التصنيف الثنائي
نصيحة
راجع علامة التبويب النص والصور لمزيد من التفاصيل!
التصنيف، مثل الانحدار، هو تقنية تعلم آلي خاضعة للإشراف ؛ وبالتالي يتبع نفس العملية التكرارية لتدريب النماذج والتحقق من صحتها وتقييمها. بدلا من حساب القيم الرقمية مثل نموذج الانحدار، تحسب الخوارزميات المستخدمة لتدريب نماذج التصنيف قيم الاحتمال لتعيين الفئة ومقاييس التقييم المستخدمة لتقييم أداء النموذج مقارنة الفئات المتوقعة بالفئات الفعلية.
تستخدم خوارزميات التصنيف الثنائي لتدريب نموذج يتنبأ بأحد التسميات المحتملة لفئة واحدة. بشكل أساسي، التنبؤ بالقيمة الحقيقية أو الخاطئة. في معظم السيناريوهات الحقيقية، تتكون ملاحظات البيانات المستخدمة لتدريب النموذج والتحقق من صحته من قيم ميزة متعددة (x) وقيمة y إما 1 أو 0.
مثال - التصنيف الثنائي
لفهم كيفية عمل التصنيف الثنائي، دعونا ننظر إلى مثال مبسط يستخدم ميزة واحدة (x) للتنبؤ بما إذا كانت التسمية y هي 1 أو 0. في هذا المثال، سنستخدم مستوى السكر في الدم للمريض للتنبؤ بما إذا كان المريض مصابا بالسكري أم لا. إليك البيانات التي سندرب النموذج بها:

|

|
|---|---|
| جلوكوز الدم (x) | السكري؟ (y) |
| 67 | 1 |
| 103 | 1 |
| 114 | 1 |
| 72 | 1 |
| 116 | 1 |
| 65 | 1 |
تدريب نموذج تصنيف ثنائي
لتدريب النموذج، سنستخدم خوارزمية لملاءمة بيانات التدريب مع دالة تحسب احتمال صحة تسمية الفئة (بمعنى آخر، أن المريض مصاب بمرض السكري). يتم قياس الاحتمال كقيمة بين 0.0 و1.0، بحيث يكون الاحتمال الإجماليلجميع الفئات المحتملة هو 1.0. على سبيل المثال، إذا كان احتمال الإصابة بمرض السكري هو 0.7، فهناك احتمال مقابل يبلغ 0.3 أن المريض ليس مصابا بالسكري.
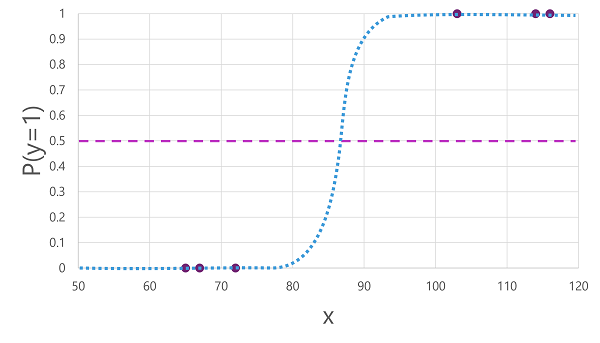
هناك العديد من الخوارزميات التي يمكن استخدامها للتصنيف الثنائي، مثل الانحدار اللوجستي، الذي يستمد دالة sigmoid (على شكل S) مع قيم بين 0.0 و1.0، مثل هذا:
إشعار
على الرغم من اسمه، يستخدم الانحدار اللوجستي للتعلم الآلي للتصنيف، وليس الانحدار. النقطة المهمة هي الطبيعة اللوجستية للدالة التي تنتجها، والتي تصف منحنى على شكل S بين القيمة الدنيا والأعلى (0.0 و1.0 عند استخدامها للتصنيف الثنائي).
تصف الدالة التي تنتجها الخوارزمية احتمال صحة y (y=1) لقيمة معينة من x. رياضيا، يمكنك التعبير عن الدالة كما يلي:
f (x) = P (y = 1 | x)
بالنسبة لثلاث من الملاحظات الست في بيانات التدريب، نعلم أن yصحيح بالتأكيد، لذا فإن احتمال أن تكون y=1 هي 1.0 وبالنسبة للملاحظات الثلاث الأخرى، نعلم أن yبالتأكيد خطأ، لذا فإن احتمال أن y=1 هو 0.0. يصف المنحنى على شكل S توزيع الاحتمال بحيث يحدد رسم قيمة x على السطر الاحتمال المقابل وهو y هو 1.
يتضمن الرسم التخطيطي أيضا خطا أفقيا للإشارة إلى الحد الذي سيتنبأ به النموذج المستند إلى هذه الدالة بالقيمة true (1) أو false (0). يقع الحد عند نقطة الوسط ل y (P(y) = 0.5). بالنسبة لأي قيم في هذه المرحلة أو أعلى، سيتنبأ النموذج بالقيمة true (1)؛ بينما بالنسبة لأي قيم أقل من هذه النقطة، فإنه سيتنبأ بالخطأ (0). على سبيل المثال، بالنسبة للمريض الذي لديه مستوى جلوكوز الدم 90، ستؤدي الدالة إلى قيمة احتمالية تبلغ 0.9. نظرا لأن 0.9 أعلى من عتبة 0.5، فإن النموذج يتوقع صواب (1) - وبعبارة أخرى، يتوقع أن يكون المريض مصابا بداء السكري.
تقييم نموذج تصنيف ثنائي
كما هو الحال مع الانحدار، عند تدريب نموذج تصنيف ثنائي، فإنك تمسك مجموعة فرعية عشوائية من البيانات للتحقق من صحة النموذج المدرب. لنفترض أننا قمنا بالاحتفاظ بالبيانات التالية للتحقق من صحة مصنف مرض السكري لدينا:
| جلوكوز الدم (x) | السكري؟ (y) |
|---|---|
| 66 | 1 |
| 107 | 1 |
| 112 | 1 |
| 71 | 1 |
| 87 | 1 |
| 89 | 1 |
يؤدي تطبيق الدالة اللوجستية التي اشتقناها سابقا إلى قيم x إلى الرسم التالي.
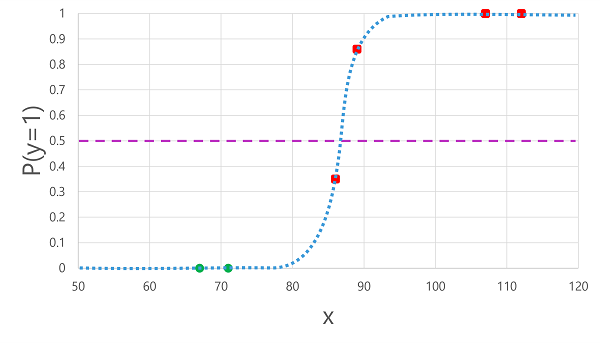
بناء على ما إذا كان الاحتمال المحسوب بواسطة الدالة أعلى من الحد أو أقل منه، ينشئ النموذج تسمية متوقعة من 1 أو 0 لكل ملاحظة. يمكننا بعد ذلك مقارنة تسميات الفئة المتوقعة (ŷ) بتسميات الفئة الفعلية (y)، كما هو موضح هنا:
| جلوكوز الدم (x) | تشخيص مرض السكري الفعلي (y) | تشخيص مرض السكري المتوقع (ŷ) |
|---|---|---|
| 66 | 1 | 1 |
| 107 | 1 | 1 |
| 112 | 1 | 1 |
| 71 | 1 | 1 |
| 87 | 1 | 1 |
| 89 | 1 | 1 |
مقاييس تقييم التصنيف الثنائي
عادة ما تكون الخطوة الأولى في حساب مقاييس التقييم لنموذج تصنيف ثنائي هي إنشاء مصفوفة لعدد التنبؤات الصحيحة وغير الصحيحة لكل تسمية فئة ممكنة:
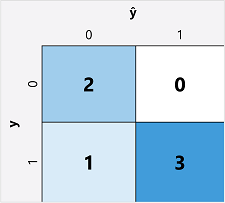
تسمى هذه المرئيات مصفوفة الارتباك، وتظهر إجماليات التنبؤ حيث:
- ŷ=0 وy=0: السلبيات الحقيقية (TN)
- ŷ=1 وy=0: الإيجابيات الخاطئة (FP)
- ŷ=0 وy=1: السلبيات الخاطئة (FN)
- ŷ=1 وy=1: الإيجابيات الحقيقية (TP)
ترتيب مصفوفة الارتباك بحيث تظهر التنبؤات الصحيحة (الحقيقية) في خط قطري من أعلى اليسار إلى أسفل اليمين. في كثير من الأحيان، يتم استخدام كثافة الألوان للإشارة إلى عدد التنبؤات في كل خلية، لذا فإن إلقاء نظرة سريعة على نموذج يتنبأ جيدا يجب أن يكشف عن اتجاه قطري مظلل بعمق.
الدقة
أبسط مقياس يمكنك حسابه من مصفوفة الارتباك هو الدقة - نسبة التنبؤات التي حصل عليها النموذج بشكل صحيح. يتم حساب الدقة على النحو التالي:
(TN + TP) ÷ (TN + FN + FP + TP)
في حالة مثال مرض السكري لدينا، فإن الحساب هو:
(2+3) ÷ (2+1+0+3)
= 5 ÷ 6
= 0.83
لذلك بالنسبة لبيانات التحقق من الصحة الخاصة بنا، نتج عن نموذج تصنيف مرض السكري تنبؤات صحيحة 83% من الوقت.
قد تبدو الدقة في البداية كمقياس جيد لتقييم نموذج، ولكن ضع في اعتبارك ذلك. لنفترض أن 11% من السكان مصابون بداء السكري. يمكنك إنشاء نموذج يتنبأ دائما ب 0، وسيحقق دقة 89%، على الرغم من أنه لا يجعل أي محاولة حقيقية للتمييز بين المرضى من خلال تقييم ميزاتهم. ما نحتاجه حقا هو فهم أعمق لكيفية أداء النموذج عند التنبؤ ب 1 للحالات الإيجابية و0 للحالات السلبية.
الاستدعاء
الاستدعاء هو مقياس يقيس نسبة الحالات الإيجابية التي حددها النموذج بشكل صحيح. وبعبارة أخرى، بالمقارنة مع عدد المرضى الذين يعانون من مرض السكري، كم عدد الذين توقع النموذج الإصابة بمرض السكري؟
صيغة الاستدعاء هي:
÷ TP (TP+FN)
بالنسبة لمثال مرض السكري لدينا:
3 ÷ (3+1)
= 3 ÷ 4
= 0.75
لذلك حدد نموذجنا بشكل صحيح 75% من المرضى الذين يعانون من مرض السكري على أنهم مصابون بالسكري.
الدقة
الدقة هي مقياس مشابه لاسترجاعه، ولكنها تقيس نسبة الحالات الإيجابية المتوقعة حيث تكون التسمية الحقيقية إيجابية بالفعل. وبعبارة أخرى، ما هي نسبة المرضى الذين توقعهم النموذج لمرض السكري بالفعل؟
صيغة الدقة هي:
÷ TP (TP+FP)
بالنسبة لمثال مرض السكري لدينا:
3 ÷ (3+0)
= 3 ÷ 3
= 1.0
لذا فإن 100% من المرضى الذين توقعهم نموذجنا لمرض السكري لديهم بالفعل مرض السكري.
درجة F1
درجة F1 هي مقياس إجمالي يجمع بين الاسترجاع والدقة. صيغة درجة F1 هي:
(2 × الدقة × الاستدعاء) ÷ (الدقة + الاستدعاء)
بالنسبة لمثال مرض السكري لدينا:
(2 × 1.0 × 0.75) ÷ (1.0 + 0.75)
= 1.5 ÷ 1.75
= 0.86
المنطقة تحت المنحنى (AUC)
اسم آخر للتذكر هو المعدل الإيجابي الحقيقي (TPR)، وهناك مقياس مكافئ يسمى المعدل الإيجابي الخاطئ (FPR) الذي يتم حسابه على أنه FP÷(FP+TN). نحن نعلم بالفعل أن TPR لنموذجنا عند استخدام حد 0.5 هو 0.75، ويمكننا استخدام صيغة FPR لحساب قيمة 0÷2 = 0.
وبطبيعة الحال، إذا أردنا تغيير الحد الذي يتنبأ النموذج أعلاه بالقيمة الحقيقية (1)، فإنه سيؤثر على عدد التنبؤات الإيجابية والسلبية؛ وبالتالي قم بتغيير مقاييس TPR وFPR. غالبا ما تستخدم هذه المقاييس لتقييم نموذج عن طريق رسم منحنى خاصية عامل التشغيل المستلم (ROC) الذي يقارن TPR وFPR لكل قيمة حد ممكنة بين 0.0 و1.0:
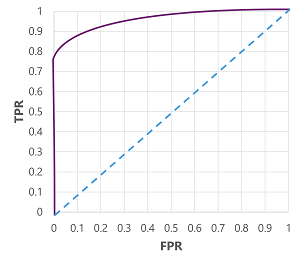
سوف ينتقل منحنى ROC لنموذج مثالي مباشرة إلى أعلى محور TPR على اليسار ثم عبر محور FPR في الأعلى. نظرا لأن منطقة الرسم للمنحنى تقيس 1x1، فإن المنطقة تحت هذا المنحنى المثالي ستكون 1.0 (مما يعني أن النموذج صحيح 100% من الوقت). في المقابل، يمثل الخط القطري من أسفل اليسار إلى أعلى اليمين النتائج التي سيتم تحقيقها عن طريق التخمين العشوائي لتسمية ثنائية؛ إنتاج منطقة تحت منحنى 0.5. بمعنى آخر، نظرا لتسمية فئتين محتملتين، يمكنك أن تتوقع بشكل معقول تخمين 50% من الوقت بشكل صحيح.
في حالة نموذج مرض السكري لدينا، يتم إنتاج المنحنى أعلاه، والمساحة تحت مقياس المنحنى (AUC) هي 0.875. نظرا لأن AUC أعلى من 0.5، يمكننا استنتاج أن أداء النموذج أفضل في التنبؤ بما إذا كان المريض مصابا بالسكري أم لا من التخمين العشوائي.