تمرين - تنظيف البيانات وإعدادها
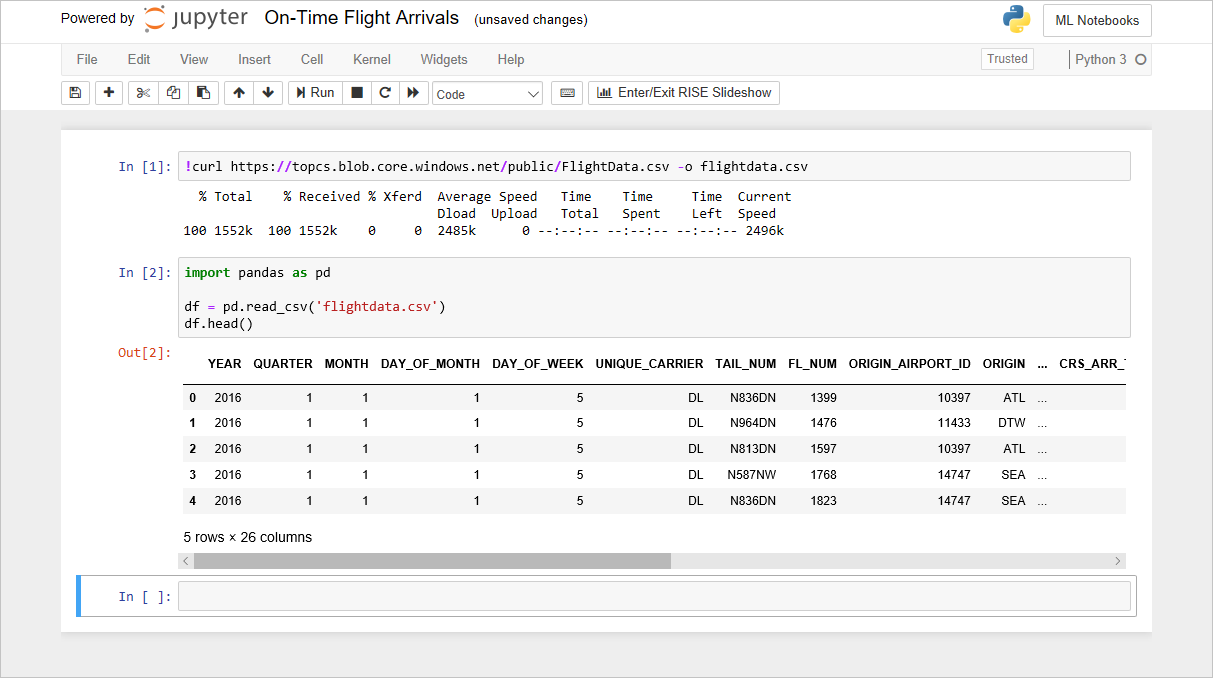
قبل أن تتمكن من إعداد مجموعة بيانات، تحتاج إلى فهم محتواها وبنيتها. في المعمل السابق، قمت باستيراد مجموعة بيانات تحتوي على معلومات الوصول في الوقت المحدد لشركة طيران أمريكية كبرى. وشملت تلك البيانات 26 عمودًا وآلاف الصفوف، حيث يمثل كل صف رحلة واحدة، ويحتوي على معلومات؛ مثل: أصل الرحلة، ووجهتها، ووقت المغادرة المقرر. قمت أيضًا بتحميل البيانات في دفتر ملاحظات Jupyter، واستخدمت برنامج نصي Python بسيط؛ لإنشاء Pandas DataFrame منه.
DataFrame هو بنية بيانات ذات تسمية ثنائية الأبعاد. يمكن أن تكون الأعمدة في DataFrame من أنواع مختلفة، تمامًا مثل الأعمدة في جدول بيانات، أو جدول قاعدة بيانات. وهو العنصر الأكثر استخدامًا في Pandas. في هذا التمرين، سوف تفحص الـ DataFrame — والبيانات داخلها — بشكل أكبر عن كثب.
التحول مرة أخرى إلى Azure notebook الذي قمت بإنشائه في المقطع السابق. إذا قمت بإغلاق دفتر الملاحظات، يمكنك تسجيل الدخول مرة أخرى إلى مدخل Microsoft Azure Notebooks، افتح دفتر ملاحظاتك، واستخدم Cell ->Run All لإعادة تشغيل جميع الخلايا في دفتر الملاحظات بعد فتحه.
دفتر ملاحظات FlightData
تنشئ التعليمات البرمجية التي أضفتها إلى دفتر الملاحظات في المختبر السابق DataFrame من flightdata.csv وتستدعي DataFrame.head عليه لعرض الصفوف الخمسة الأولى. أحد أول الأشياء التي تريد عادةً معرفتها حول مجموعة البيانات؛ هي عدد الصفوف التي تحتوي عليها. للحصول على عدد، اكتب العبارة التالية في خلية فارغة في نهاية دفتر الملاحظات، وقم بتشغيلها:
df.shapeتأكد من أن "DataFrame" تحتوي على 11,231 صف و26 عمود:

الحصول على عدد الصفوف والأعمدة
الآن خذ لحظة لفحص الـ 26 عمود في مجموعة البيانات. تحتوي الأعمدة على معلومات هامة؛ مثل: تاريخ الرحلة (YEAR، وMONTH، وDAY_OF_MONTH)، وأصل الرحلة والوجهة (ORIGIN وDEST)، وأوقات المغادرة والوصول المقررة (CRS_DEP_TIME، وCRS_ARR_TIME)، والفرق بين وقت الوصول المقرر، ووقت الوصول الفعلي بالدقائق (ARR_DELAY)، وما إذا كانت الرحلة متأخرة 15 دقيقة أو أكثر (ARR_DEL15).
فيما يلي قائمة كاملة بالأعمدة في مجموعة البيانات. يتم التعبير عن الأوقات بالوقت العسكري 24-ساعة. على سبيل المثال، 1130 تساوي 11:30 صباحاً و1500 تساوي 3:00 مساءً.
العمود الوصف YEAR السنة التي تم فيها الرحلة QUARTER الربع الذي تم فيه الرحلة (1-4) MONTH الشهر الذي تم فيه الرحلة (1-12) DAY_OF_MONTH اليوم من الشهر الذي تم فيه الرحلة (1-31) DAY_OF_WEEK اليوم من الأسبوع الذي تم فيه الرحلة (1=الاثنين، 2=الثلاثاء، الخ) UNIQUE_CARRIER التعليمة البرمجية لشحن شركات الطيران (مثل DL) TAIL_NUM رقم ذيل الطائرة FL_NUM رقم الرحلة ORIGIN_AIRPORT_ID هوية المطار الأصلي ORIGIN التعليمة البرمجية للمطار الأصلي (ATL، DFW، SEA، الخ.) DEST_AIRPORT_ID هوية مطار الوجهة DEST التعليمة البرمجية لمطار الوجهة (ATL، DFW، SEA، إلخ.) CRS_DEP_TIME وقت المغادرة المجدول DEP_TIME وقت المغادرة الفعلي DEP_DELAY عدد الدقائق التي تأخرتها المغادرة DEP_DEL15 0= تأخير المغادرة أقل من 15 دقيقة، 1= تأخير المغادرة 15 دقيقة أو أكثر CRS_ARR_TIME وقت الوصول المجدول ARR_TIME وقت الوصول الفعلي ARR_DELAY عدد الدقائق التي وصلت بها الرحلة متأخرة ARR_DEL15 0= وصلت أقل من 15 دقيقة في الوقت متأخرة، 1=وصلت 15 دقيقة أو أكثر في الوقت متأخرة CANCELLED 0= لم يتم إلغاء الرحلة، 1= تم إلغاء الرحلة DIVERTED 0= لم يتم تحويل مسار الرحلة، 1= تم تحويل مسار الرحلة CRS_ELAPSED_TIME وقت الرحلة المجدول بالدقائق ACTUAL_ELAPSED_TIME وقت الرحلة الفعلي بالدقائق DISTANCE المسافة المقطوعة في ميل
تشمل مجموعة البيانات توزيعًا متكافئًا تقريبًا للتواريخ على مدار السنة، وهو أمر مهم؛ لأن احتمالية تأخير الرحلة من Minneapolis بسبب العواصف الشتوية في تموز/ يوليه أقل من موعدها في كانون الثاني/ يناير. ولكن مجموعة البيانات هذه أبعد ما تكون عن كونها "نظيفة" وجاهزة للاستخدام. دعونا نكتب بعض رموز Pandas لتنظيفها.
أحد أهم جوانب إعداد مجموعة بيانات للاستخدام في التعلم الآلي هو تحديد أعمدة "الميزة" ذات الصلة بالنتيجة التي تحاول التنبؤ بها أثناء تصفية الأعمدة التي لا تؤثر على النتيجة، أو قد تحيزها بطريقة سلبية، أو قد تنتج خطوطا متعددة. مهمة هامة أخرى هي إزالة القيم المفقودة؛ إما عن طريق حذف الصفوف أو الأعمدة التي تحتوي عليها، أو استبدالها بقيم ذات معنى. في هذا التمرين، سوف تقوم بإزالة الأعمدة الدخيلة، واستبدال القيم المفقودة في الأعمدة المتبقية.
واحدة من أول الأشياء التي يبحث علماء البيانات عادة عنها في مجموعة البيانات هي القيم المفقودة. هناك طريقة سهلة للتحقق من القيم المفقودة في Pandas. للتوضيح، نفذ التعليمة البرمجية التالية في خلية في نهاية دفتر الملاحظات:
df.isnull().values.any()تأكد من أن المخرجات هي "True"، مما يشير إلى أن هناك قيمة مفقودة واحدة على الأقل في مكان ما في مجموعة البيانات.

التحقق من وجود قيم مفقودة
الخطوة التالية هي معرفة أين هي القيم المفقودة. للقيام بذلك، نفذ التعليمة البرمجية التالية:
df.isnull().sum()تأكد من أنك ترى المخرجات التالية التي تسرد عدد من القيم المفقودة في كل عمود:
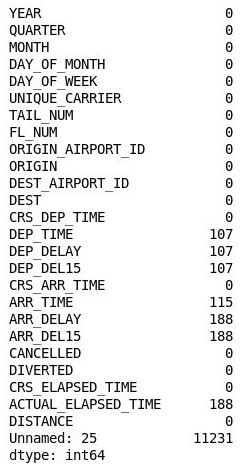
عدد القيم المفقودة في كل عمود
الغريب أن العمود 26 ("غير مسمى: 25") يحتوي على 11,231 قيمة مفقودة، والذي يساوي عدد الصفوف في مجموعة البيانات. تم إنشاء هذا العمود عن طريق الخطأ؛ لأن ملف CSV الذي قمت باستيراده يحتوي على فاصلة في نهاية كل سطر. لإزالة هذا العمود، قم بإضافة التعليمة البرمجية التالية إلى دفتر الملاحظات وقم بتنفيذه:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()افحص المخرجات، وتأكد من اختفاء العمود 26 من DataFrame:
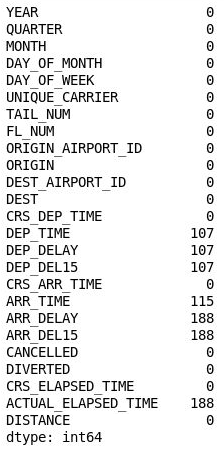
DataFrame مع إزالة العمود 26
لا يزال يحتوي الـ DataFrame على الكثير من القيم المفقودة؛ ولكن بعضها غير مفيد؛ لأن الأعمدة التي تحتوي عليها غير ذات صلة بالنموذج الذي تقوم ببنائه. الهدف من هذا النموذج هو التوقع بما إذا كانت الرحلة التي تفكر في حجزها من المرجح أن تصل في الوقت المحدد. إذا كنت تعرف أن الرحلة من المحتمل أن تكون متأخرة، فقد تختار حجز رحلة أخرى.
وبالتالي، فإن الخطوة التالية هي تصفية مجموعة البيانات؛ لإزالة الأعمدة التي لا تتعلق بنموذج توقعي. على سبيل المثال، ربما يكون لرقم ذيل الطائرة تأثير ضئيل على ما إذا كانت الرحلة ستصل في الوقت المحدد، وفي الوقت الذي تقوم فيه بحجز تذكرة، لا تملك طريقة لمعرفة ما إذا كان سيتم إلغاء الرحلة، أو تحويل مسارها أو تأخيرها. وعلى النقيض من ذلك، يمكن أن يكون لوقت المغادرة المجدول الكثير للقيام به مع الوصول في الوقت المحدد. بسبب النظام المحوري الذي تستخدمه معظم شركات الطيران، تميل الرحلات الصباحية إلى أن تكون في الوقت المحدد أكثر من رحلات بعد الظهيرة أو المسائية. وفي بعض المطارات الكبرى، تتكدس حركة المرور خلال النهار، مما يزيد من احتمالية تأخير الرحلات الجوية في وقت لاحق.
يوفر Pandas طريقة سهلة لتصفية الأعمدة التي لا تريدها. نفذ التعليمة البرمجية التالية في خلية جديدة في نهاية دفتر الملاحظات:
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()تُظهر المخرجات أن DataFrame يتضمن الآن فقط الأعمدة ذات الصلة إلى النموذج، وأن عدد القيم المفقودة تقل إلى حد كبير:
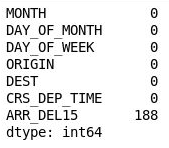
DataFrame المصفاة
العمود الوحيد الذي يحتوي الآن على قيم مفقودة هو عمود ARR_DEL15، الذي يستخدم 0s لتحديد الرحلات التي وصلت في الوقت المحدد، و1s للرحلات التي لم تفعل. استخدم التعليمة البرمجية التالية لإظهار الصفوف الخمسة الأولى ذات القيم المفقودة:
df[df.isnull().values.any(axis=1)].head()يمثل Pandas القيم المفقودة مع
NaN، والتي ترمز إلى Not a Number. تظهر المخرجات أن هذه الصفوف بالفعل قيم مفقودة في عمود ARR_DEL15: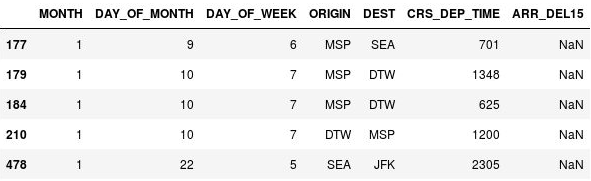
صفوف ذات قيم مفقودة
السبب في أن هذه الصفوف هي قيم ARR_DEL15 مفقودة؛ هو أنها تتوافق جميعًا مع الرحلات الجوية التي تم إلغاؤها أو تحويلها. يمكنك استدعاء dropna على DataFrame لإزالة هذه الصفوف. ولكن نظرا لأن الرحلة التي تم إلغاؤها أو تحويلها إلى مطار آخر يمكن اعتبارها "متأخرة"، فلنستخدم طريقة fillna لاستبدال القيم المفقودة ب 1s.
استخدم التعليمة البرمجية التالية لاستبدال القيم المفقودة في عمود ARR_DEL15 بـ 1s، وعرض الصفوف من 177 إلى 184:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]تأكد من
NaNاستبدال s في الصفوف 177 و179 و184 ب 1s مما يشير إلى أن الرحلات وصلت متأخرة: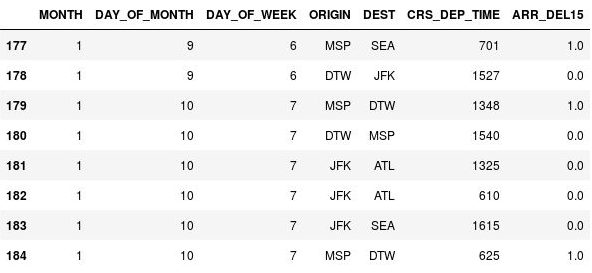
تم استبدال NaNs ب 1s
أصبحت مجموعة البيانات الآن "نظيفة" بمعنى أن القيم المفقودة قد استُبدلت، وأن قائمة الأعمدة قد ضاقت بأعمدة أكثر صلة بالنموذج. لكنك لم تنتهي بعد. هناك المزيد للقيام به لإعداد مجموعة البيانات؛ لاستخدامها في التعلم الآلي.
يمثل عمود CRS_DEP_TIME لمجموعة البيانات التي تستخدمها، أوقات المغادرة المجدولة. يمكن أن يكون تكرار الأرقام في هذا العمود— تحتوي على أكثر من 500 قيمة فريدة— تأثير سلبي على الدقة في نموذج للتعلم الآلي. يمكن حل هذا باستخدام تقنية تسمى الربط أو التكميم. ماذا لو قسمت كل رقم في هذا العمود على 100 وقربته لأقرب عدد صحيح؟ 1030 سوف تصبح 10، و 1925 ستصبح 19، وهكذا، وسوف تُترك مع 24 قيمة منفصلة في هذا العمود كحد أقصى. بديهياً، فمن المنطقي، أنه ربما لا يهم كثيراً إذا كانت الرحلة تغادر في الساعة 10:30 صباحاً أو 10:40 صباحاً ولكنه يهم كثيراً ما إذا كانت تغادر في الساعة 10:30 صباحاً أو 5:30 مساءً.
بالإضافة إلى ذلك، تحتوي أعمدة ORIGIN وDEST الخاصة بمجموعة البيانات على رموز المطار التي تمثل قيم التعلم الآلي الفئوية. هذه الأعمدة تحتاج إلى تحويلها إلى أعمدة منفصلة تحتوي على متغيرات المؤشرات، والمعروفة أحيانًا باسم المتغيرات "الوهمية". وبعبارة أخرى، فإن عمود ORIGIN، الذي يحتوي على خمسة رموز للمطار، يحتاج إلى تحويله إلى خمسة أعمدة، عمود لكل مطار، مع كل عمود يحتوي على 1s و0s مشيراً إلى ما إذا كانت الرحلة قد نشأت في المطار الذي يمثله العمود. يحتاج العمود DEST إلى معالجته بطريقة مشابهة.
في هذا التمرين، ستقوم "بربط" أوقات المغادرة في العمود CRS_DEP_TIME واستخدام أسلوب get_dummies Pandas لإنشاء أعمدة مؤشرات من عمودي ORIGIN وDEST.
استخدم الأمر التالي لعرض الصفوف الخمسة الأولى من الـ DataFrame:
df.head()لاحظ أن العمود CRS_DEP_TIME يحتوي على قيم من 0 إلى 2359 تمثل أوقات 24- ساعة.
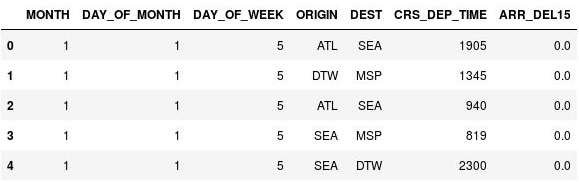
DataFrame مع أوقات مغادرة غير مرتبطة
استخدم العبارات التالية لوضع أوقات المغادرة في خانات:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()تأكد من أن الأرقام في العمود CRS_DEP_TIME تقع الآن في النطاق 0 إلى 23:
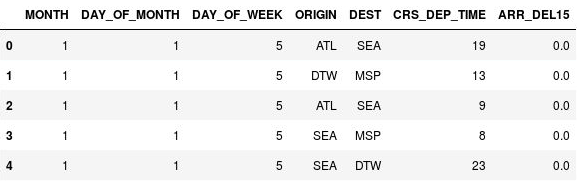
DataFrame مع أوقات المغادرة المرتبطة
الآن استخدم العبارات التالية لإنشاء أعمدة المؤشر من أعمدة ORIGIN وDEST أثناء إسقاط أعمدة ORIGIN وDEST نفسها:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()افحص الـ DataFrame الناتج، ولاحظ أن الأعمدة ORIGIN وDEST تم استبدالها بأعمدة مطابقة لرموز المطار الموجودة في الأعمدة الأصلية. الأعمدة الجديدة لديها 1s و0s مشيرة إلى ما إذا كانت رحلة معينة نشأت في أم تم توجيهها إلى المطار المقابل.
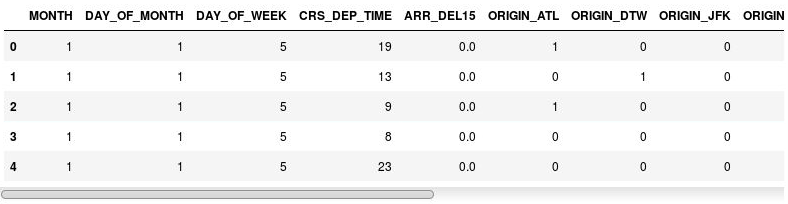
DataFrame مع أعمدة المؤشر
استخدم الأمر File ->Save and Checkpoint لحفظ دفتر الملاحظات.
مجموعة البيانات تبدو مختلفة جدًا عما كانت عليه في البداية؛ ولكن الآن هو الأمثل للاستخدام في التعلم الآلي.