تعريف بنية ومكونات ووظائف Data Deduplication
يجب أن تتعامل معظم المؤسسات والشركات، بما في ذلك Contoso، مع معالجة وتخزين حجم متزايد من البيانات. في حين أن هناك حلولاً تسمح لك بتفريغ البيانات وأرشفتها في السحابة، فمن الضروري في كثير من الحالات الاحتفاظ بها في مراكز البيانات الداخلية. وتتطلب الإدارة الفعالة لتخزين مثل هذه البيانات أدوات مناسبة. عند استخدام Windows Server، لديك خيار استخدام Data Deduplication لهذا الغرض.
ما هي Data Deduplication؟
Data Deduplication هي خدمة دور مقدمة من Windows Server تقوم بتحديد التكرار وحذفه داخل البيانات دون المساس بتكامل البيانات. وهذا يحقق أهداف تخزين المزيد من البيانات واستخدام مساحة فعلية أقل على القرص.
لتقليل استخدام القرص، تقوم Data Deduplication بالمسح الضوئي للملفات، ثم تقسيم هذه الملفات إلى مجموعات، والاحتفاظ بنسخة واحدة فقط من كل مجموعة. بعد إلغاء التكرار، لا يتم بعد ذلك تخزين الملفات كتدفقات مستقلة للبيانات. وبدلاً من ذلك، تبدّل Data Deduplication الملفات ليحل محلها كعوب تشير إلى كتل البيانات التي تخزنها في مخزن المجموعات المشتركة. تتسم عملية الوصول إلى البيانات غير المتكررة بأنها واضحة تمامًا للمستخدمين والتطبيقات.
وفي كثير من الحالات، تزيد Data Duplication من أداء القرص الكلي، حيث يمكن أن تتشارك ملفات متعددة في مجموعة واحدة مخزنة مؤقتًا في الذاكرة. وبهذه الطريقة، قد يكون من الممكن استرداد البيانات من هذه الملفات عن طريق إجراء عمليات قراءة أقل، ما يعوض تأثير الأداء الضعيف عند قراءة الملفات المتكررة. لا تؤثر Data Deduplication على أداء عمليات الكتابة على القرص، لأنه ينطبق على البيانات الموجودة بالفعل على القرص.
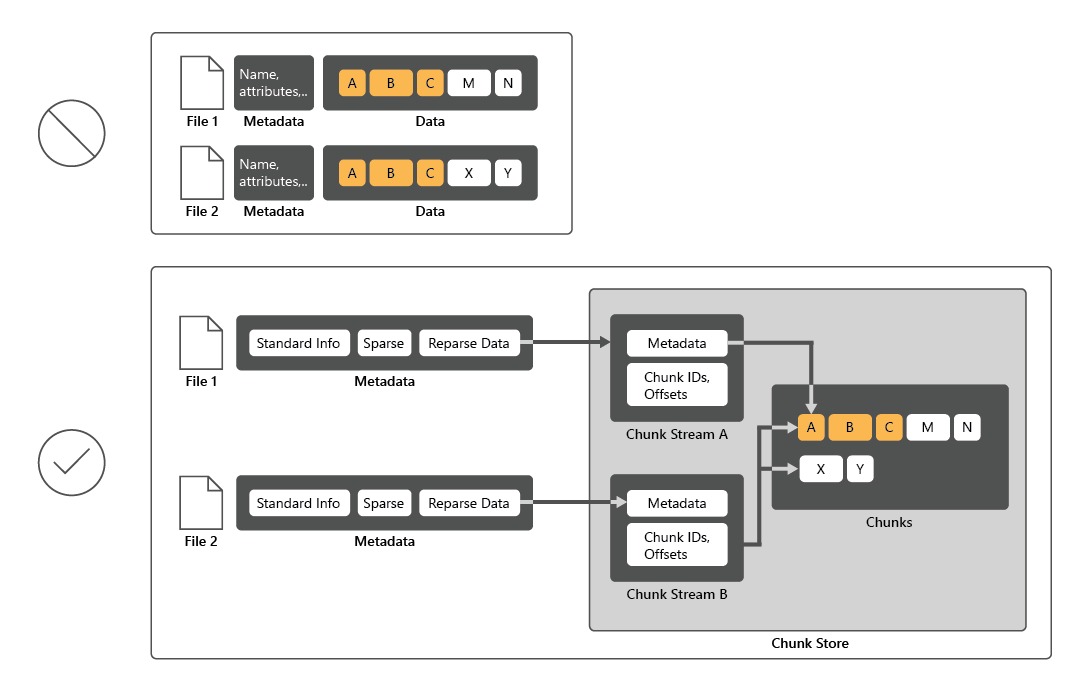
ما هي مكونات Data Deduplication؟
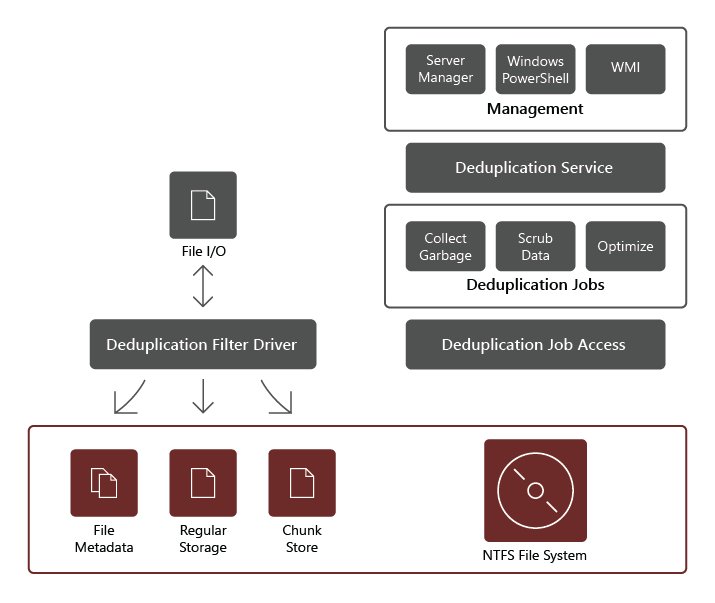
تتكون خدمة الدور Data Deduplication من المكونات التالية:
- برنامج تشغيل التصفية. يعيد هذا المكون توجيه طلبات القراءة إلى المجموعات التي تعد جزءًا من الملف المطلوب. يوجد برنامج تشغيل تصفية واحد لكل وحدة تخزين.
- خدمة إلغاء التكرار. يدير هذا المكون المهام التالية:
- إلغاء التكرار والضغط. تقوم هذه المهام بمعالجة الملفات وفقًا لنهج إلغاء تكرار البيانات لوحدة التخزين. بعد التحسين الأولي للملف، إذا تم تعديل الملف بعد ذلك واستوفى الحد الأدنى من نهج إلغاء تكرار البيانات من أجل التحسين، فسيتم تحسين الملف مرة أخرى.
- مجموعة البيانات المهملة. تعالج هذه الوظيفة البيانات المحذوفة أو المعدلة على وحدة التخزين بحيث يتم تنظيف أي مجموعات بيانات لم يعد يُشار إليها، ما ينتج عنه مساحة خالية على القرص. وبشكل افتراضي، يتم تشغيل مجموعة البيانات المهملة أسبوعيًا، ومع ذلك، يمكنك أيضًا تشغيلها بعد حذف العديد من الملفات.
- تنقية البيانات. تعتمد هذه الوظيفة على ميزات المرونة مثل التحقق من صحة المجموع الاختباري وفحص تناسق بيانات التعريف لتحديد مشكلات تكامل البيانات وحلها تلقائيًا متى أمكن ذلك.
إشعار
نظرًا إلى إمكانيات التحقق من الصحة الإضافية، يمكن لعملية إلغاء تكرار البيانات اكتشاف العلامات المبكرة لتلف البيانات والإبلاغ عنها.
- عدم التحسين. تعمل هذه الوظيفة على عكس عملية إلغاء تكرار البيانات على جميع الملفات المحسّنة الموجودة على وحدة التخزين. وتتضمن بعض السيناريوهات الشائعة لاستخدام هذا النوع من الوظائف مشكلات استكشاف الأخطاء وإصلاحها مع البيانات غير المتكررة أو ترحيل البيانات إلى نظام آخر لا يدعم Data Deduplication.
إشعار
قبل بدء هذه المهمة، يجب استخدام Disable-DedupVolume Windows PowerShell cmdlet لتعطيل مزيد من نشاط إلغاء تكرار البيانات على وحدة تخزين واحدة أو أكثر.
إشعار
بعد تعطيل Data Deduplication، تظل وحدة التخزين في الحالة غير المتكررة وتظل البيانات غير المتكررة الموجودة قابلة للوصول إليها، ومع ذلك، يتوقف الخادم عن تشغيل مهام التحسين لوحدة التخزين، ولا يقوم بتكرار البيانات الجديدة. بعد ذلك، يمكنك استخدام وظيفة عدم التحسين للتراجع عن إلغاء تكرار البيانات الموجودة على وحدة التخزين. في نهاية وظيفة عدم التحسين الناجحة، يتم حذف جميع بيانات التعريف الخاصة بإلغاء تكرار البيانات من وحدة التخزين.
هام
عند استخدام وظيفة عدم التحسين، تأكد من التحقق من أن وحدة التخزين التي تستضيف هذه البيانات تحتوى على مساحة خالية كافية، لأن جميع الملفات التي تم إلغاء تكرارها ستعود إلى حجمها الأصلي.
نطاق Data Deduplication
تعالج Data Deduplication جميع البيانات الموجودة على وحدة تخزين محددة، مع بضعة استثناءات، تشمل ما يلي:
- الملفات التي لا تتوافق مع نهج إلغاء تكرار البيانات الذي يمكنك تكوينه.
- الملفات الموجودة في المجلدات التي تقوم باستبعادها بشكل صريح من نطاق إلغاء التكرار.
- ملفات حالة النظام.
- تدفقات البيانات البديلة.
- الملفات المشفرة.
- الملفات ذات السمات الموسعة.
- الملفات الأصغر من 32 كيلوبايت.
إشعار
يدعم Resilient File System (ReFS) فيWindows Server 2019 data deduplication لوحدات تخزين يصل حجمها إلى 64 تيرابايت والملفات التي يصل حجمها إلى 4 تيرابايت. كما يعتمد أيضًا على مخزن مجموعات متغير الحجم يتضمن ضغطًا اختياريًا لزيادة توفير مساحة القرص إلى أقصى حد، بينما تحافظ بنية المعالجة اللاحقة متعددة مؤشرات الترابط على تأثير الأداء عند الحد الأدنى.