التعرف على Spark
للحصول على فهم أفضل لكيفية معالجة البيانات وتحليلها باستخدام Apache Spark في Azure Databricks، يجدر بك فهم ما تعنيه «البنية الأساسية».
نظرة عامة رفيعة المستوى
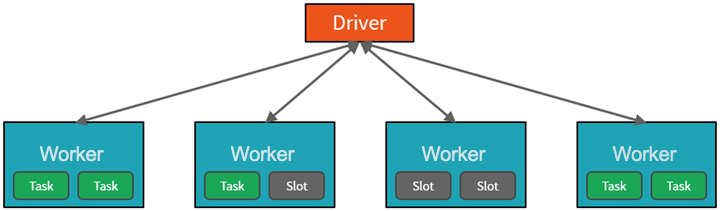
تُطلق Azure Databricks service Apache Spark clusters وتديرها ضمن اشتراك Azure الخاص بك وذلك من مستوى رفيع. Apache Spark clusters عبارة عن مجموعات من أجهزة الكمبيوتر التي يتم التعامل معها على أنها جهاز كمبيوتر واحد وتعالج تنفيذ الأوامر الصادرة من دفاتر الملاحظات. تتيح أنظمة المجموعات إمكانية معالجة البيانات بحيث تكون متوازية عبر العديد من أجهزة الكمبيوتر لتحسين الحجم والأداء. وهي تتكون من برنامج تشغيل أجهزة Spark وعُقد العامل. تُرسل عُقدة برنامج التشغيل العمل إلى عُقدة العامل، وتُرشدها إلى سحب البيانات من مصدر بيانات محدد.
في Databricks، عادة ما تكون واجهة دفتر الملاحظات هي برنامج التشغيل. يحتوي برنامج تشغيل الجهاز هذا على التكرار الحلقي الرئيسي للبرنامج، ويقوم بإنشاء مجموعات البيانات الموزعة على نظام المجموعة، ثم يقوم بتطبيق العمليات على مجموعات البيانات تلك. تصل برامج تشغيل الجهاز إلى Apache Spark من خلال عنصر SparkSession بغض النظر عن موقع التوزيع.
يدير Microsoft Azure نظام المجموعة ويقوم بتحجيمه تلقائيًا حسب الحاجة استنادًا إلى الاستخدام والإعداد المستخدم عند تكوين نظام المجموعة. يمكن أيضًا تمكين الإنهاء التلقائي، ما يُتيح لـ Azure إنهاء نظام المجموعة بعد عدد محدد من دقائق عدم النشاط.
مهام Spark بالتفصيل
يتم تقسيم العمل الذي تم إرساله إلى نظام المجموعة إلى العديد من الوظائف المستقلة حسب الحاجة. هذه هي الطريقة التي يتم بها توزيع العمل عبر عُقد نظام المجموعة. وتنقسم الوظائف بدورها إلى مهام أخرى. يتم تقسيم الإدخال إلى وظيفة إلى قسم واحد أو أكثر. وهذه الأقسام هي وحدة العمل لكل slot. في المهام الإضافية، قد تحتاج الأقسام إلى إعادة تنظيمها ومشاركتها عبر الشبكة.
يكمن السر وراء أداء Spark الرائع في التوازي. يقتصر التحجيم عمودياً (عن طريق إضافة موارد إلى كمبيوتر واحد) على كمية محدودة من ذاكرة الوصول العشوائي (RAM) ومؤشرات الترابط وسرعات CPU؛ ولكن تتوسع أنظمة المجموعات أفقياً، مع إضافة عقد جديدة إلى نظام المجموعة حسب الحاجة.
يتوازى Spark مع الوظائف على مستويين:
- المستوى الأول من التوازي هو المُنفِّذ - جهاز Java ظاهري (JVM) يتم تشغيله على عقدة، وعادةً، يكون هناك مثيلاً واحداً لكل عقدة.
- يتمثل المستوى الثاني من عملية التوازي في الفتحة - يتم تحديد عددها من جانب عدد من الذاكرات الأساسية ووحدات CPU لكل عقدة.
- يحتوي كل مُنفِّذ على فتحات متعددة يمكن تعيين المهام المتوازية إليها.
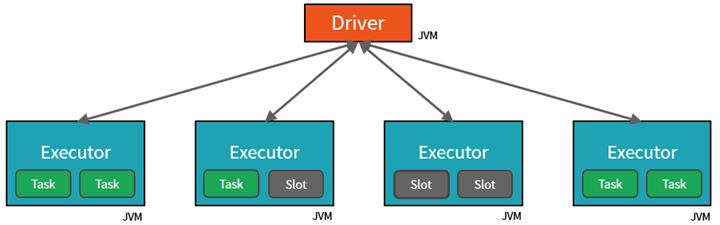
يعد جهاز Java الظاهري بطبيعة الحال ذا مؤشرات ترابط متعددة، ولكن الجهاز الواحد من أجهزة Java الظاهرية، مثل ذلك الجهاز الذي ينسق العمل على جانب برنامج التشغيل، يحتوي على حد أعلى محدود. من خلال تقسيم العمل إلى مهام، يمكن لبرنامج تشغيل الجهاز تعيين وحدات العمل إلى *فتحات في المُنفِّذين على عُقد العامل للتنفيذ المتوازي. بالإضافة إلى ذلك، يحدد برنامج تشغيل الجهاز كيفية تقسيم البيانات بحيث يمكن توزيعها للمعالجة المتوازية. لذلك، يعيّن برنامج تشغيل الجهاز قسماً من البيانات لكل مهمة بحيث تعرف كل مهمة أي جزء من البيانات يجب معالجته. بمجرد البدء، ستقوم كل مهمة بإحضار قسم البيانات المعينة إليه.
الوظائف والمراحل
اعتماداً على العمل الذي يتم تنفيذه، قد تكون هناك حاجة إلى وظائف متوازية متعددة. يتم تقسيم كل وظيفة إلى مراحل. هناك تشبيه مفيد يتمثل في تخيل أن الوظيفة هي بناء منزل:
- المرحلة الأولى هي إرساء الأساس.
- المرحلة الثانية هي إقامة الجدران.
- وستكون المرحلة الثالثة هي إضافة السقف.
إن محاولة القيام بأي من هذه الخطوات خارج النظام أمر غير منطقي، وقد يكون مستحيلاً في الواقع. وبالمثل، يقسِّم Spark كل وظيفة إلى مراحل لضمان تنفيذ كل شيء بالترتيب الصحيح.