وصف الدفق المهيكل في Spark
يُعد الدفق المهيكل في Spark نظامًا أساسيًا شائعًا للمعالجة في الذاكرة. لديه نموذج موحد للدفعة والدفق. أي شيء تتعلمه وتستخدمه للدفعة، يمكنك استخدامه للدفق، لذلك من السهل أن تتطور من إرسال البيانات في دفعات إلى دفق البيانات. Spark Streaming هو ببساطة محرك يعمل فوق Apache Spark.

يُنشئ التدفق المهيكل استعلاماً طويل المدى تقوم خلاله بتطبيق العمليات على بيانات الإدخال، مثل التحديد، والإسقاط، والتجميع، ووضع النوافذ، والانضمام إلى دفق DataFrame مع DataFrames المرجعية. بعد ذلك، يمكنك إخراج النتائج إلى تخزين الملفات (Azure Storage Blobs، أو Data Lake Storage) أو إلى أي مستودع بيانات باستخدام التعليمات البرمجية المخصصة (مثل: SQL Database، أو Power BI). كما يوفر Structured Streaming الإخراج إلى وحدة التحكم لتصحيح الأخطاء داخليًا، وإلى جدول ذاكرة؛ بحيث يمكنك مشاهدة البيانات التي تم إنشاؤها لتصحيح الأخطاء في HDInsight.
تدفق البيانات في جداول
يمثل الدفق المهيكل في Spark دفقًا من البيانات في صورة جدول غير مقيد في العمق؛ أي: أن الجدول يستمر في النمو مع وصول البيانات الجديدة. تتم معالجة جدول الإدخال هذا بشكل مستمر بواسطة استعلام طويل المدى، ويتم إرسال النتائج إلى جدول الإخراج:

في Structured Streaming، تصل البيانات إلى النظام، ويتم استيعابها على الفور في جدول إدخال. تكتب الاستعلامات (باستخدام واجهات برمجة تطبيقات DataFrame وDataset) التي تنفذ العمليات مقابل جدول الإدخال. ينتج عن إخراج الاستعلام جدول آخر، جدول النتائج. يحتوي جدول النتائج على نتائج الاستعلام الخاص بك، والتي يمكنك من خلالها رسم بيانات لمستودع بيانات خارجي؛ مثل: قاعدة بيانات ارتباطية. يتم التحكم في توقيت معالجة البيانات من جدول الإدخال بواسطة فاصل التشغيل. بشكل افتراضي، الفاصل الزمني للتشغيل هو صفر؛ لذلك يحاول Structured Streaming معالجة البيانات بمجرد وصولها. في الممارسة العملية، هذا يعني أنه بمجرد انتهاء Structured Streaming من معالجة تشغيل الاستعلام السابق، فإنه يبدأ تشغيل معالجة أخرى لأي بيانات تم تلقيها حديثًا. يمكنك تكوين المشغل لتشغيله في فاصل زمني؛ بحيث تتم معالجة بيانات متدفقة على دفعات وفق توقيت محدد.
قد تحتوي البيانات الموجودة في جداول النتائج على البيانات الجديدة فقط منذ آخر مرة تمت فيها معالجة الاستعلام (وضع الإلحاق)، أو قد يتم تحديث الجدول في كل مرة توجد فيها بيانات جديدة بحيث يتضمن الجدول جميع بيانات الإخراج منذ بدء استعلام الدفق (الوضع الكامل).
وضع الإلحاق
في وضع الإلحاق، تكون الصفوف فقط التي تمت إضافتها إلى جدول النتائج منذ آخر مرة لتشغيل استعلام موجودة في جدول النتائج، ومكتوبة على وحدة تخزين خارجية. على سبيل المثال، يقوم الاستعلام الأبسط بنسخ جميع البيانات من جدول الإدخال إلى جدول النتائج دون تغيير. في كل مرة ينقضي الفاصل الزمني للتشغيل، تتم معالجة البيانات الجديدة، وتظهر الصفوف التي تمثل تلك البيانات الجديدة في جدول النتائج.
ضع في اعتبارك سيناريو تقوم فيه بمعالجة بيانات أسعار الأسهم. افترض أن المشغل الأول قام بمعالجة حدث واحد في الساعة 00:01 لسهم MSFT بقيمة 95 دولارًا. في المشغل الأول للاستعلام، يظهر فقط الصف مع الوقت 00:01 في جدول النتائج. في الساعة 00:02 عند وصول حدث آخر، يكون الصف الجديد الوحيد هو الصف الذي يحتوي على الوقت 00:02 ولذا فإن جدول النتائج سيحتوي على هذا الصف فقط.
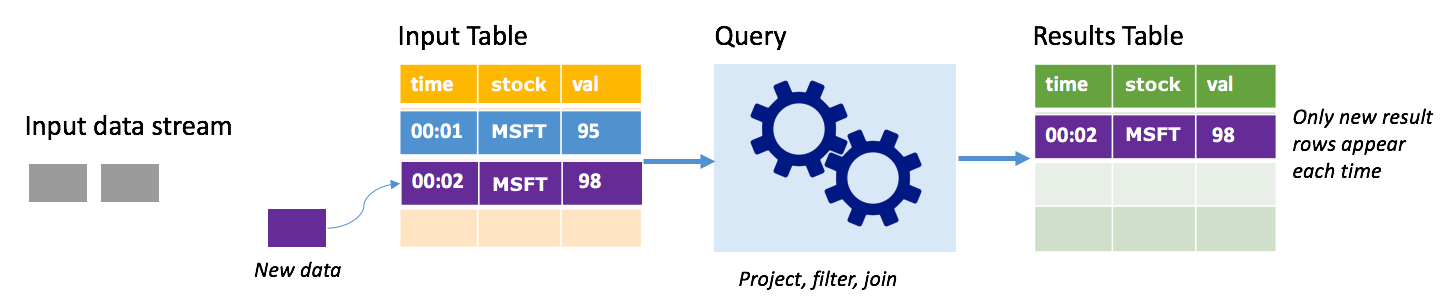
عند استخدام وضع الإلحاق، يكون الاستعلام الخاص بك تطبيق عمليات الإسقاط (تحديد الأعمدة التي يهتم بها) أو التصفية (انتقاء الصفوف التي تتطابق مع شروط معينة فقط) أو الربط (تعزيز البيانات ببيانات من جدول بحث ثابت). يجعل وضع الإلحاق من السهل دفع نقاط البيانات الجديدة ذات الصلة فقط إلى وحدة التخزين الخارجية.
الوضع الكامل
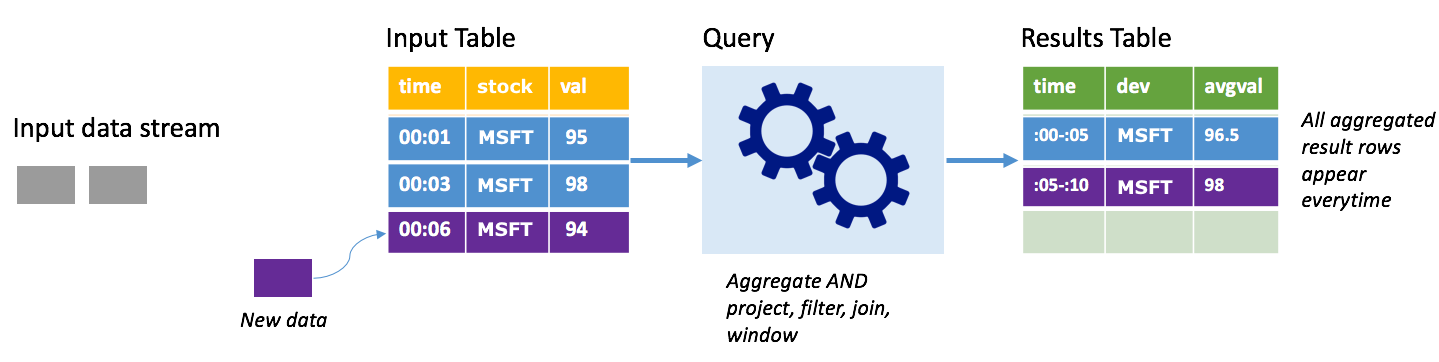
ضع في اعتبارك نفس السيناريو، هذه المرة باستخدام الوضع الكامل. في الوضع الكامل، يتم تحديث جدول الإخراج بأكمله على كل مشغل؛ بحيث يتضمن الجدول البيانات ليس فقط من تشغيل المشغل الأحدث؛ ولكن من كافة عمليات التشغيل. يمكنك استخدام الوضع الكامل لنسخ البيانات دون تغيير من جدول الإدخال إلى جدول النتائج. في كل تشغيل يتم تشغيله، تظهر صفوف النتائج الجديدة جنباً إلى جنب مع جميع الصفوف السابقة. سوف ينتهي جدول نتائج الإخراج بتخزين كافة البيانات التي تم تجميعها منذ بدء الاستعلام، ثم في نهاية المطاف ينتهي بك الأمر إلى نفاد الذاكرة. يخصص الوضع الكامل للاستخدام مع استعلامات التجميع التي تلخص البيانات الواردة بطريقة ما؛ لذلك مع كل مشغل يتم تحديث جدول النتائج بملخص جديد.
افترض حتى الآن أن هناك ما يعادل خمس ثوانٍ من البيانات تمت معالجتها بالفعل، وأن الوقت قد حان لمعالجة البيانات للثانية السادسة. يحتوي جدول الإدخال على أحداث للوقت 00:01 والوقت 00:03. الهدف من مثال الاستعلام هو إعطاء متوسط سعر السهم كل خمس ثوانٍ. تنفيذ هذا الاستعلام يطبق تجميعاً يأخذ كافة القيم التي تقع ضمن إطار زمني مدته 5 ثوانٍ، ويأخذ متوسط سعر السهم، وينتج صفاً لمتوسط سعر السهم خلال ذلك الفاصل الزمني. في نهاية أول إطار زمني مدته 5 ثوانٍ، هناك مجموعتان: (00:01, 1, 95)، و (00:03, 1, 98). لذلك للإطار 00:00-00:05 فإن استعلام التجميع ينتج مجموعة قيم بمتوسط سعر السهم 96.50 دولارًا. في الإطار الزمني المكون من 5 ثوانٍ التالية، هناك نقطة بيانات واحدة فقط في التوقيت 00:06، وبالتالي فإن سعر السهم الناتج هو 98 دولارًا. في الوقت 00:10، باستخدام الوضع الكامل، يحتوي جدول النتائج على صفوف لكلا الإطارين الزمنيين 00:00-00:05 و00:05-00:10؛ لأن الاستعلام ينتج كافة الصفوف المجمعة، وليس الجديدة فقط. لذلك، يستمر جدول النتائج في الزيادة كلما أضيفت إطارات زمنية جديدة.
لا تتسبب كافة الاستعلامات التي تستخدم الوضع الكامل في زيادة الجدول بدون حدود. ضع في اعتبارك في المثال السابق أنه بدلاً من حساب متوسط سعر السهم لكل إطار زمني، تم حساب متوسط السعر بدلاً من ذلك حسب السهم. يحتوي جدول النتائج على عدد ثابت من الصفوف (واحد لكل سهم) مع متوسط سعر السهم للأسهم بكافة نقاط البيانات التي تم تلقيها من ذلك الجهاز. عند تلقي أسعار الأسهم الجديدة، يتم تحديث جدول النتائج؛ بحيث تكون المتوسطات في الجدول دائمًا هي الحالية.
ما فوائد الدفق المهيكل في Spark؟
بما أننا في القطاع المالي، فإن توقيت المعاملات مهم جدًا. على سبيل المثال، في تداول الأسهم، الفرق بين وقت تداول الأسهم في سوق الأوراق المالية، أو عند تلقيك المعاملة، أو عندما تتم قراءة البيانات، كلها أمور مهمة. بالنسبة إلى المؤسسات المالية، فهي تعتمد على هذه البيانات المهمة، والتوقيت المرتبط بها.
وقت الحدث والبيانات المتأخرة، والعلامة المائية
يعرف الدفق المهيكل في Spark الفرق بين وقت الحدث، ووقت معالجة الحدث من قبل النظام. كل حدث يمثل صفًا في الجدول، ووقت الحدث قيمة عمود في الصف. يسمح هذا للتجميعات المستندة إلى إطار زمني (على سبيل المثال: عدد الأحداث كل دقيقة) أن تكون مجرد تجميع وإضافة على عمود وقت الحدث، وكل إطار وقت هو مجموعة، ويمكن أن ينتمي كل صف إلى عدة أطر زمنية/ مجموعات. لذلك، يمكن تعريف استعلامات التجميع المستندة إلى إطار وقت الحدث بشكل متناسق على كل من مجموعة بيانات ثابتة، وكذلك على دفق البيانات، ما يجعل حياة مهندس البيانات أسهل بكثير.
وعلاوة على ذلك، يعالج هذا النموذج بشكل طبيعي البيانات التي وصلت بعد الموعد المتوقع بناءً على وقت الحدث. يتحكم Spark تحكمًا كاملاً في تحديث التجميعات القديمة عند وجود بيانات متأخرة، بالإضافة إلى تنظيف التجميعات القديمة للحد من حجم بيانات الحالة الوسيطة. بالإضافة إلى ذلك، منذ صدور النسخة Spark 2.1، فإن Spark يدعم العلامات المائية، والذي يسمح لك بتحديد عتبة البيانات المتأخرة، ويسمح للمحرك بتنظيف الحالة القديمة وفقًا لذلك.
المرونة في تحميل البيانات الحديثة، أو كافة البيانات
كما ناقشنا في الوحدة السابقة، يمكنك اختيار استخدام وضع الإلحاق «Append»، أو الوضع الكامل «Complete» عند العمل مع الدفق الميهكل في Spark؛ بحيث يتضمن جدول النتائج الخاص بك البيانات الأحدث فقط، أو كافة البيانات.
دعم الانتقال من الدفعات الصغيرة إلى المعالجة المستمرة
بتغيير نوع المشغّل لاستعلام Spark، يمكنك الانتقال من معالجة الدفعات الصغيرة إلى المعالجة المستمرة دون تغييرات أخرى في إطار العمل الخاص بك. وهنا أنواع مختلفة من المشغلات التي يدعمها Spark.
- غير محدد، هذا هو الافتراضي. إذا لم يتم تعيين مشغل بشكل صريح، يتم تنفيذ الاستعلام في دفعات صغيرة، وستتم معالجتها بشكل مستمر.
- دفعة صغيرة مع فاصل زمني ثابت. يتم بدء الاستعلام في فواصل زمنية متكررة يضبطها المستخدم. إذا لم يتم تلقي بيانات جديدة، لا يتم تشغيل معالجة الدفعة الصغيرة.
- دفعة صغيرة لمرة واحدة. يقوم الاستعلام بتشغيل دفعة صغيرة واحدة، ثم يتوقف. هذا مفيد إذا كنت تريد معالجة كافة البيانات بعد الدفعة الصغيرة السابقة، ويمكن توفير التكاليف للوظائف التي لا تحتاج إلى تشغيل مستمر.
- مستمر بفاصل زمني ثابت عند نقطة التحقق. يتم تشغيل الاستعلام في زمن انتقال جديد منخفض، في وضع المعالجة المستمرة الذي يوفر زمن انتقال منخفض بين الطرفين (~ 1 مللي ثانية) مع ضمانات التسامح مع الخطأ لمرة واحدة على الأقل. هذا هو مماثل للافتراضي، والذي يمكن أن يحقق ضمانات لمرة واحدة بالضبط، ولكنه يحقق أزمنة انتقال تبلغ 100 مللي ثانية فقط في أحسن الأحوال.
الجمع بين وظائف الدفعة والدفق
بالإضافة إلى تبسيط الانتقال من وظائف الدفعة إلى الدفق، يمكنك كذلك الجمع بينهما. هذا مفيد خاصة عندما تريد استخدام بيانات تاريخية طويلة الأجل للتنبؤ بالاتجاهات المستقبلية في أثناء معالجة معلومات الوقت الحقيقي. بالنسبة إلى الأسهم، قد ترغب في النظر إلى سعر السهم على مدى السنوات الخمس الماضية بالإضافة إلى السعر الحالي، للتنبؤ بالتغييرات التي تحدث حول إعلانات الإيرادات السنوية أو الفصلية.
أطر وقت الحدث
قد ترغب في التقاط البيانات في أطر زمنية؛ مثل: ارتفاع سعر السهم، وانخفاض سعر السهم في إطار يوم واحد، أو خلال دقيقة واحدة- مهما كان الفاصل الزمني الذي تقرره، ويدعم الدفق المهيكل في Spark ذلك أيضًا. يدعم كذلك الأطر المتراكبة.
وضع نقاط تحقق للتعافي من الأعطال
في حالة حدوث عطل أو إيقاف تشغيل متعمد، يمكنك استرداد التقدم السابق، وحالة استعلام سابق، والمتابعة من حيث توقف. يتم ذلك باستخدام نقاط التحقق، وسجلات الكتابة المسبقة. يمكنك تكوين استعلام مع موقع نقطة تحقق، وسيقوم الاستعلام بحفظ كافة معلومات التقدم (أي نطاق الإزاحات المعالجة في كل مشغل)، والتجميعات قيد التشغيل في موقع نقطة التحقق. يجب أن يكون موقع نقطة التحقق مسارًا في نظام ملفات متوافق مع HDFS، ويمكن تعيينه كخيار في DataStreamWriter عند بدء تشغيل استعلام.