استيعاب البيانات باستخدام Azure Databricks
قبل أن تتمكن من العمل مع البيانات في Azure Databricks، تحتاج إلى استيعاب البيانات في النظام الأساسي. بمجرد دخولك إلى النظام الأساسي، يسمح لك الحساب المستند إلى السحابة بمعالجة كميات كبيرة من البيانات بكفاءة.
يتم تخزين البيانات في Azure Databricks باستخدام Apache Delta Lake، وهو نظام مفتوح المصدر لإدارة ملفات البيانات التي يمكن تعريف الجداول الارتباطية والاستعلام عنها. يمكن أن يختلف موقع التخزين الفعلي لملفات delta lake. يدعم Azure Databricks الاتصال بخدمات تخزين البيانات السحابية مثل Azure Storage وAzure Data Lake. يوفر Azure Databricks أيضا كتالوج الوحدة كحل حوكمة لإدارة وتتبع الوصول إلى البيانات والنسب عبر مخازن البيانات المتصلة المتعددة.
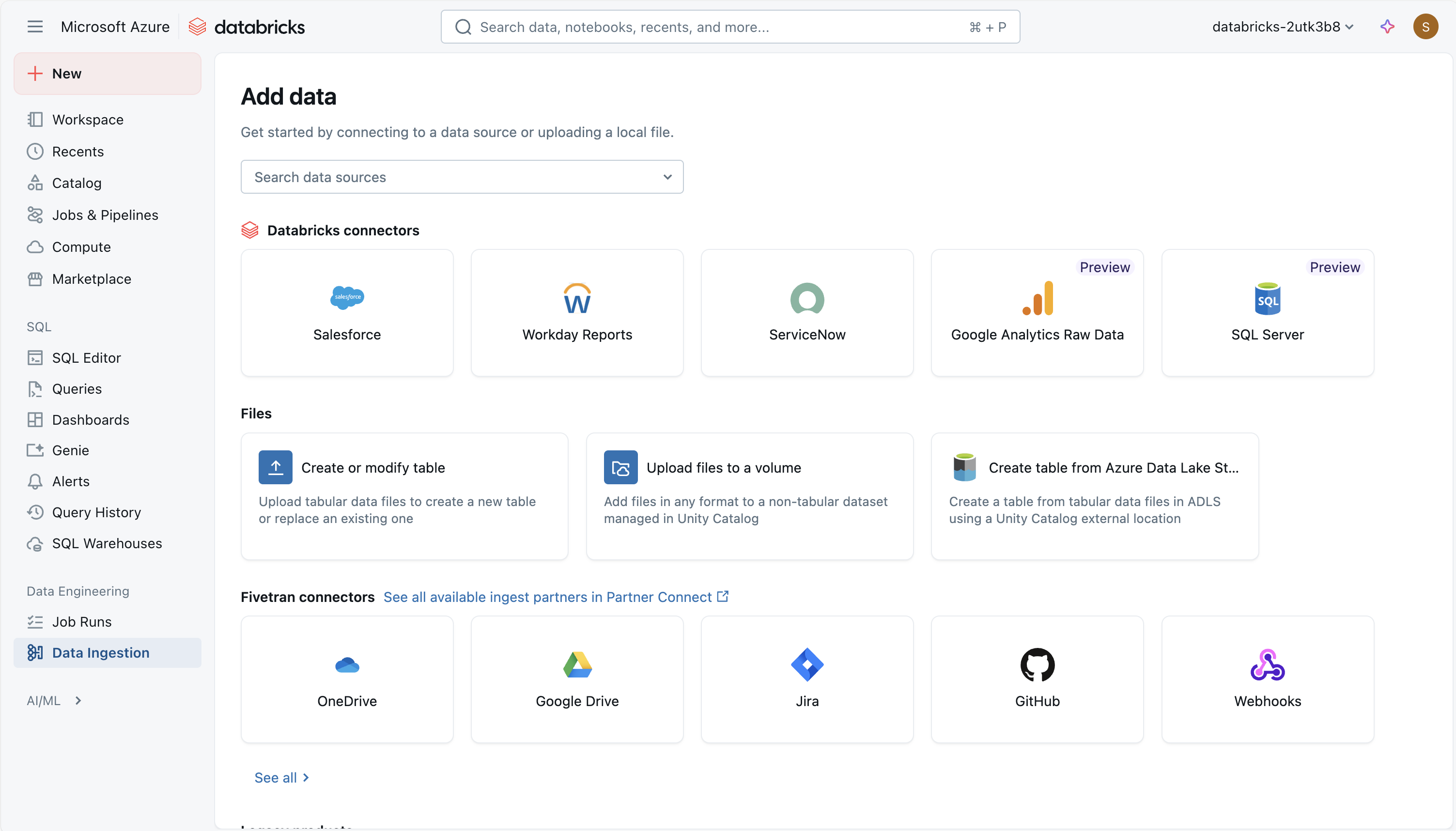
هناك طرق متعددة لاستيعاب البيانات في Azure Databricks، ما يجعلها أداة متعددة الاستخدامات وقوية لتحليل البيانات، بما في ذلك:
استخدام موصل Databricks المدار في Lakeflow Connect
يوفر Azure Databricks Lakeflow Connect إطارا لاستيعاب البيانات من تطبيقات SaaS وقواعد البيانات والمصادر الأخرى في البحيرة باستخدام الموصلات المدارة. تحدد هذه الموصلات كيفية إعداد المصادقة والمسارات وجداول الوجهة وصيانتها. بالنسبة لمصادر SaaS، فإن الأجزاء الرئيسية هي اتصال (للمصادقة)، ومسار استيعاب بلا خادم، وجداول دلتا التي تخزن البيانات التي تم استيعابها. تتضمن موصلات قاعدة البيانات نفس العناصر ولكنها تعتمد أيضا على بوابة استيعاب تعمل على الحوسبة الكلاسيكية ومنطقة تخزين مرحلية في كتالوج الوحدة للاحتفاظ بالبيانات المستخرجة مؤقتا. يتم التعامل مع التنسيق من خلال مهام Databricks، وتتم إدارة التحكم في الوصول والتدقيق من خلال كتالوج Unity.
يسمح استخدام الموصلات المدارة بجدولة مسارات البيانات وإعادة تجربتها وتوسيع نطاقها دون الحاجة إلى كتابة تعليمات برمجية استيعاب مخصصة. يتم دعم الابتلاع المتزايد ، مما يساعد على تقليل الحمل على أنظمة المصدر مع الحفاظ على تحديث الجداول. يركز النهج على الحوكمة المتسقة ومعالجة المخطط والمراقبة عبر مصادر البيانات المختلفة.
تتوفر الموصلات المدارة التالية:
- تحليلات جوجل
- Salesforce
- تقارير يوم العمل
- SQL Server
- ServiceNow
- SharePoint
تحميل الملفات إلى Azure Databricks
يمكنك استيراد ملفات CSV أو TSV أو JSON أو XML أو Avro أو Parquet أو ملفات نصية عادية محلية إلى Databricks لإنشاء جدول Delta. هذا الأسلوب مخصص للملفات الأصغر (أقل من 2 جيجابايت) المنقولة مباشرة من جهاز الكمبيوتر الخاص بك. الأرشيفات المضغوطة مثل ZIP أو TAR غير مدعومة. أثناء عملية التحميل، يوفر Databricks معاينة لما يصل إلى 50 صفا، ويمكنك ضبط إعدادات التنسيق لضمان التعرف على الأعمدة وأنواع البيانات في ملفات CSV أو JSON بشكل صحيح.
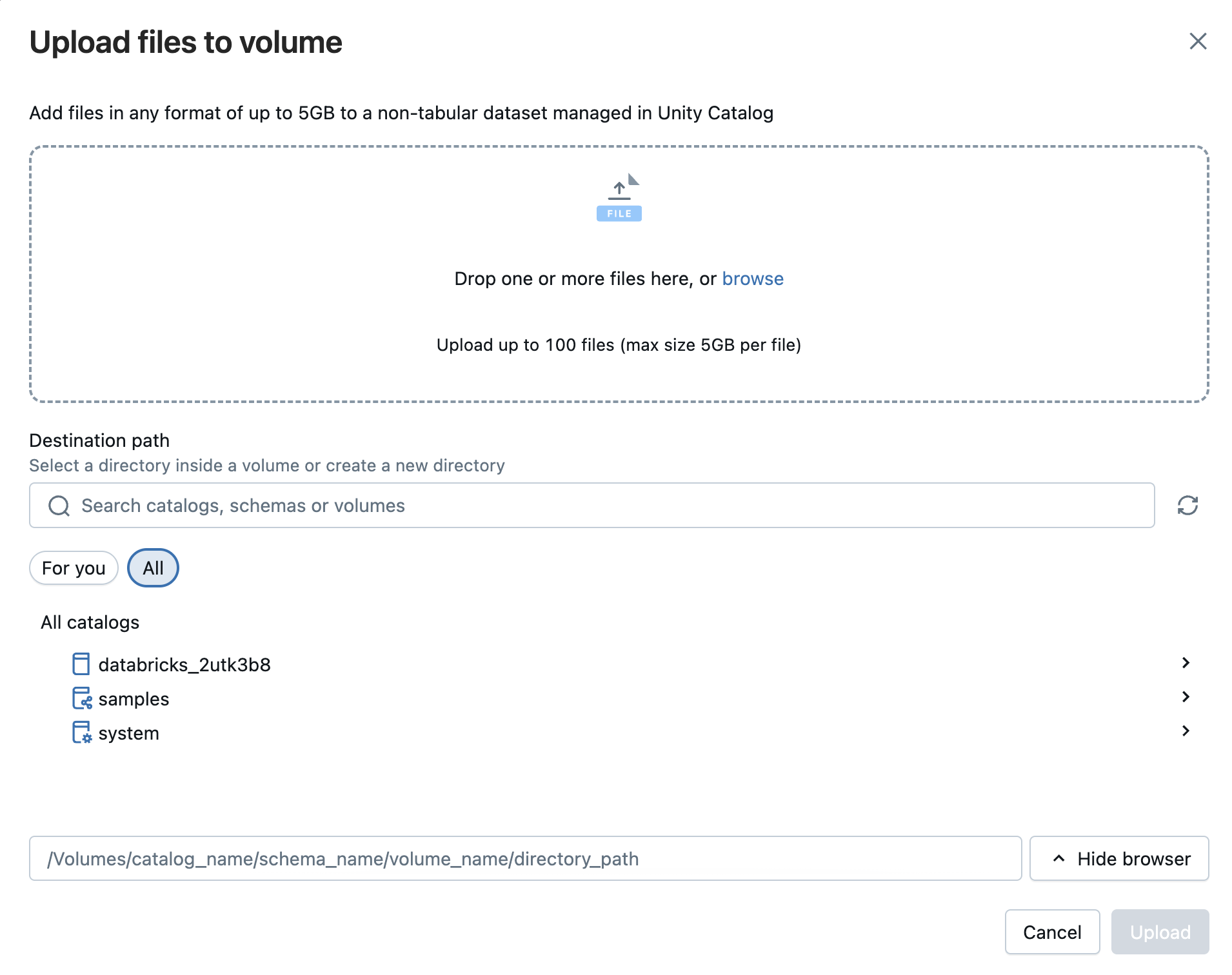
يمكنك أيضا تحميل ملفات بأي تنسيق - منظمة أو شبه منظمة أو غير منظمة - إلى وحدة تخزين. وحدة التخزين هي كائن كتالوج الوحدة الذي يوفر إدارة لمجموعات البيانات غير الجدولية ويمثل مساحة تخزين منطقية داخل مخزن كائنات سحابية. تتيح لك وحدات التخزين الوصول إلى الملفات وتخزينها وتنظيمها وتطبيقها على الحوكمة. هناك نوعان من المجلدات:
- وحدات التخزين المدارة: التخزين المدار بواسطة Databricks لحالات الاستخدام المباشرة.
- وحدات التخزين الخارجية: الحوكمة المطبقة على مواقع تخزين كائنات السحابة الموجودة.
Note
يتيح لك خيار DBFS استخدام تحميل ملف Databricks File System القديم. هذا لم يعد مدعوما.
استيعاب الملفات باستخدام واجهة برمجة تطبيقات Apache Spark
Apache Spark هو النظام الأساسي للحوسبة الأصلي ل Azure Databricks، وهو يدعم واجهات برمجة التطبيقات للغات برمجة متعددة، مثل Scala وJava وPySpark (متغير محسن ل Spark من Python) وSQL. لاستيعاب بسيط للبيانات في التخزين البعيد، يمكنك كتابة التعليمات البرمجية التي تتصل بالبيانات المطلوبة وتستوردها.
فيما يلي مثال باستخدام wget لسحب ملف بعيد إلى /tmp/ على عقدة برنامج التشغيل ، واستخدم Spark لقراءته من المسار المحلي ثم حفظه كجدول Delta في Databricks:
# Step 1: Use wget to download the file (e.g., a CSV from a public URL)
# In Databricks, prefix shell commands with "!"
!wget https://<location>/airtravel.csv -O /tmp/airtravel.csv
# Step 2: Load the downloaded file into a Spark DataFrame
df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file:/tmp/airtravel.csv")
# Step 3: Preview the data
df.show(5)
# Step 4: Save as a Delta table
df.write.format("delta").mode("overwrite").saveAsTable("default.airtravel")
تحميل البيانات باستخدام COPY INTO باستخدام كيان الخدمة
يمكنك استخدام COPY INTO الأمر لتحميل البيانات من حاوية Azure Data Lake Storage (ADLS) في حساب Azure الخاص بك إلى جدول في Databricks SQL.
COPY INTO my_json_data
FROM 'abfss://container@storageAccount.dfs.core.windows.net/jsonData'
FILEFORMAT = JSON;
خطوط أنابيب Lakeflow التصريحية
Lakeflow Declarative Pipelines هو إطار عمل تعريفي لتطوير وتشغيل مسارات البيانات المجمعة والتدفق في SQL و Python. وهو يدعم التنسيق الآلي ، وإعادة المحاولة ، وعزل الأخطاء ، وتطور المخطط ، والمعالجة المتزايدة ، والتقاط بيانات تغيير CDC من النوع 1 و 2.
التدفق هو مفهوم معالجة البيانات التأسيسي في خطوط أنابيب Lakeflow التقريرية ، والذي يدعم كلا من دلالات التدفق والدفعات. يقرأ التدفق البيانات من مصدر، ويطبق منطق المعالجة المعرفة من قبل المستخدم، ويكتب النتيجة في هدف.
يمكنك أيضا إدارة جودة البيانات مع توقعات البنية الأساسية لخط الأنابيب، والتي تسمح لك بتحديد قواعد التحقق من الصحة التي تضمن أن البيانات تفي بالمعايير المطلوبة قبل كتابتها إلى وجهتها.
فيما يلي مثال على خط أنابيب تعريفي:
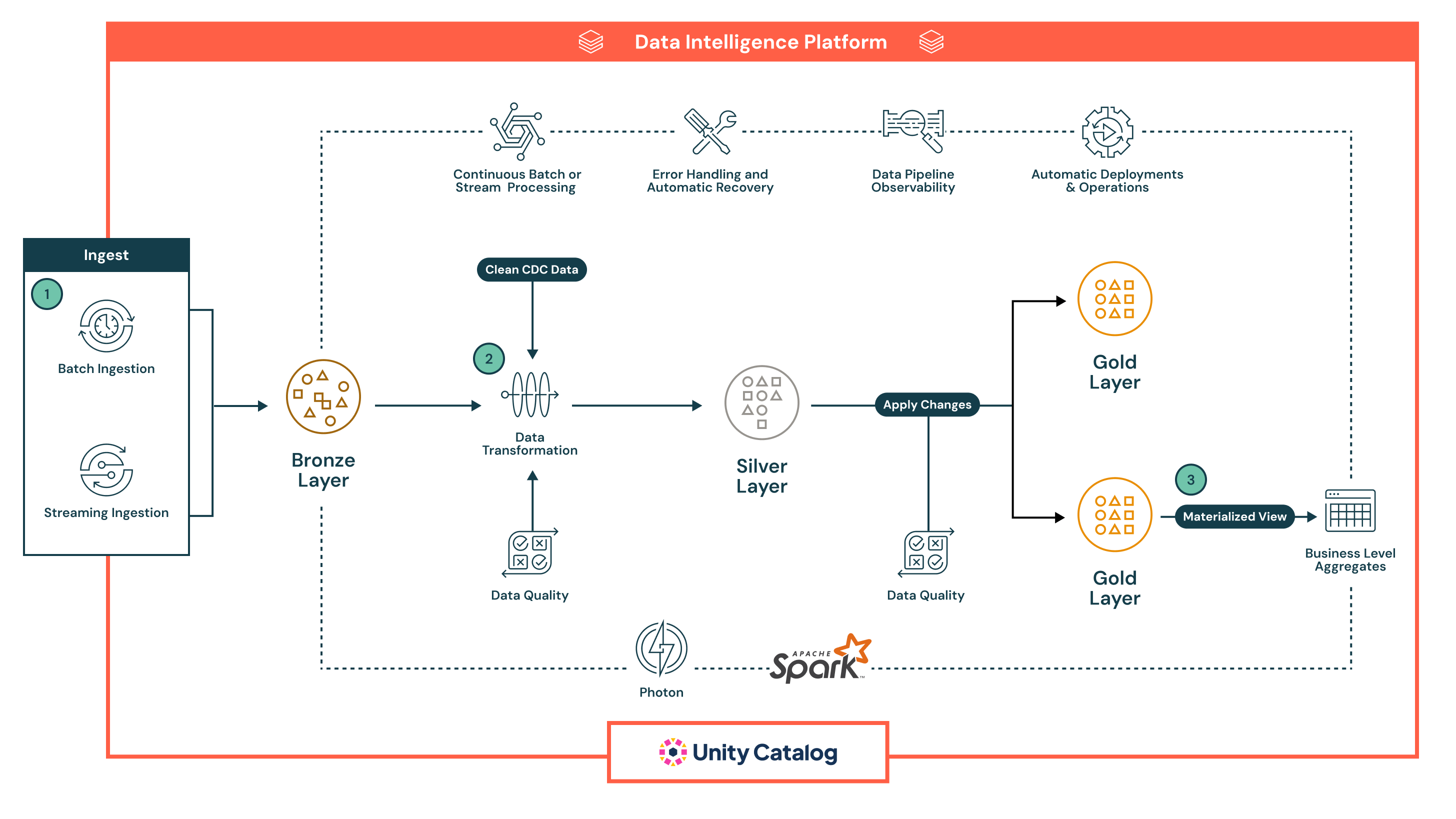
في هذا المثال، تهبط البيانات أولا في الطبقة البرونزية في شكل أولي للنسب وإعادة المعالجة الآمنة، ثم تتقدم إلى الطبقة الفضية ، حيث يتم تنظيفها وإثرائها والتحقق من صحتها باستخدام فحوصات الجودة المضمنة، ومعالجتها على نطاق واسع باستخدام Spark، قبل الوصول إلى الطبقة الذهبية ، التي توفر مجموعات بيانات منسقة وجاهزة للأعمال لذكاء الأعمال والتعلم الآلي وحالات الاستخدام المتقدمة مثل التتبع التاريخي.
Azure Data Factory
يمكنك Azure Data Factory (ADF) من نسخ البيانات من وإلى Azure Databricks Delta Lake باستخدام نشاط النسخ المضمن. عند العمل كمصدر، يمكن ل ADF استخراج البيانات من جداول Delta في Databricks ونقلها إلى المصارف المدعومة. عند العمل كحوض ، يمكنه تحميل البيانات في جداول Delta Lake من المصادر المدعومة.
يتم تنسيق حركة البيانات عن طريق استدعاء مجموعة Databricks للتعامل مع النقل، ويدعم ADF كلا من أوقات تشغيل تكامل Azure وأوقات تشغيل التكامل المستضافة ذاتيا اعتمادا على البيئة.
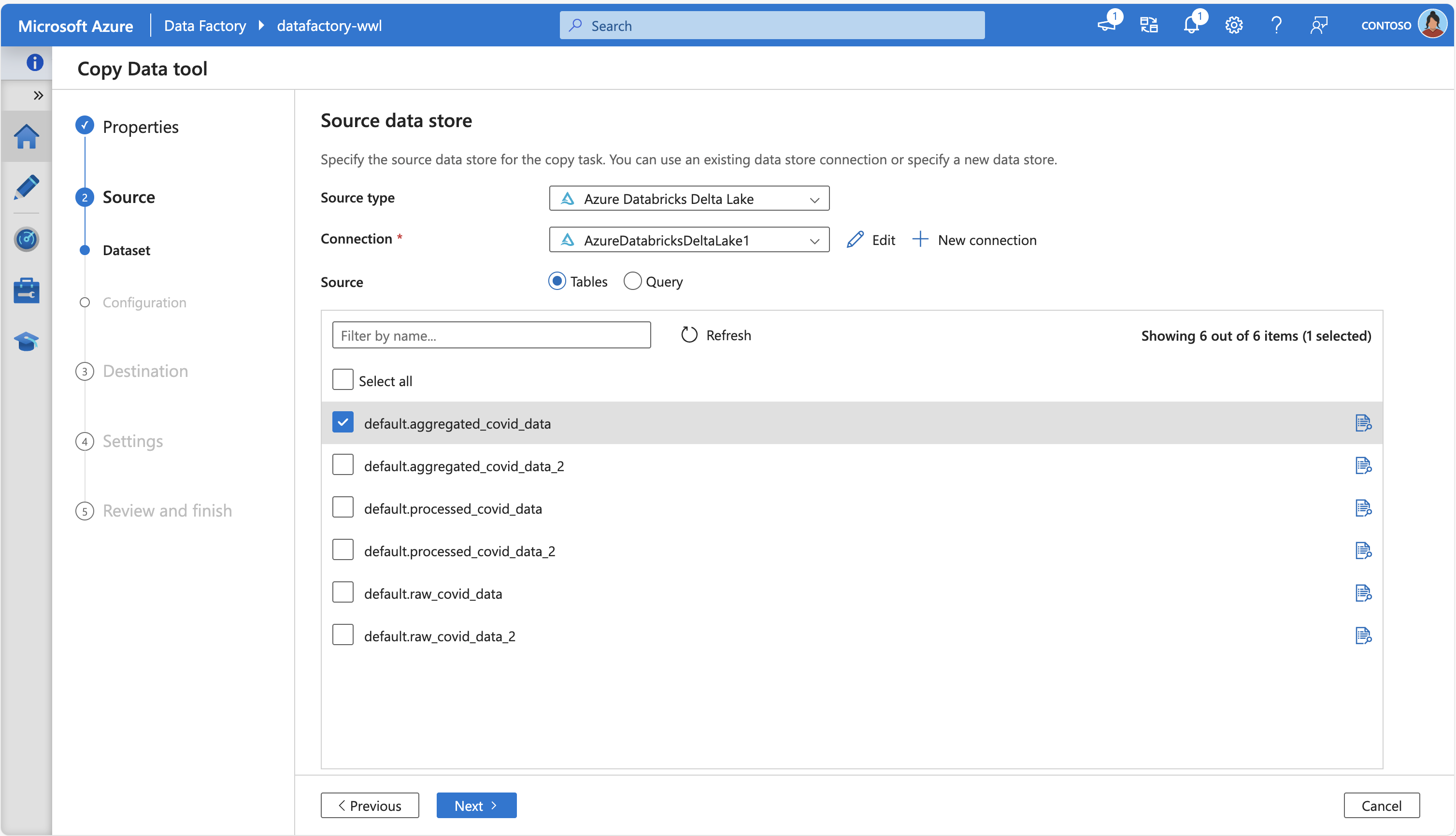
تظهر لقطة الشاشة التالية أداة نسخ بيانات Azure Data Factory، التي تتصل ب Azure Databricks Delta Lake لجلب بعض جداول المصدر:
بالإضافة إلى ذلك، توفر تدفقات بيانات تعيين ADF تجربة ETL خالية من التعليمات البرمجية: يمكنها الحصول من بيانات بتنسيق Delta والانغماس فيها على Azure Storage، مما يتيح التحويلات دون كتابة التعليمات البرمجية، وتشغيلها على Azure Integration Runtime المدار.
مراكز أحداث Azure ومراكز IoT
لاستيعاب البيانات في الوقت الفعلي، تعد Azure Event Hubs وIoT Hubs هي الخيارات الأكثر ملاءمة. فهي تمكنك من دفق البيانات مباشرة إلى Azure Databricks، ما يسمح لك بمعالجة البيانات وتحليلها عند وصولها. يعد استيعاب البيانات وتحليلها في الوقت الحقيقي مفيدا لسيناريوهات مثل مراقبة الأحداث المباشرة أو تعقب بيانات جهاز إنترنت الأشياء (IoT).
يحتوي Azure Event Hubs على نقطة نهاية متوافقة مع Kafka تعمل مع موصل Kafka للتدفق المنظم في Databricks Runtime. يمكنك إعداد مسارات Lakeflow التعريفية للاتصال بمثيل مراكز الأحداث واستهلاك الأحداث من موضوع.