ما المقصود بتصنيف البيانات?
التصنيف الثنائي هو التصنيف من فئتين. على سبيل المثال: يمكننا تصنيف المرضى على أنهم غير مصابين بالسكري أو مصابون بالسكري.
يتم التنبؤ بالفئة عن طريق تحديد الاحتمال لكل فئة ممكنة كقيمة بين 0 (مستحيل) و1 (معين). الاحتمال الإجمالي لجميع الفئات هو دائما 1، حيث إن المريض بالتأكيد إما مصاب بالسكري أو غير مصاب بالسكري. لذا، إذا كان الاحتمال المتوقع للمريض مصاب بالسكري هو 0.3، فهناك احتمال مقابل 0.7 أن يكون المريض غير مصاب بالسكري.
يتم استخدام قيمة الحد، غالبا 0.5، لتحديد الفئة المتوقعة. إذا كانت الفئة الإيجابية (في هذه الحالة، مصاب بالسكري) لديها احتمال متوقع أكبر من الحد، التنبؤ بتصنيف مرضى السكري.
تدريب وتقييم نموذج التصنيف
التصنيف هو مثال على تقنية التعلم الآلي الخاضعة للإشراف، ما يعني أنها تعتمد على البيانات التي تتضمن قيم الميزات المعروفة وقيم التسمية المعروفة. في هذا المثال، قيم الميزة هي قياسات تشخيصية للمرضى، وقيم التسمية هي تصنيف لغير مرضى السكري أو مرضى السكري. يتم استخدام خوارزمية التصنيف لاحتواء مجموعة فرعية من البيانات في دالة يمكنها حساب الاحتمال لكل تسمية فئة من قيم الميزة. تُستخدم البيانات المتبقية لتقييم النموذج من خلال مقارنة التنبؤات التي تنشأ من الميزات بتسميات الفئات المعروفة.
مثال بسيط
دعونا نستكشف مثالا للمساعدة في شرح المبادئ الرئيسية. لنفترض أن لدينا بيانات المريض التالية، والتي تتكون من ميزة واحدة (مستوى الجلوكوز في الدم) وتسمية فئة 0 لغير مرضى السكري، و1 لمرضى السكري.
| السكر في الدم | السكري |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 115 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
نستخدم أول ثماني ملاحظات لتدريب نموذج التصنيف، ونبدأ برسم ميزة جلوكوز الدم (x) وتسمية السكري المتوقعة (y).
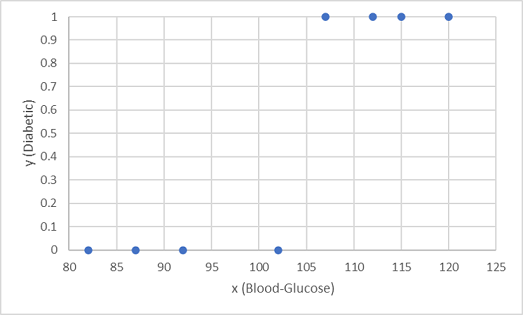
ما نريده هو دالة تحسب قيمة الاحتمال لـ y استناداً إلى x (بعبارة أخرى، نحتاج إلى الدالة f(x) = y). يمكنك أن ترى من الرسم البياني أن المرضى الذين يعانون انخفاض مستوى الجلوكوز في الدم جميعهم غير مصابين بالسكري، في حين أن المرضى الذين يعانون ارتفاع مستوى الجلوكوز في الدم يعانون مرض السكري. يبدو أنه كلما ارتفع مستوى الجلوكوز في الدم، كان من المحتمل أكثر أن يكون المريض مصابا بالسكري، مع نقطة انعطاف في مكان ما بين 100 و 110. نحن بحاجة إلى ملاءمة دالة تحسب القيمة بين 0 و1 لـ y لهذه القيم.
واحدة من هذه الدالات هي وظيفة لوجستية، والتي تشكل منحنى سيغمويدال (على شكل S).
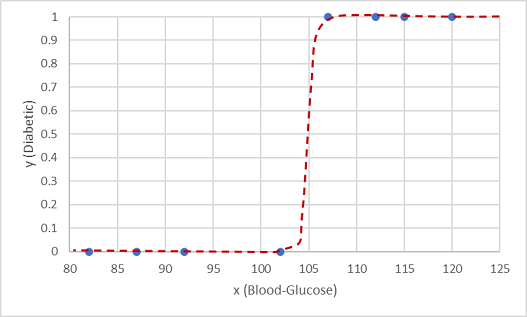
الآن يمكننا استخدام الدالة لحساب قيمة الاحتمال حيث تكون y إيجابية، وهذا يعني أن المريض مصاب بالسكري، من أي قيمة من x من خلال العثور على النقطة على خط الدالة لـ x. يمكننا تعيين قيمة عتبة 0.5 كنقطة فاصلة للتنبؤ بتسمية الفئة.
دعونا نختبرها مع قيمتي البيانات اللتين قمنا بالاحتفاظ بها.
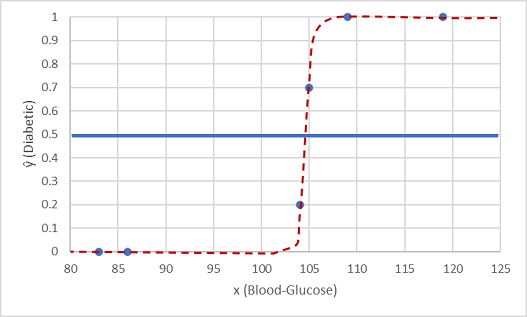
ينتج عن النقاط المرسومة تحت خط العتبة فئة متوقعة من 0 (غير مصاب بالسكري) ويتم توقع النقاط فوق الخط على أنها 1 (مصاب بالسكري).
الآن يمكننا مقارنة تنبؤات التسمية (ŷ، أو "y-hat")، استنادا إلى الوظيفة اللوجستية المغلفة في النموذج، بتسميات الفئة الفعلية (y).
| × | س | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |