خيارات تكوين HDInsight
يحتوي HDInsight على مجموعة واسعة من تقنيات OSS المضمنة فيه والتي يمكن استخدامها للتعامل مع كل من سيناريوهات البيانات المتدفقة والدُفعية، وهي المصطلحات المحددة في بنيات Lambda. في نموذج البنية هذا، هناك مسار فوري للبيانات وآخر مؤقت. يتم إنشاء المسار الفوري للبيانات في الوقت الحقيقي بواسطة الأجهزة أو أجهزة الاستشعار أو التطبيقات ويُجرى تحليل البيانات في الوقت الحقيقي تقريبًا، وغالبًا ما يشار إلى ذلك باسم تدفق البيانات. يحدث مسار البيانات الباردة عندما يتم نقل البيانات على دفعات، عادةً من مخازن البيانات الأخرى وغالبًا ما يشار إليها باسم بيانات الدُفعات.
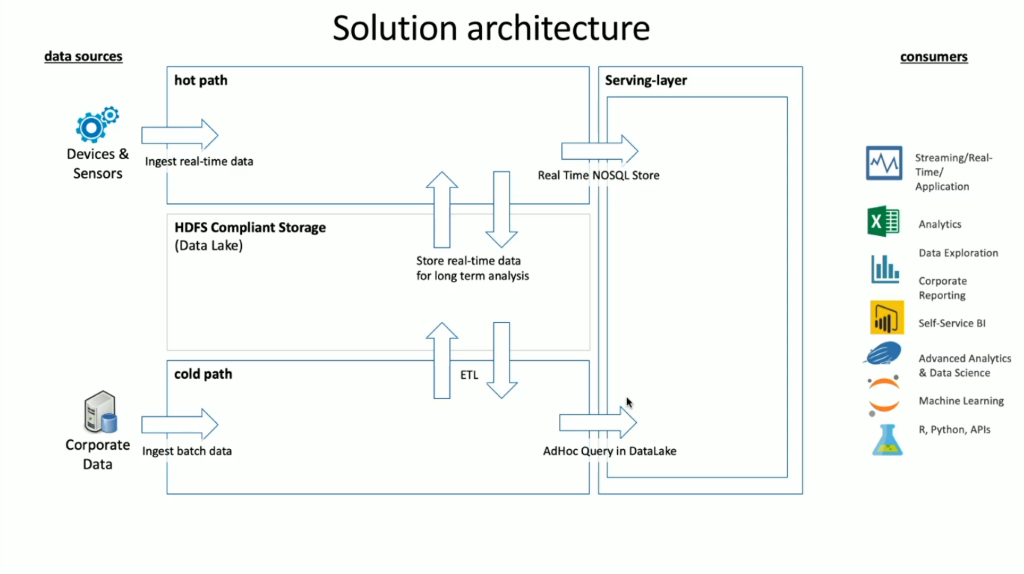
عند تنفيذ HDInsight، يتم تخزين البيانات داخل نظام الملفات الموزعة Hadoop المتوافق. في Azure، يتم استخدام Data Lake Gen2 عادةً كمخزن بيانات، نظراً إلى أنه متوافق مع HDFS. وتُخَزَّن البيانات من المسار الفوري والمسار المؤقت بعد المعالجة في مخزن بيانات مركزي يسمى Data Lake. يمكن تقسيم Data Lake في حد ذاتها للاحتفاظ بالبيانات في حجرات مختلفة، والتي يمكن تحديدها من خلال حالة البيانات (منطقة الهبوط، ومنطقة التحويل، وما إلى ذلك)، ومتطلبات الوصول (الفوري، والمتوسط، والمؤقت) ومجموعات الأعمال. طبقة العرض هي الحجرة النهائية في مستودع البيانات والتي تحتوي على البيانات في شكل جاهز للاستهلاك من قبل أنواع مختلفة من المستهلكين.
والأهم من ذلك، فإن الجانب الحسابي من HDInsight يتعامل مع معالجة البيانات المتدفقة أو بيانات الدفعة ويمكن أن تختلف اعتماداً على نوع نظام المجموعة الذي تحدده عند توفير نظام مجموعة HDInsight. ويُقدِّم HDInsight الخدمات في خيارات فردية لنظام المجموعة كما هو موضح في الجدول التالي.
| نوع نظام المجموعة | الوصف |
|---|---|
| Apache Hadoop | إطار عمل يستخدم HDFS، ونموذج برمجة MapReduce بسيط لمعالجة وتحليل بيانات المجمعة. |
| Apache Spark | إطار عمل معالجة متوازٍ مفتوح المصدر يدعم المعالجة داخل الذاكرة لتعزيز أداء تطبيقات تحليل البيانات الضخمة. |
| HBase | قاعدة بيانات NoSQL المبنية على Hadoop التي توفر الوصول العشوائي والاتساق القوي لكميات كبيرة من البيانات غير منظمة البنية وشبه منظمة البنية-- التي من المحتمل أن تصل إلى مليارات الصفوف أضعاف ملايين الأعمدة. |
| Apache Interactive Query | التخزين المؤقت في الذاكرة لاستعلامات Hive التفاعلية والسريعة. |
| Apache Kafka | منصة مفتوحة المصدر تستخدم للبنية الأساسية لبرنامج ربط العمليات التجارية والتطبيقات الخاصة بالبيانات المتدفقة. كما يوفر Kafka وظيفة قائمة الرسائل التي تسمح لك بنشر تدفقات البيانات والاشتراك فيها. |
لذلك، من المهم تحديد النوع الصحيح لنظام المجموعة لتلبية حالة الأعمال التي تحاول حلها. بغض النظر عن نوع نظام المجموعة المحدد، تتم أيضا إضافة مكونات مفتوحة المصدر إضافية داخل نظام المجموعة لتوفير قدرات إضافية بما في ذلك:
إدارة Hadoop
HCatalog - طبقة إدارة الجدول والتخزين ل Hadoop
Apache Ambari - يسهل إدارة ومراقبة مجموعة Apache Hadoop
Apache Oozie - نظام جدولة سير العمل لإدارة وظائف Apache Hadoop
Apache Hadoop YARN – يدير إدارة الموارد وجدولة/مراقبة الوظائف
Apache ZooKeeper - خدمة مركزية للحفاظ على معلومات التكوين، والتسمية، وتوفير المزامنة الموزعة، وتوفير خدمات المجموعة.
معالجة البيانات
Apache Hadoop MapReduce - إطار عمل لكتابة التطبيقات بسهولة، والتي تعالج كميات هائلة من البيانات
Apache Tez - إطار عمل تطبيق لمعالجة البيانات
Apache Hive - يسهل إدارة مجموعات البيانات الكبيرة الموجودة في التخزين الموزع باستخدام SQL
تحليل البيانات
Apache Pig – يوفر طبقة تجريد فوق MapReduce لتحليل مجموعات البيانات الكبيرة
Apache Phoenix - تمكين OLTP والتحليلات التشغيلية في Hadoop
Apache Mahout – إطار عمل الجبر لإنشاء خوارزميات خاصة بك
إشعار
في وقت الكتابة، تدعم Azure Data Lake Gen1 وAzure Blob Storage طبقات تخزين البيانات لـHDInsight. ينبغي أن ننظر في ترحيل هذه البيانات إلى Azure Data Lake Gen2، حيث إنها منصة التخزين الموصى بها لـ Spark وHadoop، فضلاً عن كونها الخيار الافتراضي لـ HBase.