الانتقال من MLOps التقليدية إلى LLMOps
تمثل عمليات MLOps (عمليات التعلم الآلي) و LLMOps (عمليات نموذج اللغة الكبيرة) نموذجين متميزين في تشغيل نماذج التعلم الآلي، ولكل منهما مجموعة خاصة به من التحديات والأدوات ومهام سير العمل.
بينما يركز MLOps التقليدي على نشر وإدارة مجموعة واسعة من نماذج التعلم الآلي، تم تصميم LLMOps خصيصا لنماذج اللغات الكبيرة (LLMs)، التي لها متطلبات فريدة من حيث الحجم وإدارة البيانات وضبط النماذج.
يدعم Azure Databricks كلا من MLOps و LLMOps، ولكن تختلف تفاصيل التنفيذ بشكل كبير. دعونا نستكشف الفرق من خلال مقارنة MLops ب LLMOps.
مقارنة MLOps ب LLMOps
يتضمن التعلم الآلي التقليدي عادة تدريب نموذج، مثل نموذج الانحدار، أو شبكة عصبية أكثر تعقيدا.
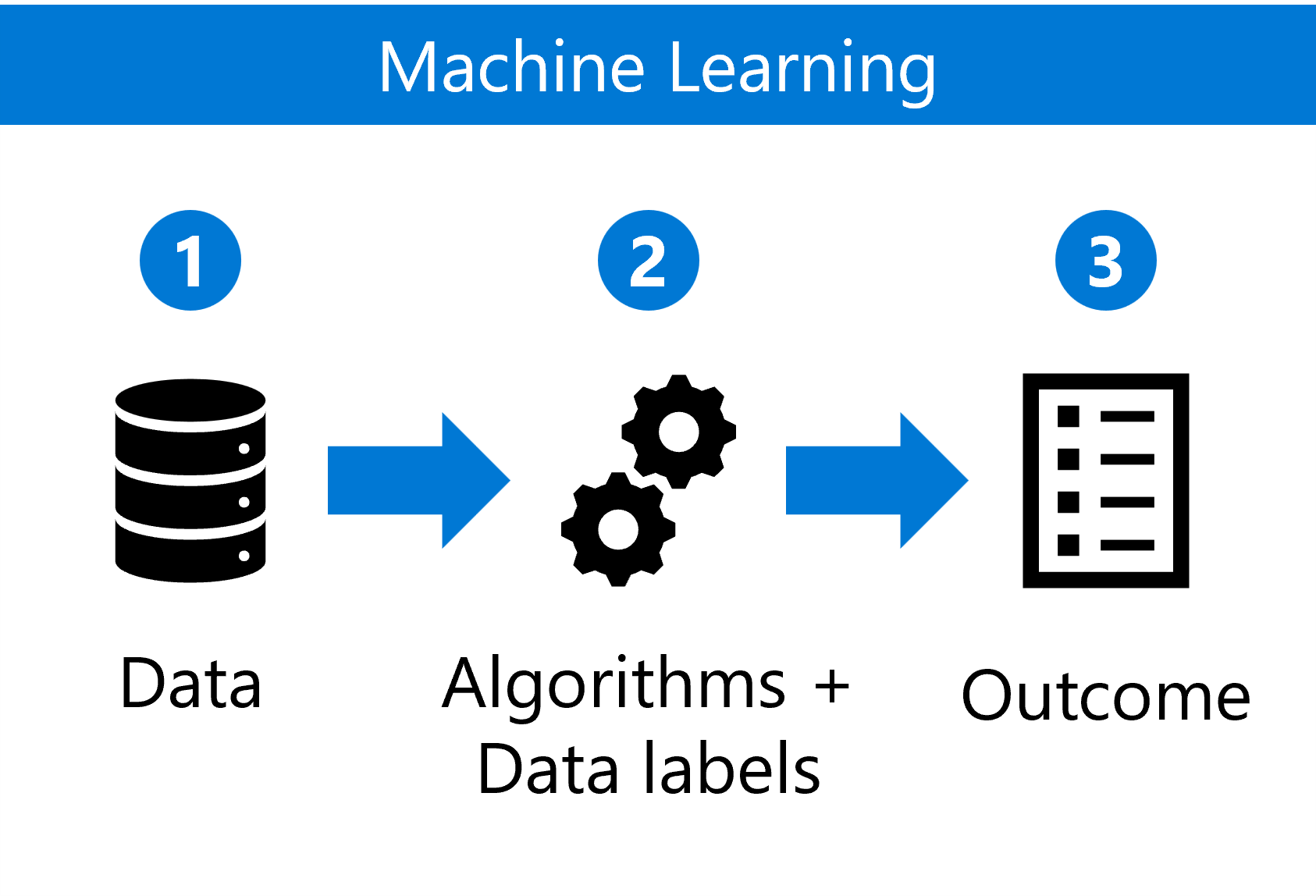
تتضمن عملية التعلم الآلي ما يلي:
- جمع مجموعة بيانات مناسبة واستكشافها وإعدادها.
- اختيار خوارزمية وتعريف تسميات البيانات.
- استخدام النموذج المدرب لإنشاء تنبؤات على بيانات جديدة.
ينصب التركيز التشغيلي على ضمان أن هذه النماذج يمكن أن تتوسع بكفاءة عبر بيئات وأحجام بيانات مختلفة.
تسهل Azure Databricks عمليات MLOps من خلال توفير موارد حوسبة قابلة للتطوير والتكامل مع Azure التعلم الآلي وأدوات مثل MLflow لتعقب النموذج ونشره.
من ناحية أخرى، تتعامل LLMOps مع نماذج اللغة المدربة مسبقا التي تعمل مع بنيات مثل المدخلات المستندة إلى النص، والمعروفة باسم المطالبات.
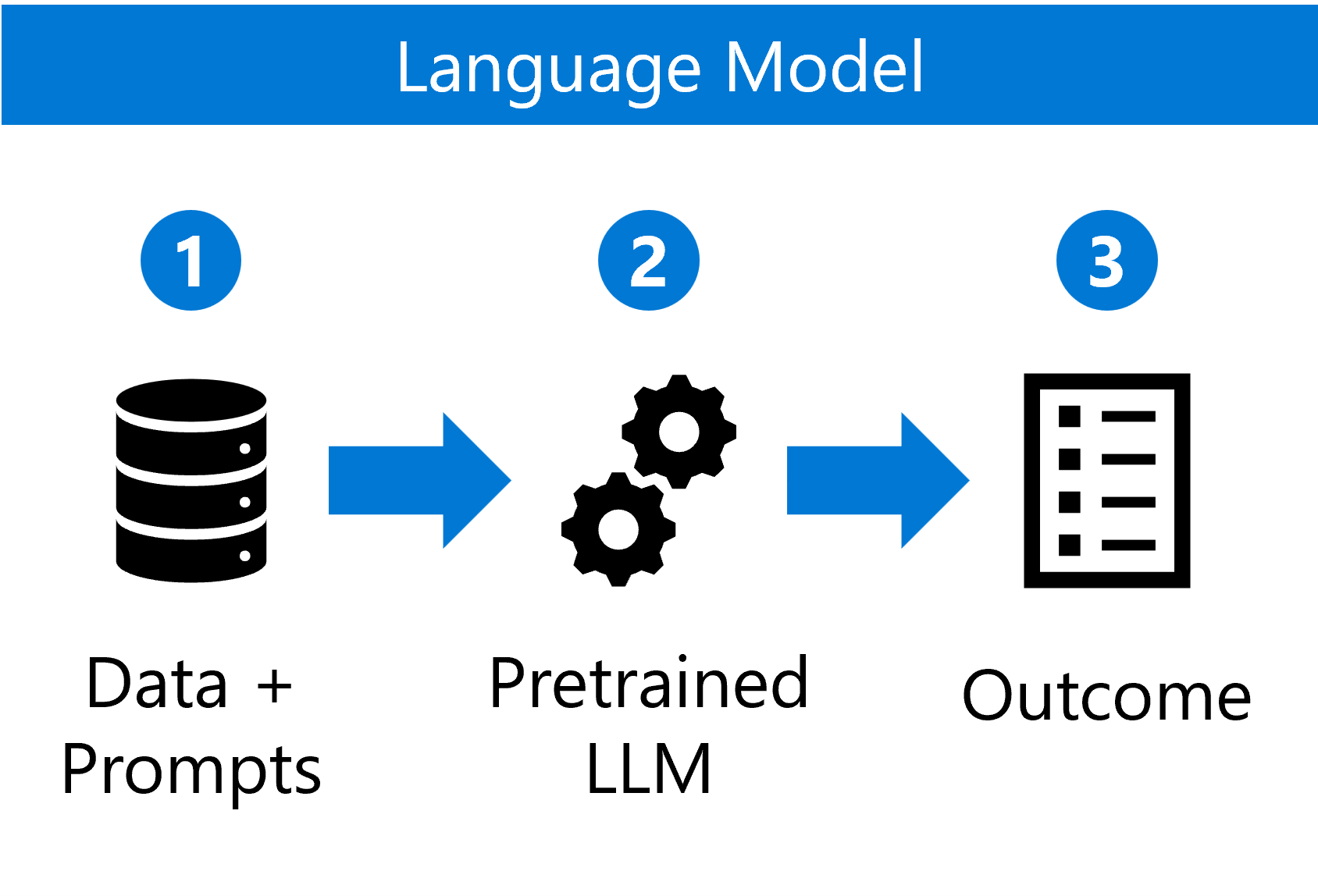
تتضمن عملية استخدام نموذج اللغة ما يلي:
- دمج البيانات مع المطالبات المتوقعة.
- اختيار وتكوين نموذج لغة مدرب مسبقا.
- استخدام النموذج المكون لإنشاء استجابات على المطالبات الجديدة.
تتعامل LLMOps مع النماذج الأكبر حجما، مثل GPT-3 أو GPT-4. لا تتطلب LLMs طاقة حسابية أكثر فحسب، بل تتطلب أيضا بنية أساسية متخصصة للتعامل مع مقياسها.
يوفر Azure Databricks مجموعات محسنة، والحوسبة الموزعة، والتكامل مع Azure OpenAI، ما يتيح نشر LLMs على نطاق واسع.
عندما نقارن MLOps ب LLMOps، هناك بعض الاختلافات الرئيسية التي نحتاج إلى فهمها.
إدارة البيانات النصية غير المنظمة
في MLOps التقليدية، يتم توسيط إدارة البيانات حول البيانات المنظمة وشبه المنظمة. داخل إدارة البيانات، ينصب التركيز على المعالجة المسبقة للبيانات وهندسة الميزات وأتمتة البنية الأساسية لبرنامج ربط العمليات التجارية.
ومع ذلك، تتطلب LLMOps معالجة كميات كبيرة من البيانات النصية غير المنظمة، ما يتطلب المزيد من استيعاب البيانات المعقدة وخطوط المعالجة المسبقة.
يتيح Azure Databricks، مع Microsoft Foundry، استيعاب ومعالجة مجموعات نصوص كبيرة، مما يتيح التدريب الفعال وضبط نماذج اللغة الكبيرة بدقة.
ضبط بدلا من التدريب من البداية
غالبا ما يتضمن MLOps التقليدي تدريب النموذج التكراري وضبط المعلمات الفائقة، مع التركيز على تحسين أداء النموذج لمهام محددة. تساعد أدوات مثل Hyperopt و AutoML (التعلم الآلي التلقائي) في Azure Databricks في أتمتة هذه العمليات.
ومع ذلك، تضع LLMOps تركيزا أكبر على ضبط النماذج المدربة مسبقا على مهام أو مجالات محددة.
يدعم Azure Databricks الضبط الدقيق من خلال تكامله مع خدمة Azure OpenAI، ما يتيح للمستخدمين ضبط LLMs مثل GPT-4 مع الحد الأدنى من تغييرات التعليمات البرمجية، باستخدام قوة الحوسبة الموزعة لأوقات تدريب أسرع.
استهلاك النموذج الذي تم توزيعه
في MLOps التقليدية، يتضمن النشر دمج النماذج في أنظمة الإنتاج باستخدام واجهات برمجة تطبيقات REST أو معالجة الدفعات أو نقاط نهاية الاستدلال في الوقت الفعلي.
ومع ذلك، في LLMOps، يحدث النشر في وقت سابق في دورة الحياة لأنك تعمل مع نماذج مدربة مسبقا وتركز على تكوين كيفية استدعاء هذه النماذج المنشورة. في LLMOps، تختلف استراتيجيات النشر الخاصة بك عن ممارسات MLOps التقليدية.
يوفر Azure Databricks نقاط نهاية مدارة لنشر LLMs، مع مراقبة وتسجيل مضمنين لضمان أداء النموذج وموثوقيته في بيئات الإنتاج. بدلا من ذلك، يمكنك نشر نماذج اللغة الكبيرة باستخدام Azure OpenAI وMicrosoft Foundry، ثم استخدامها وتكوينها في Azure Databricks.
تأمين النظام وتنفيذ الذكاء الاصطناعي المسؤول
تعد الحوكمة والامتثال والاستخدام المسؤول الذكاء الاصطناعي أمرا بالغ الأهمية في عمليات التعلم الآلي التقليدية. خاصة في الصناعات مثل التمويل والرعاية الصحية، حيث تحتاج النماذج إلى الالتزام بالمتطلبات التنظيمية الصارمة.
تقدم LLMOps تحديات أخرى في هذا المجال:
- تعد سلامة المحتوى واعتداله ضروريين لمنع نشر المعلومات الضارة.
- تحمي عمليات اختراق السجون والتدابير الأمنية من الهجمات المتطفلة.
- إن ضمان الشفافية وقابلية التفسير يبني الثقة من خلال جعل قرارات النموذج مفهومة.
- تحافظ حلقات المراقبة والملاحظات المستمرة على دقة النموذج والإنصاف والسلامة بمرور الوقت.
عند مواجهة هذه التحديات، فإنك تضمن تطوير LLMs ونشرها بمسؤولية، والالتزام بأعلى معايير الحوكمة والامتثال وممارسات الذكاء الاصطناعي المسؤولة.