ما هو التراجع؟
ينشئ الانحدار أثناء عمله علاقة بين المتغيرات الموجودة في البيانات التي تمثل الخصائص- (والمعروفة باسم الميزات)- الخاصة بالشيء الذي يتم ملاحظته، والمتغير الذي نحاول التنبؤ به- (والمعروف باسم الوصف).
تذكر أن شركتنا تستأجر الدراجات وتريد التنبؤ بالعدد المتوقع من الإيجارات في يوم معين. في هذه الحالة، ستتضمن الميزات أشياء مثل اليوم والأسبوع والشهر وهكذا، في حين أن الوصف يكون عدد إيجارات الدراجات.
لتدريب النموذج، نبدأ بعينة بيانات تحتوي على الميزات، بالإضافة إلى القيم المعروفة للتسمية؛ لذلك في هذه الحالة، نحتاج إلى بيانات تاريخية تتضمن التواريخ والظروف الجوية وعدد إيجارات الدراجات.
سنقوم بعد ذلك بتقسيم عينة البيانات هذا إلى مجموعتين فرعيتين:
- مجموعة بيانات التدريب التي سنطبق عليها خوارزمية تحدد الدالة التي تُضمِّن العلاقة بين قيم الميزة وقيم التسمية المعروفة.
- مجموعة بيانات التحقق أو الاختبار التي يمكننا استخدامها لتقييم النموذج من خلال استخدامه لإنشاء تنبؤات للتسمية ومقارنتها بقيم التسمية الفعلية المعروفة.
إن استخدام البيانات القديمة مع قيم التسمية المعروفة لتدريب نموذج ما يجعل الانحدار مثالاً على التعلم الآلي الخاضع للإشراف.
مثال بسيط
لنضرب مثالاً بسيطاً لمعرفة كيفية عمل عملية التدريب والتقييم من حيث المبدأ. على سبيل المثال، سنقوم بتبسيط السيناريو بحيث نستخدم ميزة واحدة هي درجة الحرارة اليومية المتوسطة، للتنبؤ بوصف إيجارات الدراجات.
سنبدأ ببعض البيانات التي تتضمن القيم المعروفة لميزة درجة الحرارة اليومية المتوسطة وتسمية إيجارات الدراجات.
| درجة الحرارة | الإيجارات |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
| 82 | 156 |
| 54 | 114 |
| 62 | 129 |
والآن، سنحدد بشكل عشوائي خمسة من هذه الملاحظات ثم نستخدمها لتدريب نموذج الانحدار. عندما نتحدث عن "تدريب نموذج"، فما نعنيه هو إيجاد دالة (معادلة رياضية؛ ولنسميها f) يمكنها استخدام الميزة درجة الحرارة (التي سنسميها x) لحساب عدد الإيجارات (التي سنسميها y). بمعنى آخر، نحتاج إلى تحديد الدالة التالية: f(x) = y.
تبدو مجموعة بيانات التدريب الخاصة بنا كما يلي:
| × | س |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
لنبدأ بتخطيط قيم التدريب لـ x وy على المخطط:

نحتاج الآن إلى تحديد دالة لهذه القيم، مما يسمح ببعض الاختلافات العشوائية. ربما يمكنك أن ترى أن النقاط المرسومة تشكل خط قطري مستقيم تقريبا؛ بمعنى آخر، هناك علاقة خطية واضحة بين x وy، لذلك نحن بحاجة إلى العثور على دالة خطية هي الأنسب لعينة البيانات. توجد العديد من الخوارزميات التي يمكننا استخدامها لتحديد هذه الدالة، والتي ستعثر في النهاية على خط مستقيم بالحد الأدنى من التباين الكلي من النقاط المرسومة؛ وذلك كما يلي:
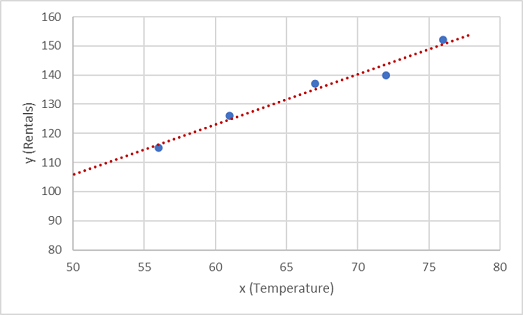
يمثل الخط دالة خطية يمكن استخدامها مع أي قيمة من قيم x لتطبيق ميل الخط وتقاطعه (موضع تقاطع الخط مع المحور y عندما تكون x تساوي 0) لحساب y. في هذه الحالة، إذا قمنا بتوسيع الخط إلى اليسار، فسنجد أنه عندما تكون x هي 0، y حوالي 20، ومنحدر الخط هو أنه لكل وحدة من x التي تتحرك على طول إلى اليمين، يزيد y بنحو 1.7. لذلك يمكننا حساب دالتنا f ك 20 + 1.7x.
الآن بعد أن حددنا دالة التنبؤ، يمكننا استخدامها للتنبؤ بالأوصاف الخاصة ببيانات التحقق التي احتفظنا بها ومقارنة القيم المتوقعة (التي نشير إليها عادة بالرمز ŷ، أو "y-hat") بالقيم الفعلية المعروفة لـ y.
| × | س | ŷ |
|---|---|---|
| 82 | 156 | 159.4 |
| 54 | 114 | 111.8 |
| 62 | 129 | 125.4 |
لنتعرف على كيفية مقارنة قيم y وŷ في الرسم البياني:

النقاط المرسومة على خط الدالة هي قيم ŷ المتوقعة المحسوبة بواسطة الدالة، والنقاط المرسومة الأخرى هي قيم y الفعلية.
توجد طرق مختلفة يمكننا من خلالها قياس التباين بين القيم المتوقعة والفعلية، ويمكننا استخدام هذه المقاييس لتقييم مدى صحة تنبؤ النموذج.
إشعار
يعتمد التعلم الآلي على الإحصاء والرياضيات، ومن المهم أن تكون على دراية بالمصطلحات المحددة التي يستخدمها الإحصائيون وعلماء الرياضيات (وكذلك علماء البيانات). يمكنك التفكير في الاختلاف بين قيمة الوصف المتوقعة وقيمة الوصف الفعليةكمقياس للخطأ. ومع ذلك، في الممارسة العملية، تستند القيم "الفعلية" إلى عينات من الملاحظات (التي قد تخضع نفسها لبعض التباين العشوائي). لتوضيح أننا نقارن قيمة (ŷ) المتوقعة مع قيمة (y) الملحوظة فإننا نشير إلى الفرق بينهما على أنه القيم المتبقية. يمكننا تلخيص القيم المتبقية لجميع تنبؤات بيانات التحقق لحساب إجمالي الفاقد في النموذج باعتبار ذلك مقياساً لأدائه في التنبؤ.
إحدى الطرق الأكثر شيوعاً لقياس الخسارة هي تربيع القيم المتبقية الفردية، وجمع القيم المربعة، وحساب المتوسط. تربيع القيم المتبقية يكافئ إسناد الحساب إلى القيم المطلقة (مع تجاهل ما إذا كان الاختلاف سالباً أم موجباً) وإعطاء أهمية أكبر للاختلافات الأكبر. يسمى هذا المقياس الخطأ التربيعي المتوسط.
بالنسبة لبيانات التحقق الخاصة بنا، يظهر الحساب كما يلي:
| س | ŷ | y - ŷ | (y - ŷ)2 |
|---|---|---|---|
| 156 | 159.4 | -3.4 | 11.56 |
| 114 | 111.8 | 2.2 | 4.84 |
| 129 | 125.4 | 3.6 | 12.96 |
| Sum | ∑ | 29.36 | |
| المتوسط | x̄ | 9.79 |
لذلك، فإن الخسارة لنموذجنا استنادا إلى مقياس MSE هي 9.79.
إذن، هل هذا جيد؟ من الصعب معرفة ذلك، لأن قيمة MSE لا يتم التعبير عنها في وحدة قياس ذات معنى. نحن نعلم أنه كلما انخفضت القيمة، قل الخسارة الموجودة في النموذج، وبالتالي، كلما كان التنبؤ أفضل. وهذا ما يجعله مقياساً فعَّالاً لمقارنة نموذجين ومعرفة النموذج الأفضل أداءً.
في بعض الأحيان، يكون من المفيد التعبير عن الخسارة في نفس وحدة القياس مثل قيمة التسمية المتوقعة نفسها؛ في هذه الحالة، عدد الإيجارات. ولكن، يمكننا إجراء ذلك عن طريق حساب الجذر التربيعي لمقياس الخطأ التربيعي المتوسط، والذي ينتج عنه مقياس معروف يُسمى جذر الخطأ التربيعي المتوسط (RMSE).
√9.79 = 3.13
لذلك، يشير RMSE الخاص بنموذجنا إلى أن الخسارة تزيد قليلا عن 3، والتي يمكنك تفسيرها بشكل فضفاض على أنها تعني أن التنبؤات غير الصحيحة في المتوسط خاطئة من خلال حوالي ثلاثة تأجيرات.
يوجد العديد من المقاييس الأخرى التي يمكن استخدامها لقياس معدل الخسارة في الانحدار. على سبيل المثال، يمثل R2 (الجذر التربيعي) (والمعروف أحياناً بمعامل التحديد) الارتباط بين x وy تربيع. ينتج عن ذلك قيمة بين 0 و1 تقيس معدل التباين الذي يمكن توضيحه بواسطة النموذج. بصورة عامة، كلما اقتربت هذه القيمة من 1، كان تنبؤ النموذج أفضل.