استكشاف المفاهيم الرئيسية لسير عمل RAG
يعد Retrieval Augmented Generation (RAG) تقنية تجعل نماذج اللغات الكبيرة أكثر فعالية من خلال توصيلها ببياناتك المخصصة. يتبع سير عمل RAG عملية بسيطة من أربع خطوات، كما هو موضح في الرسم التخطيطي:
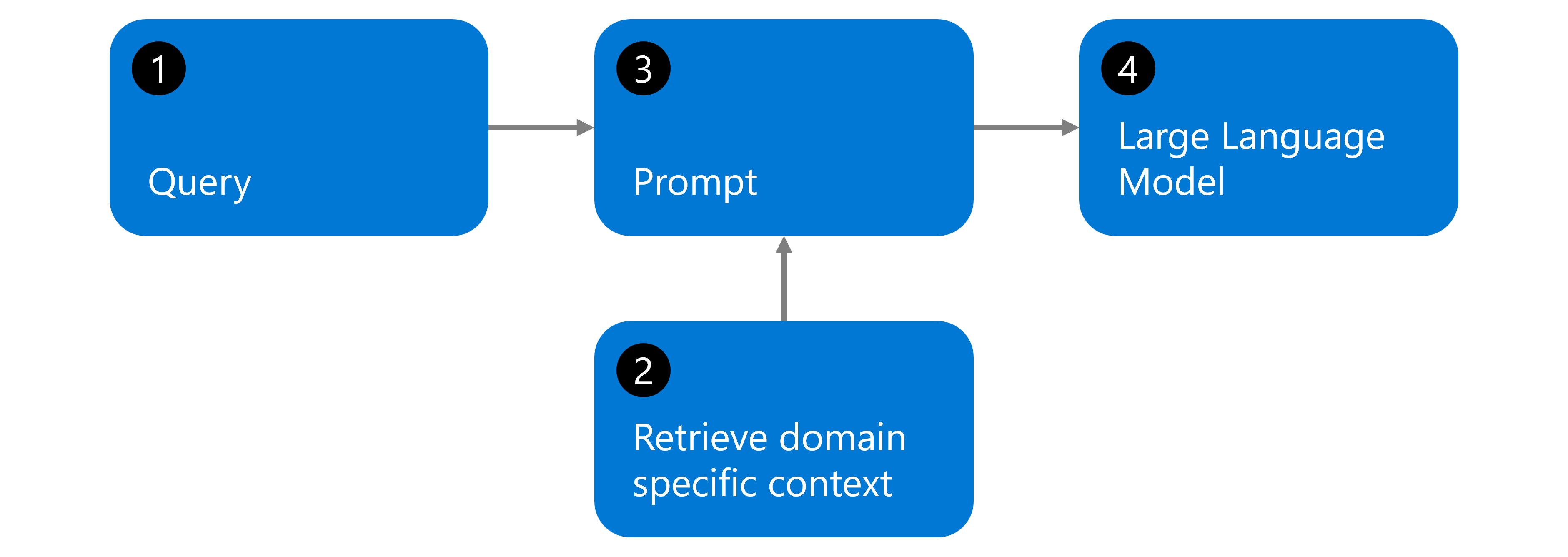
استعلام المستخدم: يطرح المستخدم سؤالا لا يمكن ل LLM الأساسي وحده الإجابة عنه بدقة لأنه ليس لديه حق الوصول إلى مستنداتك المحددة أو المعلومات الحديثة أو البيانات الخاصة.
البحث في قاعدة بياناتك: يبحث النظام من خلال مجموعة المستندات الخاصة بك (نهج الشركة والتقارير والأدلة وقواعد البيانات) - وليس بيانات التدريب الخاصة ب LLM. تم تحويل مستنداتك مسبقا إلى تضمينات وتخزينها في قاعدة بيانات متجهة. يعثر النظام على المعلومات الأكثر صلة من مستنداتك المحددة.
إضافة سياق إلى المطالبة: يتم دمج المعلومات ذات الصلة التي تم استردادها من مستنداتك مع السؤال الأصلي للمستخدم لإنشاء مطالبة محسنة توفر LLM بالسياق المحدد الذي يحتاجه.
LLM يولد استجابة: يعالج نموذج اللغة الأساسية كلا من السؤال الأصلي والسياق المسترد من مستنداتك لإنشاء استجابة دقيقة تستند إلى البيانات المحددة.
تعمل هذه العملية على سد الفجوة بين LLM للأغراض العامة ومعلوماتك المحددة أو الخاصة أو الحديثة، مما يسمح لك بالحصول على إجابات دقيقة استنادا إلى مستنداتك الخاصة دون الحاجة إلى إعادة تدريب النموذج الأساسي بأكمله.
لنلق نظرة على متى يمكنك استخدام RAG، ثم مراجعة المكونات والمفاهيم الرئيسية في سير عمل RAG.
فهم متى تستخدم RAG
يمكنك استخدام RAG لروبوتات الدردشة وتحسين البحث وإنشاء المحتوى وتلخيصه.
روبوتات الدردشة: تساعد RAG روبوتات الدردشة على توفير إجابات أكثر دقة من خلال الوصول إلى المعلومات الحالية. عند التكامل مع أنظمة دعم العملاء، يمكن لروبوتات الدردشة التي تعمل ب RAG أتمتة الدعم وحل أسئلة العملاء بسرعة باستخدام بيانات up-to-date.
تحسين البحث: بدلا من إرجاع الارتباطات والمقتطفات فقط، توفر محركات البحث التي تعمل ب RAG إجابات محادثة كاملة. يحصل المستخدمون على استجابات شاملة تقوم بتجميع المعلومات من مصادر متعددة، ما يسهل العثور على ما يحتاجون إليه.
إنشاء المحتوى وتلخيصه: إنتاج محتوى عالي الجودة وقائم على الحقائق باستخدام مصادر البيانات الخاصة بك. تمكنك RAG من إنشاء مقالات مستنيرة، وإنشاء ملخصات من مستندات طويلة، وتطوير تقارير تقوم بتجميع المعلومات من مصادر متعددة.
استكشاف المفاهيم الرئيسية في سير عمل RAG
يستند سير عمل RAG إلى أربعة مكونات أساسية تعمل معا:
- التضمينات - تحويل النص إلى متجهات رياضية تلتقط المعنى
- قواعد بيانات المتجهات - تخزين هذه المتجهات وتنظيمها للبحث السريع
- البحث والاسترداد - البحث عن المعلومات الأكثر صلة استنادا إلى استعلامات المستخدم
- زيادة المطالبة - دمج المعلومات المستردة مع السؤال الأصلي
فكر في هذه المكونات على أنها كتل بناء: تترجم عمليات التضمين كل شيء إلى لغة مشتركة، وتنظم قواعد بيانات المتجهات هذه المعلومات، وتبحث وتسترد ما هو مطلوب، وتضعها الزيادة الفورية معا الذكاء الاصطناعي لاستخدامها.
تحويل المستندات والاستعلامات باستخدام عمليات التضمين
قبل أن يتمكن نظام RAG من العثور على المعلومات ذات الصلة، يحتاج إلى تحويل جميع النصوص من كل من المستندات واستعلامات المستخدم إلى تنسيق يسمح للمقارنة الدلالية. هذا هو المكان الذي تأتي فيه التضمينات.
نموذج التضمين هو أداة الذكاء الاصطناعي متخصصة تحول النص إلى خطوط متجهة رقمية (قوائم الأرقام) تمثل معنى النص. فكر في الأمر كمترجم يحول العمل والجمل إلى لغة رياضية يمكن لأجهزة الكمبيوتر فهمها ومقارنتها.
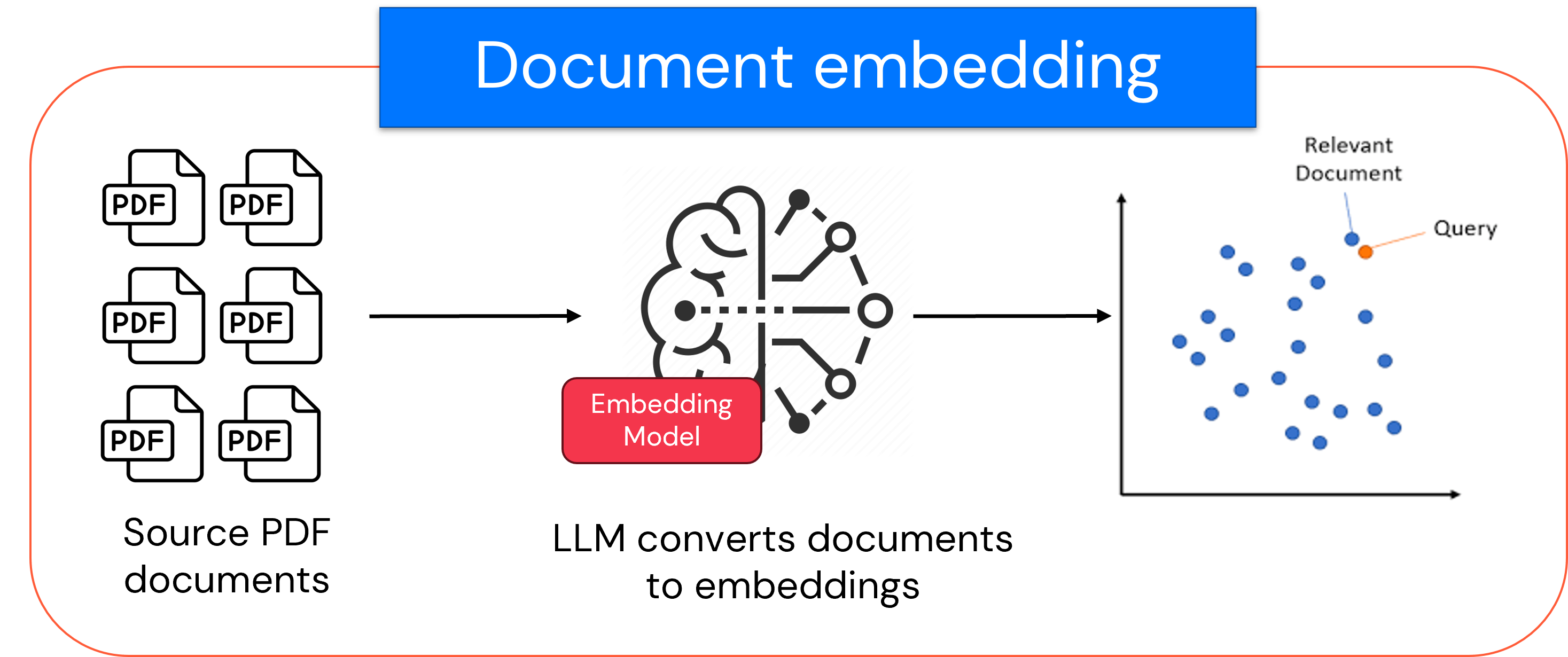
يعد تضمين المستند، كما هو موضح في الرسم التخطيطي، جزءا من مرحلة الإعداد. ويتم ذلك مرة واحدة لإعداد قاعدة معارف. قبل أن يعمل نظام RAG الخاص بك، تحتاج إلى إعداد مستنداتك. يأخذ نموذج التضمين جميع المستندات النصية الخاصة بك ويحولها إلى متجهات رياضية تسمى التضمينات، والتي تلتقط معناها الدلالي. تنشئ خطوة المعالجة المسبقة هذه قاعدة معارف قابلة للبحث.
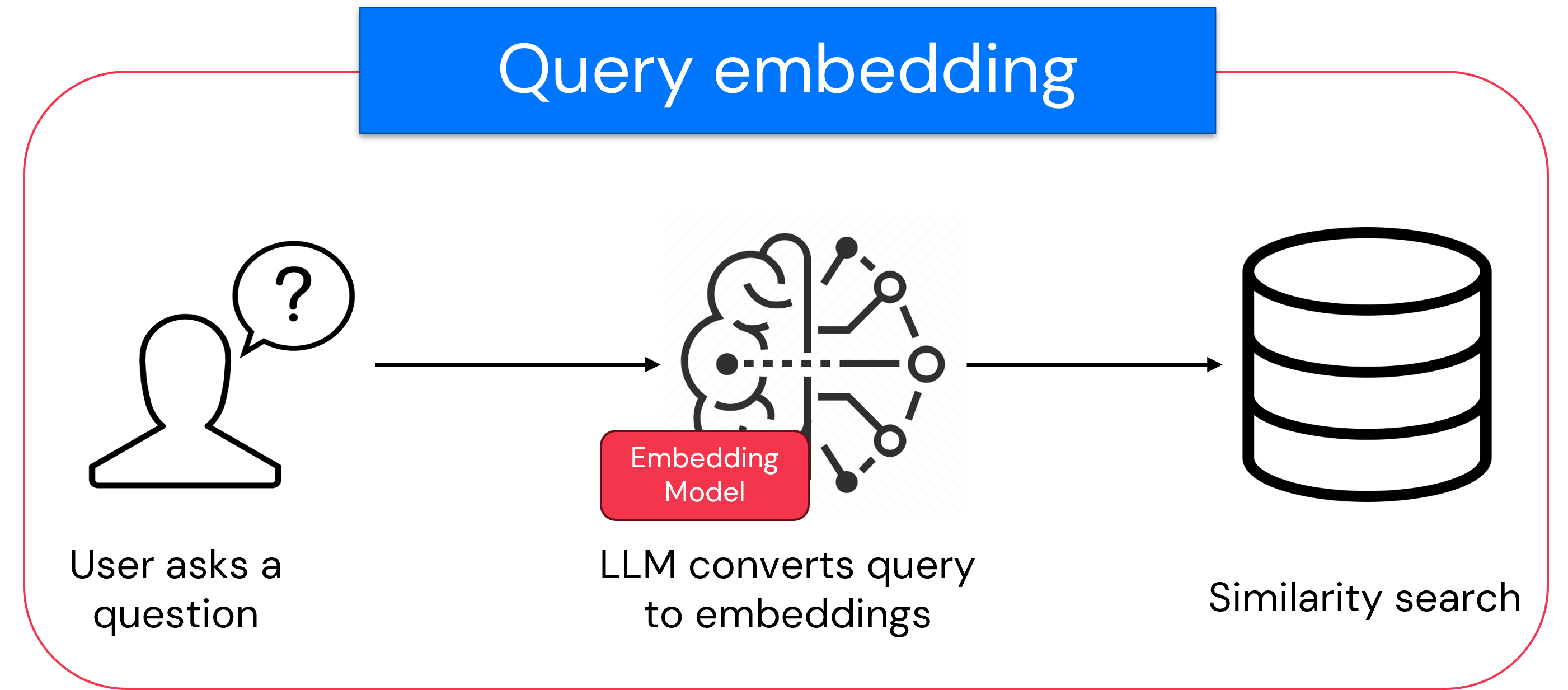
يتم تضمين الاستعلام، الموضح في الرسم التخطيطي، في كل مرة يطرح فيها المستخدم سؤالا. أولا، يتم تحويل سؤال المستخدم إلى تضمين باستخدام نفس نموذج التضمين الذي تم استخدامه لمعالجة المستندات. يقوم هذا التحويل في الوقت الحقيقي بإعداد الاستعلام للمقارنة مع تضمينات المستند المعالجة مسبقا. يمكن للنظام بدء البحث عن المستندات ذات الصلة فقط بعد تضمين الاستعلام.
فكر في تضمين المستند على أنه إنشاء مكتبتك القابلة للبحث، وتضمين الاستعلام على أنه ترجمة كل سؤال إلى نفس التنسيق حتى تتمكن من العثور على الكتب الصحيحة في تلك المكتبة. يبدأ البحث فقط بعد ترجمة السؤال.
تخزين التضمينات والبحث فيها باستخدام مخزن متجهات
بمجرد تحويل مستنداتك إلى تضمينات، تحتاج إلى مكان ما لتخزينها يسمح بالبحث الدلالي السريع. ستكافح قاعدة البيانات العادية مع هذا لأنها لا يمكنها مقارنة التشابه الرياضي بين المتجهات بكفاءة.
مخزن المتجهات هو قاعدة بيانات متخصصة مصممة خصيصا لتخزين عمليات التضمين والبحث فيها (تلك المتجهات الرياضية التي تم إنشاؤها من مستنداتك). على عكس قواعد البيانات التقليدية التي تخزن النص أو الأرقام، يتم تحسين مخازن المتجهات للعثور على خطوط متجهة مماثلة بسرعة، حتى عند التعامل مع ملايين المستندات.
يمكنك تنفيذ تخزين المتجهات من خلال قواعد بيانات المتجهات أو مكتبات المتجهات أو المكونات الإضافية لقاعدة البيانات.
يتيح مخزن المتجهات البحث الدلالي، ما يعني أنه يعثر على محتوى ذي صلة استنادا إلى المعنى بدلا من تطابق الكلمة الأساسية الدقيقة. على سبيل المثال، قد يعثر البحث عن "إجازة" على مستندات حول "نهج الإجازات" على الرغم من أن الكلمات الدقيقة لا تتطابق. عند البحث، يمكنك تطبيق عوامل التصفية قبل الاستعلام أو داخله أو بعده.
زيادة المطالبة بالمحتوى الذي تم استرداده
بعد العثور على المستندات الأكثر صلة، يجمع نظام RAG هذه المعلومات مع السؤال الأصلي للمستخدم لإنشاء "مطالبة معززة" تعطي LLM كل ما تحتاجه لتوفير إجابة دقيقة.
تبدو عملية الزيادة كما يلي:
- ابدأ بسؤال المستخدم: "ما هي سياسة الإجازة الخاصة بنا؟"
- إضافة سياق تم استرداده: تضمين مقتطفات ذات صلة من مستندات الموارد البشرية
- إنشاء مطالبة معززة: "استنادا إلى مستندات نهج الموارد البشرية هذه: [المحتوى الذي تم استرداده]، ما هو نهج الإجازة الخاص بنا؟" لدى LLM الآن سؤال المستخدم والمعلومات المحددة اللازمة للإجابة عليه بدقة. ويسمى هذا "التعلم في السياق" لأن LLM يتعلم من السياق المقدم في المطالبة بدلا من بيانات التدريب الأصلية الخاصة به.
في الخطوة الأخيرة، يتم إرسال المطالبة المعززة إلى نموذج اللغة الكبيرة (LLM)، الذي ينشئ استجابة استنادا إلى كل من السؤال والمعلومات المستردة. يمكن أن تتضمن LLM اقتباسات من المصادر الأصلية، ما يسمح للمستخدمين بالتحقق من مصدر المعلومات.
تتمثل الفائدة الرئيسية لسير عمل RAG في أنه يمنحك إجابات دقيقة مدعومة من المصدر دون الحاجة إلى إعادة تدريب نموذج اللغة بأكمله على مستنداتك المحددة.
نظرة عامة على بنية RAG
يجمع سير عمل RAG الكامل بين جميع المكونات التي راجعناها في نظام موحد يحول LLMs للأغراض العامة إلى مساعدين على دراية بمجالك المحدد.
الآلية الرئيسية هي التعلم في السياق - بدلا من إعادة تدريب LLM، يمكنك توفير معلومات ذات صلة بسياق في كل مطالبة، ما يسمح ل LLM بإنشاء استجابات مستنيرة دون تعديل دائم.
قد تتضمن التطبيقات المتقدمة حلقات ملاحظات لتحسين النتائج عندما لا تفي الاستجابة الأولية بحدود الجودة.