
يمكنك استخدام هذه الدالة للتنبؤ بعدد الآيس كريمات المباعة في يوم واحد مع أي درجة حرارة معينة. على سبيل المثال، لنفترض أن توقعات الطقس تخبرنا أنه في الغد ستكون 77 درجة. يمكننا تطبيق نموذجنا لحساب 77-50 والتنبؤ بأننا سنبيع 27 الآيس كريم غدا.
ولكن ما مدى دقة نموذجنا؟
تقييم نموذج الانحدار
للتحقق من صحة النموذج وتقييم مدى توقعه، قمنا بالاحتفاظ ببعض البيانات التي نعرف قيمة التسمية (y). إليك البيانات التي قمنا بالاحتفاظ بها:
| درجة الحرارة (x) | مبيعات الآيس كريم (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| 78 | 26 |
| 83 | 36 |
يمكننا استخدام النموذج للتنبؤ بالتسمية لكل من الملاحظات في مجموعة البيانات هذه استنادا إلى قيمة الميزة (x)؛ ثم مقارنة التسمية المتوقعة (ŷ) بقيمة التسمية الفعلية المعروفة (y).
يؤدي استخدام النموذج الذي تدربناه سابقا، والذي يغلف الدالة f(x) = x-50، إلى التنبؤات التالية:
| درجة الحرارة (x) | المبيعات الفعلية (y) | المبيعات المتوقعة (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
يمكننا رسم كل من التسميات المتوقعة والفعلية مقابل قيم الميزة مثل هذا:
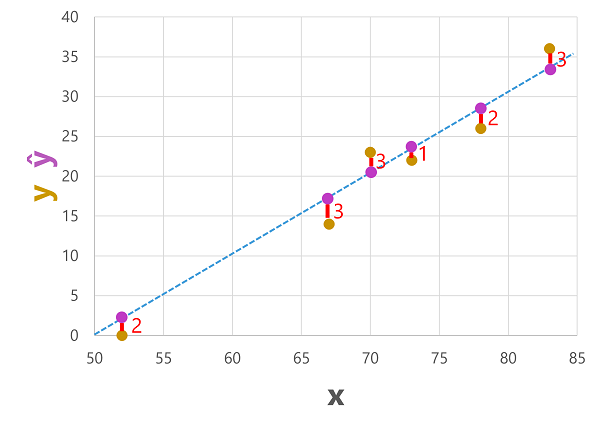
يتم حساب التسميات المتوقعة بواسطة النموذج بحيث تكون على سطر الدالة، ولكن هناك بعض التباين بين قيم ŷ المحسوبة بواسطة الدالة وقيم y الفعلية من مجموعة بيانات التحقق من الصحة؛ والتي يشار إليها في الرسم كخط بين قيم ŷ وy التي توضح مدى ابتعاد التنبؤ عن القيمة الفعلية.
مقاييس تقييم الانحدار
استنادا إلى الاختلافات بين القيم المتوقعة والقيم الفعلية، يمكنك حساب بعض المقاييس الشائعة المستخدمة لتقييم نموذج الانحدار.
متوسط الخطأ المطلق (MAE)
يشير التباين في هذا المثال إلى عدد الآيس كريمات التي كان كل تنبؤ بها خاطئا. لا يهم ما إذا كان التنبؤ قد تجاوز القيمة الفعلية أو تحتها (على سبيل المثال، يشير كل من -3 و+3 إلى تباين 3). يعرف هذا المقياس بالخطأ المطلق لكل تنبؤ، ويمكن تلخيصه لمجموعة التحقق الكاملة على أنه متوسط الخطأ المطلق (MAE).
في مثال الآيس كريم، متوسط (متوسط) الأخطاء المطلقة (2 و3 و3 و1 و2 و3) هو 2.33.
متوسط خطأ تربيعي (MSE)
يأخذ متوسط مقياس الخطأ المطلق جميع التناقضات بين التسميات المتوقعة والفعلية في الاعتبار على قدم المساواة. ومع ذلك، قد يكون من المستحسن أن يكون لديك نموذج خاطئ باستمرار بمقدار صغير من نموذج يجعل أخطاء أقل، ولكن أكبر. إحدى الطرق لإنتاج مقياس "تضخيم" أخطاء أكبر عن طريق تربيع الأخطاء الفردية وحساب وسط القيم التربيعية. يعرف هذا المقياس باسم متوسط الخطأ التربيعي (MSE).
في مثال الآيس كريم لدينا، متوسط القيم المطلقة التربيعية (وهي 4 و9 و9 و1 و4 و9) هو 6.
خطأ تربيعي متوسط الجذر (RMSE)
يساعد متوسط الخطأ التربيعي في أخذ حجم الأخطاء في الاعتبار، ولكن لأنه يربع قيم الخطأ، لم يعد المقياس الناتج يمثل الكمية التي تم قياسها بواسطة التسمية. وبعبارة أخرى، يمكننا أن نقول إن MSE لنموذجنا هو 6، ولكن هذا لا يقيس دقته من حيث عدد الآيس كريمات التي تم تحريفها؛ 6 هو مجرد درجة رقمية تشير إلى مستوى الخطأ في تنبؤات التحقق من الصحة.
إذا أردنا قياس الخطأ من حيث عدد الآيس كريمات، نحتاج إلى حساب الجذر التربيعي ل MSE؛ والذي ينتج مقياسا يسمى خطأ تربيعي متوسط الجذر. في هذه الحالة √6، وهو 2.45 (الآيس كريم).
معامل التحديد (R2)
تقارن جميع المقاييس حتى الآن التباين بين القيم المتوقعة والقيم الفعلية من أجل تقييم النموذج. ومع ذلك، في الواقع، هناك بعض التباين العشوائي الطبيعي في المبيعات اليومية من الآيس كريم التي يأخذها النموذج في الاعتبار. في نموذج الانحدار الخطي، تناسب خوارزمية التدريب خطا مستقيما يقلل من متوسط التباين بين الدالة وقيم التسمية المعروفة. معامل التحديد (يشار إليه عادة باسم R2 أو R-Squared) هو مقياس يقيس نسبة التباين في نتائج التحقق التي يمكن تفسيرها من قبل النموذج، بدلا من بعض الجوانب الشاذة لبيانات التحقق من الصحة (على سبيل المثال، يوم مع عدد غير معتاد للغاية من مبيعات الآيس كريم بسبب مهرجان محلي).
حساب R2 أكثر تعقيدا من المقاييس السابقة. يقارن مجموع الاختلافات التربيعية بين التسميات المتوقعة والتسميات الفعلية مع مجموع الاختلافات التربيعية بين قيم التسمية الفعلية وسط قيم التسمية الفعلية، مثل هذا:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
لا تقلق كثيرا إذا كان ذلك يبدو معقدا؛ يمكن لمعظم أدوات التعلم الآلي حساب المقياس نيابة عنك. النقطة المهمة هي أن النتيجة هي قيمة بين 0 و1 تصف نسبة التباين التي يشرحها النموذج. بعبارات بسيطة، كلما اقتربت هذه القيمة من 1، كلما كان النموذج مناسبا لبيانات التحقق من الصحة. في حالة نموذج انحدار الآيس كريم، يكون R2 المحسوب من بيانات التحقق من الصحة هو 0.95.
التدريب التكراري
تستخدم المقاييس الموضحة أعلاه عادة لتقييم نموذج الانحدار. في معظم سيناريوهات العالم الحقيقي، سيستخدم عالم البيانات عملية تكرارية لتدريب نموذج وتقييمه بشكل متكرر، متفاوتا:
- تحديد الميزات وإعدادها (اختيار الميزات التي يجب تضمينها في النموذج، والحسابات المطبقة عليها للمساعدة في ضمان ملاءمة أفضل).
- تحديد الخوارزمية (استكشفنا الانحدار الخطي في المثال السابق، ولكن هناك العديد من خوارزميات الانحدار الأخرى)
- معلمات الخوارزمية (إعدادات رقمية للتحكم في سلوك الخوارزمية، وتسمى بشكل أكثر دقة hyperparameters لتمييزها عن المعلمات x وy).
بعد تكرارات متعددة، يتم تحديد النموذج الذي ينتج عنه أفضل مقياس تقييم مقبول للسيناريو المحدد.