تمرين - نقل بيانات Kafka إلى دفتر ملاحظات Jupyter وعرض البيانات في نافذة
يقوم نظام المجموعة Kafka الآن بكتابة البيانات في سجله، والذي يمكن معالجته عبر Spark Structured Streaming.
يتم تضمين دفتر ملاحظات Spark في النموذج المستنسخ، لذا تحتاج إلى تحميل دفتر الملاحظات إلى نظام مجموعة Spark لاستخدامه.
تحميل دفتر ملاحظات Python إلى نظام مجموعة Spark
في مدخل Azure، انقر فوق "Home > HDInsight clusters" ثم اختر نظام مجموعة Spark الذي قمت بإنشائه للتو (وليس نظام مجموعة Kafka).
من جزء لوحات معلومات «Cluster»، انقر فوق «Jupyter notebook».

عند مطالبتك ببيانات الاعتماد، أدخل اسم مستخدم المسؤول، وأدخل كلمة المرور التي قمت بإنشائها عند إنشاء أنظمة المجموعات. يتم عرض موقع ويب Jupyter.
انقر فوق «PySpark»، ثم في صفحة PySpark، انقر فوق «Upload».
انتقل إلى الموقع حيث قمت بتنزيل النموذج من GitHub، اختر ملف RealTimeStocks.ipynb، ثم انقر فوق «Open»، ثم انقر فوق «Upload»، ثم انقر فوق «Refresh» في مستعرض الإنترنت.
بمجرد تحميل دفتر الملاحظات إلى مجلد PySpark، انقر فوق RealTimeStocks.ipynb؛ لفتح دفتر الملاحظات في المستعرض.
قم بتشغيل الخلية الأولى في دفتر الملاحظات عن طريق وضع المؤشر داخل الخلية، ثم النقر فوق «Shift+Enter» لتشغيل الخلية.
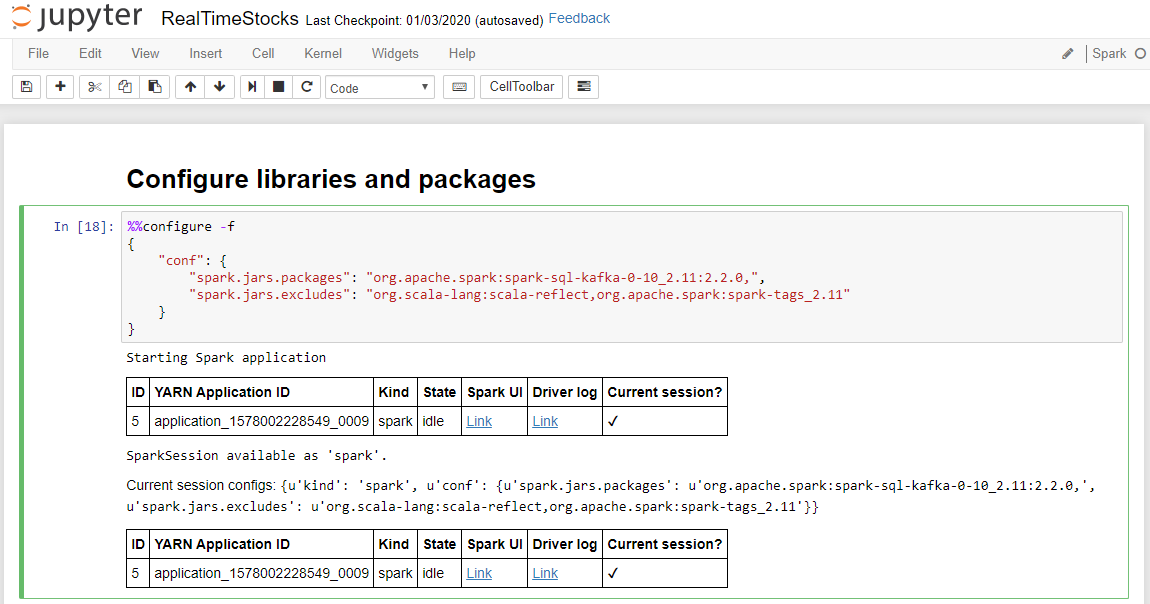
تكتمل خلية تكوين المكتبات والحزم بنجاح عندما تعرض رسالة بدء تشغيل تطبيق Spark ومعلومات إضافية كما هو موضح في التسمية التوضيحية للشاشة التالية.
في الاتصال الإعداد إلى خلية Kafka، في السطر .option("kafka.bootstrap.servers", "")، أدخل وسيط Kafka بين المجموعة الثانية من علامات الاقتباس. على سبيل المثال، .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"), then click Shift+Enter to run the cell.
يكتمل الإعداد الاتصال إلى خلية Kafka بنجاح عندما يعرض إدخال الرسالة inputDf: org.apache.spark.sql.DataFrame = [key: binary, value: binary ... 5 حقول أخرى]. يستخدم Spark واجهة برمجة تطبيقات readStream لقراءة البيانات.

حدد الخلية Read from Kafka into Streaming Dataframe ، ثم انقر فوق Shift+Enter لتشغيل الخلية.
تكتمل الخلية بنجاح عندما يعرض الرسالة التالية: stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 more fields]

حدد خلية Output Streaming Dataframe to Console، ثم انقر فوق Shift+Enter لتشغيل الخلية.
تكتمل الخلية بنجاح عندما تظهر معلومات مشابهة لما يلي. يظهر الإخراج قيمة كل خلية كما تم تمريرها في الدفعة الصغيرة، وتوجد دفعة واحدة في الثانية.

حدد الخلية «Windowed Stock Min / Max»، ثم انقر فوق «Shift+Enter» لتشغيل الخلية.
تكتمل الخلية بنجاح عندما توفر السعر الأعلى والأدنى لكل سهم في نافذة الثواني الأربعة، والتي يتم تعريفها في الخلية. كما نوقش في وحدة سابقة، فإن توفير معلومات عن إطارات زمنية محددة هي واحدة من المزايا التي تحصل عليها باستخدام Spark Structured Streaming.

اختر «Collect all values for stocks» في خلية إطار زمني، ثم انقر فوق «Shift+Enter» لتشغيل الخلية.
تكتمل الخلية بنجاح عندما توفر جدولاً بقيم الأسهم الموجودة في الجدول. اكتمل outputMode؛ ولذا يتم عرض كافة البيانات.

في هذه الوحدة، قمت بتحميل دفتر ملاحظات Jupyter إلى نظام مجموعة Spark، وتوصيله بنظام مجموعة Kafka، وإخراج البيانات المتدفقة التي يتم إنشاؤها بواسطة ملف منتج Python إلى دفتر ملاحظات Spark، وحددت إطارًا زمنيًا للبيانات المتدفقة، وعرضت أسعار الأسهم المرتفعة والمنخفضة في ذلك الإطار الزمني، وعرضت جميع قيم الأسهم في الجدول. تهانينا، لقد قمت بنجاح بإجراء الدفق المهيكل باستخدام Spark وKafka!